Inspiration
Pathologists today have to manually scan enormous microscope slides to find cancerous tissue — it's slow, subjective, and error prone. We wanted to see if we could automate the most tedious part: finding where the tumor actually is.
What it does
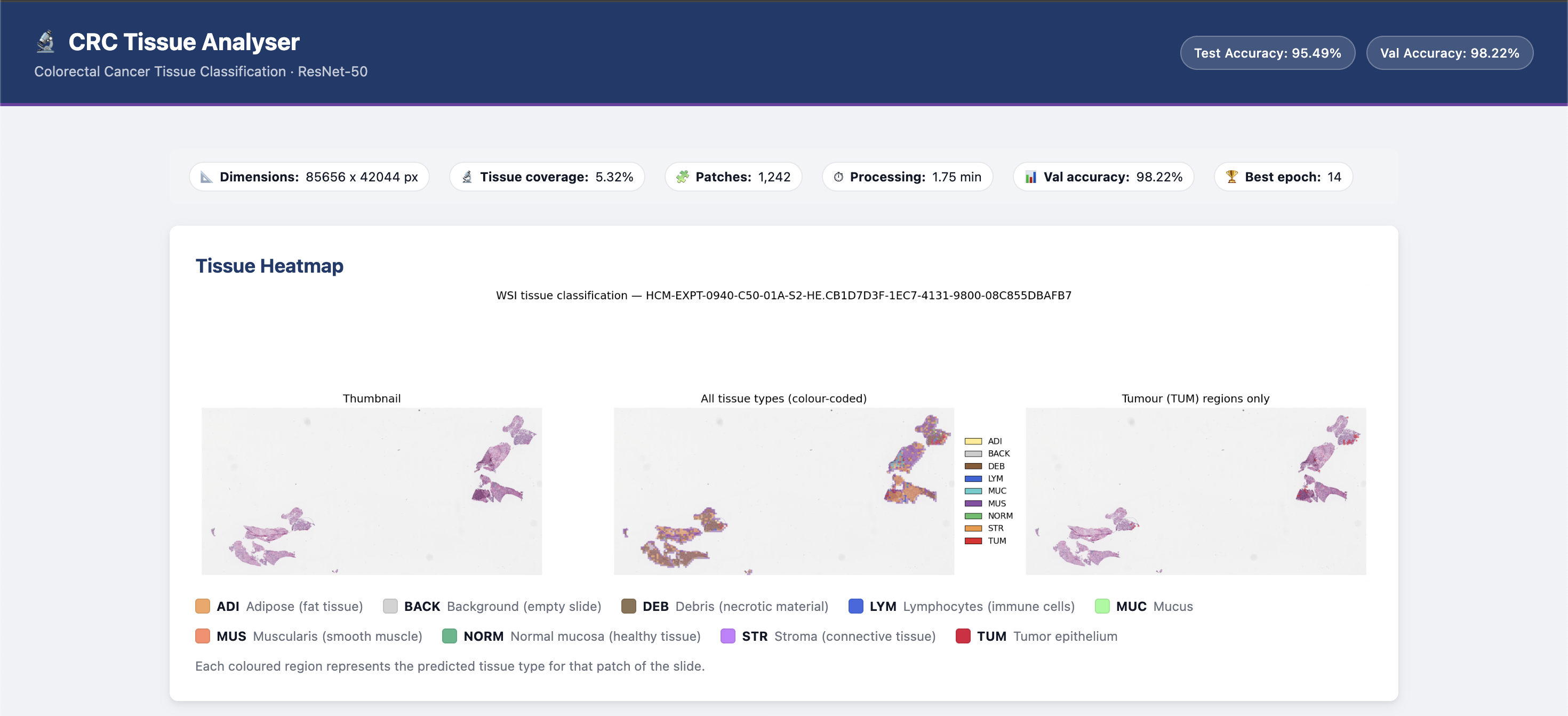
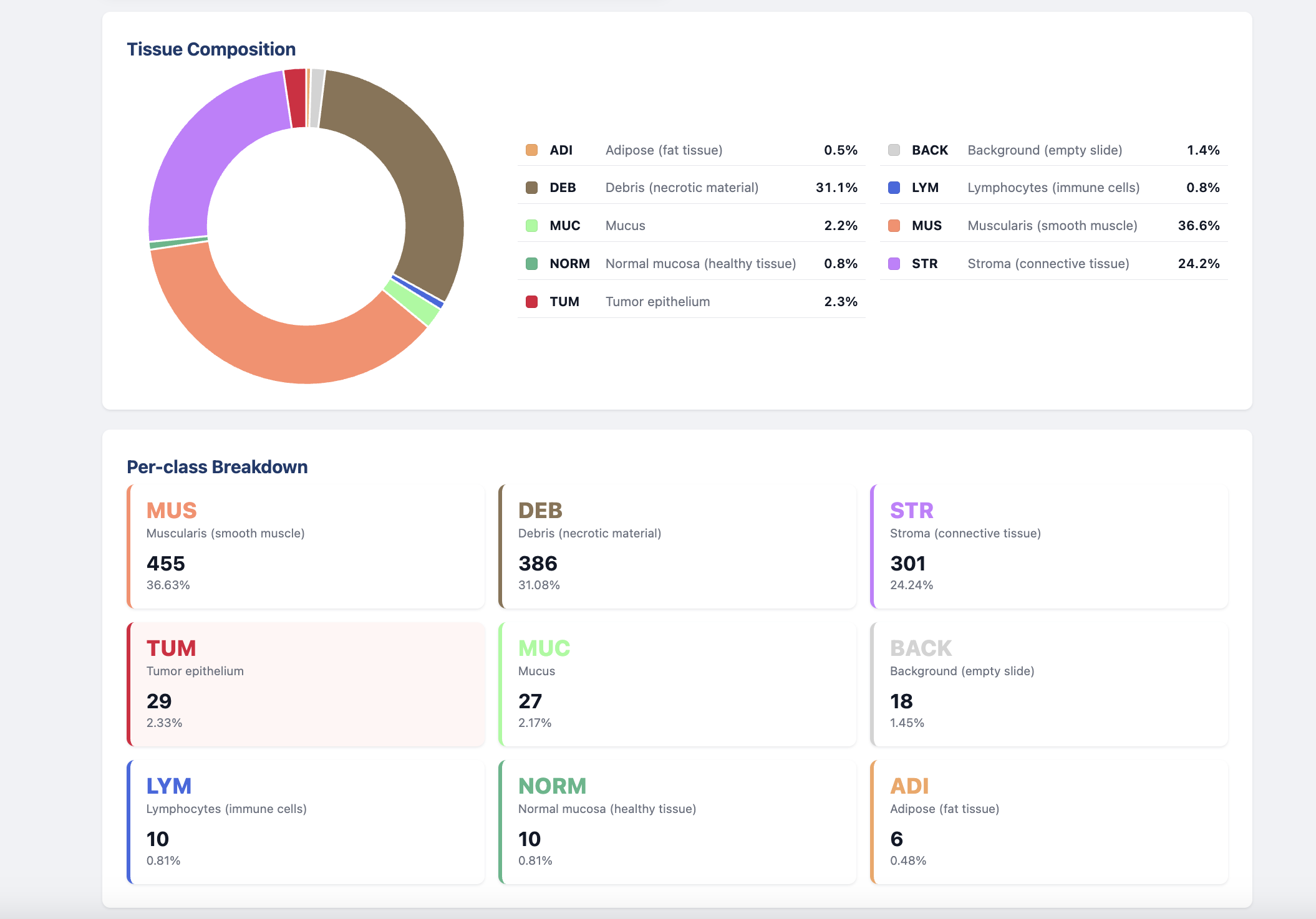
It takes a colorectal cancer biopsy slide, breaks it into thousands of small patches, and classifies each one into one of 9 tissue types. Those predictions get stitched back into a heatmap overlaid on the original slide, giving a visual map of exactly where cancer tissue is present and how much of the slide it occupies.
- ADI — Adipose (fat tissue)
- BACK — Background (empty slide, no tissue)
- DEB — Debris (necrotic/dead cells)
- LYM — Lymphocytes (immune cell clusters)
- MUC — Mucus (glandular secretions)
- MUS — Muscularis (smooth muscle)
- NORM — Normal mucosa (healthy colon)
- STR — Stroma (fibrous connective tissue)
- TUM — Tumor epithelium (the cancer)
How we built it
We fine-tuned a ResNet-50 convolutional neural network pretrained on ImageNet, training it on the NCT-CRC-HE-100K dataset of 4,500 H&E-stained histology patches. The training pipeline was built in PyTorch. For whole slide image inference, we used OpenSlide to extract patches at the correct microns-per-pixel resolution to match training magnification. A saturation-based HSV filter screens out empty glass before any patch hits the model.
Challenges we ran into
We had no GPU — everything trained on CPU, which meant long iteration cycles and careful decisions about dataset size. Whole slide images can be several gigabytes each, so patch extraction had to be memory-efficient. Calibrating the correct magnification level across slides from different scanners was also a non-trivial problem.
Accomplishments that we're proud of
Reaching 95% accuracy on CRC-VAL-HE-7K — a benchmark drawn from different patients and different scanners than the training data — without any stain normalization. Building a full end-to-end pipeline that goes from a raw slide file all the way to a tumor heatmap. Doing it while learning PyTorch, transfer learning, and digital pathology concepts from scratch.
What we learned
Transfer learning works surprisingly well on medical imaging even with modest data. The classification model is actually the easier half — the real engineering challenge is the inference pipeline that runs it over a full slide efficiently. We also learned how much domain knowledge matters: understanding what each tissue type looks like and why certain classes get confused shaped every decision we made.
What's next for Colorectal Cancer Tissue Classification
Push accuracy from 95% toward the 97% target with longer training and tuning. Add stain normalization so the model generalizes better across hospitals and scanners. Integrate an LLM as a reasoning layer on top of the heatmap — reading the spatial distribution of tumor patches and generating a natural language pathology report summarizing findings.
Built With
- kaggle
- matplotlib
- numpy
- opencv
- openslide
- pillow
- python
- pytorch
- scikit-learn
- torchvision



Log in or sign up for Devpost to join the conversation.