-
-
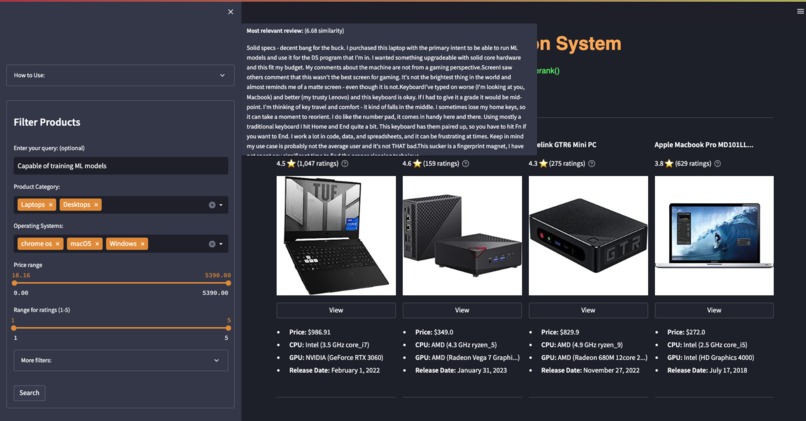
Hover over '?' icon to see relevant reviews
-
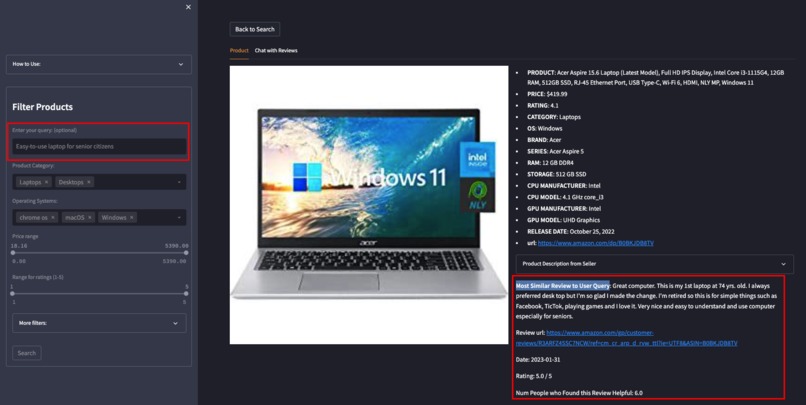
'View' page contains detailed product specs and relevant reviews
-
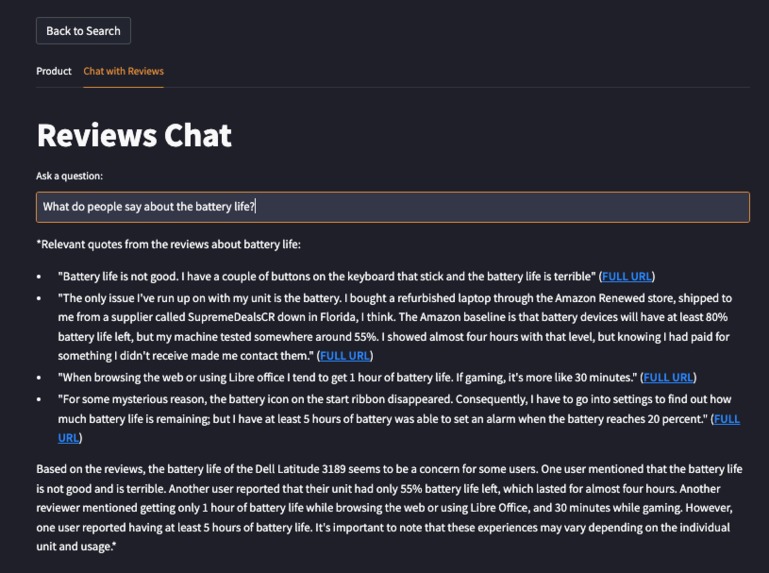
Access unbiased aspect-based sentiments from reviews
-
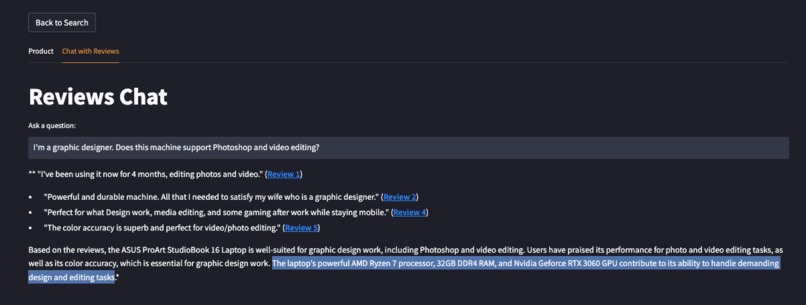
Get answers based both on reviews and product specs
Commercial Consensus: Revolutionizing E-Commerce with Intelligent Semantic Search
- Try it out: Commercial Consensus (hosted on AWS)
- NOTE - video was filmed before final optimized search process was implemented, but it gives a decent overview of the first draft. Updated demo here: https://github.com/sfuller14/public_ref/blob/master/recsys.gif.
- Libraries & Execution Flow Diagrams
- Inspiration and references
Overview
Commercial Consensus is an intelligent search platform designed to revolutionize e-commerce recommendation systems. By combining the power of structured tabular data with unstructured customer reviews, we provide an innovative solution to the longstanding problem of data quality in e-commerce platforms.
The Problem
Traditional e-commerce recommendation systems, such as collaborative filtering and graph-based methods, rely heavily on structured, tabular data. However, this approach is fraught with limitations due to the widespread missing and inconsistent data inherent to third-party seller platforms:
Example of inconsistent data availability for two products in the same category:
Missing data across our full dataset:
Even when data is available, it is often heterogeneous:
This data quality issue hampers the effectiveness of recommendation systems, thereby reducing platform revenue generation as well as impeding optimal user experience.
The Solution
Commercial Consensus tackles this problem head-on by harnessing the latent information within customer reviews. Utilizing state-of-the-art technologies, such as Pinecone's vector search engine over indexed product review embeddings and Cohere's reranking endpoint, our platform performs a hybrid (tabular + semantic) search. This innovative approach provides a new dimension of search, enabling users to tap into the Commercial Consensus – an aggregated, reliable body of knowledge derived from customer reviews - in a targeted and personalized way.
Features
Enhanced Search
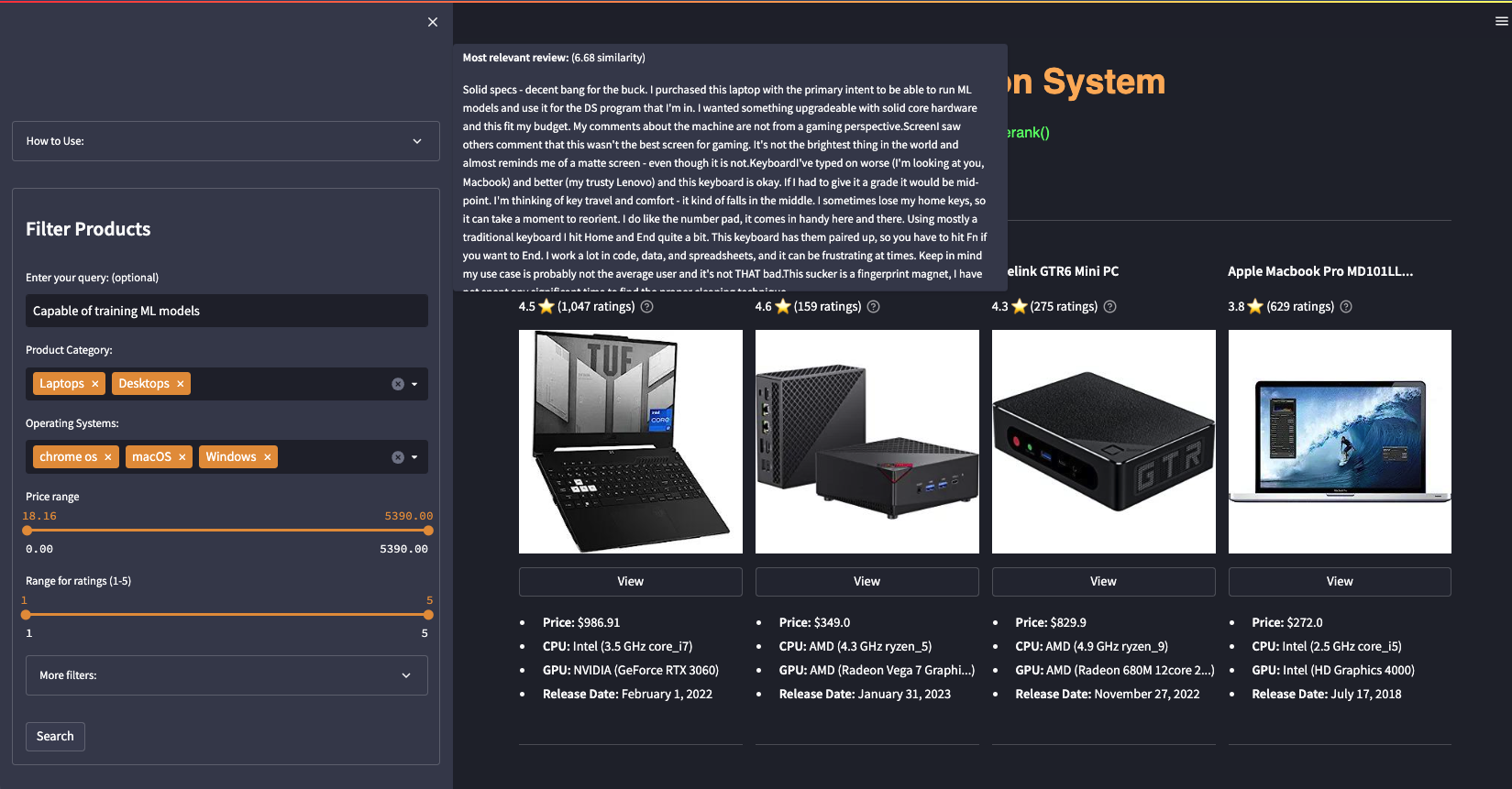
Commercial Consensus offers an ultra-personalized and efficient search experience, powered by pinecone.query() and cohere.rerank(). Our platform goes beyond lexical search/simple keyword matching, delivering results based on enhanced semantic similarity to user queries. This approach provides a more intuitive and user-centric search experience, improving product discovery and enhancing user satisfaction.
Ultra-relevant recommendations using pinecone.query() (with metadata & namespace filters) + cohere.rerank()
Hover over the '?' icon to see the most similar review to your query.
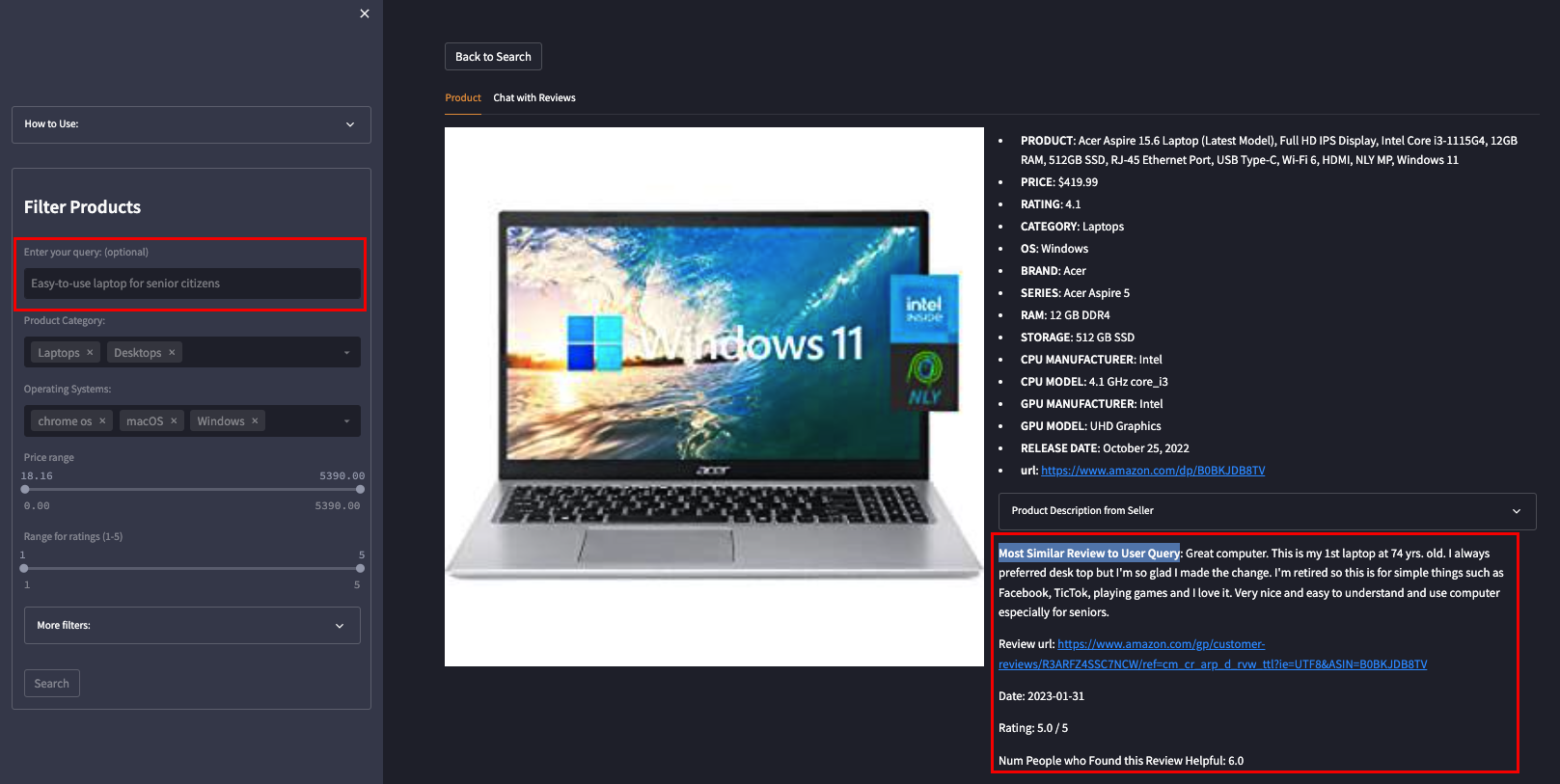
'View' page contains detailed product specs and relevant reviews
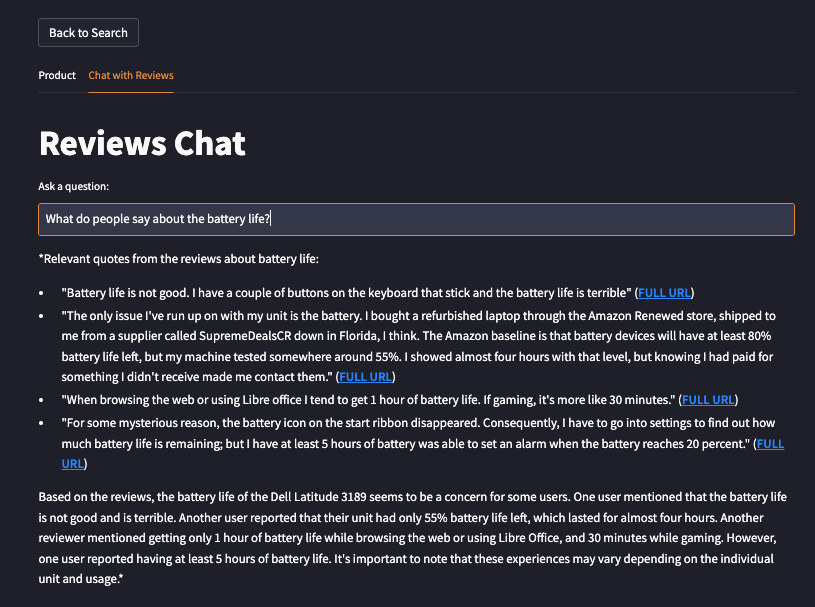
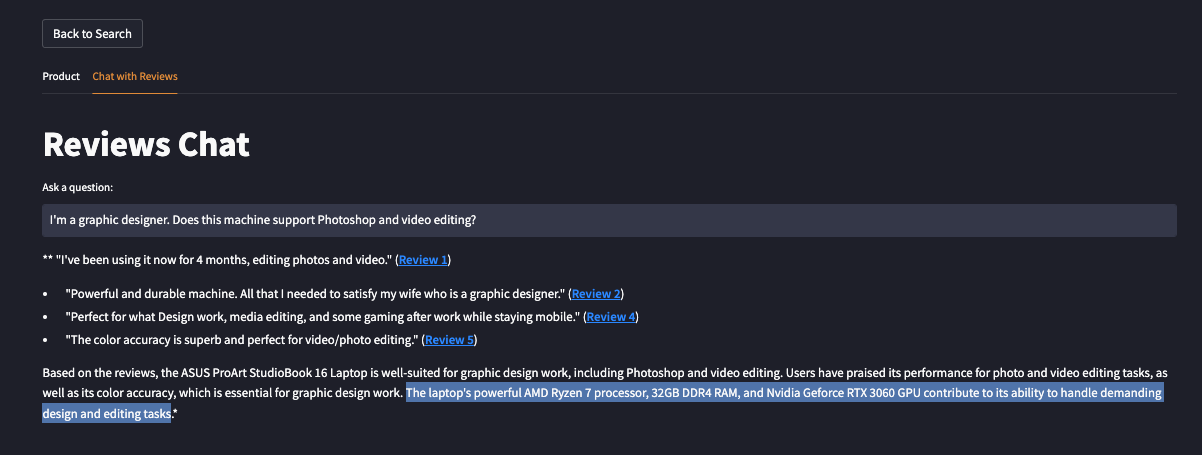
Intelligent Chat Interface
Our platform features a chat interface that leverages the power of quality-controlled retrieval-augmented generation (RAG). By utilizing a custom pinecone.query() + cohere.rerank() + openai.ChatCompletions() chain, users receive detailed responses based on both product specifications and relevant reviews. This feature not only provides valuable insights to potential buyers but also serves as a tool for sellers performing market research.
Access aspect-based sentiments from reviews
Custom pinecone.query() + cohere.rerank() + openai.ChatCompletions() chain.
Targeted retrieval + controlled generation using both aggregated reviews and product specs.
Libraries
Commercial Consensus is built using a suite of cutting-edge technologies. Pinecone enables efficient vector similarity search over large volumes of data organized by namespace (product embeddings, word embeddings, and combined) and stored with metadata. Cohere's reranking capabilities are utilized heavily to enhance the relevance of the inital query results and ensure high quality documents are retrieved for GPT-4 in the Chat portion. A customized prompt (as well as providing product specs along with product reviews) limits hallucination and maximizes response relevancy by OpenAI's GPT-4 model. Streamlit enabled a backend dev to throw a passable front-end on the system.
Commercial Consensus
The name "Commercial Consensus" embodies the core value proposition of our platform. By aggregating and semantically searching customer reviews, we are able to capture the collective wisdom of the consumer base - a consensus on the quality and features of products. This consensus, driven by real user experiences, provides a reliable and unbiased source of information that complements, and often outperforms, traditional tabular data.
Try It Out
Experience the future of e-commerce with Commercial Consensus. Hosted on AWS.
Narrated Demo:
NOTE - video was filmed before final optimized search process was implemented. It gives a decent overview of the first draft, but please refer to the GIF or, better yet, try out the app!
Technical Appendix
Re-ranking is an important and widely-used step in modern search engines. It is generally run on the results of a lighter-weight lexical search (like TF-IDF or BM25) to refine the results. Re-ranking using BERT variants has shown SOTA search status in recent years:
Cohere recently introduced their rerank endpoint along with some research on the associated search improvement it provides:
We found the endpoint to be highly performant, both in terms of quality and response time. It handles up to 1,000 documents (passed as raw text, not embeddings) in a single call, and returns the re-ranked results almost instantly.
Each call made to pinecone.query() in main.py is followed by co.rerank(). This occurs at three points in our application:
Execution Flow
1) When the user enters a query and presses 'Search'
EVEN THOUGH THIS IS POTENTIALLY CONFUSING TO THE USER, rerank_score * 100 is displayed as 'Similarity' in the tooltip on hover (to try to get a sense of how to set threshold since this is just demo app)
2) When a user clicks View on a product
3) When a user enters a question in the Chat tab
The user question + product's title (which for Amazon contains a hodgepodge of specs) + top 12 reviews + the system prompt are passed to openai.ChatCompletion.create() (with tiktoken truncating the reviews if cl100k_base max context window is exceeded):
Product Title Example
This is likely done for facilitating lexical search in the presence of variably-populated data fields. We're able to exploit this approach within the LLM prompt. See the awesome examples from the pinecone documentation for more on this topic in the context of querying. Combining sparse-dense search with our tabular-dense approach (and adding in reranking) could be an interesting area for further investigation.
While pinecone.query() without re-ranking was often sufficient for simple and well-formed queries, certain query formations (like specific negation expressions) led to undesirable results. Adding re-ranking also generally appeared to show better matching on longer reviews, however in some cases this not necessarily desirable (i.e. re-ranking led to longer reviews being prioritized while a more succinct match would be preferred for display on the home page). In other cases (specifically during RAG chaining), the longer reviews led to significantly better output. More testing is needed here.
A few examples of using pinecone.query() alone vs. pinecone.query()+cohere.rerank():
In the above, notice that both reviews mentioning BSOD in the re-ranked results go on to say that they resolved it.
Note that these comparisons are not reflective of pinecone's querying performance, but of cosine similarity search on 'text-embedding-ada-002' vs. the re-ranked equivalent.
Inspiration and References
The materials provided by pinecone's documentation are extremely high quality.
- This post by James Briggs on hybrid (sparse textual + dense image) search was the main inspiration for this project & the proposed system is largely a riff/expansion on that case study (with the main additions being tabular filtering, reranking, and LLM incorporation)
- Chat feature inspired by LangChain's ConversationalRetrieverChain with reranking added
Built With
- amazon-web-services
- cohere
- openai
- pinecone





{kind=link}
Log in or sign up for Devpost to join the conversation.