-
-
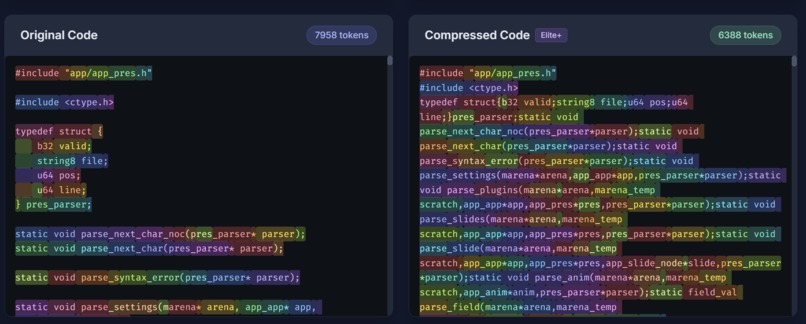
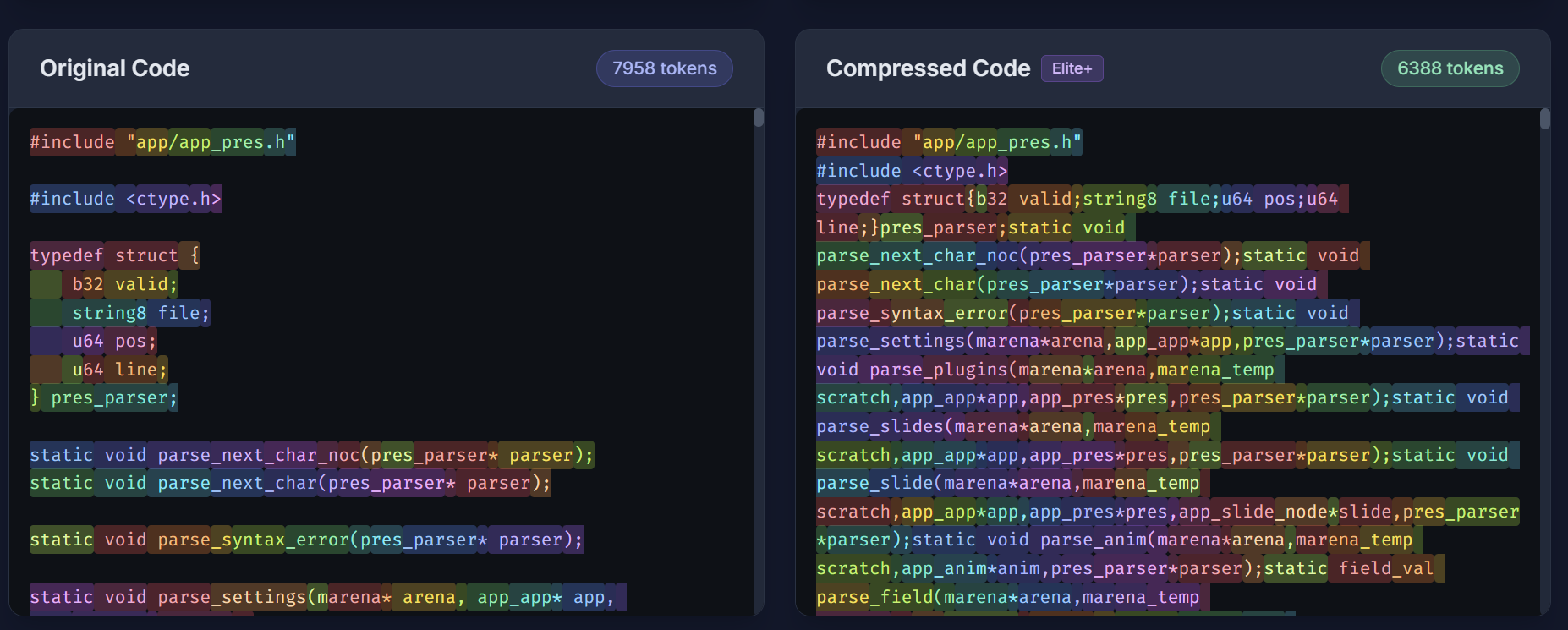
Code Compression Token Analysis
-
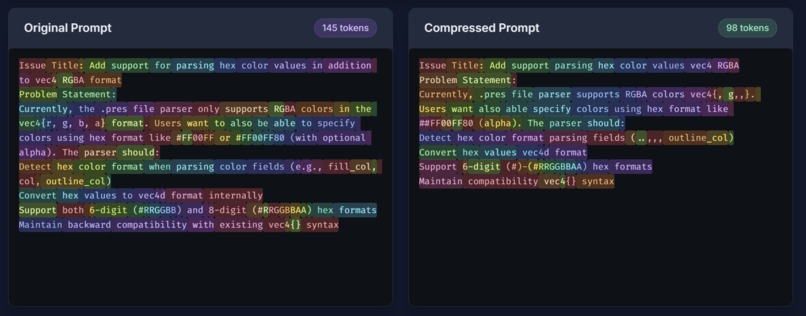
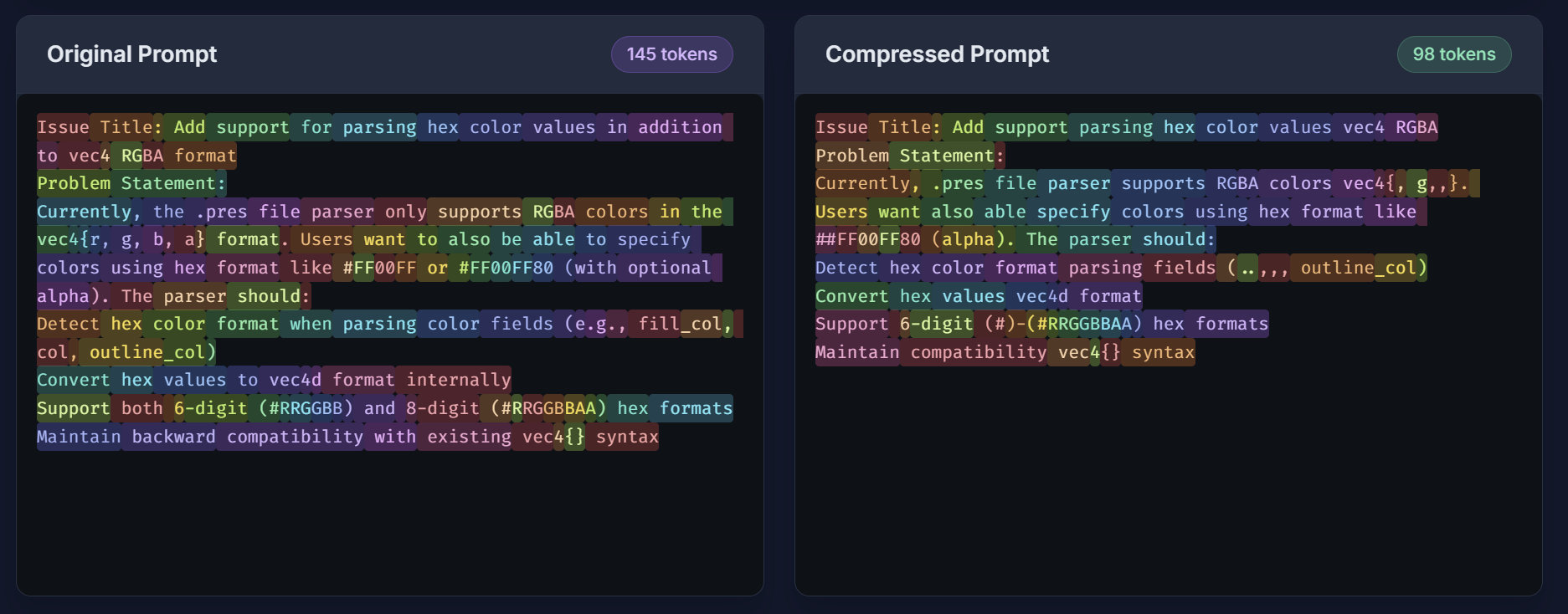
Prompt Compression Token Analysis
-
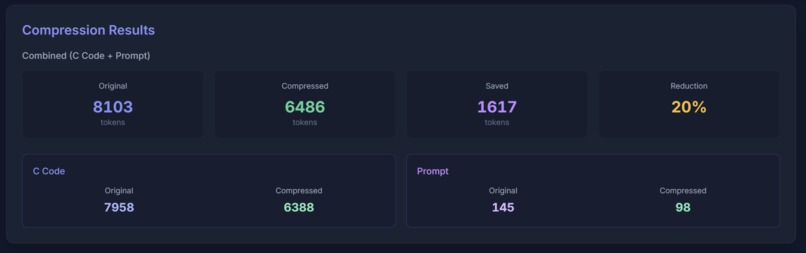
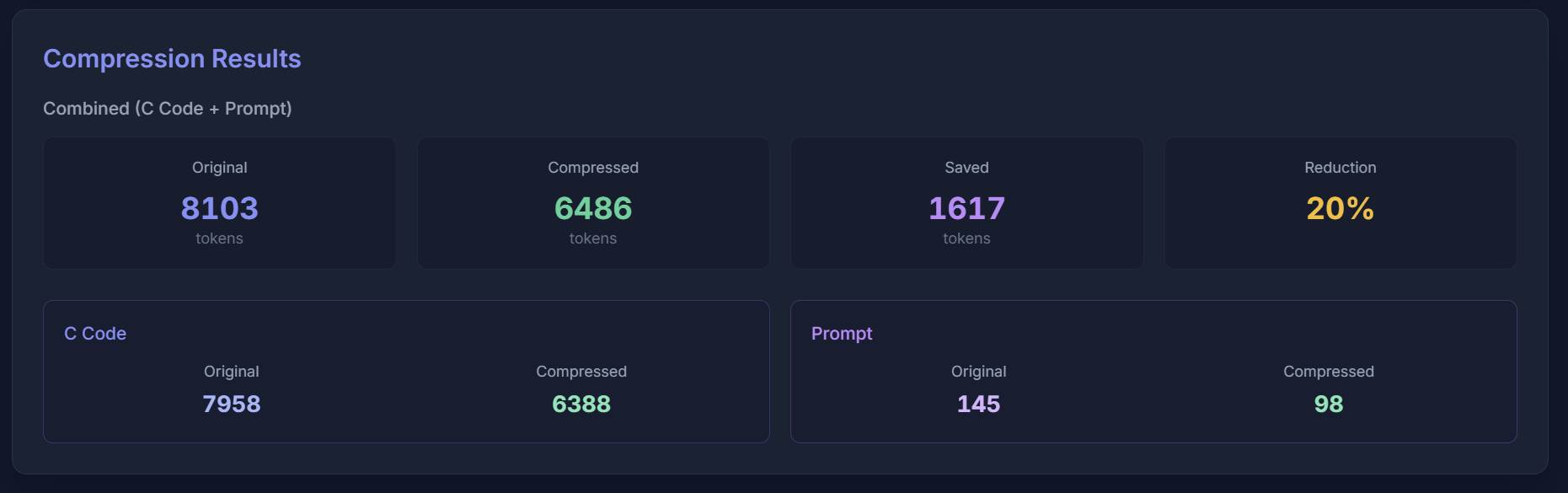
Compression results for combined code and prompt example
-
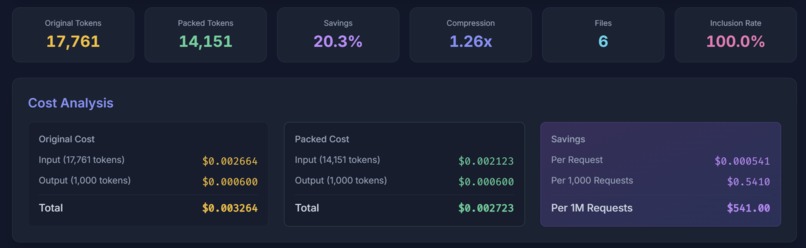
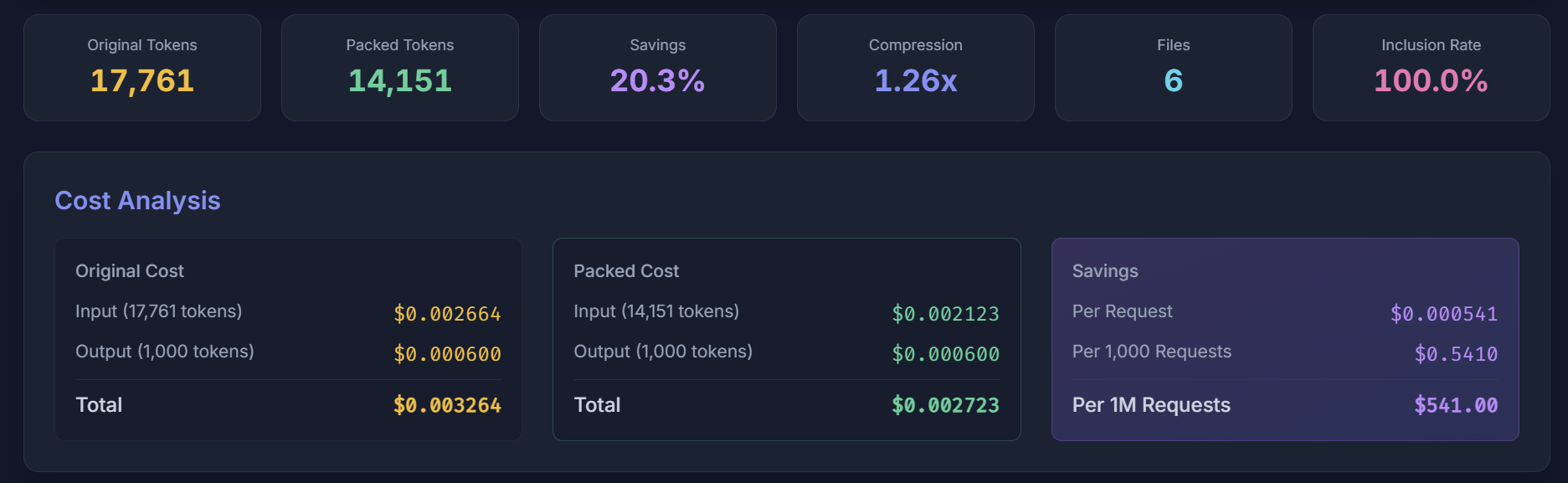
Cost analysis of compression results
Inspiration
We were inspired across many domains of programming and research. With the increased use of LLMs in programming, especially with the advent of agent-based programming, optimizing token use for these models is increasingly critical in today's world. More specifically, we wanted to target token use specifically for code. Despite this focus, we also implemented a near-SOTA semantic based compression algorithm based on TCRA-LLM: Token Compression Retrieval Augmented Large Language Model for Inference Cost Reduction.
What it does
Comaqt compresses token use for LLM through three primary algorithms. For the compression of code, we use a minification algorithm to reduce whitespace and unnecessary characters in the code, which typically reduces token usage by up to 25%. Additionally, we have a more aggressive compression algorithm for the code which identifies and targets frequently used function and variable names in the codebase and replaces them with more token-efficient alternative using a keying system. Our product intercepts the code before and after the LLM's processing so that the user does not ever see the compressed code. As for prompt compression, we based our algorithm off of Liu et. al.'s research. Our method locally runs smaller sentence-transformer embedding models to achieve an embedding vector for individual sentences of the prompt. After splitting the prompt into sentences, we split the sentences into words, and compare the original sentence's embedding to the embeddings with each word removed using a cosine-similarity score in embedding space. All of these methods in conjunction achieve a high compression ratio while maintaining model performance.
How we built it
The backend of our system in Python using tiktoken for tokenization, Hugging Face's sentence_transformers for sentence embeddings, and Flask for web hosting. We made the frontend of our system in plain HTML, CSS, and JavaScript using DevSwarm. Our website interacts directly with our backend to have the most up-to-date and accurate information displayed on the website.
Challenges we ran into
The primary challenge we ran into repeatedly throughout this project was maintaining model accuracy throughout our various compression methods. High model accuracy was imperative for our method to be worth it at all because accuracy is more important than token use. We built a benchmarking system to ensure that model accuracy was maintained. Additionally, for the prompt compression, we had many ideas and experiments that did not pan out. Our initial idea was to look at the different heads of attention after the Q-K matrix product in a smaller, local LLM. For various reasons, this did not completely pan out, but we were still able to get the prompt compression working through sentence embedding.
Accomplishments that we're proud of
We are very proud of the novelty of our approach. Our code-specific compression algorithms combine ideas across multiple programming domains to achieve our compression ratios. Additionally, we are proud of the research aspect of this project. We had to delve into the emerging research field of semantic token compression for LLMs and implement their ideas for our product.
What we learned
We learned many things both about how LLMs and AI Agents work and how to build and finish a real project. We had to combine many ideas from areas of active research, using our understanding of attention architectures, embedding spaces, and abstract semantic representations of information.
What's next for Compaqt
Our next steps include integration with existing AI Agent platforms to have a seamless end-to-end token compression. Additionally, we want to look into more aggressive and home-grown compression techniques that could achieve higher accuracy. This may include the training of our own, custom models to identify which tokens contribute the most to LLMs' outputs.


Log in or sign up for Devpost to join the conversation.