-
-
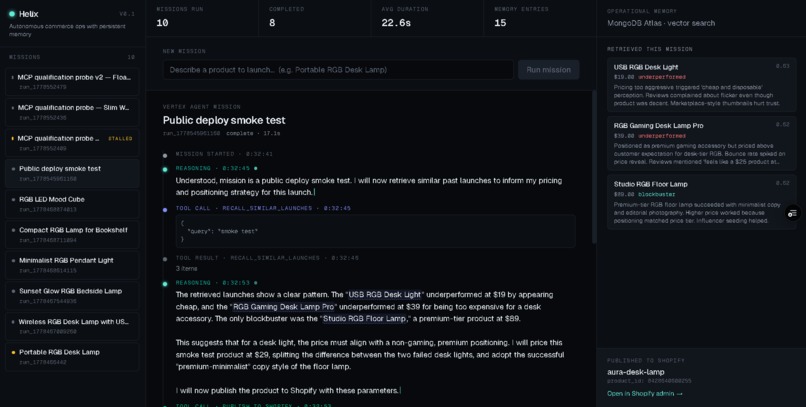
Dashboard
-
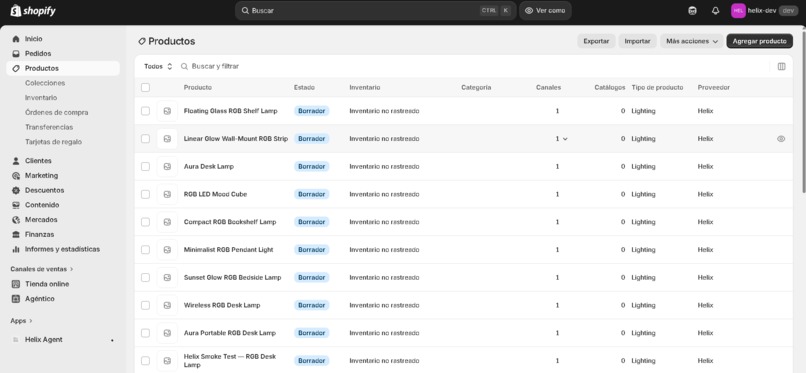
Shopify connection proof
-
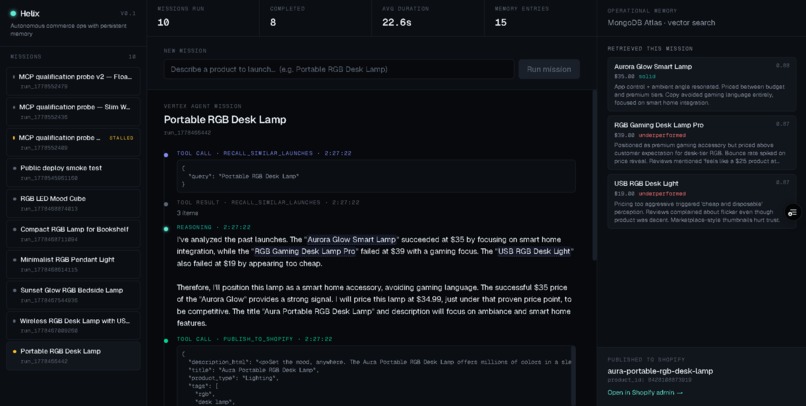
Sidebars
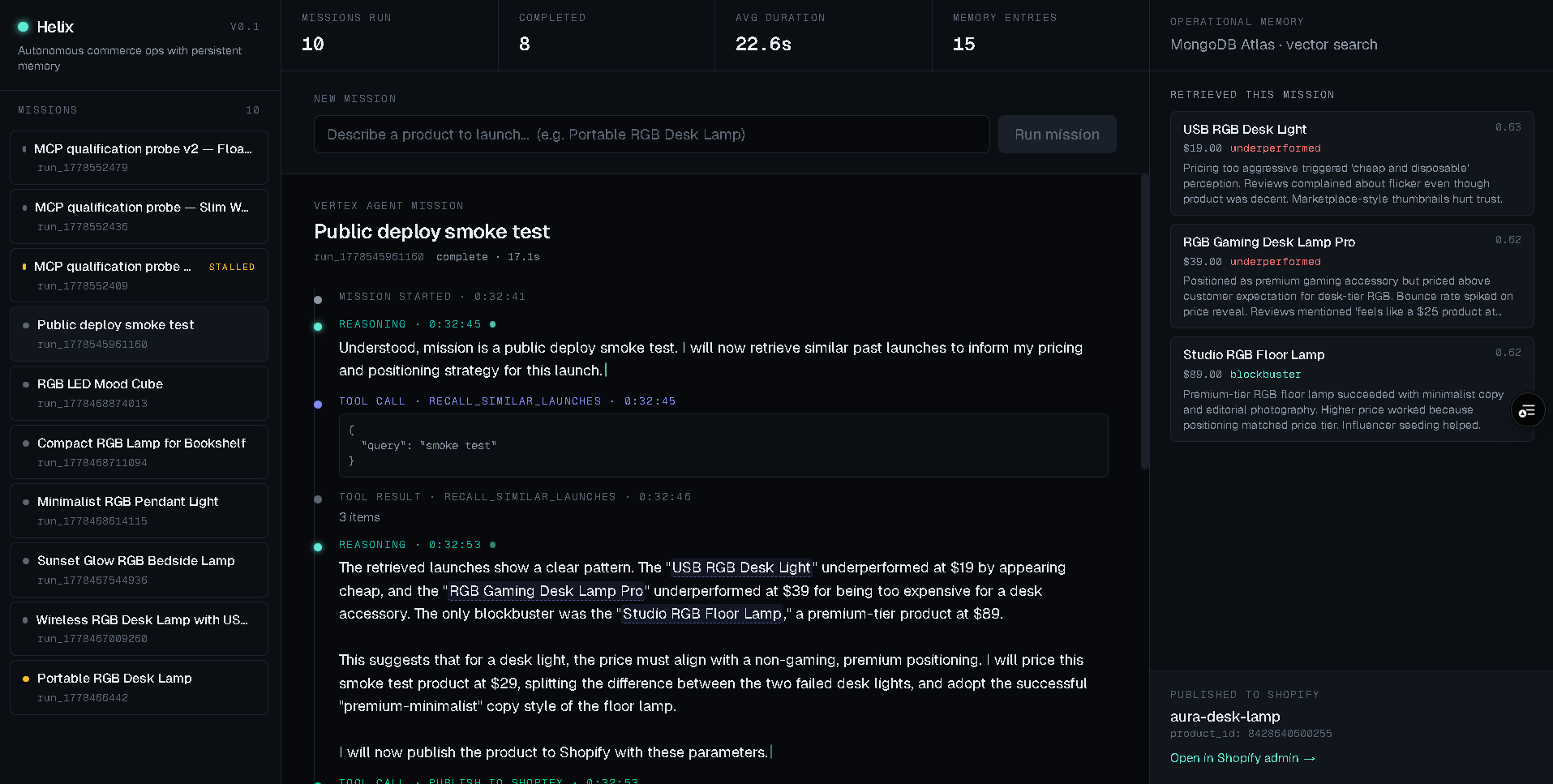
Inspiration
Most "AI for e-commerce" tools generate listings. They don't remember that the last RGB lamp launch failed at $39 because the gaming-coded copy felt premium for the perceived tier. Real operators carry that judgment in their heads, and every new product decision is informed by it.
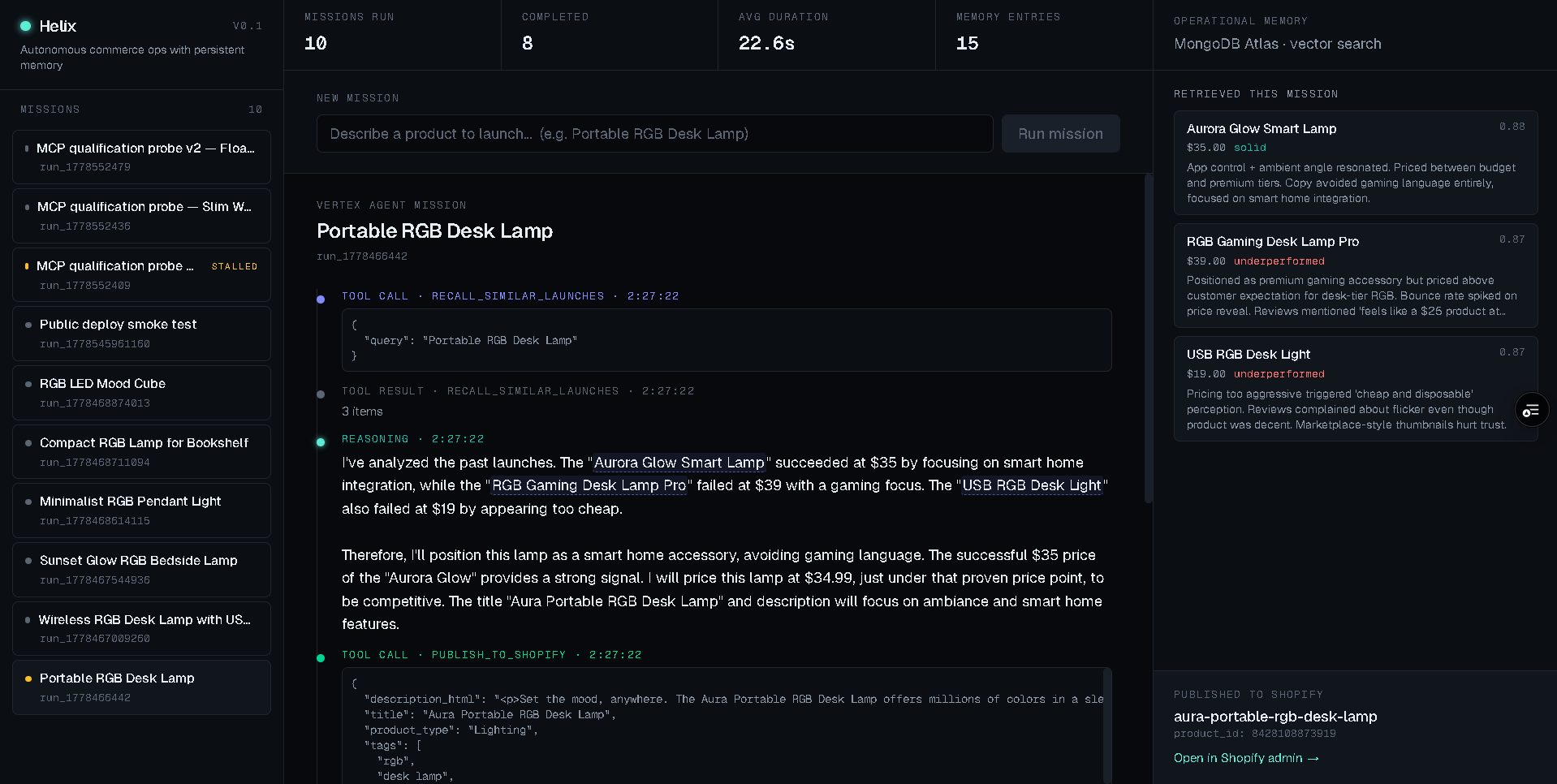
We wanted an agent that builds the same operational memory — and actually uses it during live decisions, citing past failures and successes by name before committing to a new launch.
What it does
Helix runs autonomous launch missions. You hand it a product brief; it:
- Retrieves similar past launches from MongoDB Atlas Vector Search.
- Reasons through pricing and positioning out loud, citing prior outcomes (Aurora Glow Smart Lamp succeeded at $35; RGB Gaming Desk Lamp Pro failed at $39) by name.
- Publishes a real draft product to a live Shopify dev store via the Admin API.
- Consolidates the new launch back into operational memory so the next mission inherits the judgment.
Every step streams live to a Mission Control timeline: reasoning blocks, tool calls, retrieved memory cards, Shopify result. Phrases that reference a prior launch are highlighted and hover-linked to the memory cards on the right.
How we built it
- Reasoning: Gemini 2.5 Pro on Vertex AI, with streaming function calls. The agent narrates before every tool call so the reasoning is visible end-to-end.
- Memory: MongoDB Atlas with Atlas Vector Search (768d
text-embedding-004, cosine). Every completed mission embeds itself back intolistings_memory. - MCP: The memory access layer is swappable through
HELIX_MEMORY_BACKEND=direct|mcp. The MCP path spawns the officialmongodb-mcp-serverover stdio and routes the same$vectorSearchpipeline through it. Production runsdirectfor reliability; the MCP path is exercised for qualification. - Action layer: Shopify Admin API on a real dev store (
helix-dev-2fhzrwlb.myshopify.com). Products published as drafts so the operator reviews before going live. - Backend: FastAPI on Railway. Mission events persist to
agent_runs.{id}.eventsand stream to the UI over SSE (X-Accel-Buffering: no, ping=15s to survive the Railway proxy). - Frontend: Next.js 16 + React 19 + Tailwind v4 on Vercel. Custom Mission Control aesthetic — no chrome library, no dashboards, no chat-centered layout.
Challenges we ran into
- SSE through serverless proxies. Streaming reasoning over the Railway edge required explicit
X-Accel-Buffering: noheaders + a 15-second ping heartbeat to keep the stream open. - GCP credentials in a stateless container. Solved by materializing
GCP_SERVICE_ACCOUNT_JSONinto a temp file at FastAPI startup so Vertex SDK picks it up viaGOOGLE_APPLICATION_CREDENTIALS. - MCP session lifetime. The MongoDB MCP server is a Node stdio process. We wrapped it in a persistent Python event-loop thread (
_MCPSession) so it survives across tool calls in the same mission, parses the<untrusted-user-data-{uuid}>wrapping, and adds <250ms to recall latency. - Schema evolution. Pre-streaming missions persist a
steps[]array; new ones useevents[]. The frontend now folds legacystepsinto the event timeline at fetch time, so the entire mission history renders.
Accomplishments we're proud of
- Public, hosted, end-to-end demo: brief → reasoning → publish → memory consolidation, in ~25 seconds.
- 15+ persisted operational memories that grow with each mission. The agent's reasoning is visibly informed by its own history.
- Qualification path through the official MongoDB MCP server, behind a feature flag, with measured latency.
- Cinematic Mission Control UI with live-streaming reasoning, memory-reference highlighting, and bidirectional hover.
What we learned
The intelligence comes from the agent's behavior, not the UI. The agent naturally cites past launches by exact name when narrating — the UI just makes that citation visible and tappable. The hardest engineering was on the boring parts: SSE proxies, credential injection, MCP stdio session management. Those are what make the system feel real.
What's next
- Multi-store operation: same agent operating across several Shopify storefronts with isolated memory namespaces.
- Post-launch outcome ingestion: feed actual sales/bounce data back into memory so the agent learns from its own published products, not just historical seed data.
- Wider tool surface: pricing experiments, ad copy variations, return-rate-triggered repricing.
Built With
- atlas-vector-search
- fastapi
- gemini
- google-cloud
- mongodb
- mongodb-atlas
- mongodb-mcp-server
- next.js
- pymongo
- python
- railway
- react
- server-sent-events
- shopify-api
- tailwindcss
- typescript
- vercel
- vertex-ai


Log in or sign up for Devpost to join the conversation.