-
-
TNMM check!
Inspiration
I read an article about how a company shifted millions in profits using royalties. I ended up researching more about the topic and that’s when I stumbled upon transfer pricing. Transfer pricing is the price one branch of a company charges another branch for goods, services, or intellectual property across borders. I'm currently taking a class in my grad program, a nascent research field called neurosymbolic AI as well. When I looked at the process of how people establish transfer pricing, I realized it fit the shape of the problem neurosymbolic AI attempts to tackle very well. I ended up building a solution to a transfer pricing problem with this emerging technique which provides explainable and auditable decisions to AI.
What it does
Transfer pricing is an expensive obligation companies deal with worldwide.
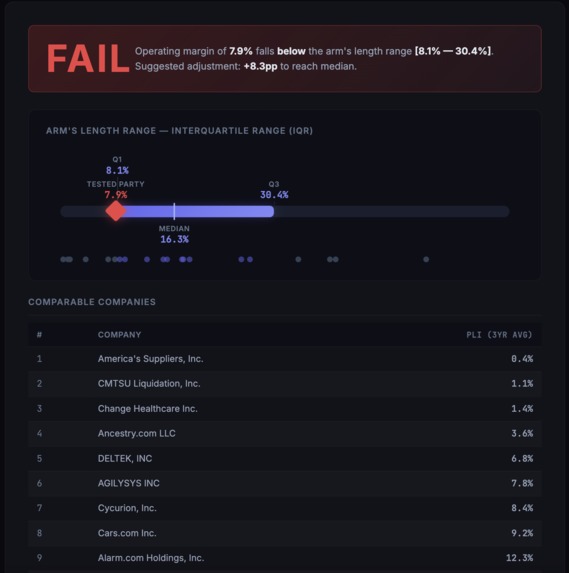
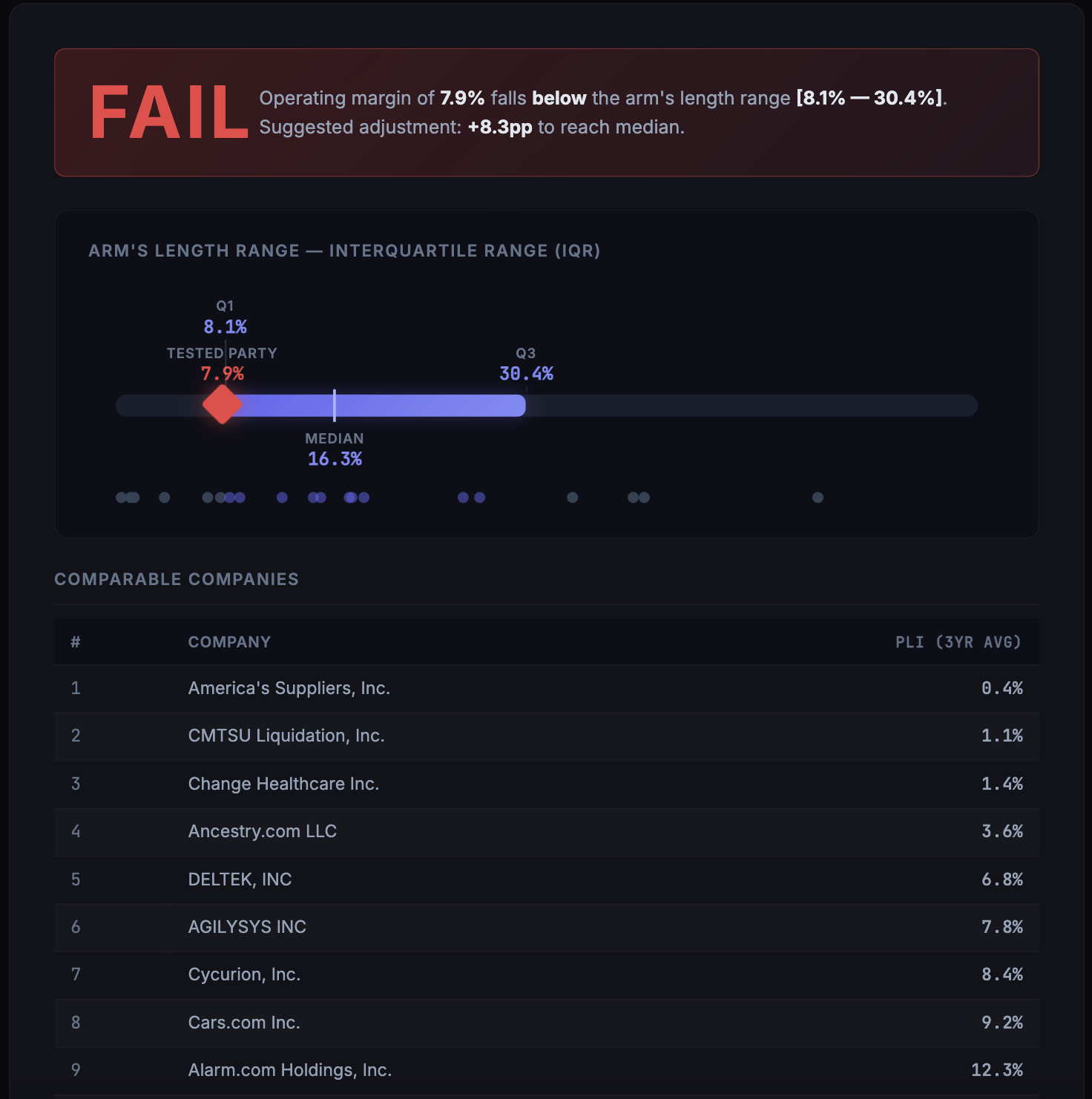
Every time a subsidiary of a multinational sells something to a sister company, tax authorities in both jurisdictions demand proof that the price was "arm's length." Meaning: the price two unrelated companies would have agreed to in the open market. This isn't optional. It's mandated by the OECD's Base Erosion and Profit Shifting (BEPS) framework, enforced in 140+ countries, and getting a transfer price wrong can trigger adjustments in the tens of millions of dollars. The standard methodology for proving arm's length pricing is the Transactional Net Margin Method (TNMM). It works like this:
1) Read the intercompany agreement to understand what the "tested party" does 2) Search public company filings to find comparable uncontrolled transactions — independent companies performing similar functions 3) Calculate a Profit Level Indicator (PLI) for each comparable (e.g., operating margin, net cost plus markup) 4) Compute the interquartile range (IQR) across comparables:
Q1=P25,Q3=P75,Arm’s Length Range=[Q1,Q3]Q_1 = P_{25}, \quad Q_3 = P_{75}, \quad \text{Arm's Length Range} = [Q_1, Q_3]Q1=P25,Q3=P75,Arm’s Length Range=[Q1,Q3]
5) Test whether the tested party's PLI falls within that range:
Result={PASSif Q1≤PLItested≤Q3FAILotherwise\text{Result} = \begin{cases} \textbf{PASS} & \text{if } Q_1 \leq \text{PLI}_{\text{tested}} \leq Q_3 \ \textbf{FAIL} & \text{otherwise} \end{cases}Result={PASSFAILif Q1≤PLItested≤Q3otherwise
6) If FAIL, calculate the suggested adjustment to median:
Δ=Median−PLItested\Delta = \text{Median} - \text{PLI}_{\text{tested}}Δ=Median−PLItested
Right now, steps 1–3 take a senior consultant 60–80% of the engagement time. They're reading dense legal agreements, manually searching SEC EDGAR and Bureau van Dijk databases, hand-screening dozens of companies against selection criteria, and building Excel models to run calculations that are, at their core, deterministic arithmetic.
Comps.ai aims to automate this process with a neurosymbolic approach.
How we built it
Comps.ai is a three-stage neurosymbolic pipeline: Stage 1 (LLM Extraction) The user pastes or uploads an intercompany agreement. Claude reads the document and extracts structured facts into a strict Pydantic schema: company name, business function, target SIC codes, PLI metric, reported margin, and revenue estimate. The system prompt constrains the model to behave as a transfer pricing analyst -> conservative extraction, no inferred financials, null over hallucination.
Stage 2 (Comparable Search Engine (SEC EDGAR)) The pipeline queries the SEC's EDGAR database using the extracted SIC codes. It pulls candidate companies from EDGAR's company index, retrieves their XBRL-tagged financial statements (revenue, operating income, gross profit), and computes 3-year weighted average PLI ratios. Every candidate passes through a multi-rule screening filter.
Every rejected company is logged with the specific rule and reason. This rejection log is a first-class output meant to appease practitioners of TP with the quality of the screening methodology.
Stage 3 (Symbolic Reasoning Engine (Deterministic TNMM)) No LLM touches this stage. The engine sorts comparable PLIs, computes the interquartile range using OECD-specified interpolation, runs the arm's length test, and flags any suggested adjustment. The math is exact and auditable: IQR=[Q1,Q3],Q1=percentile25(PLI),Q3=percentile75(PLI)\text{IQR} = [Q_1, Q_3], \quad Q_1 = \text{percentile}{25}(\mathbf{PLI}), \quad Q_3 = \text{percentile}{75}(\mathbf{PLI})IQR=[Q1,Q3],Q1=percentile25(PLI),Q3=percentile75(PLI) The output is a professional report with six sections: tested party summary, selected comparables table, rejected comparables with reasons, IQR calculation, PASS/FAIL result with visualization, and a methodology disclosure.
Challenges we ran into
EDGAR is not built for programmatic use. The SEC's full-text search API and ATOM feeds have inconsistent response formats and undocumented behavior around SIC code filtering. In order to get reliable comparable company discovery, I had to iterate through multiple API strategies. I ended up combining approaches for robustness.
The comparable selection problem is harder than the math. The IQR calculation is trivial, but the hard part is determining which companies are truly comparable, which is where the domain expertise and professional judgment lives. I scoped the PoC to handle the deterministic screening rules (SIC, revenue band, data quality) and explicitly positioned the output as a "first-pass analysis requiring practitioner review" in order to justify the scope.
Accomplishments that we're proud of
Understanding the domain enough where I figured out where to build what was interesting. Proud of being able to put something together there.
What we learned
Learned a lot about transfer pricing, and some implementation details when combining LLMs with determinism.
Built With
- claude
- company-submissionssymbolic-enginenumpy-(iqr-calculation)
- css3
- custom-python-rules-modulebackendfastapi
- fastapi
- full-text-search
- html
- javascript
- matplotlibfrontendvanilla-html/css/js
- pydantic
- pydantic-v2data-sourcesec-edgar-xbrl-api
- python
- server-sent-events-(sse)pdf-generationweasyprint-/-html-fallback-with-jinja2document-parsingpdfplumberhttp-clienthttpx-(async)data-processingpandas
- uvicorn

Log in or sign up for Devpost to join the conversation.