-
-
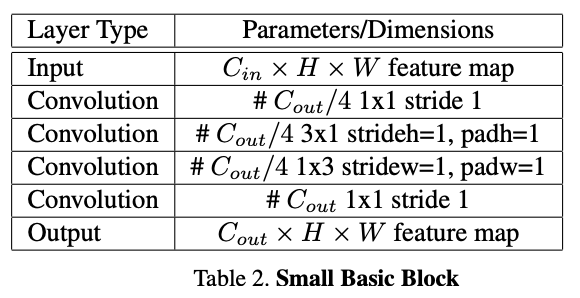
Model architecture (taken from paper linked in description)
-
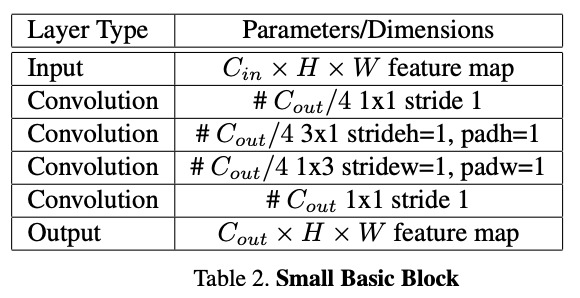
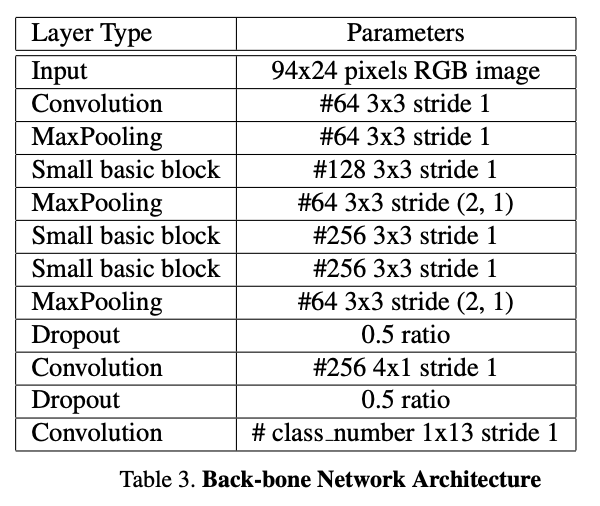
Small Basic Block architecture (from paper)
-
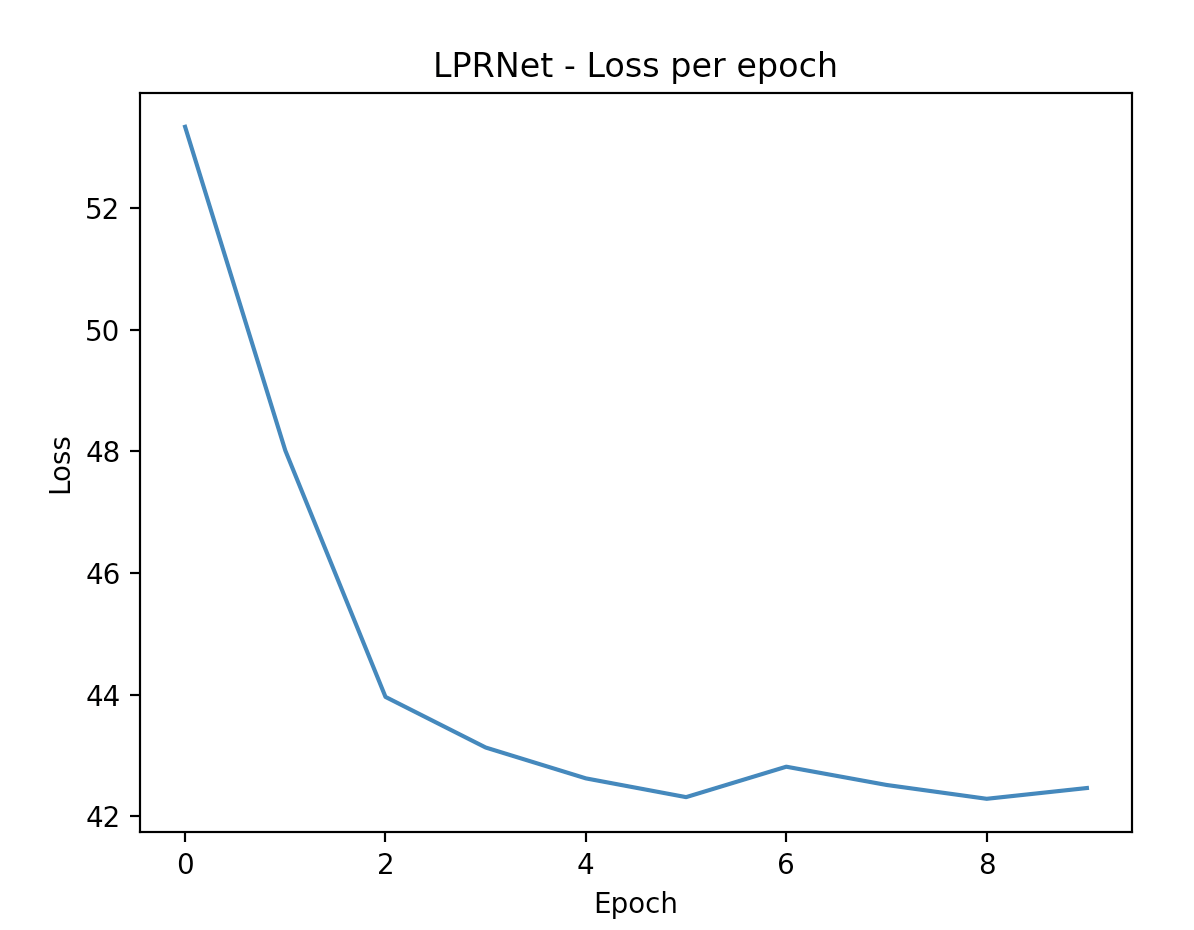
LPRNet loss
-
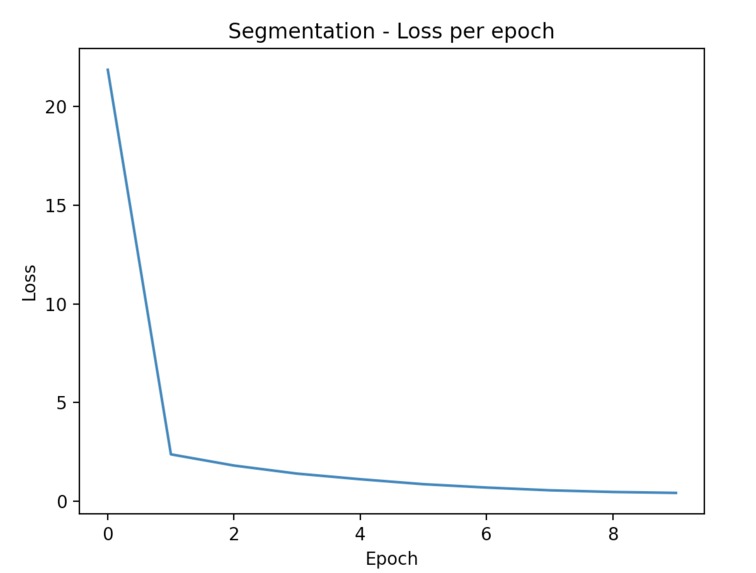
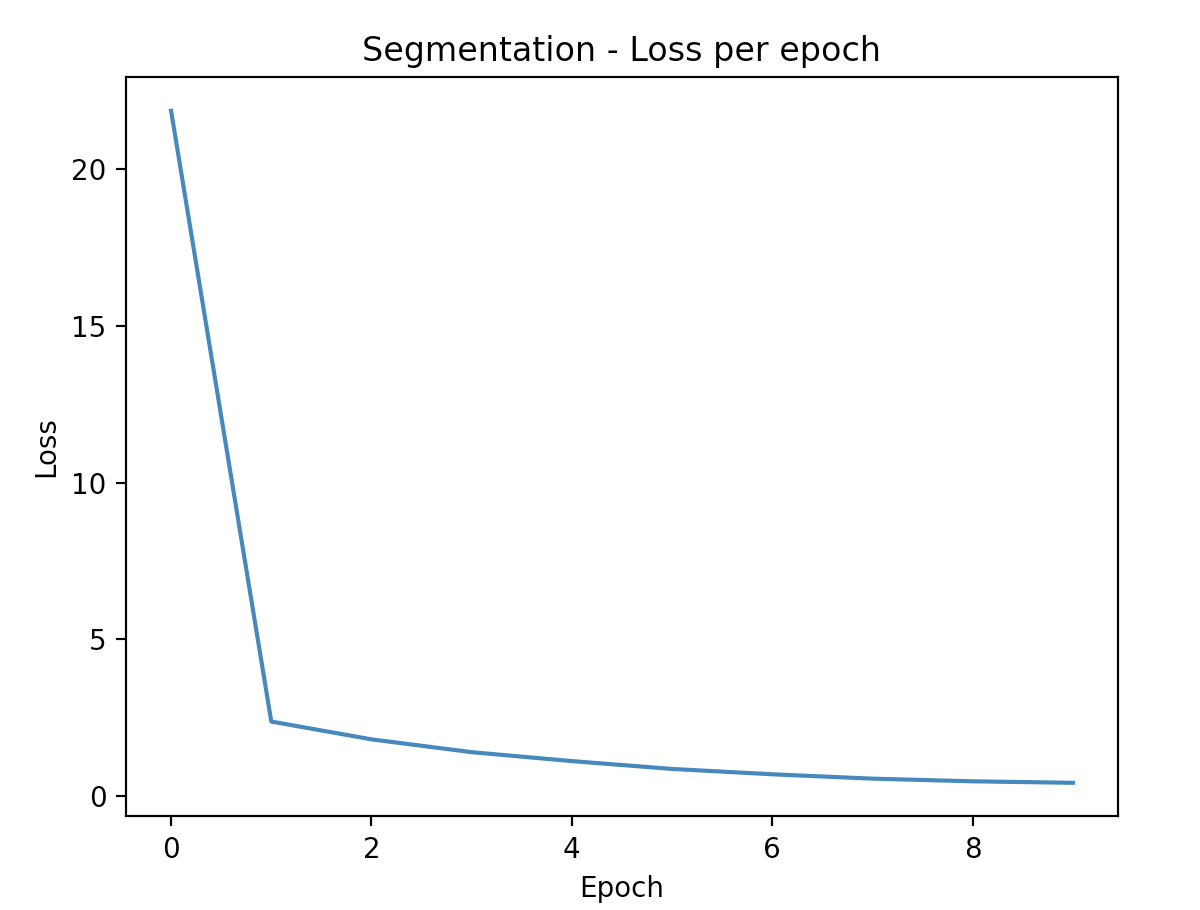
Segmentation loss

License plate recognition model
Eric Ma: ema11 Sherry Zhang: szhan235 Jacob Hirschhorn: jhirschh Prithvi Oak: poak1
Final Report:
Github link:
https://github.com/prithvioak/college-dropout-s
Introduction
We are reimplementing the paper “LPRNet: License Plate Recognition via Deep Neural Networks,” by Sergey Zherzdev and Alexey Gruzdev, which aims to produce license plate numbers from images of license plates. The paper aims to do this by implementing LPRNet, an automatic license plate recognition model that doesn’t use RNNs, only CNNs. The purpose of just using CNNs is to create a model that is more lightweight and can run on a variety of platforms including embedded devices. This allows the model to be more accessible for real-time use. As the goal of the model is to identify license plate numbers from pictures, this is a classification problem. We based our model on the PyTorch implementation used by the paper, found here. In addition, we also created a simpler model, still using a solely CNN-based architecture, in order to more effectively fit the constraints of the data.
Methodology
The dataset used in our model comes from the paper ''On the Cross-dataset Generalization in License Plate Recognition.” The dataset is available upon request for academic research purposes only, and is cited below. It consists of 20000 images of the fronts of cars, split into 4 groups of 5000, as well as txt files giving the license plate number corresponding to each image. For preprocessing the inputs, we cropped the images to be just the license plates. Then, we used the cv2 library to segment each image into its characters, resized them to all have consistent dimensions, and converted them into RGB vectors. For the labels, we converted the string representation of the license plate number into a list of each character in the sequence. Then we one-hot encoded each label with respect to the different characters, and used those as our labels.
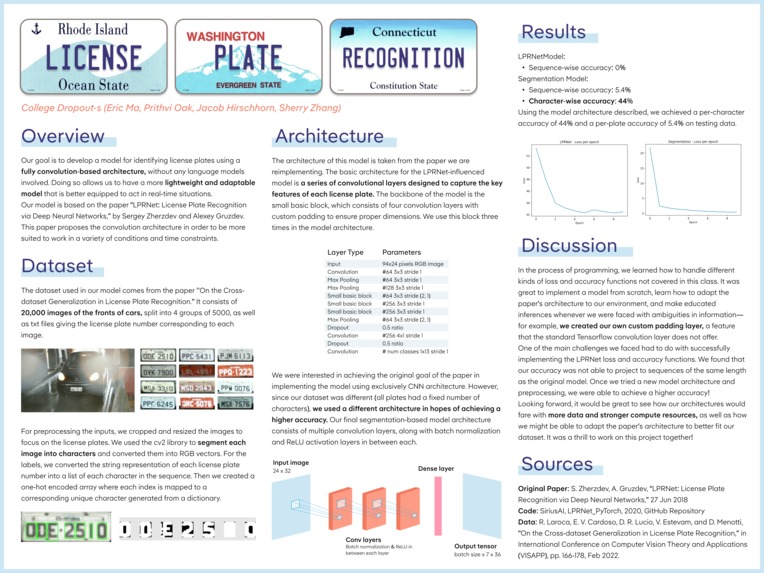
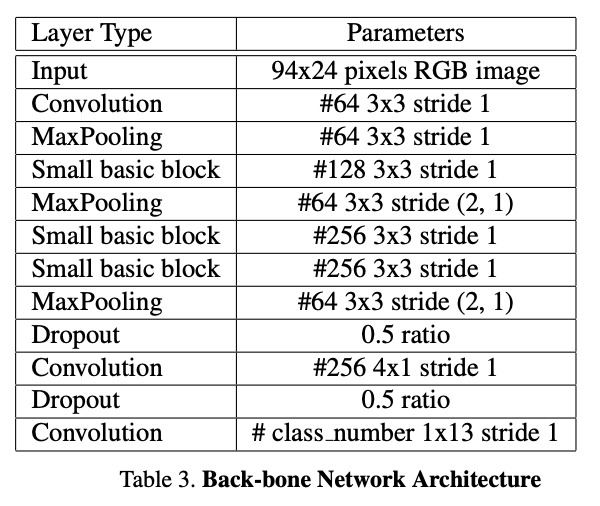
The architecture of the LPRNetModel model can be seen in the above images.
The architecture of this model is taken from the paper we are reimplementing. The PyTorch code for the model can be found here- we reimplemented it in TensorFlow. The basic architecture for the LPRNet-influenced model is a series of convolutional layers, designed to capture the key features of each license plate. The backbone of the model is the small basic block, which consists of four convolution layers, with custom padding to ensure proper dimensions. We use this block three times in the model architecture. After each one, there is a ReLU activation and batch normalization. Additionally, there are other convolution layers, as well as max pooling and dropout layers in the model. This architecture represents the backbone of the encoding model. This is what we pass into the CTC loss to calculate loss and optimize the model. The accuracy function utilizes a decoding algorithm, which uses a greedy search to determine the most likely prediction at each step without considering a broader context, and uses exact “true” matches found from the decoded sequence to find the accuracy (aka true positive ratio).
We were interested in achieving the original goal of the paper in implementing the model using exclusively CNN architecture, but we chose to make changes to our model architecture and loss function to account for the differences in our dataset which was that we had a fixed number of characters, so we used a different architecture in hopes of achieving a higher accuracy. Our final segmentation-based model architecture consists of multiple convolution layers, along with batch normalization and ReLU activation layers in between each. That accuracy was similarly calculated as the previous model; however, instead of using a greedy search algorithm for decoding, we were able to make use of a softmax cross-entropy for loss and true (sequence-wise) positive sequences and weak (character-wise) positive ratio.
Results
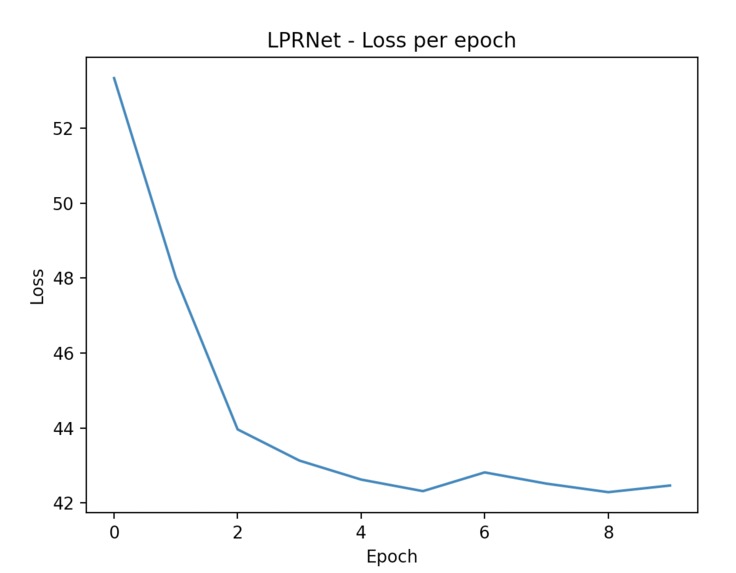
Despite showing clear signs of learning due to a consistent decreasing loss after each epoch, our LPRNet model had significant trouble with obtaining desired accuracy; in particular, greedy decoding the encoded sequence from our model. Due to this, the true accuracy of our model never reached above zero due to it not being able to project to sequences of the same length as the original model and the characters in those sequences not being totally accurate also.
Our segmentation model yields a consistent per-character accuracy rate of 44.4%, the mean of 10 runs using our entire dataset. The sequence-wise (true) accuracy, defined by the percentage of plates predicted with 100% accuracy, was 5.4%.
Challenges
We faced a couple of challenges as we worked on this project. One main issue came as we tried to find the best way to preprocess the data. Since we ended up working with multiple model architectures, we had to preprocess the data in different ways to get it to work for the different inputs necessary. It took a considerable amount of time to learn how to segment the images properly, since we were using the cv2 library, which was new to us. Most of our issues, however, stemmed from trying to get the LPRNet-based implementation to work. Initially, our main struggles with this part of the process came from attempting to match the dimensions that were used in the paper. We tried to scale the model down by using fewer layers, but the structure of the call function for the model concatenates the outputs of layers, so they need to have the same dimensions. We initially did not meet this constraint, since we had removed some of the layers that changed output dimensions. We also had to create a designated padding layer in TensorFlow because the model padded individual dimensions, which is not possible using the base TensorFlow padding operation. We created a custom tf keras Layer that allowed us to implement convolution with padding, where the padding input is an iterable object rather than “SAME” or “VALID”.
Once we got the dimensions to line up, we struggled to get the CTC loss function to work. Since none of us were familiar with the function, we had to spend some time learning how to properly format the data to be inputted. Even once we got that to work, we had a tough time understanding how to measure accuracy for the model. Since our result from the model was a Tensor representing image features, we did not know how exactly to compare the output to the label, which was a representation of the characters on the license plate. These challenges were definitely a part of our learning experience, though, as we had to use our skills in working through errors with debugging.
Reflection
The project ultimately turned out to be a great learning experience. We were able to achieve our base goal of having a better-than-random model. For our character-wise accuracy, we almost hit our target goal of 50%. However, we were much further from our stretch goal of reaching the paper’s model accuracy. One of the reasons we did not achieve our goals to the degree we would have hoped is because of challenges with the paper’s architecture that we only found later in the process. Because of this, we changed our approach as the project progressed, and created a second model that was better fitted to the dataset we were using and outputted better loss and accuracy. Specifically, we kept the base architectural structure of only using CNNs and not language models, but changed the format of the output of the model and the way we calculated loss and accuracy. Although we did not achieve the accuracy we would have hoped to, we are nonetheless proud of the effort we put in and what we achieved. We believe that it is a project that has a lot of promise! If we had more time, we would likely have tried to adapt the original model architecture to fit our dataset after thorough literature review. With more time, we could have also explored a more elaborate architecture and longer training iterations.
We believe that we learned a lot from this project:
- Working with and around dependency issues and making sure all the packages worked together
- Learning about different model architectures and how completely different architectures can be used for similar goals (ex: encoder-decoder vs CNN-classifier)
- Building model architectures from scratch and implementing methods from research papers
- Learning more about TensorFlow’s capabilities and using available libraries to our advantage
- Partner programming with four people; leveraging tools like VSCode Liveshare to work together effectively
Mentor check-in 3 link:
https://docs.google.com/document/d/11L7KRCnnPuBiLiSfoUwG6Mq7tx0cBVECTO2f14ldZ_o/edit?usp=sharing
Introduction: What problem are you trying to solve and why?
We are creating a deep learning model that can extract information from images of license plates! https://arxiv.org/pdf/1806.10447.pdf The paper aims to implement LPRNet, an automatic license plate recognition model that doesn’t use RNNs. As the goal of the model is to identify license plate numbers from pictures, this is a classification problem.
Related Work: Are you aware of any, or is there any prior work that you drew on to do your project?
Another paper that goes beyond the paper we are re-implementing is A. Graves, S. Fernndez, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” in Proceedings of the 23rd international conference on Machine learning. This paper describes a method of using RNNs to learn sequences of labels from unsegmented data by presenting a new way of training RNNs to label these sequence data directly through a sliding window approach. This represents one of the earlier approaches towards processing sequence data that didn’t involve first segmenting the characters of the license plate. Public implementations: https://arxiv.org/pdf/2309.04331v2.pdf
Data: What data are you using (if any)?
We are using the CLPD dataset, which stands for Chinese License Plate Dataset. It is a set of pictures taken of cars in China, from all 31 provinces. This dataset consists of 1200 images, which may cause issues due to the relatively small size of the dataset compared to the paper we are reimplementing. However, given the resources we have, that is likely a good thing, as we can only devote so much compute resources towards the model. We will need to do some preprocessing of these images as they are not cropped.
Methodology: What is the architecture of your model?
Our model will take in RGB images of license plates as the input and use a sequence of convolution layers with max pooling and dropout to classify the image. Notably, the model doesn’t involve an RNN. We will additionally split our dataset into training and testing sets. We think the hardest part about implementing the model will stem from the paper using cropped photos of license plates as opposed to pictures of entire cars (which is what our dataset has). As a result, our accuracy will likely be much lower than the paper’s accuracy.
Metrics: What constitutes “success?”
In terms of metrics, we are planning on using what was outlined in the paper to determine the robustness of our model. In the paper, they used recognition accuracies as well as the 1LP processing time in the context of the other related works in the past. I think for our model, we can focus on test accuracy. We plan to run the experiments run by the paper, but for base and target goals, we can focus on the baseline LPRNet method testing experiments. Base Goal: A functioning model with an accuracy of better than random. Target Goal: A functioning model with an accuracy of more than 50%. Stretch Goal: A functioning model with an accuracy similar to the paper’s accuracy (94%).
Ethics:
-> What broader societal issues are relevant to your chosen problem space? When working with license plate data (especially that of another country), there are natural ethical concerns that will be brought up. Many of these issues are relevant to license plate recognition. Firstly, being that of personal privacy. If cameras and broader systems are able to recognize and capture the movement of certain cars, then they are able to track the movement of its drivers also. Systems must be clear in their transparency and allow drivers the choice of consenting to being tracked. Given this core issue, we see that this technology is truly so powerful and when placed in the hands of biased or unregulated state interests, issues regarding the distribution of power in society are brought to the forefront.
-> Who are the major “stakeholders” in this problem, and what are the consequences of mistakes made by your algorithm? One major stakeholder in this problem is governmental and law enforcement agencies. These agencies use license plate recognition technology for things like finding stolen vehicles, catching traffic violations, and monitoring traffic generally. If our algorithm makes a mistake, and returns an incorrect license plate identification, then people could be fined for traffic violations they did not commit, or law enforcement agencies could fail to locate stolen vehicles. On the flip side, another stakeholder in this problem is vehicle owners. If our algorithm misidentifies a license plate, a vehicle owner could be incorrectly fined for violations they did not actually incur, or could be targeted for stealing a vehicle that actually belongs to them.
Division of labor: Briefly outline who will be responsible for which part(s) of the project.
Since we are each hoping to learn how to do this project through-and-through and not just how to implement individual parts of it, we are planning on largely partner programming for this project. In other words, we will be scheduling regular meetings to work on the code all together. This will ensure that there are no gaps in the skills and knowledge gained by each member of the project.
Built With
- python
- tensorflow





Log in or sign up for Devpost to join the conversation.