-
-

Header
-
Findings + Source Citing + Legal Statutes
-
Self-Improvement Panel
-
Architecture Diagram
-
Arize Phoenix Trace Waterfall

Inspiration
Every founder we know ships first and worries about compliance later. Usually, a lawyer, an enterprise security review, or a regulator forces the issue, and by then the cleanup is expensive. GDPR and CCPA are not unknowable. The difficulty is that the law lives in long PDF documents while the risk lives in code, and nobody has time to hold both in their head at once.
We wanted an agent who closes that gap continuously. You point it at a repository, and it tells you, in plain English and with the statute quoted, exactly where your code falls short. Then it writes the patch.
We are also skeptical of compliance tools that confidently hallucinate regulations, so we set a harder bar for ourselves. Beyond producing findings, the agent should be able to prove how good those findings are and correct itself when its quality slips, without anyone touching the code. That second goal pulled us deep into Arize Phoenix, and it turned into the most interesting engineering work of the project.
What it does
You give ComplianceOS a public GitHub or GitLab URL. In about a minute, it does five things.
- It profiles the repository with Gemini. It works out the product type, the data the code handles, where the users are, and whether the system touches payments or machine learning. It then reasons about which regulations actually apply, because there is no point auditing a static site against CCPA rules on selling personal data.
- It retrieves the relevant statute text from an Elasticsearch corpus of real GDPR, CCPA, and EU AI Act articles using hybrid BM25 and vector search.
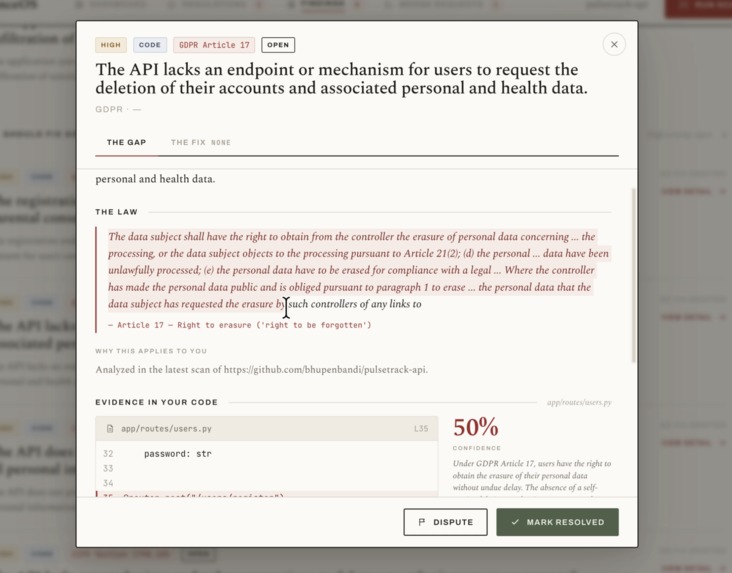
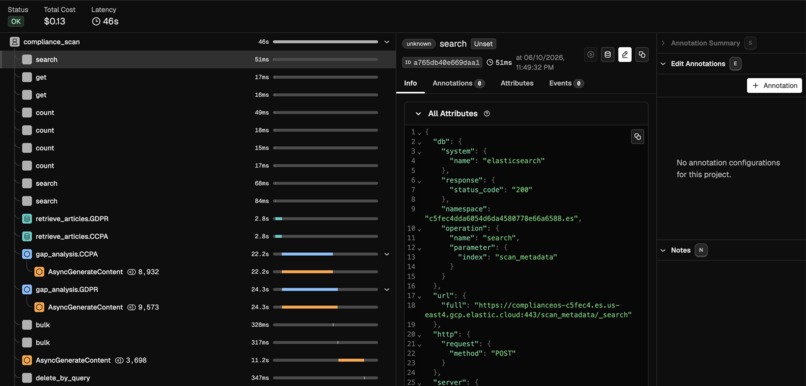
- It runs one gap analyzer per applicable regulation in parallel. Each analyzer reasons with Gemini over a single shared fetch of the code and emits findings that quote the offending line and cite the article verbatim.
- It deduplicates, confidence scores, and ranks the gaps, then assigns a launch posture of ready, partial, or not ready.
- It drafts the fixes as reviewable merge requests. You get a plain English summary and a real diff that you approve and merge yourself. The agent never merges on its own.
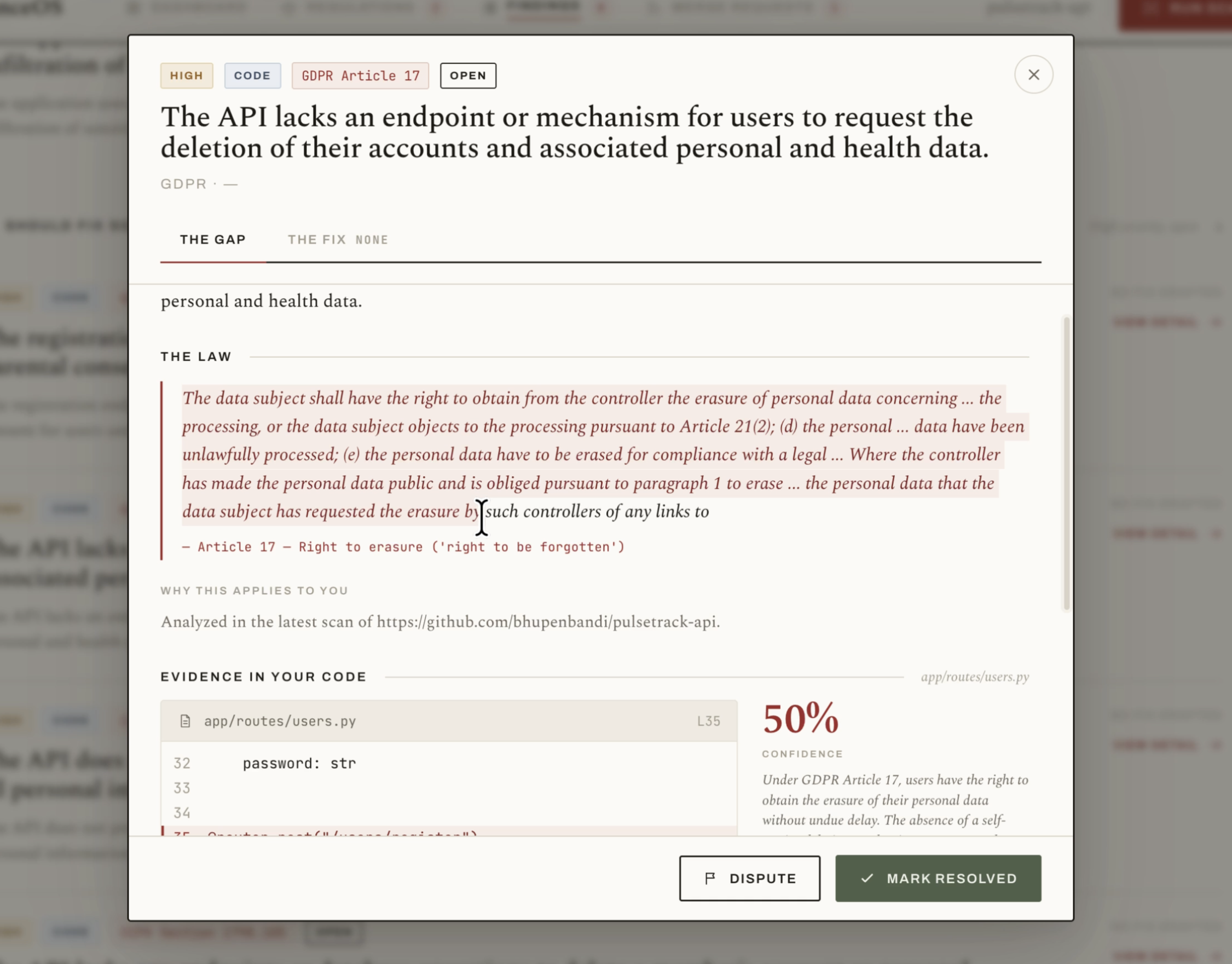
On our demo repository, a fictional health and fitness API named pulsetrack-api that we seeded with realistic violations, a scan surfaces 8 findings, 3 of them critical. One finding shows the API sharing member profiles and health metrics with a third-party ad partner without respecting opt-out, which violates CCPA section 1798.120. Another flags the missing right to erasure endpoint required by GDPR Article 17. Each finding is anchored to a file and a line number.
We built this for small teams that have no compliance function of their own: the seed-stage startup heading into its first enterprise security review, the team shipping a machine learning feature to EU users while the EU AI Act's main obligations begin applying in August 2026, the agency that has to hand a client a defensible codebase. ComplianceOS works as a scan you run before launch and then re-run on every release.
The part we are proudest of: the agent grades itself and gets better
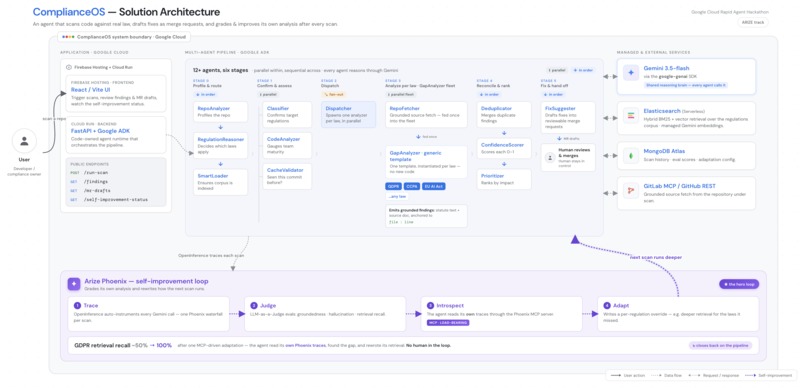
After every scan, ComplianceOS runs an evaluation and adaptation pass over its own output. The loop has four steps.
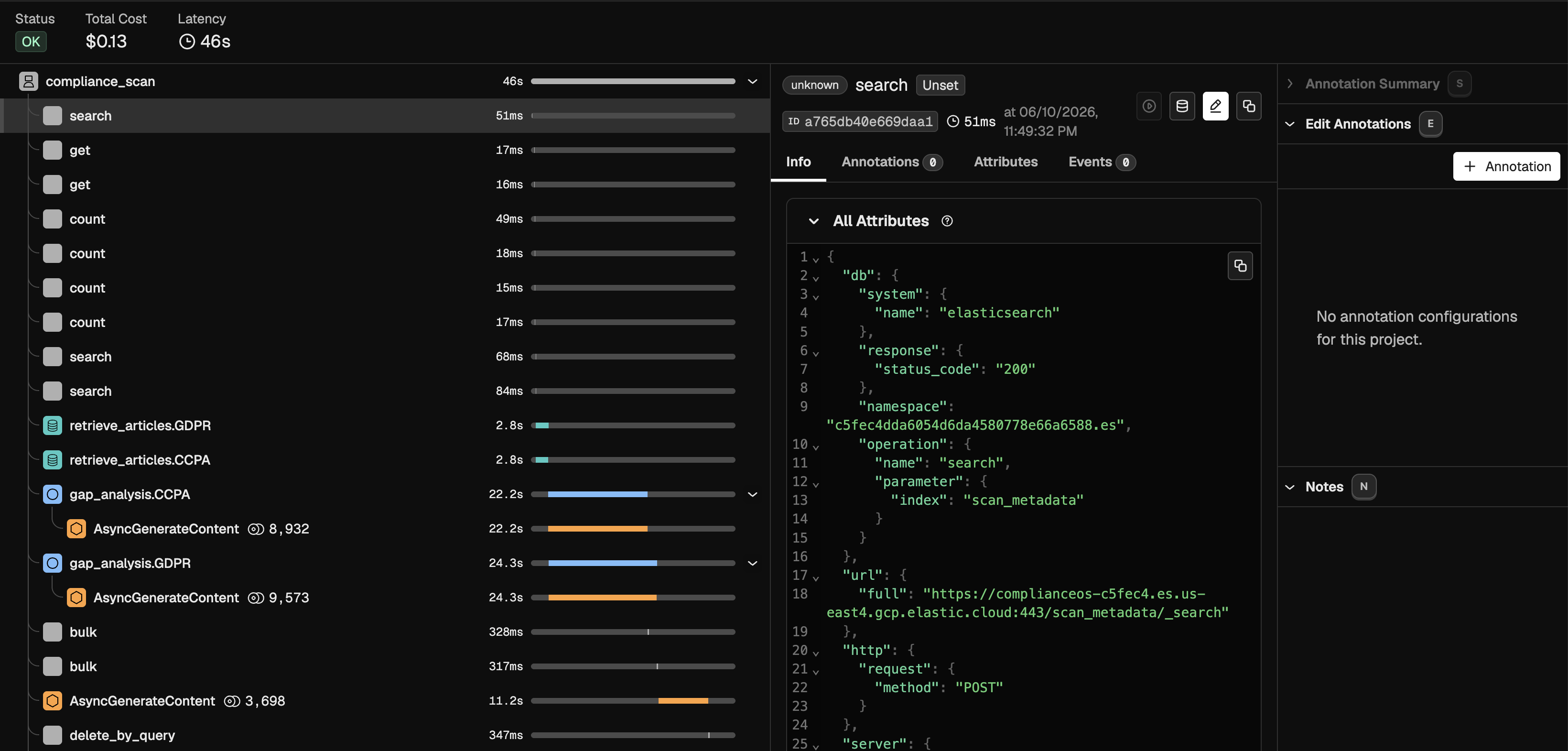
Trace. OpenInference auto-instruments every Gemini call. A full scan collapses into a single Phoenix waterfall: an agent span for the scan, a chain span per regulation, a retriever span with the retrieved statutes attached, and every model call nested underneath.
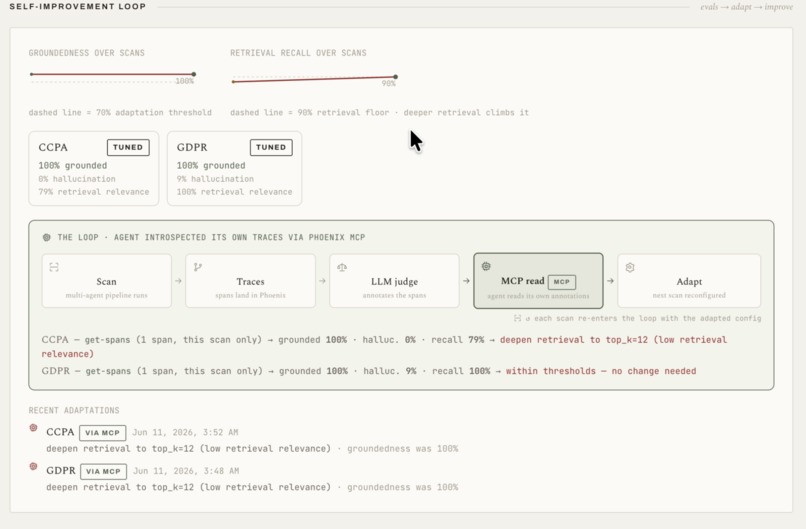
Judge. An LLM-as-a-Judge grades each finding on groundedness, hallucination, and retrieval recall. The grading rubric is itself fetched at eval time through the Phoenix MCP server with get-latest-prompt, from a prompt we keep versioned in Phoenix Prompts. The verdicts are written back to Phoenix as annotations on the exact spans that produced those findings.
Introspect. The agent then reads its own grades back through the Phoenix MCP server. It calls get-spans to pull the eval annotations off its recent traces, and if MCP is unreachable, it falls back to MongoDB, so the loop never breaks.
Adapt. The verdict becomes a per-regulation override, such as deeper statute retrieval, which is persisted to MongoDB and applied on the next scan.
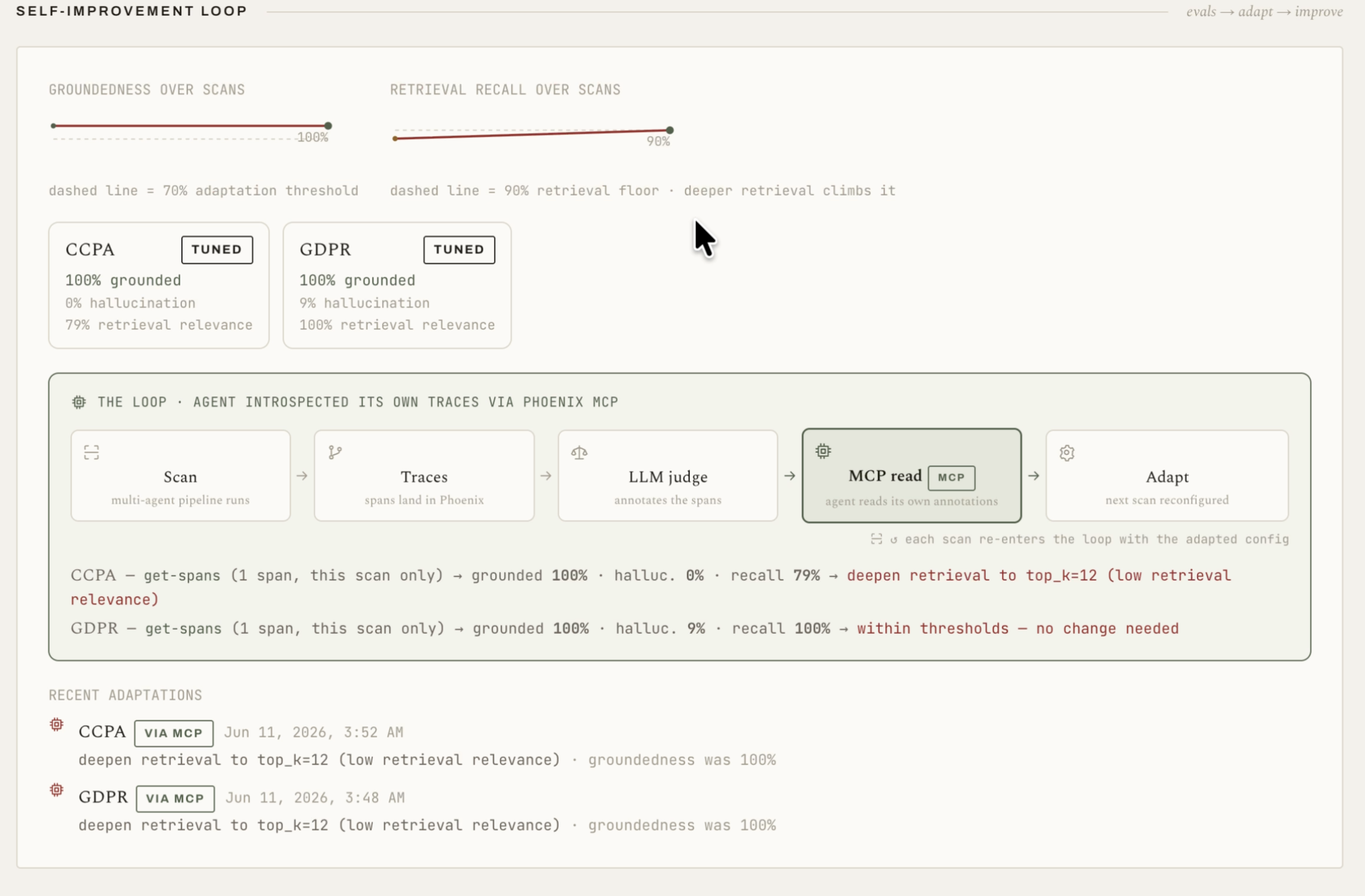
The first time we watched this loop close was the highlight of the project. On the seeded demo repository, the untuned baseline retrieved two statute candidates per gap, and the judge measured GDPR retrieval recall at roughly 50 percent. The agent read that verdict over MCP and deepened its own retrieval from two candidates to twelve. On the next scan, recall came back at 100 percent, judged blind by the same metric. Nobody touched the code in between, and the metric can still fall: recall is judged against a label set that does not depend on retrieval depth, so a future shallow scan would be caught the same way.
Per-scan grading is one half of our eval story. The other half is regression testing. A golden dataset in Phoenix named compliance-golden-repos holds repositories with known compliance exposure, and we run the full pipeline against it as Phoenix Experiments, scoring regulation recall and groundedness, so we can compare quality across rubric versions and retrieval depths instead of relying on anecdotes.
How we built it
| Layer | Technology | Role |
|---|---|---|
| Reasoning | Gemini (gemini-3.5-flash) via the google-genai SDK | Powers all 12+ agents: repo profiling, regulation reasoning, gap analysis, fix drafting, and the eval judge |
| Agent runtime | Google ADK | A code-owned runtime we can instrument directly; the agent exposes its own observability as callable tools |
| Hosting | Cloud Run and Firebase Hosting | The FastAPI backend runs on Cloud Run, and the React frontend is served from Firebase Hosting |
| Observability | Arize Phoenix with OpenInference | Auto-instrumentation plus hand-built semantic spans produce one trace waterfall per scan |
| Self-introspection | Phoenix MCP server (@arizeai/phoenix-mcp) | The agent queries its own spans and prompts at runtime, and this read drives the adaptation decision |
| Evaluation | Phoenix evals, Prompts, Datasets, and Experiments | LLM-as-a-Judge scoring, a versioned grading rubric, and a golden-repos benchmark |
| Retrieval | Elasticsearch Serverless | Hybrid BM25 and kNN search over indexed regulations, with Elastic-managed Gemini embeddings |
| State | MongoDB Atlas | Scan history, eval scores, and the adaptation config that persists learned behavior |
| Source access | GitLab MCP and GitHub REST | Line-level fetch of the repository under scan |
The pipeline itself is 12+ agents organized into six stages. Before any of them run, a cache validator answers in under a second whether this exact commit has already been scanned, and returns the stored findings if it has. Stage 0 profiles the repository and routes the work: a RepoAnalyzer builds the compliance profile, and a RegulationReasoner decides which laws apply and how strongly. Stage 1 runs intake in parallel, where a SmartLoader makes sure every applicable law has an indexed corpus and a CodeStructureAnalyzer estimates how mature the engineering team is. Stage 2 dispatches the work by spawning one analyzer per applicable law. Stage 3 is the analyzer fleet, built from a single generic GapAnalyzer template, so supporting a new regulation requires no new code. Stage 4 deduplicates, scores confidence, and ranks by impact. Stage 5 drafts the merge requests in the background and hands control back to a human.
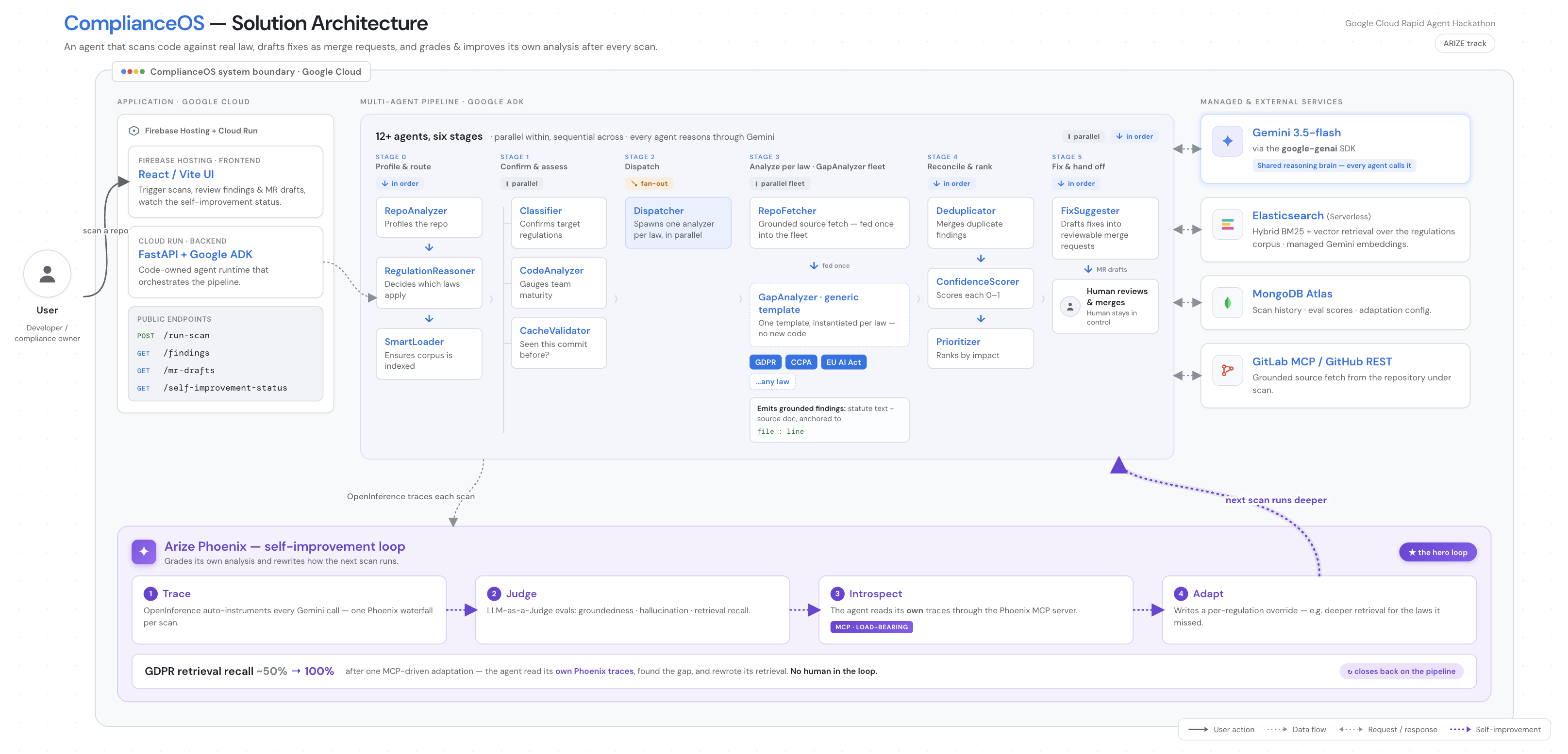
Google ADK turns the system into an agent you can talk to. The ADK root agent in agent_runtime/ wraps the scanner as a callable tool and also exposes the agent's own observability as tools: run_compliance_scan, query_agent_traces, get_self_improvement_status, introspect_evals_via_phoenix_mcp, and list_my_observability_tools. You can open it with adk web, ask it to audit a repository, then ask how reliable its GDPR analysis has been, and it will answer by reading its own eval annotations through the Phoenix MCP server and tell you which source it used. The production API wraps the same pipeline in FastAPI on Cloud Run.
Gemini carries the whole system, so it is worth saying how we use it. Every agent shares one gemini-3.5-flash client through the google-genai SDK. The profiling and gap-analysis agents request JSON-constrained responses so findings parse reliably, the dispatcher fans the per-regulation model calls out in parallel under asyncio.gather, and we chose flash because a scan has to fit inside a latency budget a developer will actually wait for. Retrieval runs on Gemini too, since Elastic's managed gemini-embedding-001 inference endpoint produces the statute embeddings inside the cluster. The same model then grades the pipeline's output as the eval judge.
How this maps to the Arize track
| Track requirement | What ComplianceOS does |
|---|---|
| Code-owned agent runtime | FastAPI on Cloud Run with a Google ADK agent, so every decision is directly instrumentable |
| OpenInference instrumentation | The google-genai auto-instrumentor plus semantic agent, chain, and retriever spans |
| Traces to Phoenix Cloud | Every scan streams to Phoenix Cloud as a single waterfall |
| Phoenix MCP configured in the agent | The adaptation loop reads eval verdicts via get-spans and its rubric via get-latest-prompt, with a MongoDB fallback if MCP is unreachable |
| Evaluations on traces | LLM-as-a-Judge scores for groundedness, hallucination, and retrieval recall, written back as span annotations |
| Bonus: improve from your own observability data | GDPR retrieval recall rose from about 50 percent to 100 percent after one MCP-driven adaptation |
Challenges we ran into
Building the loop turned out to be the easy part. Making it honest was much harder. Our first retrieval metric graded the article that each finding chose to cite. Since the pipeline only emits findings it has already grounded in an on-point citation, the metric was scoring a post-selection artifact, and it pinned itself between 98 and 100 percent on every clean scan at any retrieval depth. The adaptation floor of 90 percent never tripped, so the agent could never honestly find anything to improve, and that defeated the purpose of the loop.
We threw that metric out and rebuilt it as genuine recall at k. A judge first labels which articles a compliance analyst would need for a given gap, working from a broad candidate pool that does not depend on retrieval depth, and without seeing what the agent retrieved. The metric then measures what fraction of those required articles the agent actually surfaced. This version behaves the way the real world does. Shallow retrieval genuinely misses relevant law, and deeper retrieval genuinely recovers it.
Two smaller battles are worth mentioning. Phoenix Cloud's OTLP authentication required us to build the exporter manually with an explicit bearer header. Separately, a hung npx subprocess inside an MCP fetch could stall a scan for more than two minutes until we wrapped it in a hard wall-clock bound.
Accomplishments that we're proud of
- Adding a new regulation takes zero new code. The entire analyzer fleet is one generic template, and when a law is not yet in the corpus the SmartLoader fetches it from its official source, parses it, embeds it, and indexes it live during the scan. We watched the system pull the EU AI Act from EUR-Lex on demand and analyze against it in the same run.
- Every finding is independently verifiable at both ends. Each one carries the verbatim statute text and the source-document id of the article it cites, plus the exact file and line in the code that triggered it, so a reviewer can confirm both the law and the violation without trusting the model.
- The system degrades at every external boundary instead of failing or lying. Elastic MCP falls back to the direct client, Phoenix MCP falls back to MongoDB, a hung repository fetch is hard-bounded so a slow clone cannot stall a scan, and a fetch that returns no code refuses to report a false "ready" verdict.
- Regulation retrieval runs on the Elastic MCP server in the live scan path. Every gap analyzer grounds its findings against the indexed statute corpus through MCP, with the direct client only as a fallback.
What we learned
We stopped treating observability as a dashboard you bolt on at the end. Once our evals lived as annotations on spans that the agent could query over MCP, self-improvement became a control loop with a measurable error signal. We also learned that the loop is only as good as the honesty of its metric. A metric that cannot go down cannot teach the agent anything.
What's next for ComplianceOS
- Scheduled re-scans triggered by regulatory change. An EU AI Act amendment watcher is already scaffolded.
- More regulations, starting with HIPAA, India's DPDP Act, and Brazil's LGPD.
- Inline review comments posted directly to GitHub and GitLab pull requests.
- A learned adaptation policy that promotes today's heuristics into a policy we evaluate as Phoenix experiments.
Built With
- arize-phoenix
- elasticsearch
- fastapi
- firebase-hosting
- gemini
- google-adk
- google-cloud-run
- model-context-protocol
- mongodb
- openinference
- opentelemetry
- phoenix-mcp
- python
- react
- tailwindcss
- vite


Log in or sign up for Devpost to join the conversation.