-
-

Title Card
-
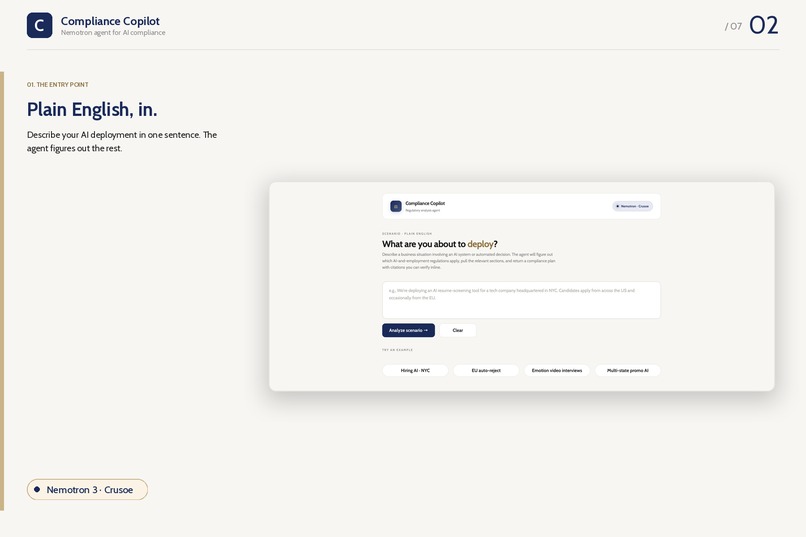
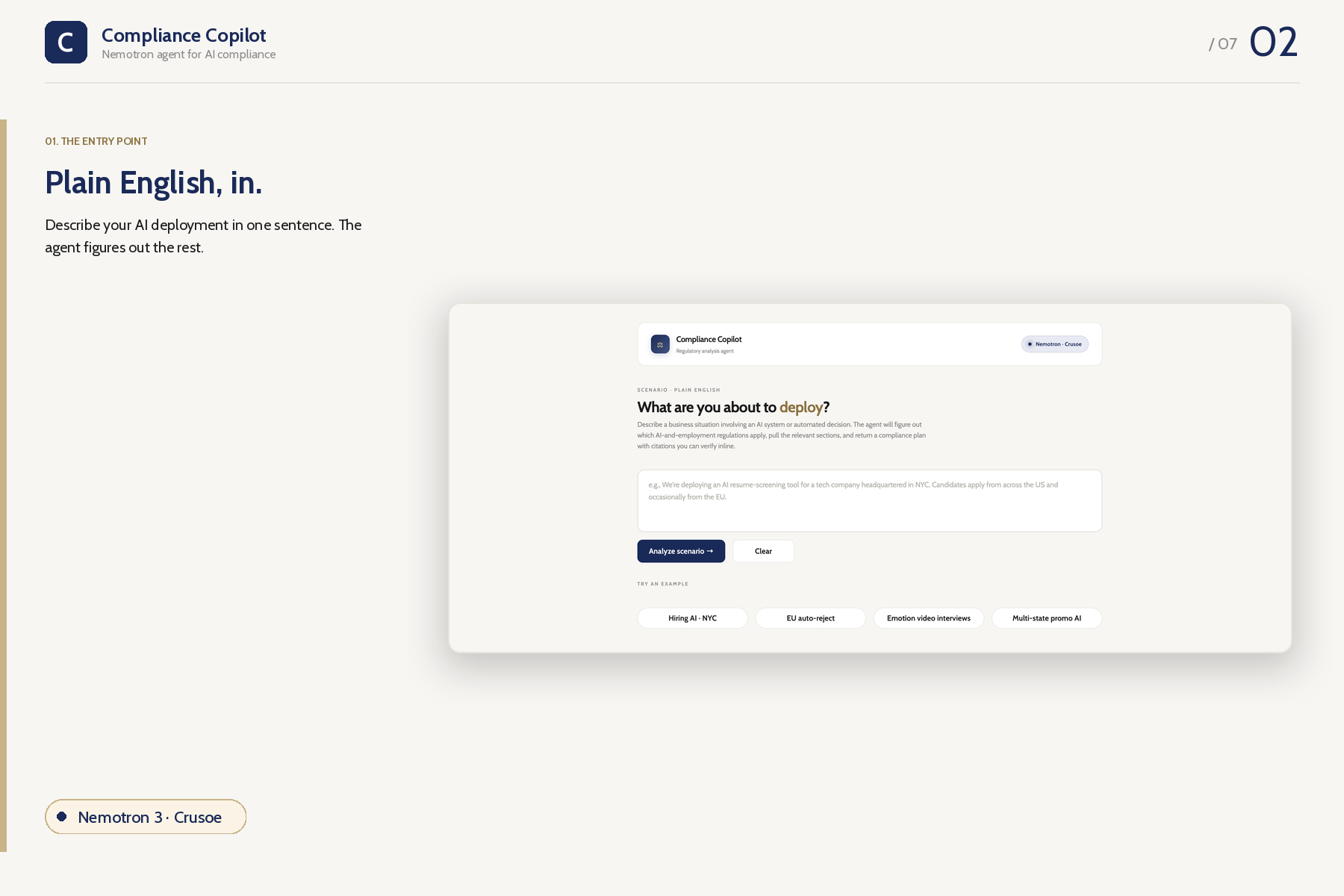
Entry
-
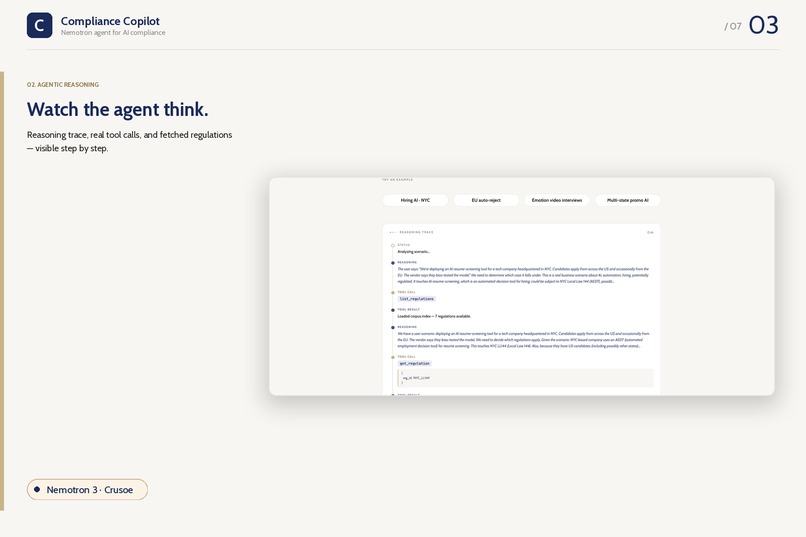
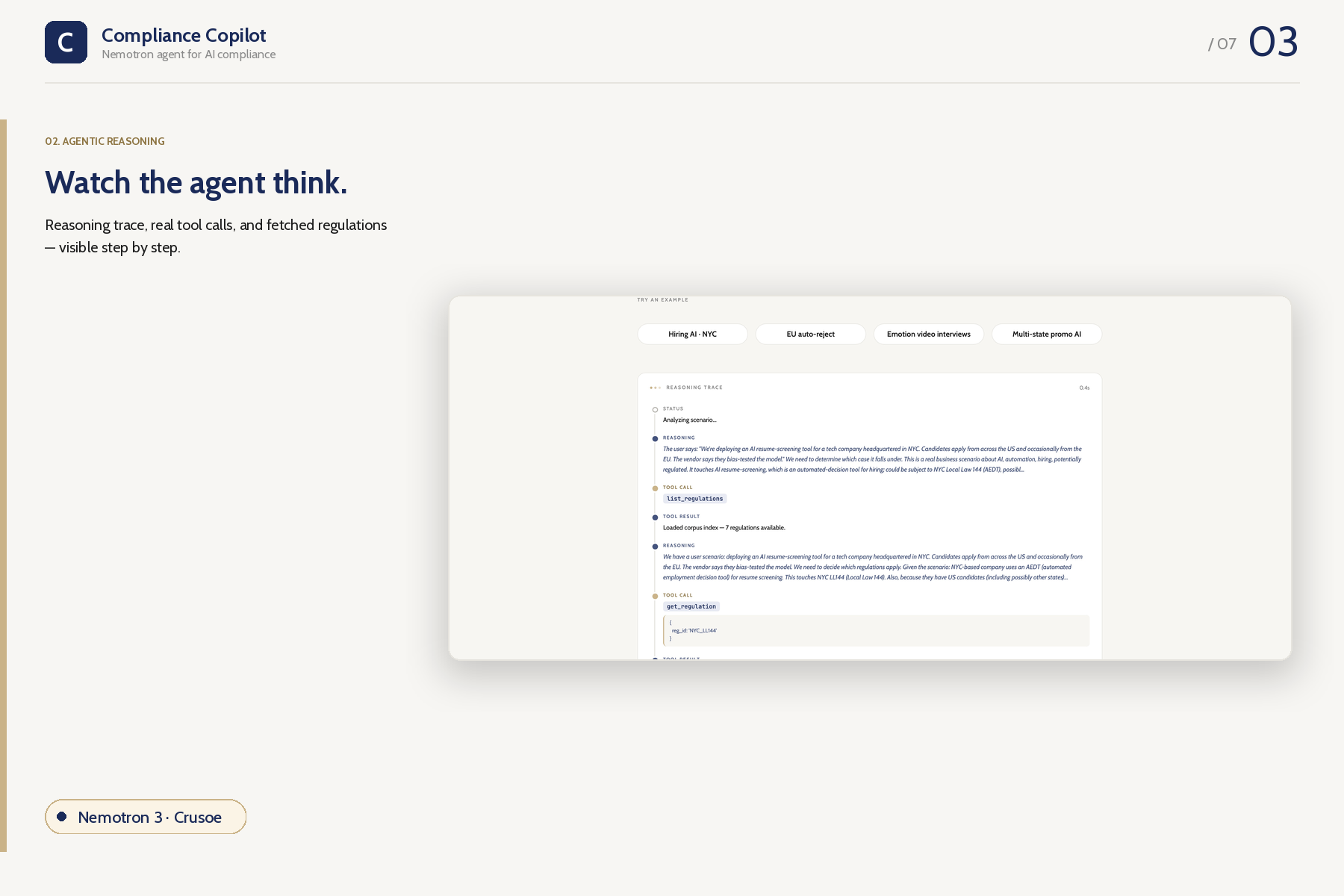
Reasoning
-
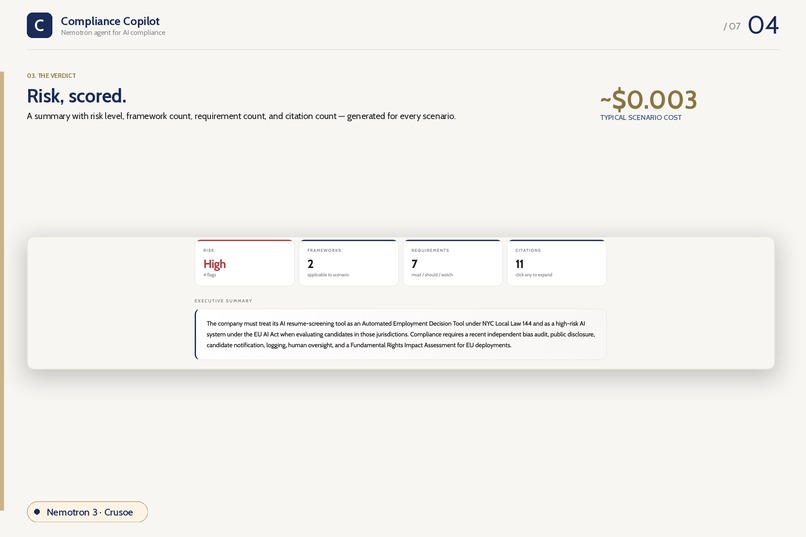
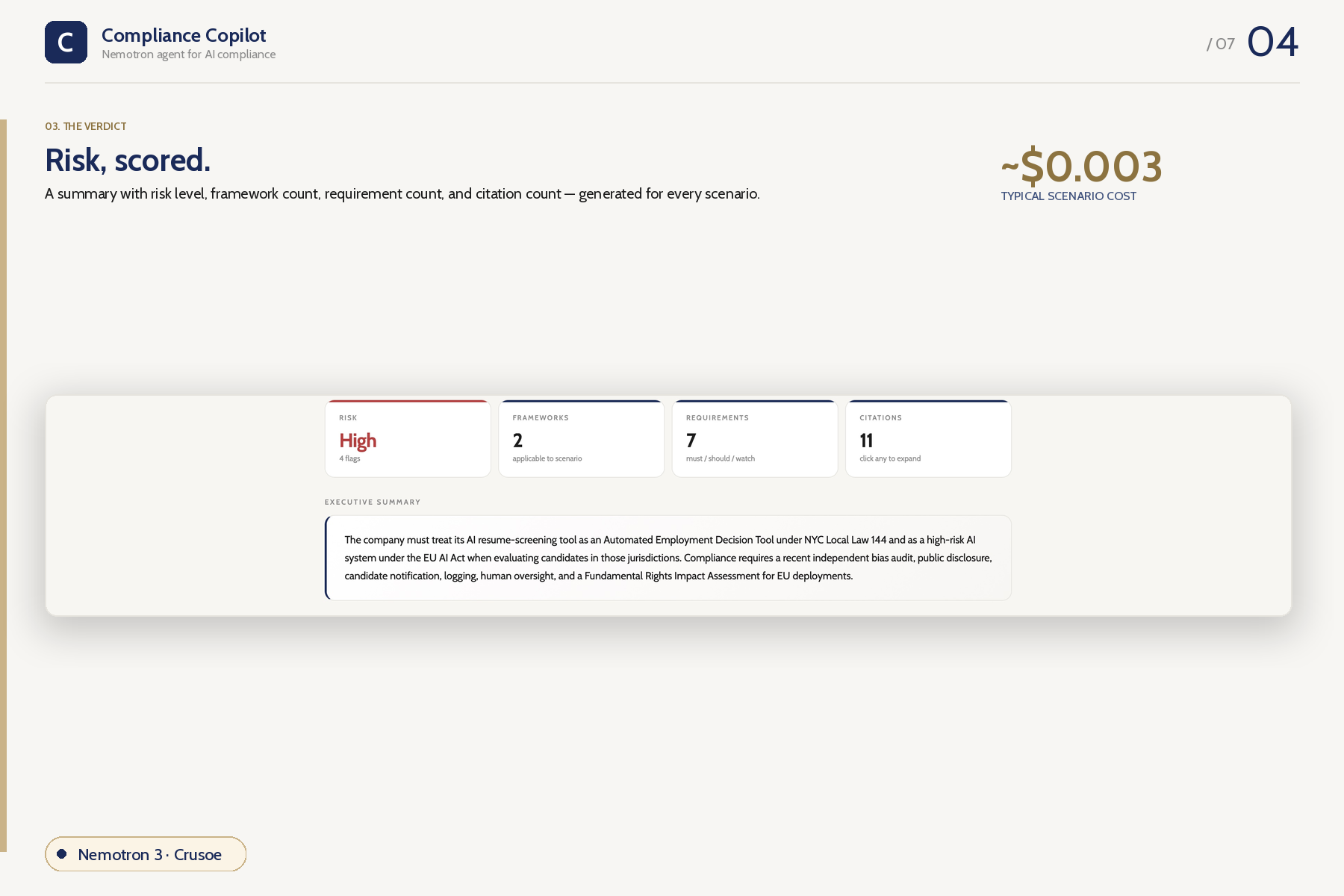
Verdict
-
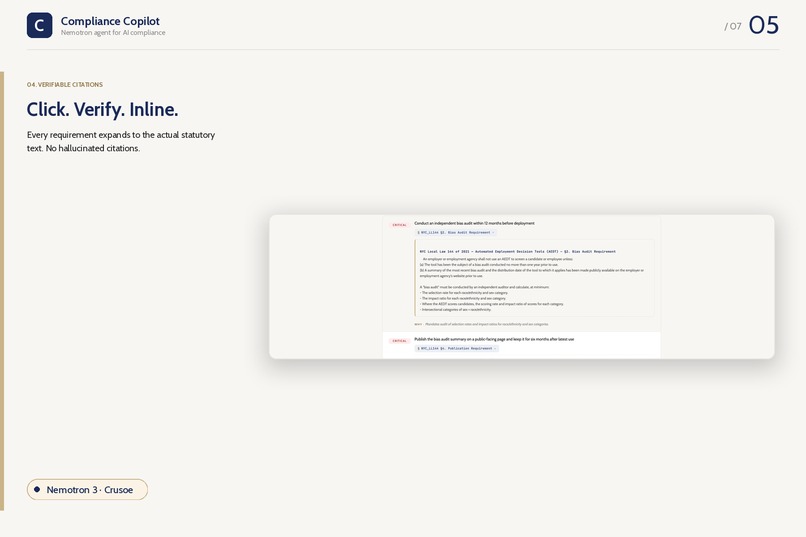
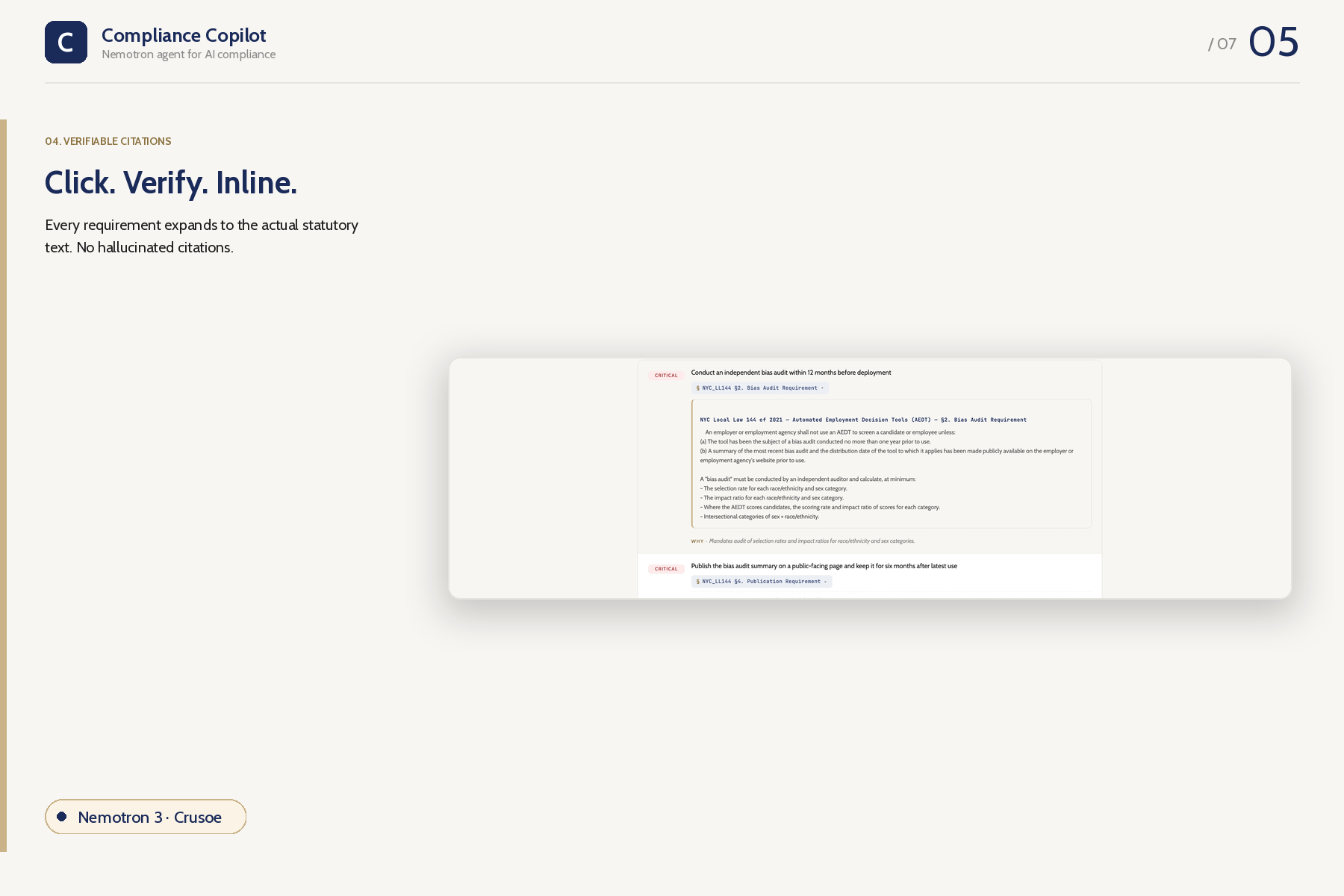
Citations
-
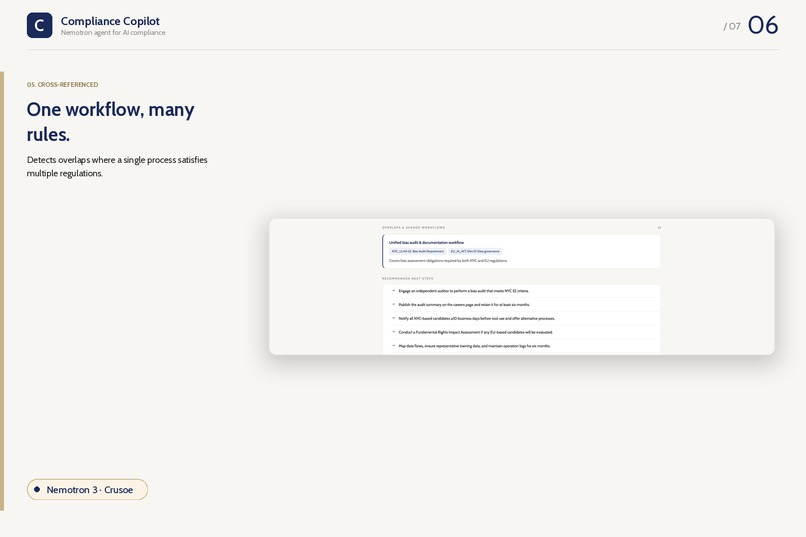
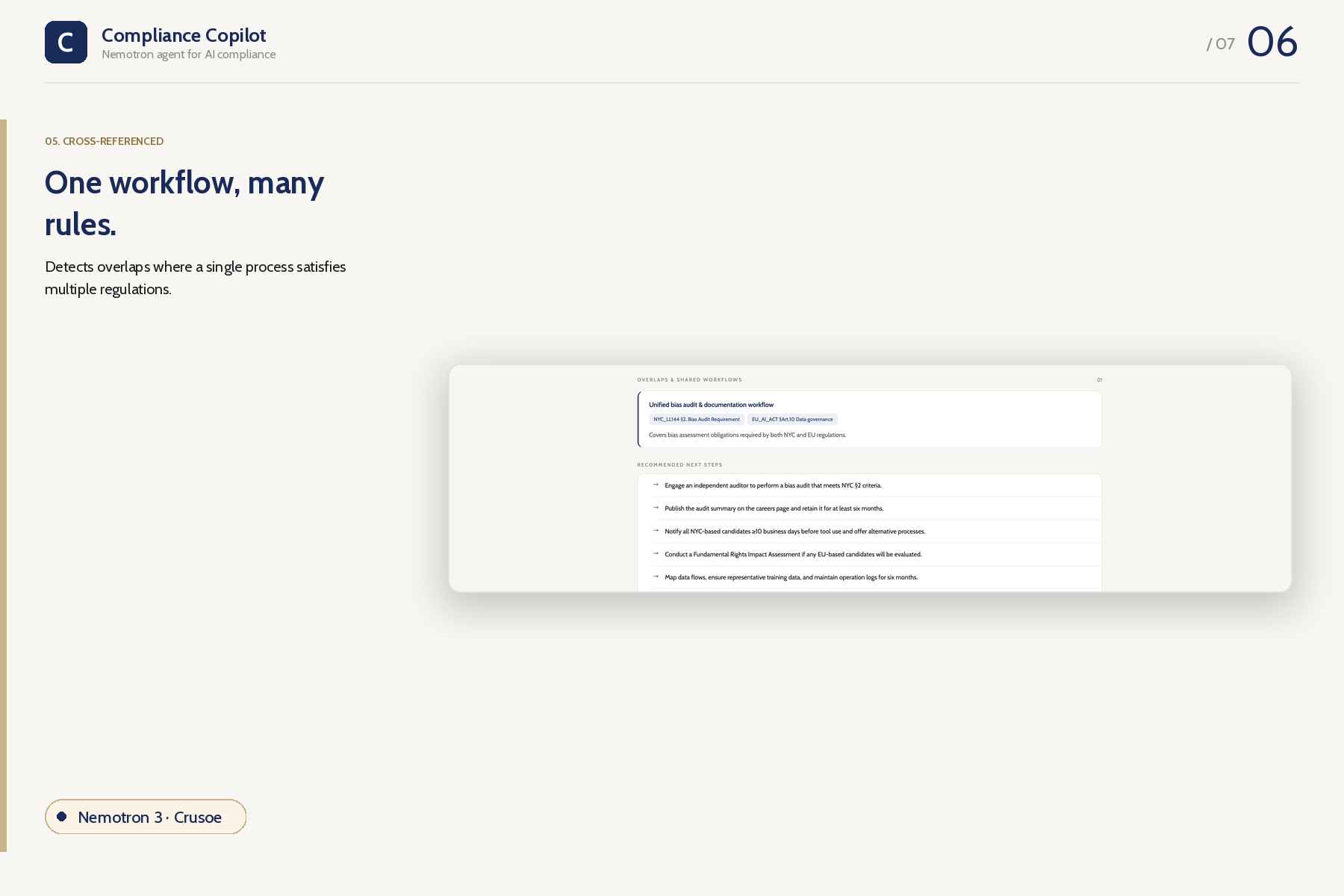
Overlaps
-
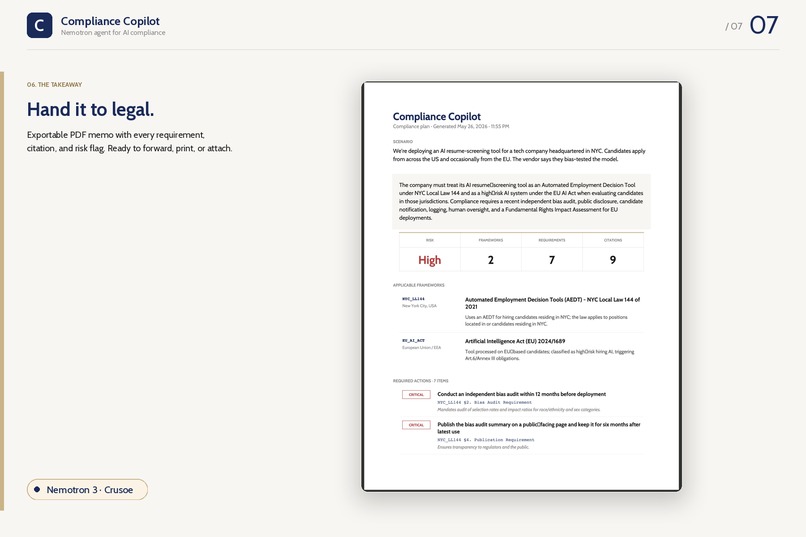
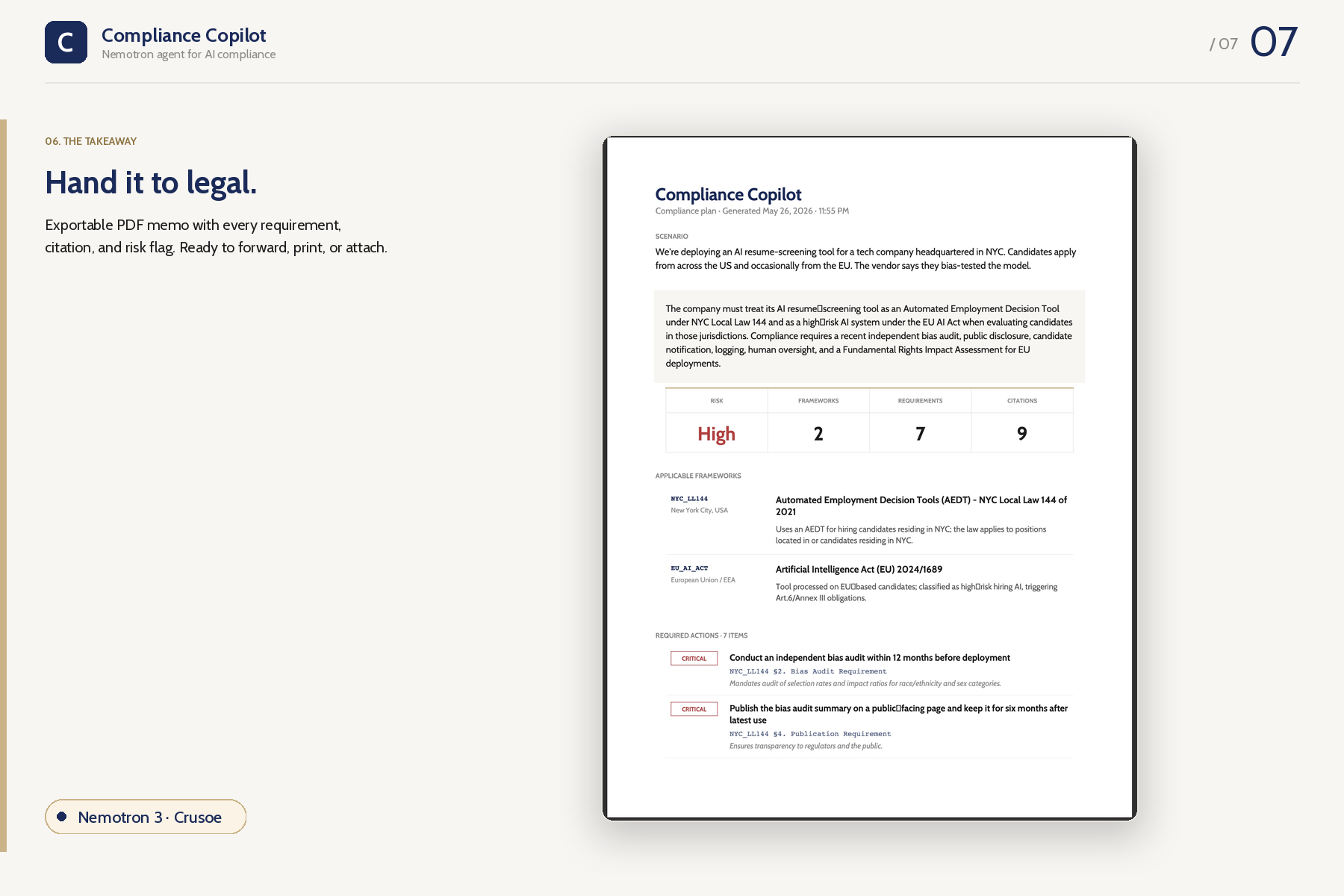
Takeaway

What it does
Compliance Copilot is an agentic regulatory analysis tool for AI deployments.
Type a business scenario in plain English — "We're deploying AI resume screening for a tech company in NYC, candidates from the US and occasionally the EU" — and an NVIDIA Nemotron agent on Crusoe Managed Inference decides which laws apply, fetches the actual sections from a curated corpus, cross-references them against your facts, and emits a structured compliance plan with verifiable citations and a downloadable PDF memo.
In 25 seconds and about three cents.
Inspiration
Every company deploying AI in employment decisions sits at the intersection of half a dozen overlapping regulations: NYC Local Law 144, the EEOC's four-fifths rule, GDPR Article 22, the EU AI Act, CCPA / CPRA, Colorado SB 24-205, Illinois's AI Video Interview Act — and the list keeps growing.
The fines are real. NYC LL 144 is $500–$1,500 per day per violation. GDPR is up to 4% of global revenue. The EU AI Act caps at 7%.
The current options for navigating this are all bad:
- Hire outside counsel — $400–$1,500/hour, weeks of turnaround for a memo.
- Buy a compliance platform (Vanta, Drata, OneTrust) — built for continuous infrastructure monitoring against static frameworks like SOC 2. You can't paste a paragraph and ask "does this trigger Article 22?"
- Pay a bias-audit firm (Holistic AI, Babl AI) — perfect once you know you need a $50K audit. Doesn't help you discover you need one.
- Ask ChatGPT or Claude — happily answers but fabricates citations. Useless for legal teams who need verifiable sources.
There's a missing tier: fast, agentic, plain-English scoping that produces verifiable citations and structured next steps. That's the gap Compliance Copilot fills.
How we built it
The core is a single agentic loop with three tools the model can call autonomously:
list_regulations()— returns a routing index of available frameworksget_regulation(reg_id)— returns full section-split text plus metadataemit_verdict(...)— required structured output: summary, applicable regulations, requirements with rationale, risk flags, cross-references, next steps, open questions
The model decides what to fetch and in what order. Judges literally watch the agent plan, fetch, reconsider, then emit — every tool call, every reasoning step, every fetched section is surfaced in a live timeline.
The corpus is seven curated regulations as markdown files with YAML frontmatter:
| File | Regulation | Jurisdiction |
|---|---|---|
nyc_ll144.md |
NYC Local Law 144 — AEDT bias audit | New York City |
eeoc_ai_hiring.md |
EEOC Title VII guidance on AI hiring | US federal |
gdpr.md |
GDPR Art. 5, 6, 9, 13–14, 22, 35, 44–49 | EU / EEA |
eu_ai_act.md |
EU AI Act — prohibited + high-risk + deployer duties | EU / EEA |
ccpa_cpra.md |
CCPA / CPRA — Automated Decisionmaking Technology | California |
colorado_ai_act.md |
Colorado AI Act (SB 24-205) | Colorado |
illinois_aivi.md |
Illinois AI Video Interview Act | Illinois |
We deliberately skipped a vector database. The corpus is small enough that routing is reasoning, not similarity search — letting the model read an index file and decide which regs to pull in full produces sharper citations than top-k retrieval would.
Triage layer. Before engaging the pipeline, the system prompt classifies the input into five buckets: real scenario, greeting, meta-question, off-topic, too vague. Only real scenarios invoke tools. A "hi" gets a friendly reply in one $0.0001 call instead of seven $0.004 calls.
Three resilience layers (also targeting the TrueFoundry challenge):
- JSON synthesis fallback — if Nemotron writes plain text instead of calling
emit_verdict, the agent rebuilds a fresh, focused conversation and asks for a fenced JSON block. A brace-balanced parser handles nested objects. - Degraded verdict — if JSON parsing fails too, the agent synthesizes a minimal verdict from the regulations it did fetch by walking the tool-call history.
- Transient-error retry — 3 attempts with exponential backoff on 5xx, timeout, and rate-limit errors.
The UI is a Streamlit workspace with three panels:
- Left rail — agent timeline with circular nodes for each tool call, tool result, and reasoning trace; the live node pulses while running.
- Center — live conversation: scenario bubble, thinking bubbles surfacing Nemotron's separate
reasoningfield, tool-call bubbles showing actual function calls with arguments, results streaming in. - Right rail — compliance plan building progressively. Risk / Frameworks / Requirements / Citations metrics, framework cards, severity-coded action items (CRITICAL / REQUIRED / ADVISED), citation pills that expand inline to show the actual regulation text — no rerun, no context-switch.
PDF export uses reportlab with Cabin registered as a TTF (with patched name-table metadata so bold ≠ regular) to keep brand consistency from web → PDF.
Challenges we ran into
- Nemotron is a reasoning model with split output. The first smoke test returned
Response: Noneuntil we realized the model emits its thinking in a separatereasoningfield and only writes the answer tocontentifmax_tokensis generous enough to finish reasoning first. We turned that into a feature: surfacing the reasoning trace as a visible timeline event makes the model's "thinking" legible to judges, which is exactly what the Crusoe challenge asks for. - Forced
tool_choicereturned empty 500s on the Crusoe Nemotron route. Instead of fighting routing, we built the JSON-synthesis fallback — same structural outcome, no footgun. - Streamlit's top-down execution model fights three-pane workspace UIs. We solved it with
st.empty()placeholders + custom CSS injection for Cabin and the indigo / fawn / dusk palette, plus.streamlit/config.tomlto pin the theme (dark-mode-auto would have inverted the palette). - Streaming progressive UI updates inside a single Streamlit run required treating the agent as an event generator that yields dicts the UI accumulates into session state — not as a synchronous function call.
Accomplishments we're proud of
- It's actually agentic. Not a scripted pipeline pretending to be an agent. The model plans, fetches, and decides on its own.
- Verifiable citations. Every requirement points to a section the agent actually fetched from the corpus, expandable inline. No hallucination.
- About $0.003–$0.005 per scenario. A $7 hackathon budget runs ~2,000 scenarios. Triaged non-scenarios cost $0.0001.
- The PDF export looks like a real legal memo, not a Streamlit screenshot.
- The UI surfaces the model's reasoning trace, tool calls, and fetched sections in real time — so a legal team can verify everything the agent claims.
What we learned
- Reasoning models change the deal —
max_tokensis the budget for thinking plus answering, and surfacing the reasoning trace is a UX superpower. - For small, curated corpora, letting an agent reason over an index file beats vector search on precision of citations.
- Resilience isn't a feature you add at the end — JSON-synthesis fallback, degraded-verdict synthesis, and transient retry have to be designed into the agent loop from the start.
- Input triage is non-obvious but high-leverage. A compliance agent that "analyzes" the word "hi" looks dumb and wastes ~30× the cost.
What's next
- Citation verification pass — a second cheap LLM call that checks each emitted citation against the actual section text, surfacing hallucinated section numbers with a "verified ✓" badge.
- Multi-model fallback via TrueFoundry AI Gateway — wrap the client so a Crusoe 500 fails over to Llama 3.3 70B.
- More regulations — BIPA (Illinois biometrics), Maryland HB1202, Tennessee ELVIS Act, California AB-2885. Each is a single markdown file.
- "What-if" diff mode — re-run with a modified scenario ("what if we expand to Germany?") and show the diff against the previous verdict.
- Generated compliance documents — once we know NYC LL 144 § 2 applies, generate a draft candidate notification with the user's company name pre-filled.
- Evaluation harness — a test set of ~20 ground-truth scenarios with expected applicable regulations; CI runs the agent against them and reports precision/recall on framework selection.
- Compliance-as-code generator — translate a verdict into a YAML policy file an ATS can enforce: "block all California applicants if no ADMT pre-use notice is configured."
Compliance Copilot is not legal advice. It's the legal scoping step, automated for the price of a tweet.
Built on NVIDIA Nemotron 3 via Crusoe Managed Inference.
Built With
- crusoe
- crusoe-managed-inference
- css
- html
- javascript
- markdown
- nvidia-nemotron
- openai-sdk
- python
- reportlab
- streamlit

Log in or sign up for Devpost to join the conversation.