Inspiration
Our inspiration stems from the pressing need for privacy-conscious AI tools within the corporate environment. Companies are increasingly seeking to leverage the power of AI for efficiency but are hampered by legitimate concerns over data security and privacy. We saw an opportunity to bridge this gap by integrating a Large Language Model (LLM) with a secure, internal Knowledge Base (KB) to create an assistant that respects corporate data governance policies.
What it does
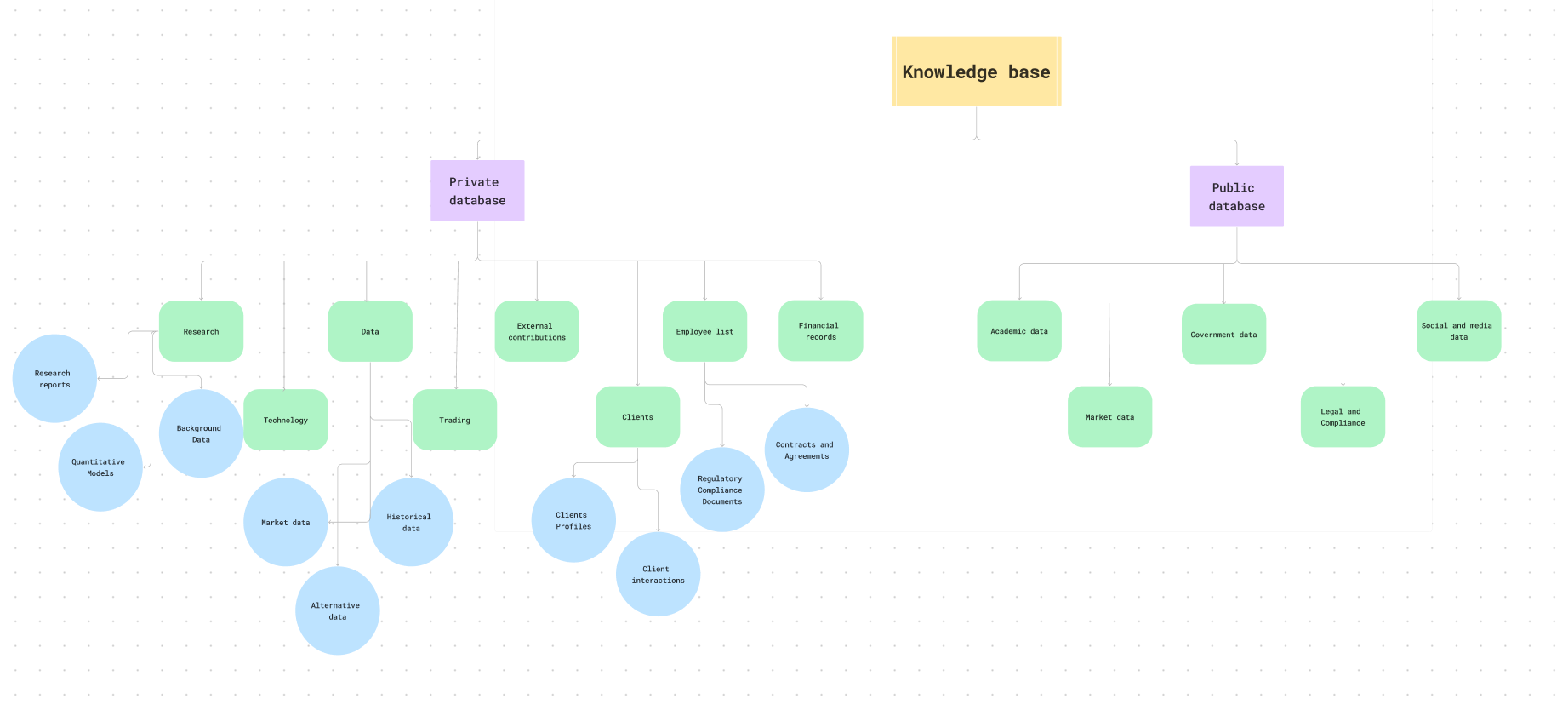
The Company-used Large Language Model Assistant (CLLMA) provides employees with a powerful tool to query the company’s knowledge base using natural language. It understands context within the company’s domains, provides accurate information retrieval, and helps streamline workflows without compromising sensitive data. The assistant can generate code, debug, summarize documents, and facilitate onboarding by tapping into a vast array of internal corporate knowledge, all within a secure, private framework.
How we built it
We built CLLMA on LangChain, utilizing the Llama 13B models suitable for a corporate setting. We prioritized security from the outset, ensuring all data remains on-premises or within a private cloud. The knowledge base is built from vectorized representations of corporate documents, allowing for efficient information retrieval while fine-tuning the LLM on non-sensitive data ensures domain-specific relevance. The user interface is developed as a chatbot within a WebUI, enabling a straightforward and intuitive interaction for users.
Challenges we ran into
One of the biggest challenges was ensuring that the vectorization of the KB did not diminish the quality of the data retrieval. We also faced difficulties in fine-tuning the LLM on a limited dataset due to privacy restrictions. Ensuring user queries did not inadvertently reveal sensitive information required careful design of the input fields and AI prompts. Balancing performance with privacy was a constant theme throughout our development process.
Accomplishments that we're proud of
We're particularly proud of creating an assistant that addresses a significant market need without compromising on privacy—a solution that's fully compliant with corporate data governance policies. Developing a retrieval system that maintains high accuracy and speed despite the limitations posed by privacy considerations has been a rewarding challenge. We're also proud of the user interface we've crafted, which has been praised for its ease of use during our pilot tests.
What we learned
Throughout this project, we've gained deeper insights into information retrieval techniques, the importance of domain-specific tuning of language models, and the intricacies of data privacy in AI applications. We've also learned a lot about user experience design, particularly in the context of creating intuitive interfaces for complex AI interactions.
What's next for Company-used Large Language Model Assistant
Moving forward, we aim to expand CLLMA’s capabilities to cover more languages and regional dialects, accommodating global enterprises. We plan to explore more advanced vectorization and retrieval techniques to further enhance the accuracy and speed of the system. Additionally, we'll conduct more comprehensive pilot programs to refine our model and prepare for a broader roll-out. Scalability, continuous learning from user interactions, and further improvements in privacy-preserving technologies will also be central to our roadmap.



Log in or sign up for Devpost to join the conversation.