
Inspiration
Digital exploitation, grooming, sextortion, coercion, and cyberbullying often develop gradually across multiple messages rather than appearing as one clearly harmful statement.
However, systems designed to detect these risks can also create serious concerns involving privacy, surveillance, false positives, and automated accusations.
We created CompanionCare AI to explore a safer alternative: a privacy-preserving, human-in-the-loop decision-support platform that helps qualified analysts identify concerning conversational patterns, review supporting evidence, and prioritize cases without automatically labeling anyone as an offender or victim.
Our goal is not to replace investigators or safeguarding professionals. CompanionCare AI is designed to help nonprofit safety teams, survivor-support organizations, and trained reviewers make more informed decisions while keeping human judgment at the center of the process.
What it does
CompanionCare AI analyzes de-identified conversations for patterns associated with:
- Cyberbullying and harassment
- Online grooming
- Secrecy and isolation
- Emotional dependency
- Sexual escalation
- Threats and coercion
- Emotional distress
- Persistent or increasing conversational risk
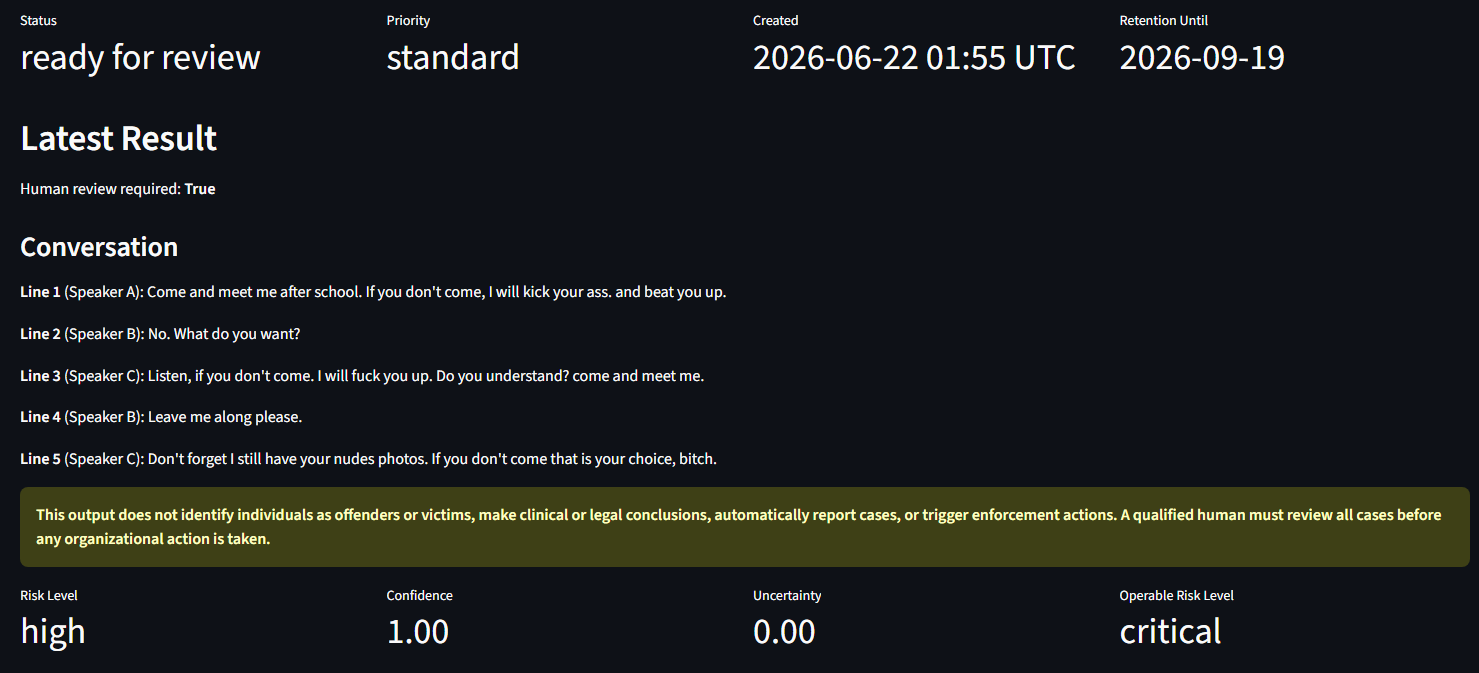
Before analysis, the system removes personally identifiable information and replaces participant identities with conversation-local labels such as SPEAKER_A and SPEAKER_B.
The platform combines several types of signals:
- Transformer-based cyberbullying classification
- Conversation-level grooming detection
- Structured LLM safety signals
- Deterministic safety rules
- GoEmotions-based emotion analysis
- Accumulated risk, trend, and persistence across conversation windows
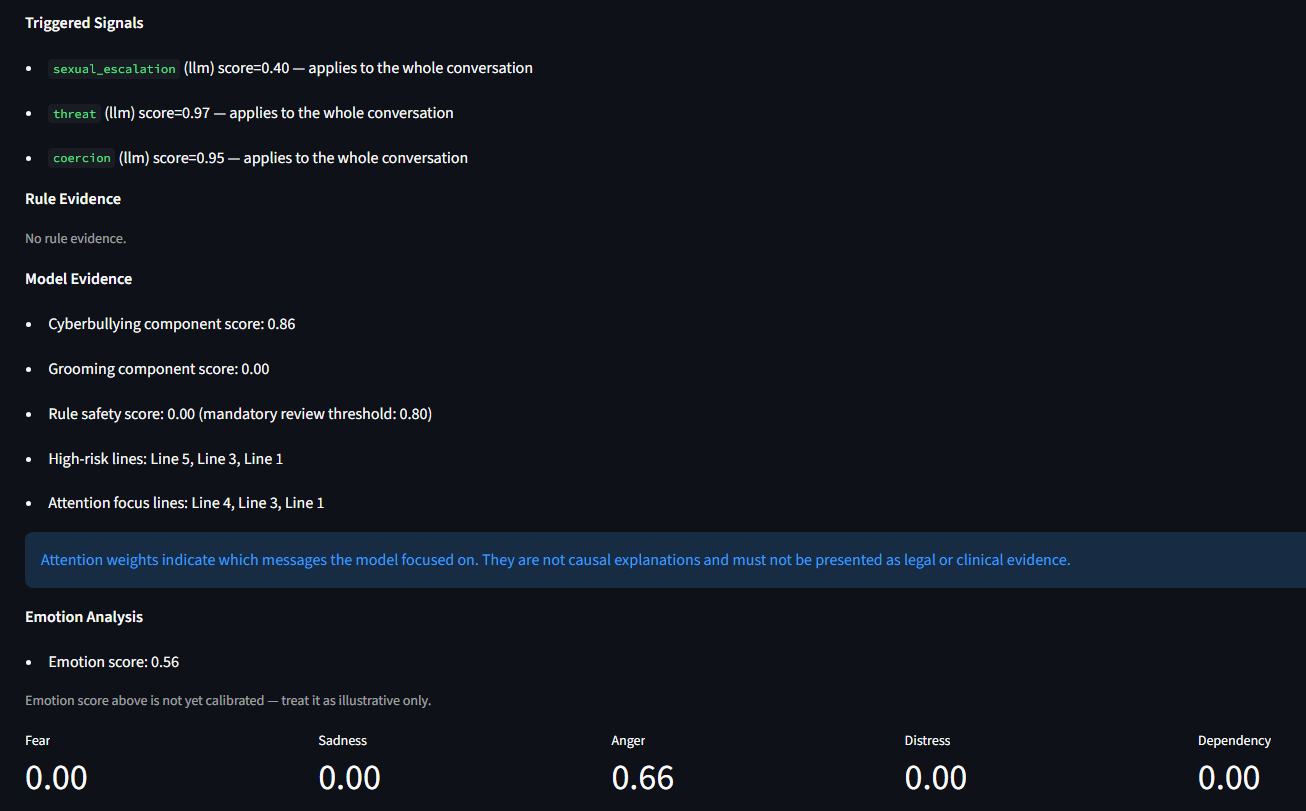
The analyst dashboard displays:
- Cyberbullying and grooming component scores
- Rule-based and LLM-extracted safety signals
- Fear, sadness, anger, distress, and dependency indicators
- Confidence and uncertainty information
- Redacted message evidence
- Known model and data limitations
- Human-review recommendations
Long conversations are divided into sequential windows instead of analyzing only the most recent messages. Risk state is carried across those windows so earlier warning signals are not silently discarded.
CompanionCare AI does not automatically report cases, make legal or clinical conclusions, identify individuals as offenders or victims, or trigger enforcement. A qualified human reviewer remains responsible for all organizational decisions.
How we built it
CompanionCare AI uses a hybrid architecture that combines machine learning, deterministic rules, structured LLM extraction, emotion analysis, privacy preprocessing, and human review.
AI analysis pipeline
- Privacy preprocessing
Personally identifiable information is redacted before model inference. Speaker identities are remapped locally within each conversation, messages are ordered, and the input is checked for completeness.
- Conversation windowing
Conversations are processed in windows of up to 12 messages. Longer conversations are divided into sequential, non-overlapping windows and passed through the same historical-risk tracker.
- Structured signal extraction
An LLM extracts six behavioral safety signals:
- Secrecy
- Isolation
- Dependency
- Sexual escalation
- Threat
- Coercion
A deterministic rule engine separately detects patterns such as secret requests, contact migration, age references, image requests, and threat phrases.
- Cyberbullying detection
A trained transformer-based classifier evaluates individual messages. The conversation-level score combines the highest-risk message with the average of the three highest-risk messages.
- Grooming detection
A conversation encoder produces a contextual representation of the exchange. We trained and compared:
- Variant A: text-only
- Variant B: text plus deterministic rules
Variant B is currently used in the local and real inference modes.
- Emotion analysis
A frozen GoEmotions classifier evaluates messages independently. Its outputs are mapped into five analyst-facing dimensions:
- Fear
- Sadness
- Anger
- Distress
- Emotional dependency
- Temporal risk tracking
The system tracks accumulated risk, change in risk, and persistence across multiple windows. A deterministic early-warning baseline identifies persistent or rapidly increasing patterns.
- Explainability
The Explainability Service assembles structured evidence from model scores, rules, LLM signals, redacted messages, confidence values, and data limitations.
Application architecture
The MVP uses:
- FastAPI for backend APIs
- Streamlit for the analyst dashboard
- SQLite for the local hackathon demonstration
- An in-process
asynciojob queue for asynchronous analysis - JWT-based authentication and role-based permissions
- Structured audit records
- Separate
stub,local, andrealmodel execution modes
The production architecture is designed to replace the local substitutions with PostgreSQL, Row-Level Security, Redis, durable job queues, object storage, MFA, centralized monitoring, and independently retained audit storage.
These production components are documented architectural targets and are not all implemented in the current hackathon MVP.
Challenges we ran into
Limited and imperfect training labels
PAN12 identifies predator authorship, but it does not provide complete conversation-level grooming probabilities, full grooming-phase annotations, or labels for all six behavioral dimensions.
Because of this limitation:
- The Grooming Head uses predator-presence-derived weak labels.
- The six-dimensional Behavior Head is not trained.
- The fully supervised Early Detection Head is not trained.
- Current early warning uses accumulated risk, trend, and persistence instead.
Context-dependent false positives
Live testing showed that the grooming model can assign high risk to harmless meeting or farewell language such as:
“Great practice today, see you tomorrow.”
Meeting arrangements can be a real escalation pattern in grooming conversations, but the current model sometimes applies that association without enough contextual discrimination.
We documented this limitation instead of applying an unvalidated scoring workaround.
Domain mismatch in cyberbullying data
The original cyberbullying model was primarily trained on short social-media text. It produced false positives on longer, formal, or supportive conversations.
Adding neutral long-form examples reduced false positives, but it also revealed another limitation: without matching long-form harmful examples, the model could learn shortcuts related to sentence length or writing style.
LLM cost and reliability
The LLM-enhanced grooming model requires safety-signal extraction for a very large number of conversations.
A full PAN12 run would require approximately 222,000 LLM calls. At the measured prototype cost and sequential processing speed, this would require substantial cost and several days of execution.
The smoke test also revealed that LLM requests may return refusals. We added explicit refusal handling so one refused response no longer crashes an entire training or inference run.
Keeping the architecture and implementation consistent
Our architecture includes production features such as durable queues, priority processing, organization administration, session revocation, file uploads, object storage, bulk export, API versioning, and operational alerts.
A code-to-document gap analysis found that several of these features remain future production work rather than completed MVP features.
Examples include:
- Urgent cases currently use the same FIFO queue as standard cases.
- Organization Admin member-management endpoints are not implemented.
- Logout only clears client-side tokens; server-side token revocation is not implemented.
- File upload and object storage are not wired into the API.
- Bulk export and sensitive-operation re-authentication are not implemented.
- Several production alert conditions are documented but not yet automated.
This review helped us separate our current implementation from our intended production architecture.
Accomplishments that we're proud of
We built an end-to-end prototype connecting:
- Privacy preprocessing
- Trained cyberbullying and grooming models
- Rule-based safety detection
- LLM signal extraction
- Emotion analysis
- Temporal risk tracking
- Explainability
- Asynchronous processing
- Analyst review workflows
- Audit logging
Our Grooming Head experiments achieved the following results on the official PAN12 test corpus:
| Model | Precision | Recall |
|---|---|---|
| Text-only Variant A | 0.781 | 0.744 |
| Text + Rules Variant B | 0.790 | 0.763 |
The improvement is small and currently based on one random seed, so we do not claim statistical significance. However, it provides preliminary evidence that deterministic rules can add useful information beyond text representations alone.
We are especially proud that code audits and live testing led to concrete security, privacy, and reliability improvements.
We identified and fixed issues involving:
- Concurrent audit-log hash-chain writes
- Contradictory analyst decisions submitted at the same time
- DLQ entries being redriven or closed more than once
- Worker crashes consuming retry attempts without traceability
- Cross-organization DLQ metric leakage
- Failed submissions leaking concurrency slots
- Phone numbers without punctuation bypassing PII redaction
- Validation errors returning unredacted input text
- Retention deletion leaving message evidence in result JSON
- Threat rules missing common violent phrasings
- Long messages crashing the lightweight stub model
- Real mode failing to load the Claude API key from
.env - Dashboard input remaining when switching submission modes
We also added:
- Sequential processing for conversations longer than one window
- Fail-safe handling for invalid uncertainty values
- A
localmode that loads trained checkpoints without requiring paid LLM calls - Role-aware dashboard tabs
- Redacted conversation transcripts in the case-detail view
- Rule safety and mapped-emotion outputs in the Explainability API
- Explicit dashboard warnings for uncalibrated scores and known model biases
What we learned
We learned that responsible safety AI is not only a model-development problem.
A useful system also requires:
- Privacy protection
- Authorization and organization isolation
- Secure failure handling
- Auditability
- Retention and deletion policies
- Honest uncertainty communication
- Human-review workflows
- Clear separation between prototypes and validated production features
We also learned that conversational context is essential.
A harmful-looking sentence may become clearly benign when surrounding messages are considered. At the same time, individually harmless messages can form a concerning pattern when repeated over time.
Hybrid systems can provide practical advantages:
- Machine-learning models can recognize patterns that fixed rules miss.
- Deterministic rules provide transparent and testable severe-signal safeguards.
- LLMs can identify nuanced behavioral signals.
- Emotion models provide a separate view of emotional state.
- Historical tracking identifies persistent or escalating risk.
However, each component introduces different limitations. LLMs introduce cost, latency, inconsistency, and refusal handling. Trained classifiers inherit dataset biases. Rules can miss language that developers did not anticipate.
Most importantly, we learned that confidence is not the same as correctness. A model can produce a stable but incorrect prediction. Therefore, CompanionCare AI displays confidence, component scores, evidence, data limitations, and review requirements separately.
What's next for CompanionCare AI
Our next model-development priorities are:
- Collect expert-reviewed calibration labels
- Calibrate the Safety, Emotion, and Overall Scores
- Train Cyberbullying Stage 2 with message-in-context data
- Run the full LLM-enhanced Grooming Variant C experiment
- Repeat grooming experiments across multiple random seeds
- Evaluate identity-disjoint and cross-domain generalization
- Add properly sourced benign and harmful long-form examples
- Improve handling of benign meeting and farewell language
- Train the Behavior Head with genuinely annotated behavioral data
- Develop a supervised or conservatively weakly supervised early-detection model
- Evaluate warning recall, false-warning rate, calibration, and detection latency
- Expand threat and coercion rule coverage while controlling false positives
- Conduct evaluations with qualified safeguarding professionals
Our next platform-development priorities are:
- Replace the FIFO queue with priority-aware durable processing
- Implement Organization Admin member and role management
- Add server-side logout, account suspension, and token revocation
- Add file upload and object-storage workflows
- Implement idempotency keys
- Add API versioning and request-size limits
- Add re-authentication for sensitive actions
- Implement result caching using privacy-protected input hashes
- Add circuit breakers around external model calls
- Add urgent-case wait-time, API-error, drift, and audit-failure alerts
- Migrate the local MVP from SQLite to PostgreSQL with Row-Level Security
- Add Redis, MFA, centralized monitoring, and independently retained audit storage
CompanionCare AI will remain a decision-support system, not an automated accusation, reporting, diagnosis, or enforcement platform.
Its future development will continue to prioritize privacy, transparency, measurable validation, operational safety, and qualified human judgment.
Built With
- and
- anthropic-claude-api
- asyncio
- bert
- bigru
- distilbert
- fastapi
- git
- goemotions
- hugging-face-transformers
- jwt-authentication
- numpy
- pandas
- pydantic
- pytest
- python
- pytorch
- roberta
- scikit-learn
- sqlalchemy
- sqlite
- streamlit

Log in or sign up for Devpost to join the conversation.