-
-
Homepage
-
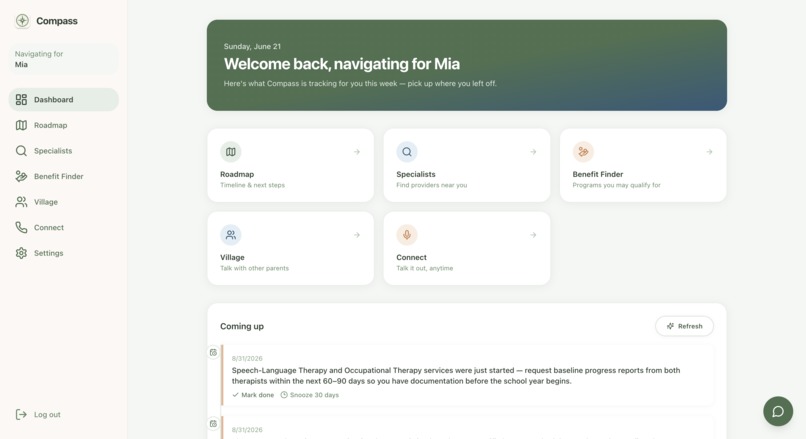
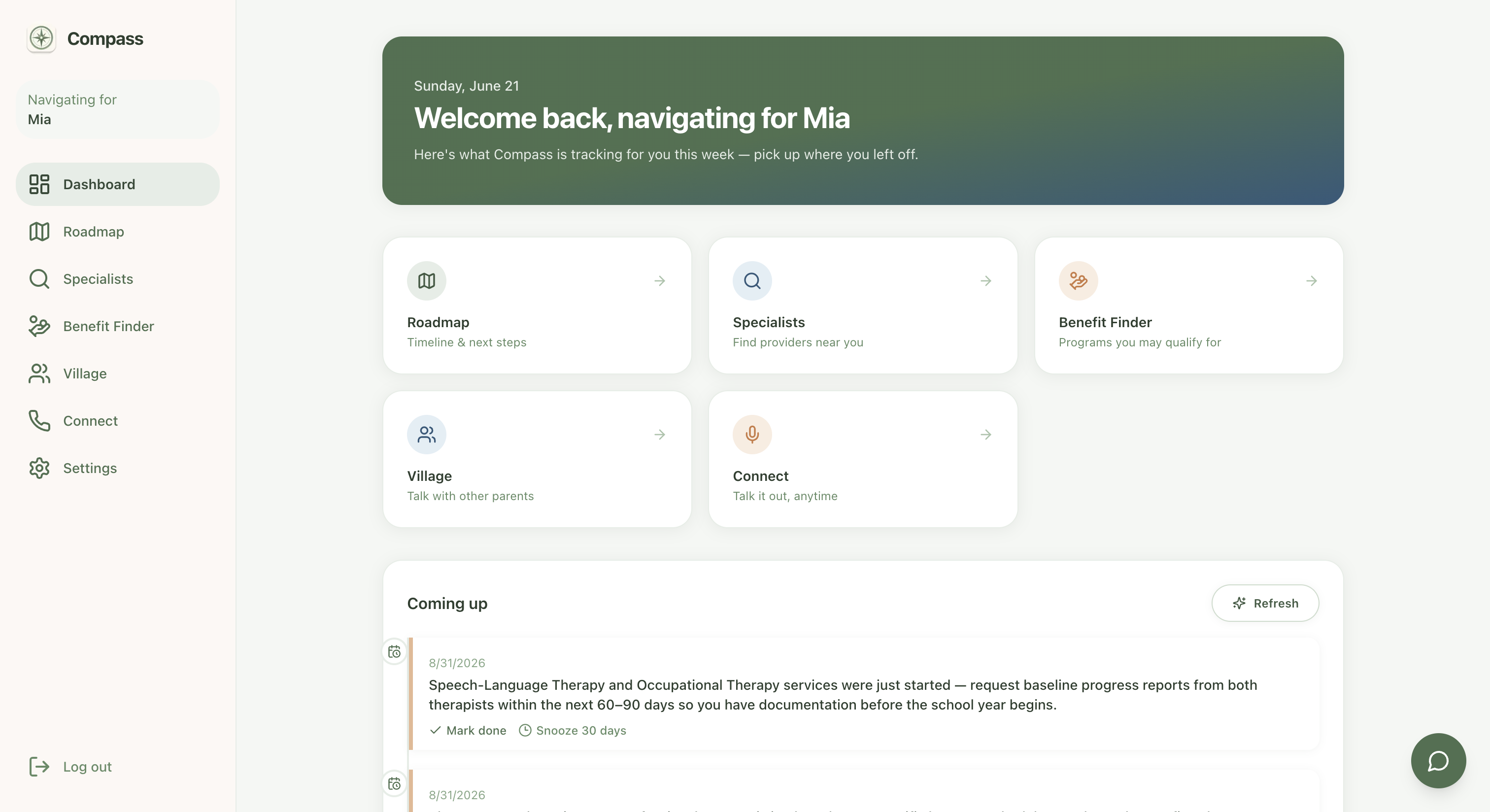
Main Dashboard
-
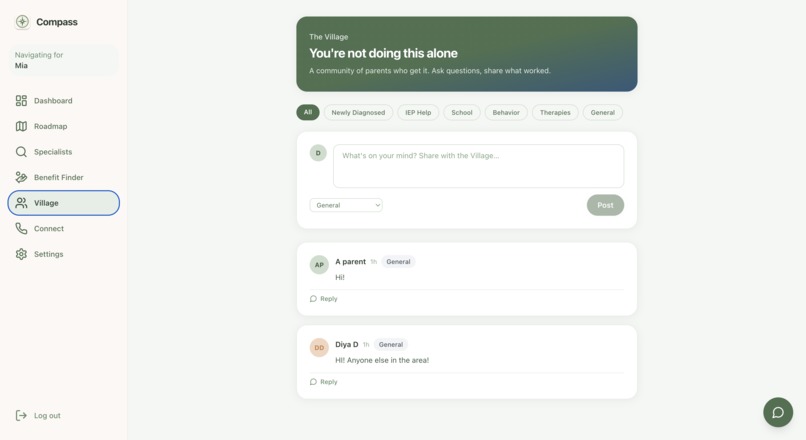
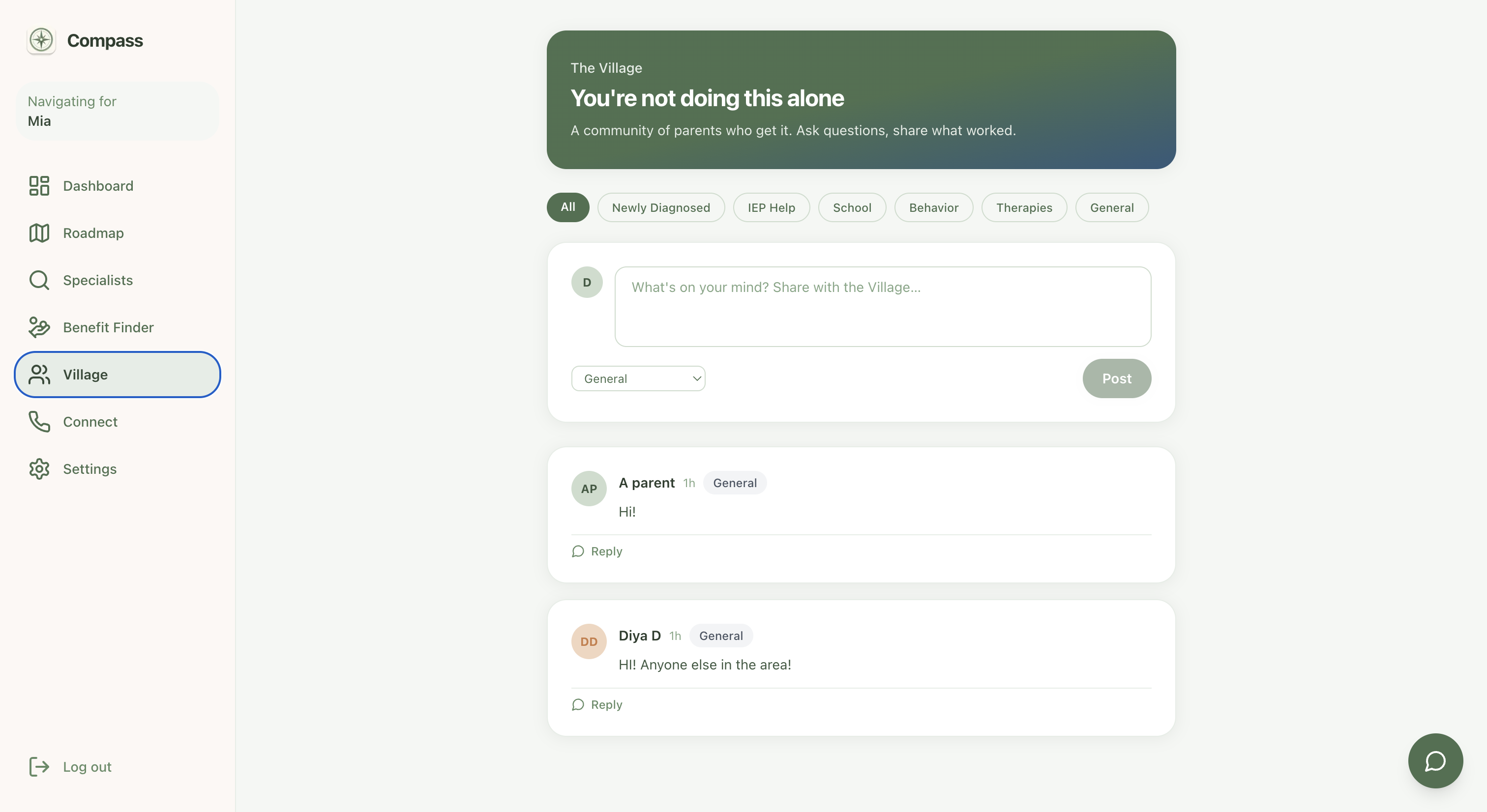
Village - light-weight forum for community building
-
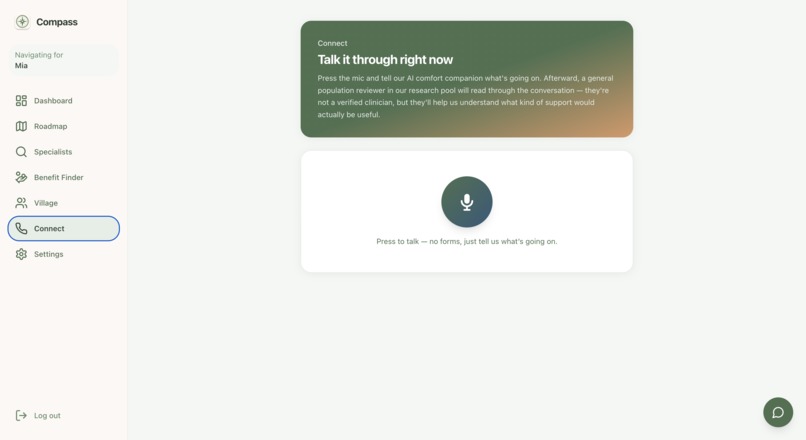
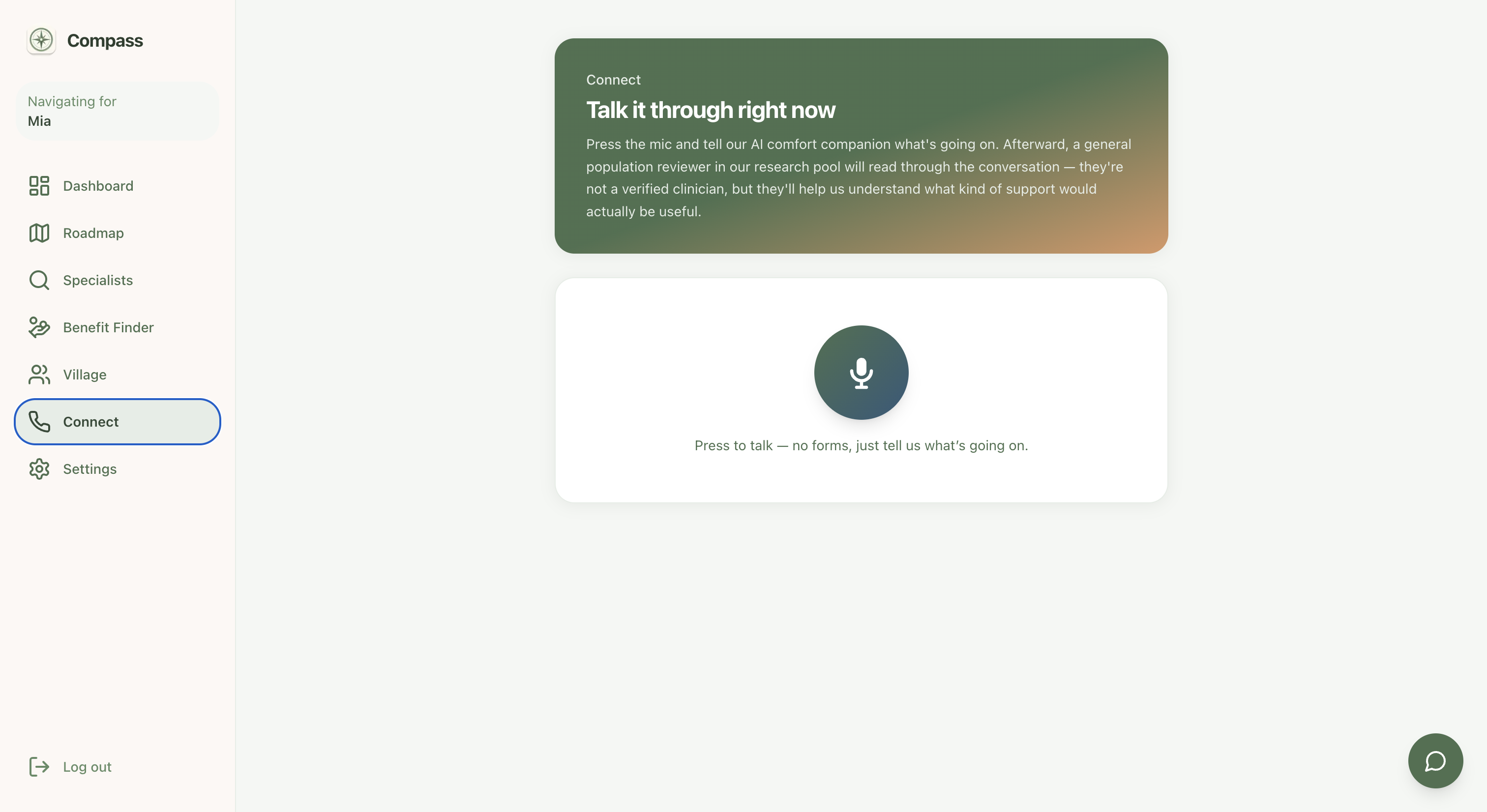
Connect - comforting agent designed to help you before talking to someone
-
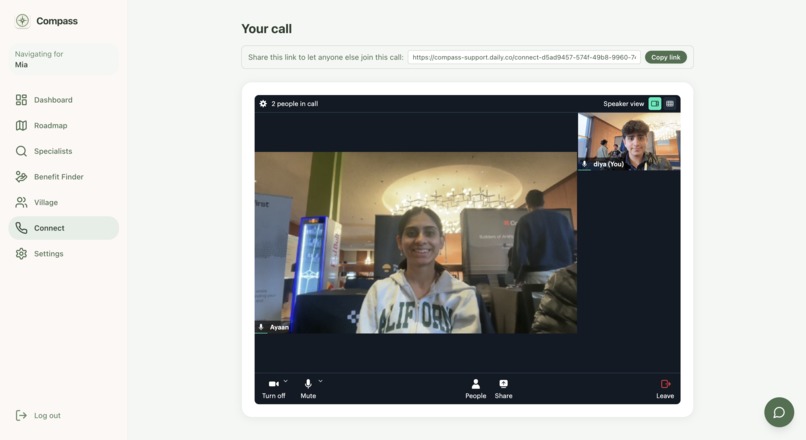
Ability to talk to someone regarding child's issue on the spot
Inspiration
We didn't start with a piece of technology we wanted to use. We started with a moment we kept hearing about, over and over, when we talked to parents of autistic kids. The moment right after the diagnosis appointment, standing in a parking lot, holding a folder full of paper, and realizing nobody had told them what to actually do next.
Not what's wrong. They already knew that. What to do. Which specialist. Which form. Which benefit they probably qualify for but will never hear about unless they happen to ask the right person the right question. Who to call at nine at night when something's hard and they just need another human being to talk it through with, and the only humans available are exhausted too.
That parking lot moment is what Compass is for. Not the diagnosis. The everything after.
What it does
Compass is a navigator, not a database. A parent uploads an IEP, an evaluation, a therapy note. And Claude reads it the way an exhausted parent at midnight can't, and turns it into a timeline and a short, clear list of what to do next. Need a speech therapist who actually takes your insurance? A specialist search agent goes and looks, live, right now, instead of handing back a directory that's been stale since 2022. Wondering if your state has a waiver program you've never heard of? Same thing, a real search, not a guess.
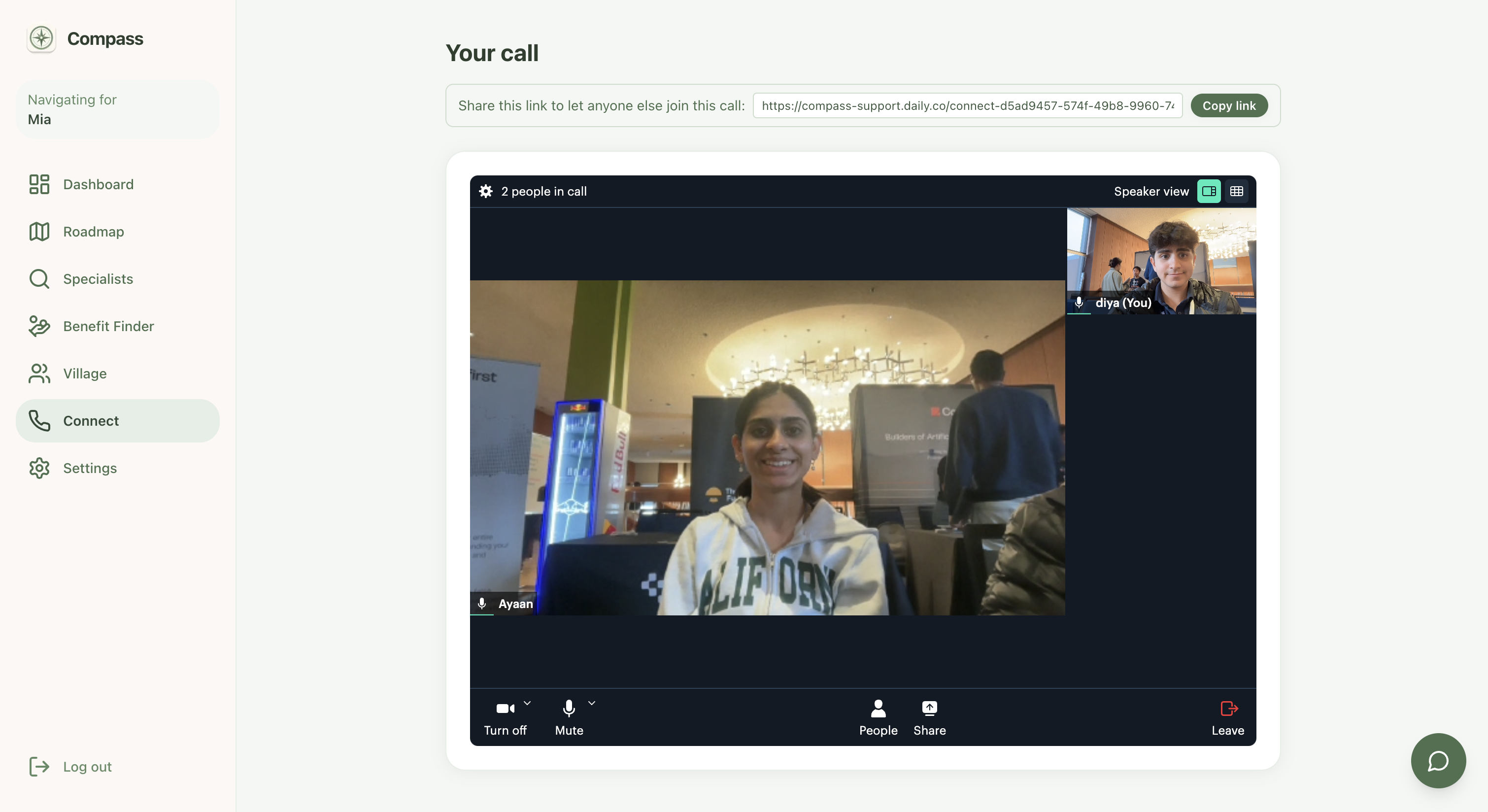
And then there's the part of the app we care about most, because it's the part that shows up at the worst moments: a single mic button. No form to fill out while you're upset. Press it, and an AI comfort companion is immediately there, talking with you, present with you, while you figure out what's going on with your kid. It is never pretending to be a doctor. It never promises something it can't know. It is just there, which is sometimes the entire thing a person needs at 9pm. From there, Compass also opens a request for a real human to join, right now, today that means a member of the general public through Terac's annotator pool, and we say that plainly rather than dress it up as something it isn't. The path forward, and the thing we actually want to build next, is a version of that same human layer screened and verified for medical professionals, so the person who picks up is exactly who a parent needs in that moment.
What makes the AI companion trustworthy isn't just that we wrote it a calm system prompt. It's that real people, through Terac, listen to what it produced and tell us, honestly, whether it was actually good. And we used that feedback to make it better, and then proved it got better, blind, with a second round of real people judging the before and after without knowing which was which.
How we built it
We built Compass as a Next.js app on Supabase, with Claude doing the reading, summarizing, and reasoning throughout. Extracting structure out of messy uploaded documents, generating next steps, moderating a community feed, writing plain English explanations of dense IEP language.
For the parts of the app that needed to know things about the world, not just reason over text, we used Browserbase and Stagehand to run real browser agents against Psychology Today and findhelp.org, so the specialist and benefits search results are genuinely current, not something we faked to look alive.
The live connect feature, the mic button, is where the architecture got genuinely complicated, in a good way. A press of the mic spins up a private Daily.co video room and starts a Vapi voice agent talking to the parent, live, in the browser. When the conversation ends, Vapi hands us a summary, and that's when we reach for Terac. We create and launch a real opportunity asking a general population annotator to read that summary and tell us, honestly, how clear and helpful it actually was, and to rewrite it if it wasn't good enough. That correction doesn't just sit in a database. We built a four script pipeline that turns real corrections into an improved version of the summarizing prompt, runs both versions against held out test scenarios, and then asks a second, separate group of Terac annotators to blindly judge which one is better, with no idea which prompt produced which answer. That blind judgment is what let us say, honestly, that human feedback measurably made the system better, not because we believed it would, but because we watched real people prefer it, 8 times out of 8.
A teammate built the Poke integration in parallel on its own branch, a parent can text Compass related questions over iMessage without ever opening the app, and we merged our work together once both pieces were solid.
Challenges we ran into
Almost nothing about this went in a straight line, and we think that's worth saying honestly instead of pretending it did.
We started building toward connecting parents with real, credentialed specialists through Terac, before realizing, partway through a working integration, that the hackathon's actual rules require general population annotators only, no clinical panels. That meant throwing out targeting logic we'd already built and rethinking what the feature was actually for. It also meant being honest in our own product about who a parent is actually being connected to right now, a general member of the public, not a verified professional, and treating that as a clearly labeled current limitation rather than something to gloss over.
We hit a real, documented outage on Terac's launch endpoint mid build. We proved it wasn't our bug by replaying a byte for byte successful payload and watching it fail identically, and had to keep building around a dependency we didn't control. We accidentally left two test opportunities running and burned real credits before we caught it, which taught us fast to put a hard cost cap in code, not just in our heads. We learned the hard way that a JWT with dots in it will break a URL templating system on the other end, and that the fix that came out of that bug, never handing a sensitive token to a third party at all, routing through our own redirect instead, ended up being more secure than what we'd originally designed.
Accomplishments that we're proud of
We're proud that the human in the loop story isn't a slide, it's real data. Real annotators, real corrections, a real blind comparison, an actual 8 out of 8 preference result we can show, not just claim.
We're proud of the mic button. It sounds small. It isn't. Replacing a form with a single press, and trusting an AI conversation to gather what a form would have demanded up front, is a genuine bet on meeting someone where they are instead of making them perform organization while they're scared.
We're also proud that we held the line on honesty about who a parent is actually talking to right now. It would have been easy to quietly imply the person on the other end of that call was a credentialed professional. We didn't, and we built the screened, verified version of that into our roadmap instead of our marketing.
And we're proud that when we hit real, unglamorous problems, an outage, a billing scare, a confusing third party bug, we slowed down, diagnosed them properly instead of guessing, and fixed the actual cause instead of papering over the symptom.
What we learned
We learned that "use the human in the loop" sounds like a feature checkbox until you actually build it, and then it becomes a real design question. Who are these humans, what are you asking them to judge, and how do you know their feedback actually made anything better rather than just feeling like it did. The blind comparison wasn't a nice to have. It was the only honest way to answer that question.
We learned that reading a sponsor's actual rules document, closely, more than once, costs you an hour and saves you a weekend.
We learned that the gap between "general population reviewer" and "verified medical professional" isn't a wording choice, it's a real safety boundary, and that the right move when you haven't built the second one yet is to say so clearly, not to describe the first one as if it were the second.
And we learned, again, that the parents we built this for don't need another app that's impressive. They need one thing to actually work when they're tired and scared and it's late. That's a much higher bar than it sounds like, and we tried to hold ourselves to it.
What's next for Compass
The most important next step is the one we already named honestly in this README. Taking the general population annotator pool we used for this hackathon and building the real version on top of it, a screened, verified pathway where the person who joins a parent's call is confirmed to be a medical professional, with real credential checks, not just an open task on a marketplace. That's not a someday idea, it's the direct next milestone for live connect.
We'd also want to run the before and after evaluation at real scale, not 8 scenarios, enough comparisons to trust the number, not just be encouraged by it. And we'd want to close the loop further, letting the live connect companion get better continuously, from every real call, not just the ones we happened to run during a weekend.
Mostly, though, what's next is the same thing that was first. Finding the next parent standing in a parking lot with a folder full of paper, and making sure Compass is the thing that tells them what to do next, and eventually, who to safely talk to.
Built With
- browserbase
- claude
- css
- daily.co
- html
- javascript
- pika
- poke
- sql
- supabase
- terac
- typescript
- vapi

Log in or sign up for Devpost to join the conversation.