-
-
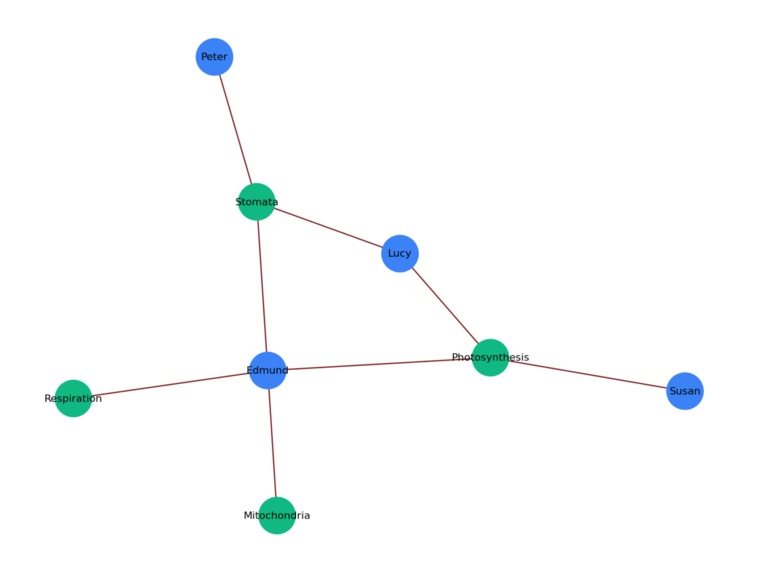
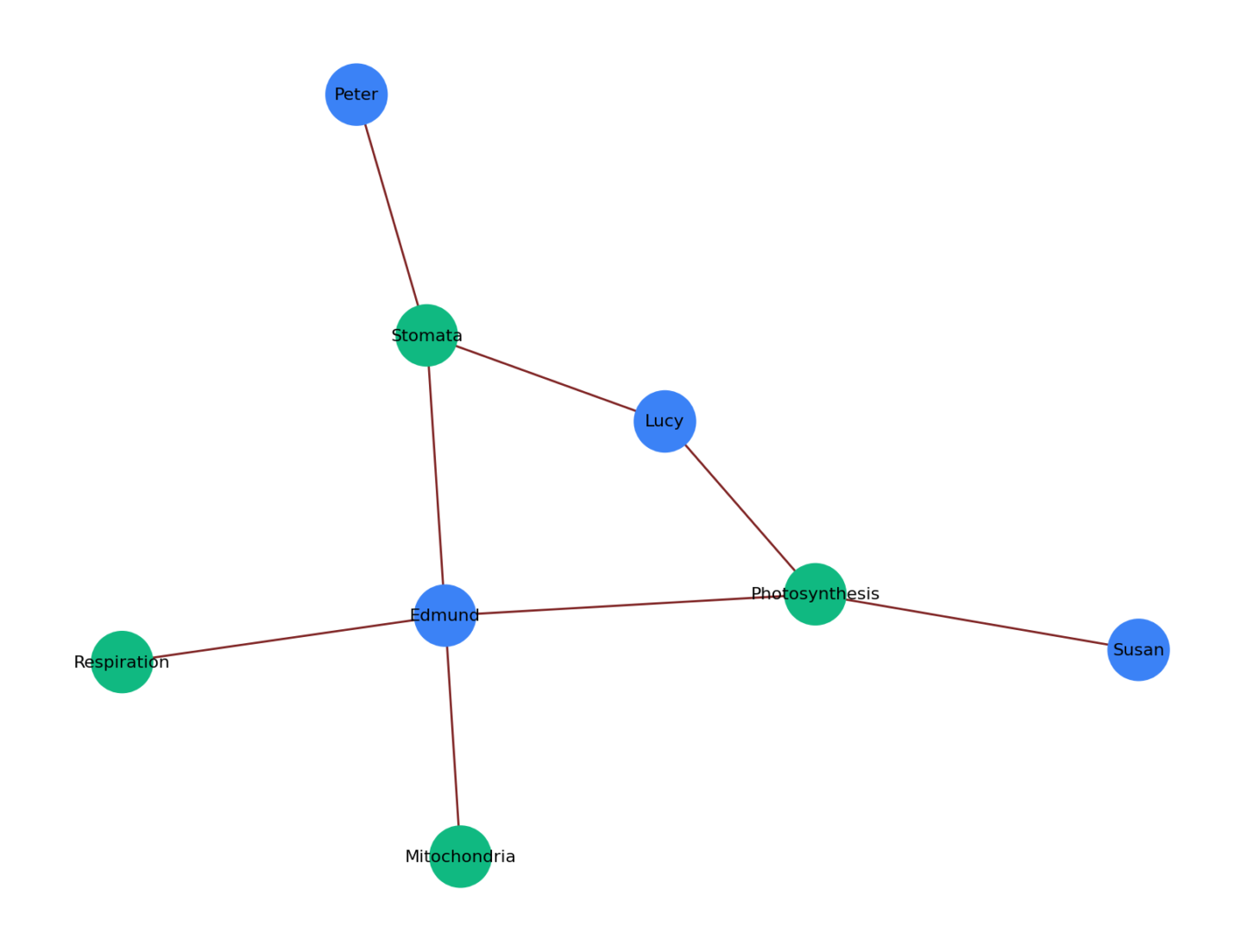
Knowledge graph Generated
-
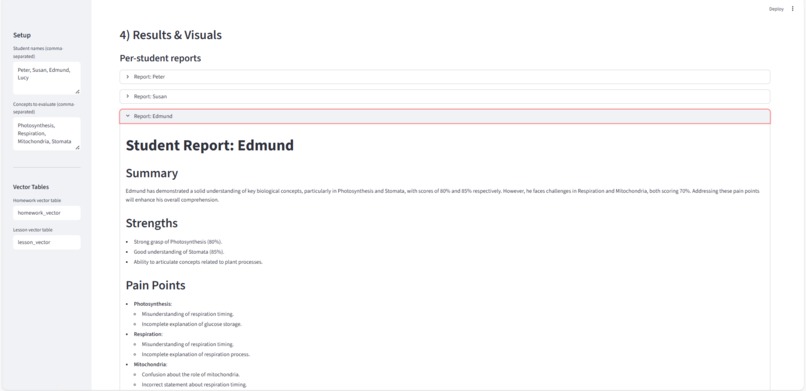
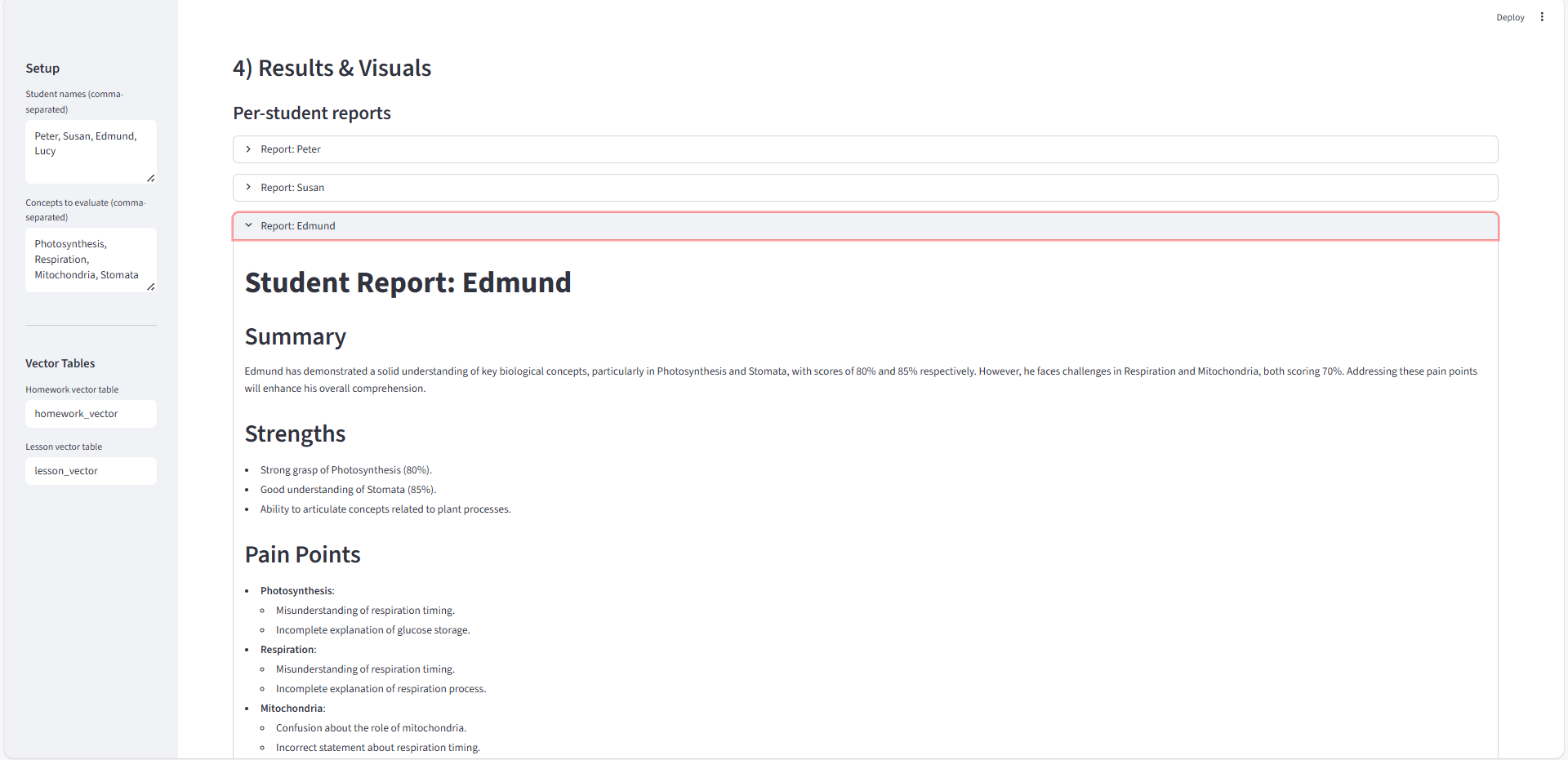
Comprehension Report
-
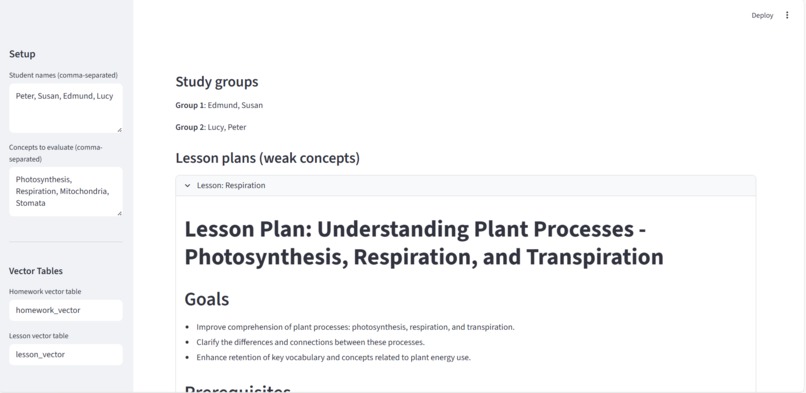
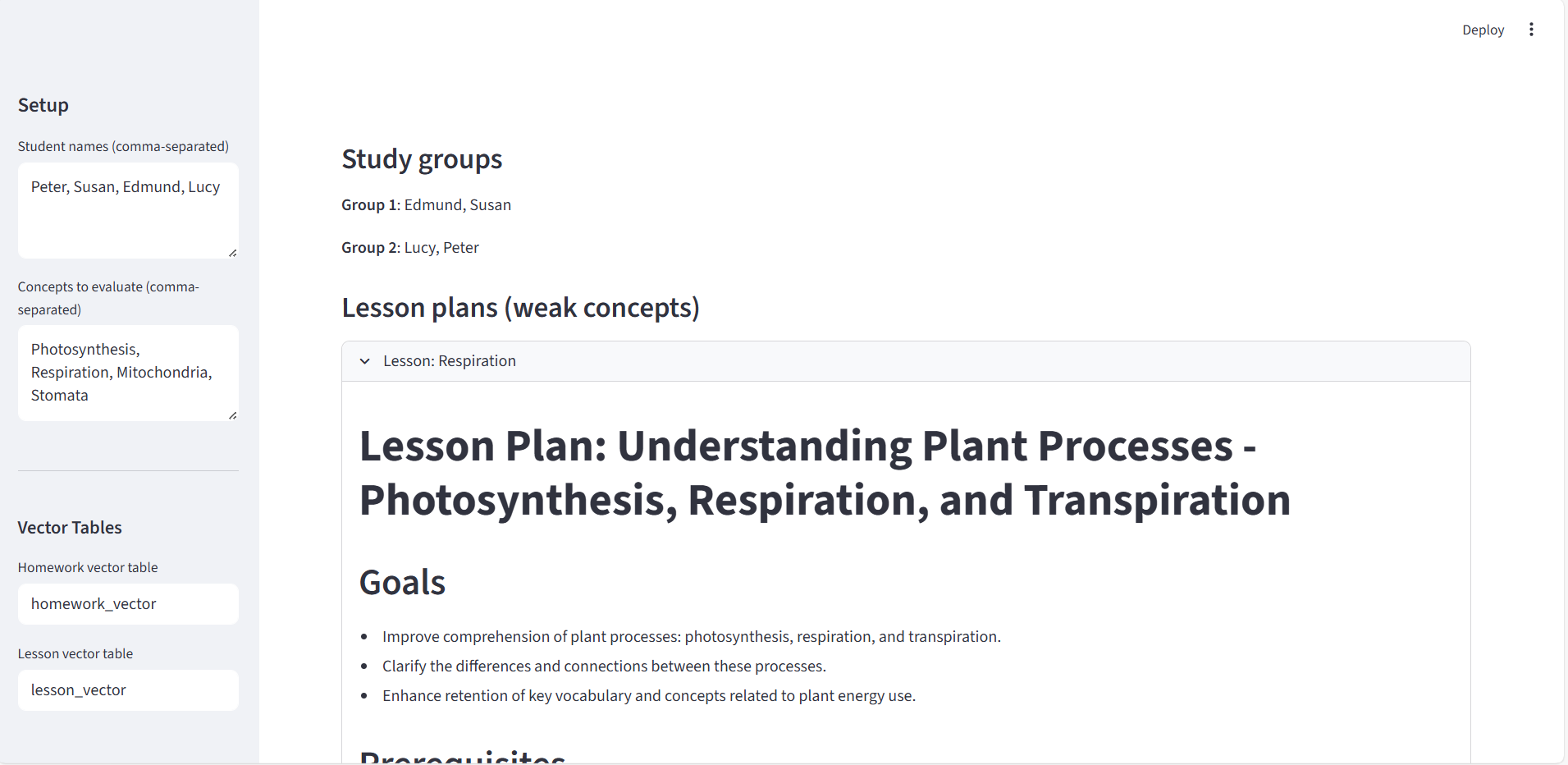
Lesson Plan Generated
-
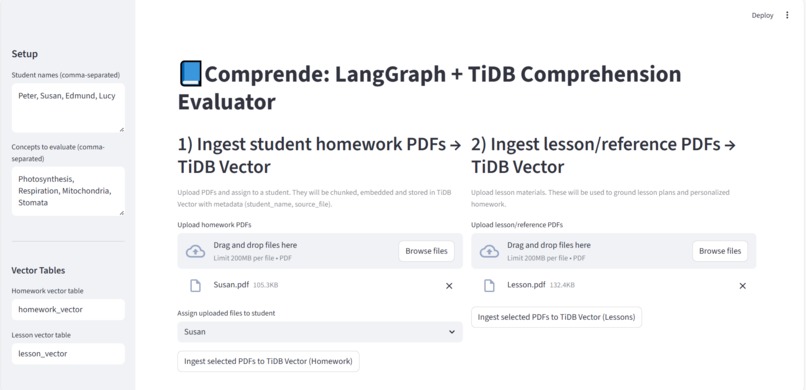
UI
-
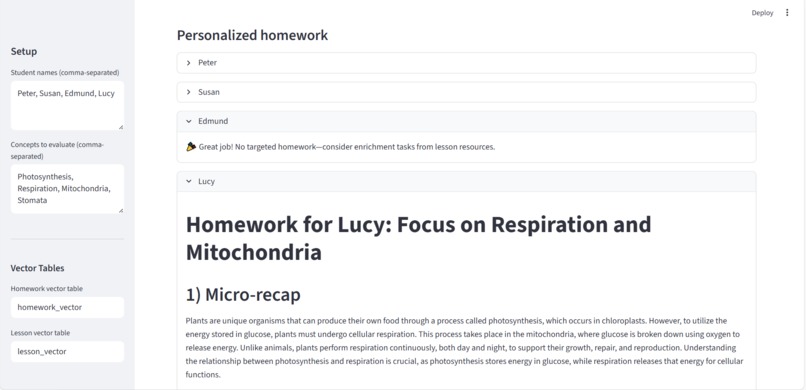
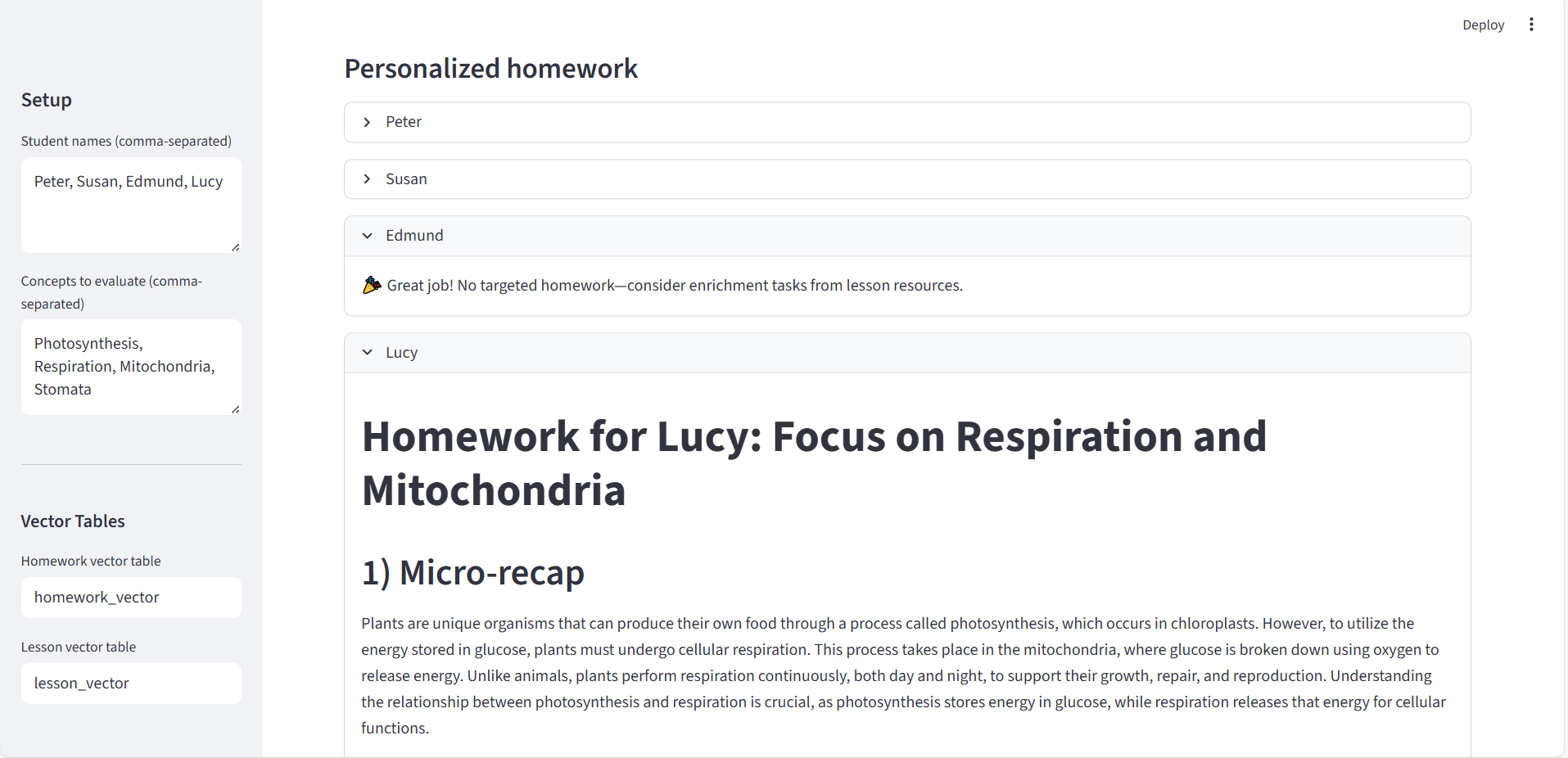
Personalized Homework based on comprehension

Inspiration
Public classrooms are overwhelmed—teachers are grading late into the night while class sizes grow, and the students who need targeted help the most are the ones least likely to get it. Globally, we face a shortage of ~44 million teachers by 2030, a crisis that makes truly personalized learning feel impossible. We built Comprende to give every student a guide and every teacher their time back—turning evidence from real student work into equitable action at classroom scale. In India alone, the sheer scale—24.8 crore students across ~14.7 lakh schools—demands tooling that is both human‑centered and technically robust.
What it does
Comprende is an agentic learning intelligence that runs a complete loop on TiDB Serverless + Vector Search:
- Ingests homework PDFs → embeds & stores them in TiDB Vector with JSON metadata (e.g., student_name).
- Retrieves concept‑specific evidence via metadata‑aware vector search (cosine/L2).
- Scores comprehension, builds a student↔concept knowledge graph, forms coverage‑aware study groups, designs a cohort lesson plan, and generates personalized homework—all orchestrated by LangGraph.
ROI & Social Good: Teachers gain hours per unit (automated assessment + planning), students get targeted help, and schools get transparent analytics in one database—fewer brittle pipelines, faster retrieval with HNSW when scale demands it, and auditable outcomes that promote equity.
How we built it
- Agentic workflow: A LangGraph state machine executes multi‑step nodes: ingest → evaluate → report → knowledge‑graph & groups → lessons → personalized homework. Vector layer on TiDB:
- Homework & lesson chunks in TiDBVectorStore with cosine/L2 similarity; JSON metadata enables per‑student filtering at retrieval time. HNSW vector indexes added as data grows; validated with EXPLAIN showing annIndex: for KNN usage.
- Relational layer on TiDB: Normalized tables for students, concepts, comprehension scores, knowledge edges, study groups, lesson plans, and personalized homework—joins across vectors + facts live in the same DB.
- LLM layer: Rubric‑based scoring prompts with grounded snippets; lesson plans and homework generated from the lesson vector store.
- Developer experience: Where needed, we drop to the tidb-vector Python SDK (SQLAlchemy VectorType/VectorAdaptor) for explicit index management and KNN queries.
Challenges we ran into
- Index semantics vs. filtering: We learned that pre‑filtering in SQL KNN queries can bypass vector indexes; we adapted by retrieving KNN first (indexed) and then post‑filtering or using metadata filters supported by the vector store API.
- Latency at scale: Warm‑up and compaction affected ANN performance until HNSW was fully built; we monitored with INFORMATION_SCHEMA.TIFLASH_INDEXES and EXPLAIN.
- Grounded evaluation: Preventing hallucinations required tight chunking + metadata filters so scoring only used student‑specific evidence.
- Group optimization: Guaranteeing at least one “concept champion” per group needed a greedy coverage heuristic and persisted scores to validate.
Accomplishments that we're proud of
- A true multi‑step agent (not a single RAG call) that operationalizes an entire learning loop—exactly what the TiDB hackathon encourages.
- Single data plane on TiDB for vectors and relational analytics—clean, auditable joins instead of stitched services.
- Demonstrable scale‑ups with HNSW and plan transparency via EXPLAIN—easy to reason about and to measure.
- Open, reproducible approach aligned with Best Open Source expectations
What we learned
- TiDB Vector + JSON metadata is incredibly effective for student‑scoped retrieval—we can ask precise questions of the right evidence.
- ANN performance is observable: seeing annIndex: in the plan and monitoring index build progress gave us confidence in latency and recall trade‑offs.
- LangGraph makes agentic flows tangible: stateful nodes, human‑in‑the‑loop opportunities, and clarity for debugging complex steps.
What's next for Comprende - Educating our future
- LMS integrations (Google Classroom/Moodle) and teacher dashboards with cohort trends and concept mastery heatmaps.
- Human‑in‑the‑loop checkpoints in LangGraph for rubric overrides and moderation.
- Multi‑modal support (diagrams, lab photos) with additional vector columns; HNSW tuning by concept density.
- District pilots focused on underserved schools; publish equity‑focused outcomes and cost/time savings.
- Security & governance hardening on TiDB Cloud with better lineage and per‑student data access controls.
Built With
- langgraph
- python
- streamlit
- tidb

Log in or sign up for Devpost to join the conversation.