-
-
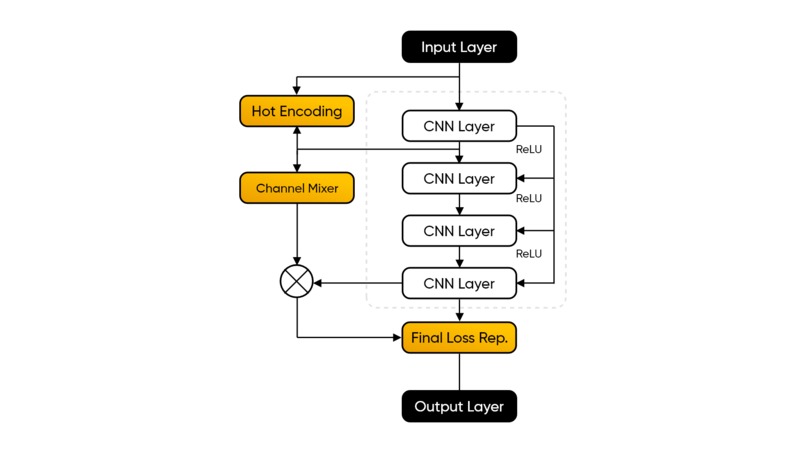
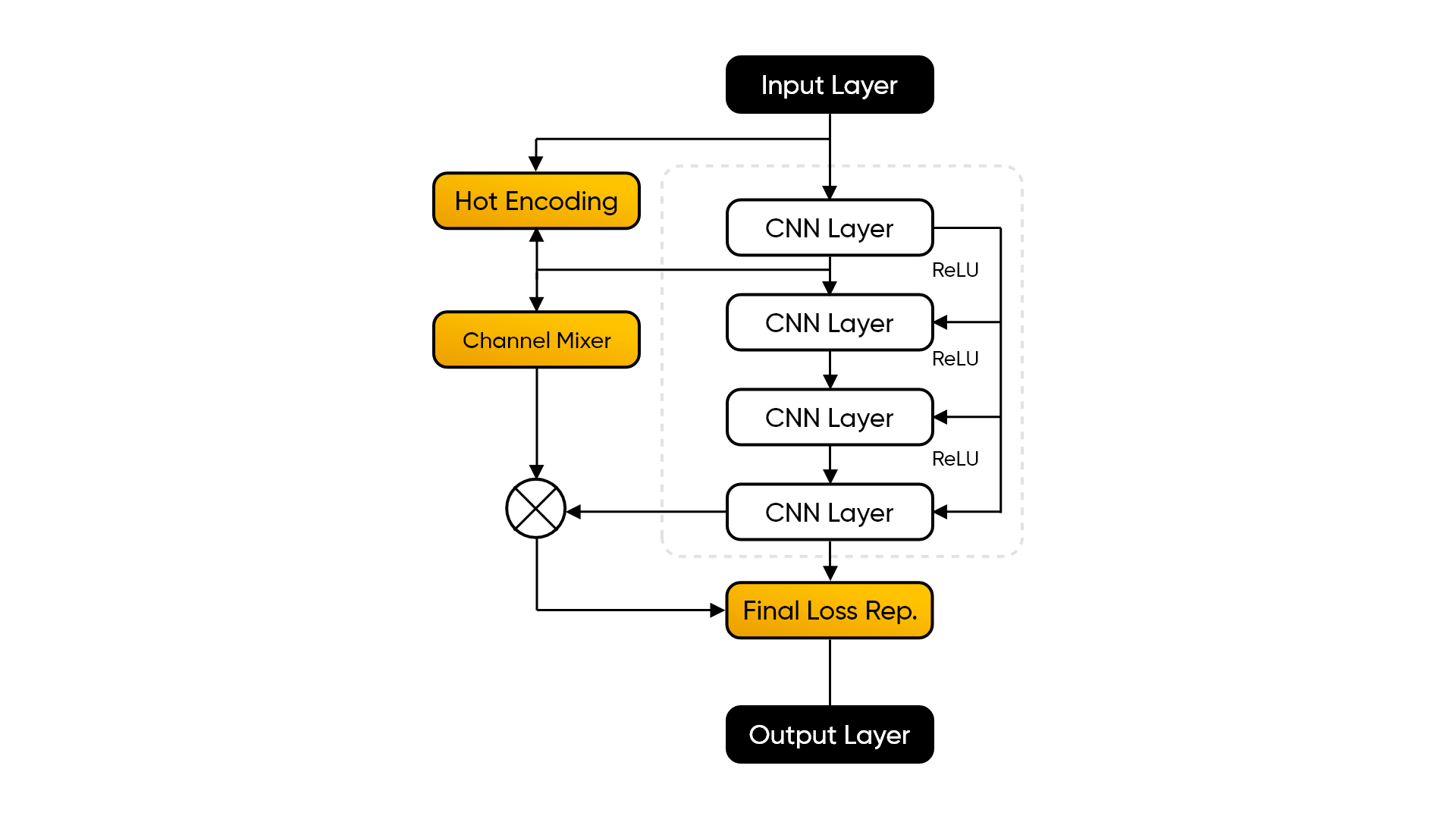
ML Model FLowchart
-

Uncompressed 1
-

Compressed 1
-

Uncompressed 2
-

Compressed 2
-

Uncompressed 3
-

Compressed 3
-

Uncompressed 4
-

Compressed 4








Inspiration
With the exponential increase of data-driven business intelligence, the current growth to meet the necessary storage capacity, at some point will underweight and hinder the entire analysis chain, not to forget about all the genocidal and environmental footprints it leaves behind with its maintenance and certain other factors that adversely impact the human lives. Until we have the most optimal compression algorithms or storage capacity worth one human brain, our project is to the rescue! Setting behind the drawbacks found in ordinary compression algorithms to suppress the essential value of any image while decompression, our algorithm provides an 87% accuracy to extract any image with all its necessary attributes intact, yet catered under smaller size.
What it does
We aim to contribute in tech with environment in heart.
Compresso at its core, using AI, does the image compression based on attribute scaling that will make sure that all the important segments of an image are restored as per the original image, yet scaling down the image size by underweighting the useless pixels in an image.
We have an added quality feature, where the compression can be self-adjusted on the scale of 1-100 keeping in mind, an equivalent loss of attributes in the image. letting users choose between size or quality.
"Save space to save every capture that matters." - Team Compresso
How we built it
We used the Local Residual Learning approach in a Biliniear2DUpSampling method in order to perceive an image which upon later convolutions with the original image through various layers in a standard CNN model, fetches us an interception image, basically, an attribute extracted image, which upon final convolution with original image renders a final image, that is attribute centric yet smaller in size.
We have used PyTorch standard CNN to supplement our machine learning model, to generate and train on YOLO v3 dataset to learn how to detect important features in an image. Our custom model is based on few phenomenal research papers we have gone through to get a clear idea about how local residual learning is the best fit for such application.
Speaking about technology stack;
OpenCV = For extracting the image pixel values to matrix dimensions
NumPY = For processing out matrix dimensions to AI algorithm
PyTorch = For AI algorithm processing and extracting to pixel values
Challenges we ran into
Understanding each layer associated with the Local Residual Learning approach and how to customize them to supplement with an additional set of hyperparameters to tune the image as per user requirement.
Adding a command prompt support to aggregate the user provides tweaks in terms of image path, quality as well a few other mandatory enhancements, required by the user.
In order to make this model work, we had come across tones of images that had an inverse ratio, meaning a sudden rise in image size, hence we have them labeled accordingly here, to ensure that we have covered them before our final deployment.
- Image with High resolution
- Image with Noisy/Useless attributes
- Image with Dull/Distorted quality
- Image with Bright/Blur Lens quality
- Image with unparalleled render quality i.e. old video camera footage
- Image with high context difference in adjacent pixels
Accomplishments that we're proud of
We are having a decent amount of accuracy on most of our tested images with attributes being intact. We have successfully accomplished a basic working prototype of this project that can accurately be tested on any platform.
What we learned
- Image Compression techniques
- Pytorch AI Modelling
- Local Residual Learning approach
- Machine Learning using CNNs
What's next for Compresso
Add a decent GUI to interact with the project and build the deployment with a bit faster result rendering.




Log in or sign up for Devpost to join the conversation.