-

Home Screen
Inspiration
Programmatically reading text from images and natural language processing seem like such cool concepts. Using Siri or Alexa was such a mystery, and we wanted to delve into this world and decrypt it a little bit. Gaining an understanding of how these processes work would help us decide what we want to develop in the future.
What it does
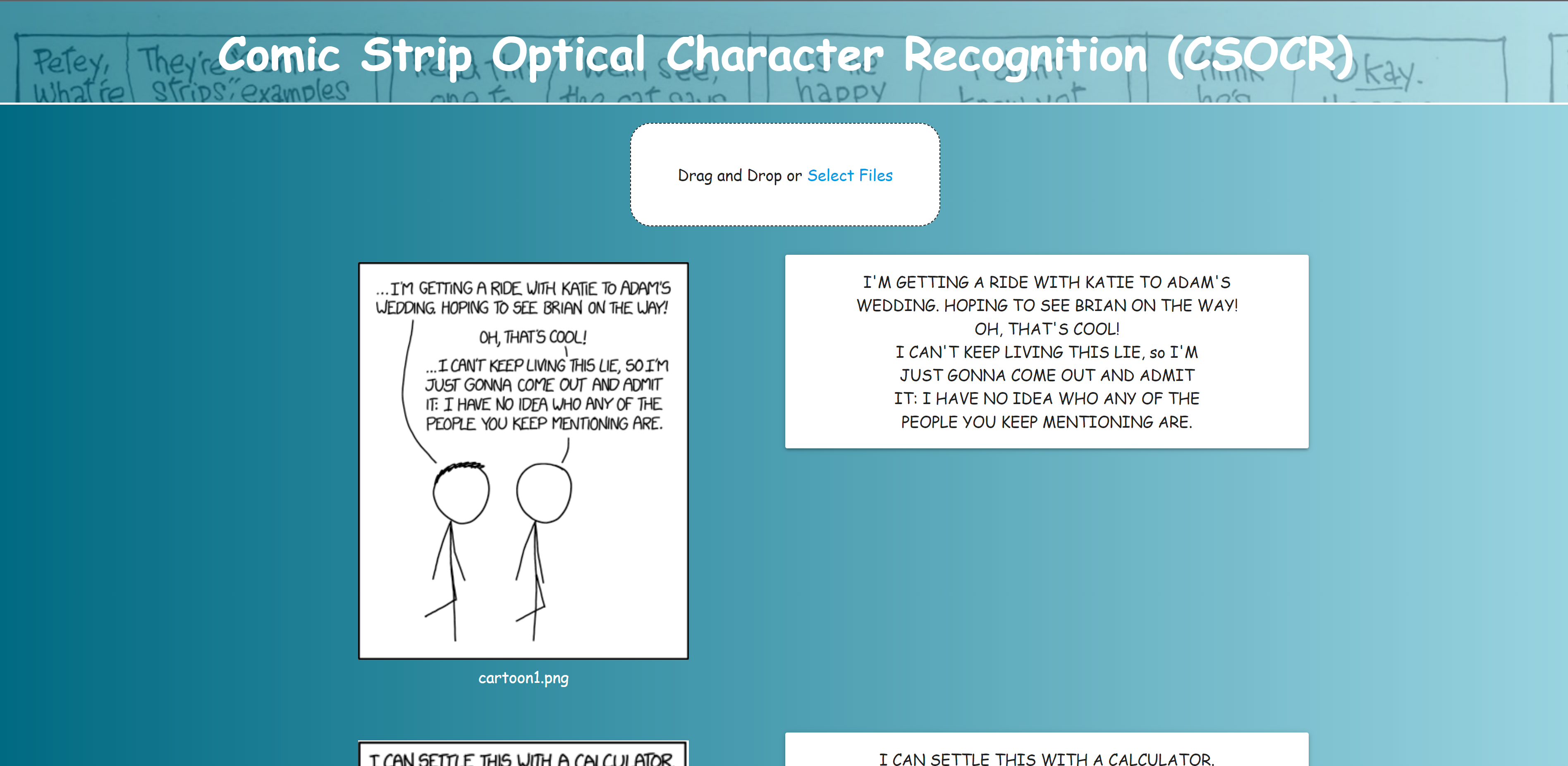
This program displays a webpage where users can upload one or more images that have text. The application will extract the text from the images and display them along with their extracted text in addition to ordering them sequentially in conversation.
How we built it
Our application uses Dash, a Python library that uses React.js and Plotly.js to create the webpage layout, and Materialize, a responsive web framework to apply a clean, minimalistic design to the page. We based our program on Amazon's Textract, a text-extracting model, and Google's Word2Vec model, which implements the Word2Vec architecture to encode text with semantic embedding. Throughout the process, we used Dash's local server to debug and AWS Elastic Beanstalk to assist with version control and deployment.
Challenges we ran into
We originally tried to use a Tesseract model, but the accuracy proved to be insufficient even with custom training data. Therefore, we made the executive decision to switch to Textract. Additionally, we had trouble figuring out how to order the comics in the sample data, knowing that natural language processing was almost necessary and that neither of us had experience with this. Finally, one of the most concerning issues was making our application compatible with AWS Elastic Beanstalk. Our earlier versions had no problem with this, but when we added the conversationally sequential ordering, there were major bugs with the pyemd library, which is used by Gensim's Word Mover's Distance algorithm.
Accomplishments that we're proud of
Before today, we did not have much experience with artificial intelligence and APIs in general, but through extensive research, we were able to produce a working application using several machine learning models.
What we learned
We learned how to train an OCR program to recognize new fonts with improved accuracy. This makes it easier to customize models for specific use cases. Secondly, the integration of machine learning and front-end development proved to be a very diverse environment where our team was able to focus on areas of interest for the future. Perhaps the most important lesson we learned, however, was that even though a project idea may seem outside of the scope of our skill sets, focusing on progressing a little at a time will yield amazing results.
What's next for Comic Strip Optical Character Recognition (CSOCR)
Future areas of development could include full deployment on a public domain as well as a better integrated natural language processing system.


Log in or sign up for Devpost to join the conversation.