-
-
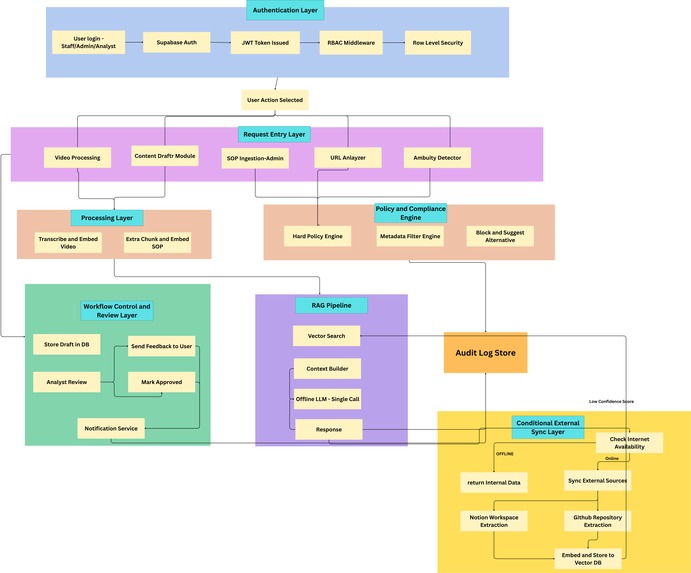
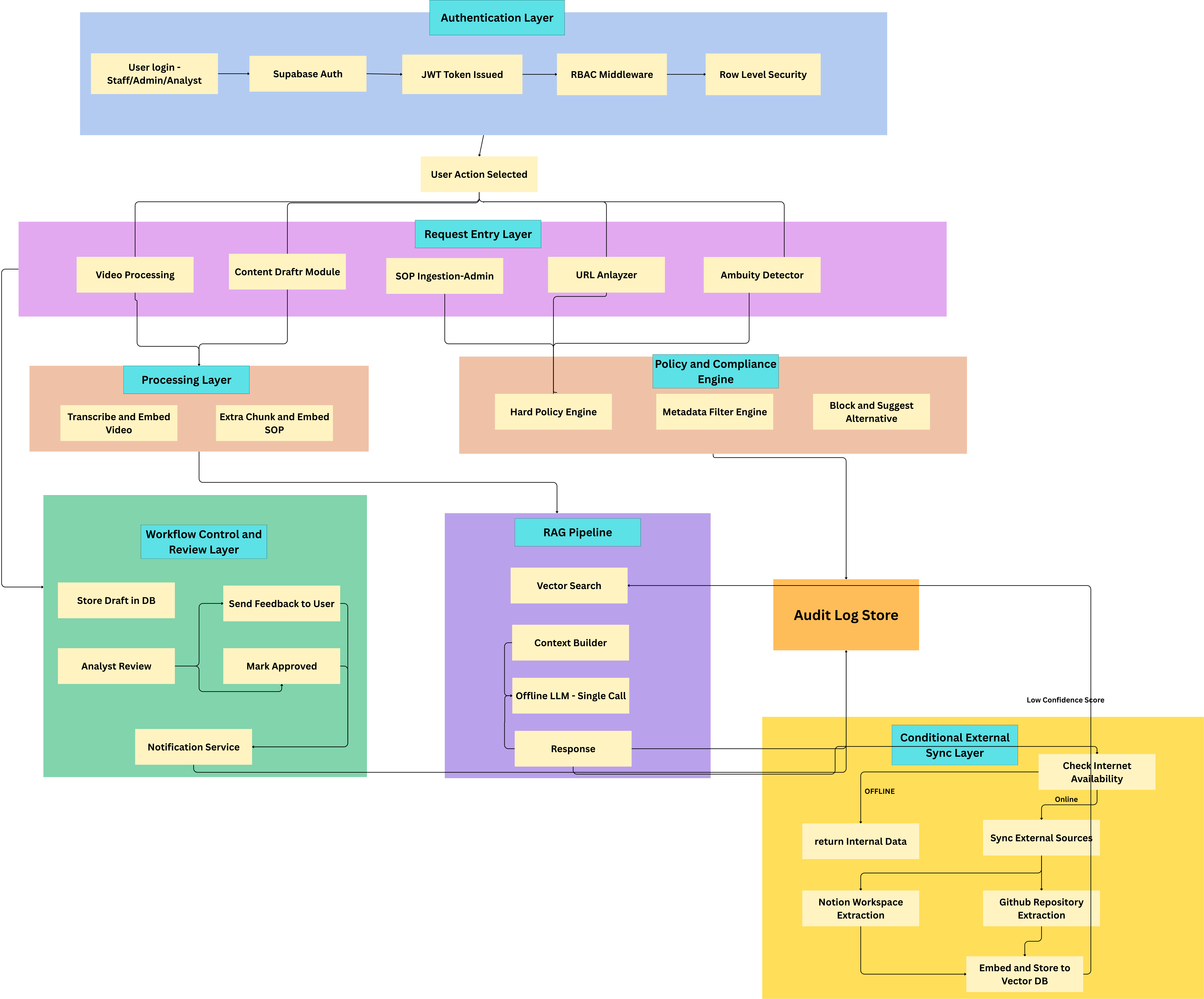
Architechture
-
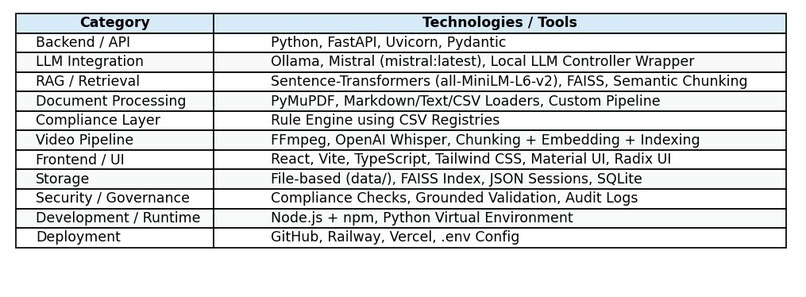
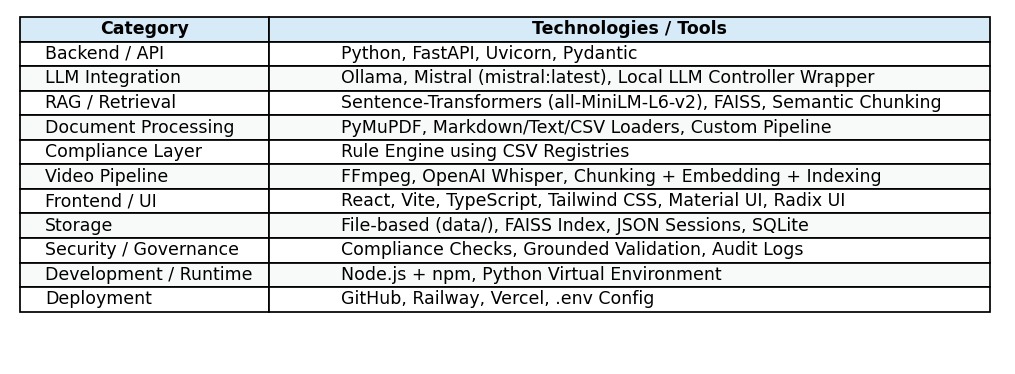
Tech Stack Used
Inspiration
In modern enterprises, the volume of internal knowledge—policies, SOPs, technical documentation, compliance guidelines, and informal communication—has grown beyond what traditional systems can effectively manage. Employees frequently spend significant time searching across fragmented platforms such as document repositories, chat tools, and internal wikis, often leading to inconsistent interpretations and delayed decision-making. This inefficiency is not merely operational—it introduces compliance risks, knowledge silos, and decision ambiguity, especially in regulated environments.
A critical gap we observed is that most AI-powered assistants available today rely heavily on external APIs and generalized knowledge models, which are not aligned with enterprise requirements for data privacy, traceability, and policy adherence. Organizations handling sensitive data cannot afford to expose internal information to third-party services, nor can they rely on AI systems that generate responses without strict grounding in verified internal documents. The risk of hallucinated or non-compliant responses makes such solutions unsuitable for real-world enterprise deployment.
We were particularly motivated by three recurring challenges:
Lack of Trust in AI Outputs: Existing AI tools often generate responses without clear traceability to source documents, making them unreliable in compliance-heavy scenarios.
Data Security Concerns: Enterprises require systems that operate entirely within their infrastructure, ensuring zero external data exposure.
Operational Inefficiencies: Employees and analysts repeatedly perform manual lookups, validations, and cross-referencing across multiple systems.
This led us to ask a fundamental question: Can we design an AI assistant that is not just intelligent, but also compliant, explainable, and fully secure within an enterprise environment?
The result is our Compliance-First Enterprise AI Assistant—a system built from the ground up with privacy, governance, and reliability as core principles, rather than afterthoughts. Instead of treating compliance as a constraint, we treat it as a design foundation. Every query is validated before processing, every response is grounded in verified internal knowledge, and every interaction is logged for auditability.
Our inspiration was not to build another chatbot, but to create a trusted decision-support system—one that organizations can confidently deploy in real-world environments where accuracy, accountability, and security are non-negotiable.
What it does
The Compliance-First Enterprise AI Assistant redefines how organizations interact with their internal knowledge — delivering secure, policy-aligned, and fully traceable intelligence in real time. Built not just to answer questions, but to power reliable decision-making in environments where accuracy, compliance, and data confidentiality are non-negotiable.
🔍 Intelligent & Context-Aware Query Processing
Every query passes through a rigorously engineered pipeline before a single word of response is generated:
- Intent Understanding & Ambiguity Detection — clarifies what the user truly needs before processing begins
- Pre-Response Compliance Validation — intercepts unsafe or policy-violating inputs at the gate
- Hierarchical RAG Retrieval — surfaces only the most relevant, version-controlled internal data
- Controlled LLM Reasoning — produces grounded, context-rich responses with zero hallucination tolerance
No guesswork. No shortcuts. Every output is relevant, verified, and compliant.
🧠 Trusted, Grounded & Explainable AI
This system operates on a closed knowledge loop — a fundamental departure from conventional AI:
- Responses draw exclusively from approved, verified internal sources
- Every answer carries traceable citations and exact source references
- A dedicated Hallucination Detection & Removal Layer strips unsupported claims before output
This transforms the assistant from a probabilistic tool into a deterministic, auditable intelligence engine — one that enterprise users can genuinely rely on.
🛡️ Compliance as a Core System Function
Compliance isn't bolted on — it's woven into every layer of the system architecture:
- Pre-query policy enforcement blocks risky interactions before the LLM is ever invoked
- Hard Policy Engine ensures strict, real-time adherence to organizational rules
- Structured Response Formatting delivers outputs with:
- Risk level classification
- Policy references and justifications
- Compliant alternatives when a query is flagged
Every response is not just informative — it is defensible.
🔐 Fully Secure, Offline-First Deployment
Engineered for environments where data sovereignty is paramount:
- Runs entirely on local infrastructure — no cloud, no third-party APIs
- Zero external data exposure by architectural design
- Suitable for regulated industries including finance, legal, healthcare, and defense
If your data cannot leave the building — this system was built for you.
📚 Unified Knowledge Intelligence Layer
The assistant dissolves information silos by consolidating enterprise knowledge into one intelligent, queryable system:
| Source | What It Captures |
|---|---|
| SOPs & Policy Docs | Operational standards and governance rules |
| GitHub Repositories | Technical documentation and version history |
| Notion Workspaces | Structured project notes and internal wikis |
| Telegram Channels | Operational discussions and decision context |
| Reddit Posts | External opinions and community insights |
| Video Transcriptions | Meeting recordings and training content via Whisper |
All sources pass through secure ingestion → semantic embedding → metadata tagging, enabling precise, context-aware retrieval at query time.
⚙️ Governance-Driven Workflow
Accountability is built into the response lifecycle itself:
- Outputs can route through an Analyst Review Layer before reaching the end user
- A structured Draft → Review → Approve workflow enforces editorial quality control
- Integrated feedback loops continuously refine retrieval accuracy and model behavior over time
Automation with oversight — not automation instead of it.
📊 Full Auditability & Decision Traceability
Every interaction leaves a traceable, unalterable record:
- Answers are linked to exact document chunks from the knowledge base
- A 7-year immutable audit log captures every query, response, and decision
- Enables frictionless compliance audits and decision reviews on demand
No decision made through this system is ever without evidence.
🔄 Adaptive Hybrid Capability
While built for offline-first operation, the system stays current:
- Conditionally syncs with external sources when network connectivity is detected
- Knowledge bases update seamlessly without compromising security or availability
- Self-improves via admin updates, audit log analysis, and feedback-driven indexing
Always controlled. Always current.
🚀 Organizational Impact
| Impact Area | Outcome |
|---|---|
| Speed | Information retrieval drops from minutes to seconds |
| Risk Reduction | Proactive compliance enforcement catches issues before they escalate |
| Operational Efficiency | Eliminates manual validation and reduces HR/admin overhead |
| Decision Quality | Evidence-backed, traceable outputs replace gut-feel decisions |
| Data Security | Zero external exposure — complete internal sovereignty |
This isn't just an AI assistant. It's a compliance-grade intelligence layer for the modern enterprise.
How we built it
We built the Compliance-First Enterprise AI Assistant as a fully offline, policy-aware RAG (Retrieval-Augmented Generation) system designed for deterministic behavior, strict compliance enforcement, and complete auditability. The implementation emphasizes controlled data flow, grounded reasoning, and modular system design — ensuring that every response is traceable, verifiable, and aligned with enterprise policies.
🏗️ System Architecture & Execution Flow
The system is structured as a layered pipeline architecture, where each stage performs validation and transformation before passing data forward. Execution is strictly enforced to prevent uncontrolled model behavior:
User Query
→ Intent & Ambiguity Detection
→ Pre-Compliance Validation
→ Query Embedding
→ Vector Search (ChromaDB)
→ Metadata Filtering
→ Context Assembly
→ Offline LLM Inference
→ Post-Processing & Validation
→ Structured Response Output
No query ever reaches the model without first clearing compliance and retrieval constraints.
💻 Frontend Layer — React.js
The frontend is built with React.js, providing a structured, role-aware interface tailored to each user type:
- Staff — submit queries and view structured responses
- Analyst — review and validate system-generated outputs
- Admin — manage ingestion pipelines and system controls
Key capabilities:
- Query submission with lifecycle tracking
- Structured response display including source citations, risk levels, and compliance flags
- Workflow state visualization: Draft → Review → Approved
- Communicates with the backend via secure REST APIs
⚙️ Backend & Orchestration Layer — FastAPI
The backend is implemented in FastAPI, chosen for its asynchronous execution model and high throughput:
- Acts as the central orchestration engine across all pipeline stages
- Manages request routing, pipeline execution, and module integration
- Uses async processing for embedding generation, vector retrieval, and LLM inference
- Enforces strict sequential execution to maintain pipeline integrity
🔐 Authentication & Access Control
Security is enforced across every entry point:
- Supabase Authentication with JWT-based session management
- Role-Based Access Control (RBAC) — Staff, Analyst, and Admin roles
- Row-Level Security (RLS) at the database layer ensuring fine-grained, query-level data isolation
Access is earned by role — not assumed by default.
🔄 Pre-Processing & Compliance Layer
Before entering the AI pipeline, every query undergoes multi-stage validation:
- Intent Detection — classifies query type and purpose
- Ambiguity Detection — identifies vague or incomplete inputs
- Pre-Compliance Validation — checks against restricted actions, sensitive entities, and organizational policies
If a violation is detected:
- The query is blocked or modified
- The system generates policy-compliant alternatives
Zero unsafe queries reach the LLM — by design.
📚 Knowledge Ingestion Pipeline — ETL
A multi-source ingestion pipeline standardizes all enterprise data into a unified, queryable format.
Data Sources:
| Source | Content Type |
|---|---|
| SOPs & Policy Docs | Governance rules and operational standards |
| Notion Workspaces | Structured notes and internal wikis |
| GitHub Repositories | Technical docs and version history |
| Telegram Channels | Operational discussions and decisions |
| Reddit Posts | External insights (lower priority) |
| Video Content | Transcribed via Whisper speech-to-text |
Pipeline Steps:
Extraction → Cleaning → Normalization → Chunking
→ Metadata Tagging → Embedding → Storage
Technical Details:
- Adaptive chunking — combines semantic boundaries with token limits
- Metadata tagging — source type, timestamp, version, author, priority
- Normalization — converts heterogeneous formats into a consistent structure
🧠 Embedding & Vector Search — ChromaDB
- Query and document embeddings are generated using local embedding models
- Stored in ChromaDB for efficient similarity search
Retrieval Process:
- Top-K nearest neighbor search with metadata-based filtering
- High-authority sources (e.g., SOPs) are prioritized during retrieval
- Hierarchical retrieval strategy ensures relevance and contextual accuracy
Precision-focused retrieval — essential for compliance-driven use cases.
🧩 Context Engineering Layer
Retrieved data is transformed into a structured prompt context before inference:
- Aggregates relevant document chunks, source references, and policy constraints
- Applies context ranking and pruning to stay within token limits
- Ensures only high-confidence, relevant data is passed to the LLM
This step is the bridge between retrieval and deterministic output generation.
🖥️ Offline LLM Inference Layer
- Uses locally hosted LLMs via Ollama runtime — no external API calls, ever
- Full data privacy guaranteed by architectural isolation
Inference Strategy:
- Single-pass generation with strict context-bound reasoning
- Controlled prompt templates for consistent, predictable outputs
Optimization:
- Quantized models for reduced memory footprint
- Designed to run on standard 8–16GB RAM systems
🚫 Post-Processing & Validation
After generation, every response passes through a final validation layer:
- Hallucination Detection — cross-checks response against retrieved context and removes unsupported claims
- Compliance Re-Validation — ensures the final output adheres to all active policies
- Structured Formatting — appends citations, risk levels, and policy references before delivery
The response is only as good as what can be proven.
⚙️ Workflow & Governance Layer
Implements a controlled response lifecycle with human-in-the-loop oversight:
Draft → Analyst Review → Approval → User Delivery
- Responses are initially stored as drafts
- Analysts can review, edit, approve, or reject outputs
- Feedback flows back into the system to improve retrieval quality and performance over time
🗄️ Storage & Audit Logging
Storage Components:
| Layer | Technology | Purpose |
|---|---|---|
| Vector Store | ChromaDB | Embeddings and metadata |
| Relational DB | PostgreSQL (Supabase) | Users, roles, workflow states, query logs |
Audit Logging captures:
- User query
- Retrieved context chunks
- Final response output
Immutable logs maintained for up to 7 years — enabling full compliance audits and decision traceability.
🔄 Hybrid Sync Mechanism
The system continuously checks for internet availability and adapts accordingly:
- Online — syncs updated data from Notion, GitHub, and other connected sources
- Offline — operates fully from the local knowledge base without degradation
Data freshness without ever compromising security or sovereignty.
Challenges we ran into
Building a Compliance-First Enterprise AI Assistant meant navigating the tension between accuracy, compliance, and performance — all under strict operational constraints. These weren't surface-level integration challenges; they were fundamental architectural problems that shaped every design decision.
🧱 Hallucination-Free Responses on a Closed Knowledge Loop
Ensuring the system never fabricates information — while restricting it exclusively to internal, approved data — required more than prompt engineering:
- Building a dedicated hallucination detection and removal layer that strips unsupported claims before output
- Designing a fully grounded RAG pipeline with no fallback to external knowledge
- Validating every response against exact document chunks, not just semantic similarity
Getting the model to say "I don't know" accurately was harder than getting it to answer.
⚡ Offline Performance Under Resource Constraints
Running a capable LLM entirely on local infrastructure — with no cloud offloading — introduced real hardware pressure:
- High memory consumption of local LLM models on standard enterprise hardware
- Latency across the full pipeline — embedding, retrieval, and generation — all happening sequentially on-device
- Optimizing the embedding + retrieval + generation chain without sacrificing response quality
Every millisecond saved required a deliberate trade-off.
🗂️ Structuring Fragmented Enterprise Knowledge
Enterprise data is messy — spread across SOPs, Telegram threads, GitHub repos, Notion pages, and video recordings. Making it uniformly retrievable was a significant challenge:
- Designing consistent chunking and metadata tagging across wildly different source formats
- Preventing retrieval degradation when document chunking was poorly optimized
- Keeping SOP and document versions synchronized in the knowledge base as they evolved
Garbage in, garbage out — and enterprise data is rarely clean.
🛡️ Real-Time Policy Enforcement Without Over-Restriction
The compliance engine needed to be firm without becoming a bottleneck that frustrated legitimate users:
- Tuning the Hard Policy Engine to block genuinely risky queries without flagging routine ones
- Designing Metadata Filter logic that was precise enough to enforce rules but flexible enough for edge cases
- Generating compliant alternatives rather than just rejecting queries — keeping users productive
The system had to say no intelligently, not just frequently.
📋 Full Auditability With Minimal Latency Impact
Logging every interaction immutably for up to 7 years, without slowing down the query pipeline, required careful engineering:
- Designing an asynchronous audit log store that didn't block the response cycle
- Ensuring source citations were accurate and traceable at the chunk level, not just the document level
- Balancing storage efficiency with the requirement for long-term, tamper-proof records
Accountability and speed are rarely natural allies.
🎯 The Core Difficulty
Building an AI system that is not just functional — but trustworthy and enterprise-ready.
Every individual component was solvable in isolation. The real challenge was making them work together — offline, in real time, under compliance constraints, with full traceability — without any single layer becoming the bottleneck that broke the rest.
Accomplishments that we're proud of
We successfully built a fully offline, compliance-first AI assistant that delivers grounded, hallucination-controlled responses using only internal enterprise data—eliminating dependency on external APIs. A key achievement was implementing end-to-end compliance enforcement, where every query is validated before processing and every response is policy-aligned, traceable, and auditable. We designed a hierarchical RAG pipeline with metadata filtering, significantly improving retrieval accuracy across diverse data sources like SOPs, repositories, chats, and videos. Additionally, integrating a hallucination detection layer, a structured review workflow (Draft → Review → Approve), and a 7-year audit logging system ensured reliability and governance. Overall, we are proud of delivering a system that is not just technically robust, but enterprise-ready, secure, and trustworthy by design.
What we learned
This project emphasized that building enterprise-grade AI systems is fundamentally a systems engineering problem, not just a modeling task. We learned the importance of RAG pipeline optimization, where retrieval quality (chunking strategy, embedding selection, metadata filtering) directly impacts generation accuracy more than model size. Implementing strict grounding constraints showed that limiting the LLM’s context to verified data significantly reduces hallucinations. We also gained practical insight into designing a policy enforcement layer that operates both pre- and post-inference, ensuring deterministic and compliant outputs. Working with offline LLMs highlighted challenges in memory management, inference latency, and model efficiency within constrained environments. Additionally, integrating heterogeneous data sources required robust ETL pipelines, vector indexing strategies, and version-controlled knowledge management. Overall, we learned that reliable AI systems depend on tight integration between data pipelines, retrieval mechanisms, and controlled inference workflows.
What's next for Compliance-First Enterprise AI Assistant
The next phase focuses on transforming the system into a plug-and-play, enterprise-ready AI platform **that can be adopted by any organization with minimal effort. We aim to make the assistant **easily integrable into any company’s existing systems through a lightweight SDK or API, where businesses can deploy the chatbot on their website or internal tools by adding just a few lines of code.
A key enhancement will be multi-tenant architecture, where each organization gets its own isolated knowledge base, vector database, and policy layer. This ensures complete data separation, security, and customization, allowing the same core system to serve multiple companies without any data overlap.
We also plan to introduce automated onboarding pipelines, enabling organizations to quickly ingest their internal data (SOPs, documents, repositories, etc.) with minimal configuration. This will include guided setup for policy definitions, access control, and knowledge indexing, reducing deployment complexity significantly.
On the technical side, we will further optimize the system with: Faster retrieval and re-ranking mechanisms for improved response precision Lightweight, domain-adaptable local LLMs for better performance in constrained environments Scalable backend deployment options (on-premise or private cloud)
Additionally, we aim to enhance the platform with monitoring dashboards, usage analytics, and compliance insights, giving organizations full visibility into how the system is being used and how decisions are being made.
The long-term vision is to build a universally deployable, compliance-aware AI assistant that acts as a secure intelligence layer for any enterprise—requiring minimal setup while delivering highly customized, isolated, and reliable knowledge systems for each organization.
Built With
- faiss
- fastapi
- ffmeg
- javascript
- langchain
- meta
- notion
- ollama
- openai
- pydantic
- python
- rag
- react
- reddis
- supabase
- tailwindcss
- telegram
- uvicorn
- vercel
- whisper

Log in or sign up for Devpost to join the conversation.