Compliance Sentinel: An Agentic, AI Red Team Approach for Proactive Geo-Compliance Risk Detection
Executive Summary Compliance Sentinel is a multi-agent AI system designed to proactively discover hidden geo-regulatory compliance risks in new and existing product features. Instead of just checking for known safeguards, our system acts as an AI "Red Team," generating adversarial threat scenarios based on legal texts and analysing internal documents (PRDs, TDDs) to find vulnerabilities that manual reviews might miss. By integrating a human-in-the-loop conversational interface, it not only flags issues but collaborates with product managers to resolve them, culminating in a formal, auditable executive report. This tool allows product managers to assess geo-specific compliance risks at the team level, encouraging distributed effort.
Core Submission Links Demonstration Video: https://youtu.be/2wA2C9oK1E4 Public GitHub Repository: https://github.com/Joshyxwa/AC-Acai Test Dataset Output CSV: https://docs.google.com/spreadsheets/d/1qJdWWik0_1xgWPefJbBLvoVcg6Eat3goa794utXJskA/edit?usp=sharing
The Problem Statement As a global platform, every product feature must comply with dozens of geographic regulations. The current process of manually identifying features that require geo-specific logic is slow, reactive, and prone to error, creating significant legal exposure and operational overhead. Our project addresses the need to turn this regulatory blind spot into a traceable, automated, and auditable output.
Our Solution: Compliance Sentinel We've built a sophisticated, multi-agent system that redefines compliance auditing from a passive check into a proactive, adversarial simulation.
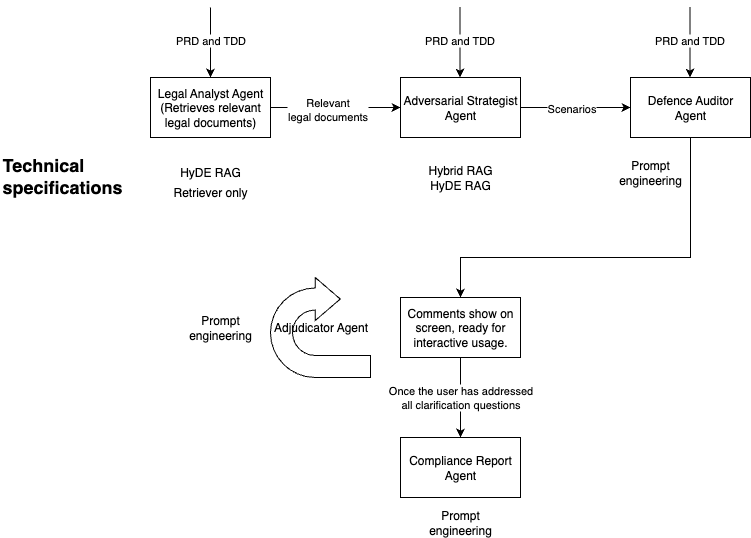
The Multi-Agent Architecture
Our solution is an orchestrated workflow between several specialised AI agents: Legal Analyst: Ingests and understands legal documents to identify relevant risks. Adversarial Strategist: Generates plausible, creative threat scenarios based on a feature's design and applicable laws. Defence Auditor: Scans internal PRDs and TDDs for documented safeguards to mitigate the generated threat. Adjudicator Agent: Manages the interactive conversation, asking clarifying questions when it finds gaps and critically evaluating human responses. Compliance Report Agent: Synthesises the entire audit, including all conversations, into a final, legally precise executive report.
The Multi-Agent Workflow
Legal Analyst The legal documents are embedded using “nlpaueb/legal-bert-base-uncased”, a BERT model finetuned on law datasets. Instead of using traditional chunking methods of max_tokens, we chunked based on individual law articles because we recognised the importance of capturing the nuances of each law.
We stored the embeddings in Supabase vectors, where they were indexed using HNSW and cosine similarity for search.
When a PDD or TRD is uploaded, legal documents that are relevant for this feature are retrieved using HyDE RAG. Traditional RAG methods immediately will embed the user query (feature description) and execute a cosine similarity search. However, we believe that this implementation, although it can retrieve laws on the same topic, might not retrieve the laws that it is potentially non-compliant. As such, HyDE allows us to generate a scenario that has a higher likelihood of retrieving the laws that are the most relevant in detecting non-compliance vulnerabilities.
Adversarial Strategist The retrieved legal documents are passed to the adversarial strategist. This agent has access to a database of historical examples of legal non-compliance by social media companies. Relevant news articles are retrieved using a hybrid RAG system, and appended to the prompt to generate more grounded ways in which the feature might have non-compliance issues.
Specifically: The news articles are embedded using the Qwen3-Embedding-8B model. This model was chosen because it ranks No. 1 in the MTEB multilingual leaderboard, and performs well at general embedding. The query is also embedded using the Qwen3-Embedding-8B model. A hybrid RAG is performed:
- Full Text Search
- Dense retrieval using the query
- Dense retrieval using HyDE Reciprocal Rank Fusion (RRF) is performed on all the retrieved data.
The adversarial strategist outputs a list of scenarios. This is then passed into the Defence Auditor.
Defence Auditor The Defence Auditor is a simple agent powered by context engineering. It analyses the PRD, TDD, threat scenario generated by the Adversarial Strategist agent, and articles of potential law broken.
This defence auditor goal is to determine if the given documented software feature has sufficient safeguards in ensuring it follows geo-specific compliance laws. After identifying the gap and weakness of different parts of the project’s TDD and PRD, it will formulate a clarification question that we hope for the project manager respond to. While certainly many features might be potentially compliant with all geo-specific laws, many documents often fail to highlight the details of their respective projects. This will lead to strong AI agents having high false positives and weak (naive) agents having high false negatives. We design a workflow where we encourage engineers and product managers to be detailed in their documentation, so that AI automated regulation checks can generate accurate results.
Adjudicator Agent This Adjudicator agent has a simple goal: To respond to the project manager’s queries and evaluate if issue can be closed. Moreover, provide clear reasons why the given feature is a compliance risk when project managers seek clarifications.
It used context engineering to synthesise various inputs to generate a comprehensive answer to the user.
Compliance Report Agent After the project manager decides to end the conversation, they can use the compliance report agent to generate a summary report that highlights the risks and issues found, so that other employees have a clear todo list to solve the issues raised.
Key Features & Innovations
Proactive Threat Generation: Instead of just classifying documents, our AI actively tries to "break" a feature's compliance, discovering unknown and second-order risks (like perverse incentives for minors). Interactive Human-in-the-Loop: When the AI finds a documentation gap, it doesn't just fail; it pauses the audit and asks the Product Manager for clarification via a conversational UI, creating a collaborative problem-solving loop. Legally-Grounded Analysis: The final report doesn't just state an opinion; it juxtaposes direct quotes from internal documents with the specific articles of the law being violated, creating an evidence-based argument. End-to-End Governance: The system manages the entire lifecycle, from initial audit to interactive clarification to the final, auditable Markdown report, providing a complete governance solution.
- Technical Implementation Details Development Tools & Languages: Python, Visual Studio Code APIs Used: Anthropic API (Claude 4.1 Opus, Claude 4 Sonnet and Claude 3.5 Haiku models) Google AI Studio API (Gemini 2.5 Flash) Supabase API (for database interactions) Key Libraries Used: Pydantic Gemini Anthropic Torch Transformers Vecs Re Database: Supabase (PostgreSQL, pgvector)
Additional Datasets: 1) Crawl for news articles on social media companies' non-compliance laws Prompt used for online news scraper:
“help me to find 50 news paper articles, law articles, reports, texts on different ways that tech companies have broken laws (focusing on social media related) i want the final format in a csv file with the following columns
law that was broken
company breaking the law
FULL text from the article/reports/text found on the internet
link to the source (make sure the link works)“
2) Legal texts of the EU Digital Service Act, California state law - Protecting Our Kids from Social Media Addiction Act, Florida state law - Online Protections for Minors, Utah state law - Utah Social Media Regulation Act, US law on reporting child sexual abuse content to NCMEC - Reporting requirements of providers
Impact & Business Value Our solution directly addresses the three core requirements of the problem statement: Reduces Governance Costs: By automating the initial deep-dive analysis of product specs, we drastically reduce the manual effort required from legal and compliance teams. Mitigates Regulatory Exposure: The proactive, adversarial approach is designed to find the non-obvious vulnerabilities that could lead to significant fines before a feature is ever launched. Enables Audit-Ready Transparency: The final, auto-generated report serves as a complete, time-stamped audit trail, proving that due diligence was performed and providing clear, defensible evidence for regulators.
Sample Output on a PRD and TDD
[{'title': 'Insufficient bias prevention safeguards for AI-generated filters targeting minors', 'evidence': '{"prd": ["Content creation is the engine of our platform, but users often face \"creator\'s block.\" Our current filter library, while extensive, is manually curated and can feel stale. To inspire creativity and increase content production, we need a system that can generate a near-infinite variety of novel, personalized video effects in real-time.", "Primary Goal: Increase the daily number of videos created using a filter by 15%.", "The recommendation engine will achieve a click-through rate (CTR) of 30% on the top 5 recommended filters."], "tdd": ["Stage 2: Ranking A deep learning collaborative filtering model will be trained to predict the probability of a user interacting with a given filter. The model inputs will include the user\'s ID, their historical interaction with other filters, and their general content viewing history. The output will be a ranked list of filters, sorted by the highest predicted engagement score. This is the only ranking method that will be implemented.", "The generative model will be trained on a pre-screened dataset to prevent the creation of unsafe or offensive visual effects. A static blocklist of prompts will be used internally during generation. All generated filters will be assigned a T2 (Tier 2) sensitivity score by default."]}', 'reasoning': "The documented safeguards are insufficient to address discriminatory beauty standards that could harm minors. While the TDD mentions 'pre-screened dataset' and 'static blocklist,' it provides no specific measures to prevent bias amplification or discriminatory beauty standards. The collaborative filtering model using historical interaction data could perpetuate existing societal biases. Most critically, there are no age-specific protections for the 13-17 demographic mentioned in the threat, despite EU DSA Article 157's explicit requirement to protect minors from discriminatory actions.", 'clarification_question': "The documentation mentions a 'pre-screened dataset' for training but doesn't specify how bias related to facial features, skin tones, or beauty standards is prevented. Given that minors aged 13-17 are particularly vulnerable to discriminatory beauty standards, what specific bias detection and mitigation measures are planned to ensure AI-generated filters don't promote discriminatory appearance alterations that could violate EU DSA protections for minors?"}]
--- Auditing with LLM --- --- Audit Complete --- [{'title': 'Missing GDPR consent mechanism for AI training on user data', 'evidence': '{"prd": ["Primary Goal: Increase the daily number of videos created using a filter by 15%.", "FR-2: High-Quality Personalization The filters presented to a user must be highly relevant and personalized. The recommendation algorithm should be the core of the feature, learning from user interactions to continuously refine its suggestions and maximize engagement."], "tdd": ["Stage 2: Ranking A deep learning collaborative filtering model will be trained to predict the probability of a user interacting with a given filter. The model inputs will include the user\'s ID, their historical interaction with other filters, and their general content viewing history. The output will be a ranked list of filters, sorted by the highest predicted engagement score. This is the only ranking method that will be implemented.", "No new primary database tables are required. The generated filter parameters will be stored in a vector database for efficient retrieval. User interaction events (impressions, clicks, usage) will be logged to the main analytics event stream and tagged with the AIFilterInteraction event name."]}', 'reasoning': 'The TDD explicitly describes collecting user IDs, historical interactions, and content viewing history for AI model training, while logging all user interactions to analytics streams. However, neither the PRD nor TDD documents any consent mechanisms, opt-in processes, or legal basis considerations for using this personal data for AI training purposes. This creates a significant GDPR compliance gap, as using personal data for AI training typically requires explicit consent or a clearly established legitimate interest with proper balancing tests.', 'clarification_question': "The documentation shows extensive collection of user behavioral data (user IDs, interaction history, viewing patterns) for AI model training, but doesn't mention any consent mechanisms or legal basis under GDPR. How do we plan to obtain proper user consent or establish legitimate interest for using this personal data to train our AI models, especially for EU users?"}]
--- Auditing with LLM --- --- Audit Complete --- [{'title': 'Lack of A/B Testing Disclosure and Consent Mechanisms', 'evidence': '{"prd": ["span6", "span7", "span9", "span10", "span11"], "tdd": ["span35", "span36"]}', 'reasoning': 'The TDD explicitly states that 5% of users in Australia and UK will be subjected to A/B testing with session time as the primary metric, but neither document mentions informed consent, disclosure of experimental participation, or opt-out mechanisms. This violates transparency obligations under GDPR Article 5(1)(a), DSA transparency requirements, and consumer protection laws in the targeted jurisdictions.', 'clarification_question': "The documentation shows A/B testing will be conducted on 5% of users in Australia and UK, but there's no mention of how users will be informed they're participating in an experiment or given the option to opt out. What disclosure and consent mechanisms will be implemented to ensure compliance with GDPR, DSA transparency obligations, and local consumer protection laws?"}, {'title': 'Engagement-Optimized Algorithm Without User Wellbeing Safeguards', 'evidence': '{"prd": ["span6", "span7", "span18"], "tdd": ["span12", "span24", "span25"]}', 'reasoning': "The system is designed to maximize engagement through personalized recommendations with engagement scores (0.98, 0.95) that nudge users toward high-engagement content. The PRD explicitly states the goal is to 'maximize engagement' and increase session time, but provides no safeguards against addictive design patterns or protection for vulnerable users like minors. This creates dark patterns that may violate DSA Article 157's requirements for user safety and protection of minors.", 'clarification_question': "The recommendation system is designed to maximize engagement and session time, but there are no documented safeguards against addictive design patterns or special protections for minors and vulnerable users. How will the system ensure compliance with DSA Article 157's requirements for user safety, particularly for minors who may be more susceptible to manipulative engagement optimization?"}, {'title': 'Insufficient Content Safety Framework for AI-Generated Filters', 'evidence': '{"prd": ["span20"], "tdd": ["span31", "span32"]}', 'reasoning': "The safety implementation relies only on pre-screened training data, a static blocklist, and default T2 sensitivity scores. There are no real-time content moderation systems, human oversight for generated content, or mechanisms to detect harmful filters that may bypass the static safeguards. This is insufficient to ensure the 'safe and transparent online environment' required by DSA Article 157, especially when the system prioritizes engagement over safety.", 'clarification_question': "The safety measures described include only pre-screening training data and static blocklists, but there's no mention of real-time content moderation or human oversight for AI-generated filters. Given that the system optimizes for engagement and targets users across different jurisdictions with varying safety standards, what additional safety mechanisms will ensure harmful or inappropriate filters don't reach users, particularly minors?"}]
Built With
- anthropic
- python











Log in or sign up for Devpost to join the conversation.