Collective
Inspiration
Modern coding agents are powerful, but they waste a huge amount of context. One agent reads the repository, reconstructs architecture, finds the relevant tests, and discovers a decision. Then another agent starts over and pays the same token cost again.
Collective was made to reduce that repeated waste. The future should not be every agent asking for a bigger context window. The future should be agents sharing verified engineering memory.
What it does
Collective is a shared memory graph for coding agents.
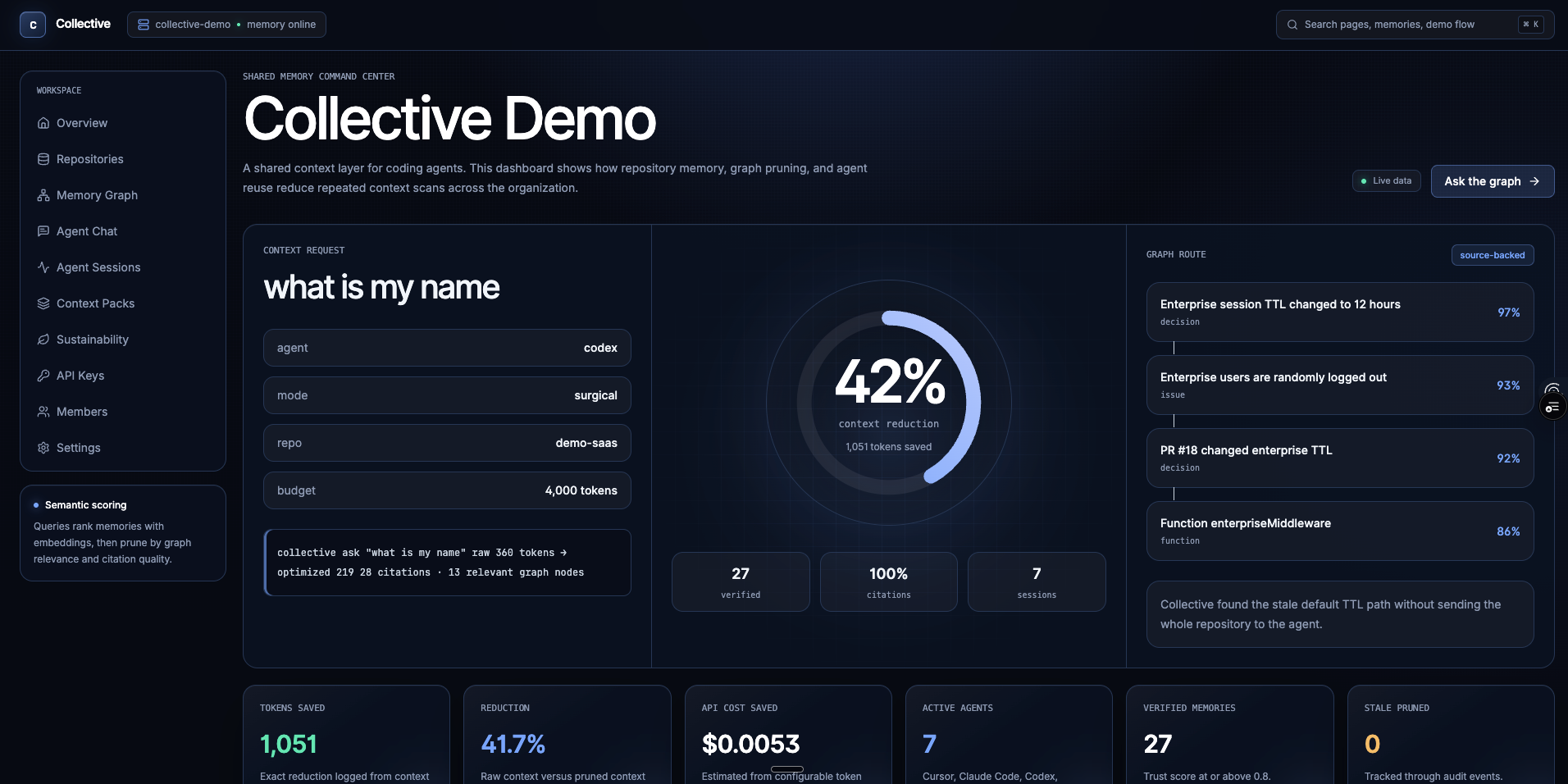
It ingests repositories, docs, issues, PR decisions, ownership hints, and agent observations into one organization-scoped graph. When an agent starts a task, Collective returns a small cited context instead of dumping the whole repo into the prompt.
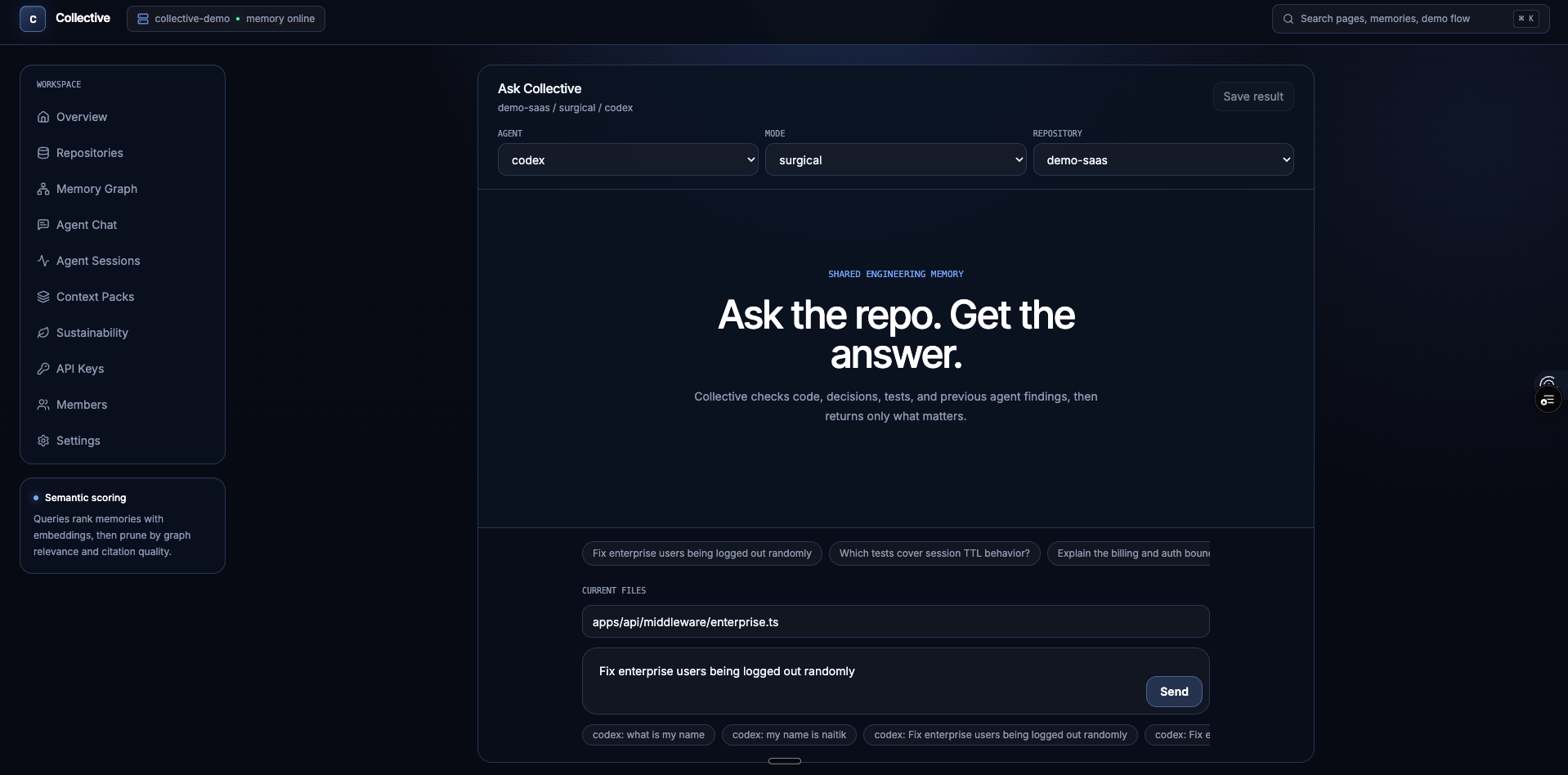
For the demo task:
Fix enterprise users being logged out randomly
Collective connects:
enterprise middleware
session TTL
PR #18 decision
auth tests
owner/context
It also tracks exact token savings and estimated cost, energy, water, and carbon savings.
How we built it
We built Collective as a TypeScript monorepo:
Next.js App Router dashboard
Prisma/Postgres production schema
JSON demo store for deterministic local judging
CLI harness for Codex, Claude Code, Copilot, Cursor, and OpenCode style workflows
Graph extraction package
Relevance pruning package
Agent SDK with API key auth
OpenAI embedding support with local fallback
The ingestion layer walks a repository, skips generated/dependency folders, hashes files, creates file summaries, extracts graph nodes, and links code to decisions/tests/issues.
The pruner scores nodes with semantic similarity, graph centrality, file overlap, source trust, recency, bug frequency, edit risk, redundancy, and staleness. It then traverses the graph, merges duplicates, fits the result into a token budget, and returns a cited context pack.
The web app and CLI share the same SDK path, so the local demo flow can run a terminal command and immediately show the updated dashboard.
Challenges we ran into
The hardest challenge was making Collective more than a vector search demo. A vector result alone is not enough for coding agents because engineering context is relational: tests cover files, PRs explain decisions, owners know domains, and stale notes can be dangerous.
Another challenge was UI direction. The dashboard needed to feel like serious developer infrastructure, not a flashy AI toy. We moved the product toward a restrained enterprise interface with neutral surfaces, clear hierarchy, and semantic color only where it means something.
Accomplishments that we're proud of
We are proud that Collective works end to end:
Repository ingestion
Memory graph generation
Graph traversal
Relevance scoring
Duplicate filtering
Context compression
Citations
Agent writeback
CLI harness
Chat UI
Savings dashboard
API key auth
Audit logs
We are also proud that the demo proves the product thesis. Collective finds the enterprise logout cause without sending the whole repository to the agent.
What we learned
We learned that the important problem is not only retrieval. It is trust.
Agents need to know:
Where did this fact come from?
Is it stale?
Is it duplicated?
Is it source-backed or just an agent observation?
Which tests are connected?
How much context did we avoid?
We also learned that shared memory is most valuable when it is operational. It has to plug into CLI workflows, browser dashboards, and agent handoffs. Otherwise it becomes another dashboard nobody checks.
What's next for Collective - Less context. More intelligence.
Next, we would build:
GitHub App ingestion for PRs, issues, reviews, and ownership
pgvector-backed semantic retrieval in Postgres
Redis-backed background ingestion jobs
automatic stale-context detection when code changes
duplicate-memory review workflows
human verification for high-impact memories
agent comparison dashboards
evaluation harnesses for context quality
Slack and Linear/Jira ingestion
The long-term vision is simple:
Every engineering organization has one shared context layer.
Every coding agent reuses it.
Every prompt gets smaller, more cited, and more accurate.
Less context. More intelligence.
Built With
- clerk
- graphify
- next.js-app-router
- prisma
- react
- tailwind-css
- typescript

Log in or sign up for Devpost to join the conversation.