-
-
Final Poster for Comparative Study of Bubble Growth Dynamics with DeepONet
Project Write-ups
Project Check-in #2 (Reflection Post)
Final Write-up and Reflection
Title
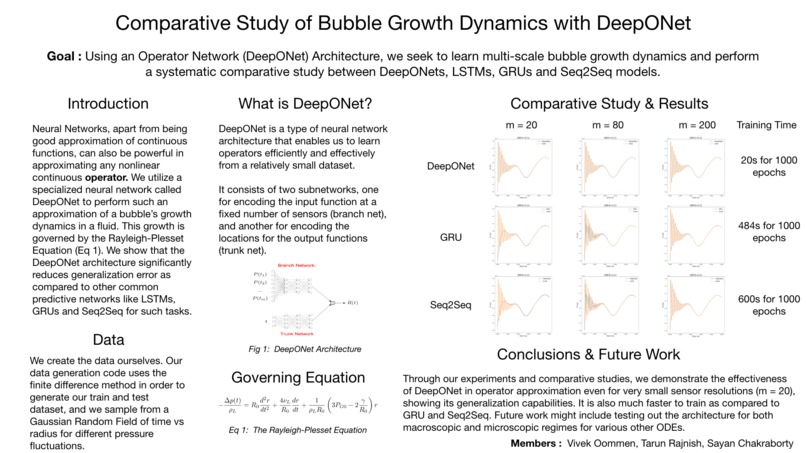
Using Operator Network (DeepONet) for learning multi-scale bubble growth dynamics and performing a systematic comparative study between DeepONets, LSTMs, GRUs and Seq2Seq models.
Who
Vivek Oommen : voommen Sayan Chakraborty : schakr12 Tarun Rajnish : trajnish
Introduction
We are implementing from scratch, the work by Chensen Lin et al., ‘Operator learning for predicting multiscale bubble growth dynamics’. In this paper, the authors propose a new deep learning framework, the DeepONet, for predicting the multiscale bubble growth dynamics governed by the Rayleigh-Plesset equation.
In the field of scientific computing, over the past years researchers have come up with several numerical methods for solving the Ordinary or Partial Differential Equations that govern the system. Although the results of this approach are accurate to a high degree and have been well investigated, the numerical simulations can be costly especially in higher dimensions. To make things worse, even a small change in the initial or boundary conditions requires the entire computations to be rerun from the very beginning as the conventional numerical techniques cannot generalize. Employing deep learning based models to learn the problems is one solution. Once the deep learning model is trained it can be used to make predictions in the unseen domain and this process is computationally cheaper than running the entire numerical solver from the very beginning as only one forward pass is required for each test case.
The novelty of our project is that we will be analyzing how the deep learning models learn in the Fourier Space/frequency domain for scientific problems. Next, the authors have only compared DeepONet with LSTMs. We will be doing systematic comparative study between LSTMs, GRUs, Seq2Seq models and DeepOnet and analyze the generalization capabilities of each type of model.
This is a Regression problem.
Related Work
We build on and combine two baseline studies for our project, namely the DeepONet paper by Lu Lu et.al. and the “Operator Learning for Predicting Multi-Scale Bubble Dynamic Growth” paper by Chensen Lin et.al. Apart from these papers, we reference a host of other blogs and documentation in order to fulfil our project goals. Some of these include the DeepONet blogpost by Ingrid Fadelli on Tech Xplore, a couple of other papers and past works on operator approximations using Neural Networks, and theory on bubble dynamics and the Rayleigh-Plesset equation.
Resource URLs Living List
DeepONet Resources https://www.nature.com/articles/s42256-021-00302-5 https://techxplore.com/news/2021-04-deeponet-deep-neural-network-based-approximate.html
Bubble Dynamics Resources https://www.cambridge.org/core/journals/journal-of-fluid-mechanics/article/abs/seamless-multiscale-operator-neural-network-for-inferring-bubble-dynamics/D516AB0EF954D0FF56AD864DB2618E94 https://authors.library.caltech.edu/25017/5/BUBBOOK.pdf
Other Artificial Neural Network References https://colah.github.io/posts/2015-08-Understanding-LSTMs/ https://en.wikipedia.org/wiki/Long_short-term_memory https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21 https://en.wikipedia.org/wiki/Seq2seq https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
Data
We are creating the data ourselves. The data generation code that implements the finite difference method (written in python) will be a part of the submission. We have generated 11 datasets, each of size 24MB. The dataset is normalized by standard scaling operation before passing it to the neural network model.
Methodology
We generated data with Finite Difference Method (using scipy.integrate.solve_ivp package in python) on the Rayleigh-Plesset equation to estimate variation in bubble radius as a function of time for a given random pressure fluctuation sampled from a Gaussian Random Field. We’ll use this generated data to compare the different types of models namely - LSTM, GRU, Seq2Seq and DeepONets.
We feel implementing the DeepONet model from scratch is the hardest part. While LSTM, GRU and Seq2Seq are covered in the coursework - DeepONet architecture of Neural Network is very new.
While DeepONets has been around and being experimented on for quite some time now (in the paper as well), we’ll go beyond comparing the model predictions of LSTM and DeepONet. We’ll be comparing GRU and Seq2Seq models as well. We will be comparing the performance of each model on testing data and verifying this statement from the paper - “from our experience, once the training data are ample, the DeepONet can predict smooth and accurate results even if only a single data point is collected per trajectory”
Metrics
Success of our project constitutes successful analysis of our models in sparse and dense data. Since, we’re trying to model a multi-scale problem - our analysis of models would yield comparative answers to 1) which neural network architecture is better at predicting with sparse vs dense dataset for such problems, 2) the generalizing capabilities of each type of architecture and, 3) how each model learns in the spectral/Fourier domain.
Yes, the notion of accuracy exists in our project. We will be generating the ground truth data by solving the Rayleigh-Plesset equation using the Finite Difference Method and comparing that with predicted data from our models with sparse as well as dense data. Each model will be minimizing Mean Squared Error (as the Loss function) computed between the true and predicted bubble radius.
The authors of the paper mentioned the superiority of DeepOnets with sparse data on forecasting time series models. The paper found LSTMs do not work well when the data is sparse as the fluctuations in bubble radius predicted/generated by LSTMs is not as accurate as that predicted by DeepONet. They used Mean Squared Error to quantify the performance.
While the paper only compares DeepOnets with LSTMs, our project will compare GRU and Seq2Seq architectures on predictions on test data and generalizing capabilities. We also use Mean Squared Error as the error metrics.
Base and target goal is to do comparative analysis of conventional function approximating models (LSTMs, GRUs and Seq2Seq) with Operator learning model (DeepOnet) on predicting multi scale bubble growth dynamics. DeepOnets conclusively performed better on sparse dataset against LSTMS. One of the stretch goals would be to see the performance of Transformers on the same problem.
Ethics
Classical neural networks are known to be universal approximators of continuous functions. However, a lesser known fact is that a neural network with a single layer can approximate accurately any nonlinear continuous operator. This leads to some interesting applications and revelations that can simplify many equations and engineering problems. However, this may entail with it a deep societal impact. Training and deploying artificial neural networks is computation and energy intensive. This adds to the strain on the environment and accelerates climate change. The use of such methodologies need to be carefully analysed and implemented at scale only if there is a dire need for such procedures. Often it is not feasible to take this approach given the societal issues it may cause.
One of the major stakeholders of our algorithm are researchers and those in academia. We aim to prove the effectiveness of DeepONet in learning nonlinear operators and hope to demonstrate that the DeepONet architecture performs better than other well-known neural network architectures in trying to approximate the underlying operator rather than function. Incorrect results may prove to be costly as researchers and students may build upon this claim and design systems using this intuition.
Division of labor
Documentation: All
Research: All
Data Creation: Vivek
DeepONet Implementation: Vivek
LSTM and GRU Implementation: Sayan
Sequence2Sequence Implementation: Tarun
Learning Visualizations: TBD
Reporting and Deliverables: All





Log in or sign up for Devpost to join the conversation.