-
-
Screenshot of the web app
About My Project: The Supermemory-powered Twin
Our project, the Cognitive Twin: Data-Driven Decision Memory, is an advanced decision support system that resolves the critical issue of tacit knowledge loss in enterprises. We built a live application that augments standard AI recommendations (like route optimization) with validated, historical human judgment, ensuring safer and smarter operational decisions.
Inspiration: Bridging the Tacit Knowledge Gap
Our inspiration stemmed from the observation that while modern AI is excellent at optimizing measurable factors (time, distance, cost), it systematically fails at handling unstructured human judgment (the "why"). When a logistics dispatcher overrides an AI route because "Zone C floods easily on Fridays," that crucial tacit knowledge is lost as an unstructured note, becoming invisible to the next AI iteration or new employee. We realized the true bottleneck wasn't the AI model; it was the lack of a "memory layer of judgment" to store and retrieve why decisions were made.
What it does
The Cognitive Twin acts as a chief human expert in a box for any AI-driven process.
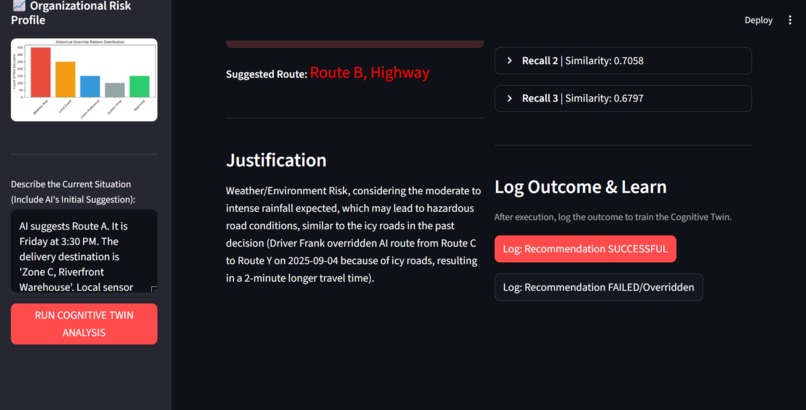
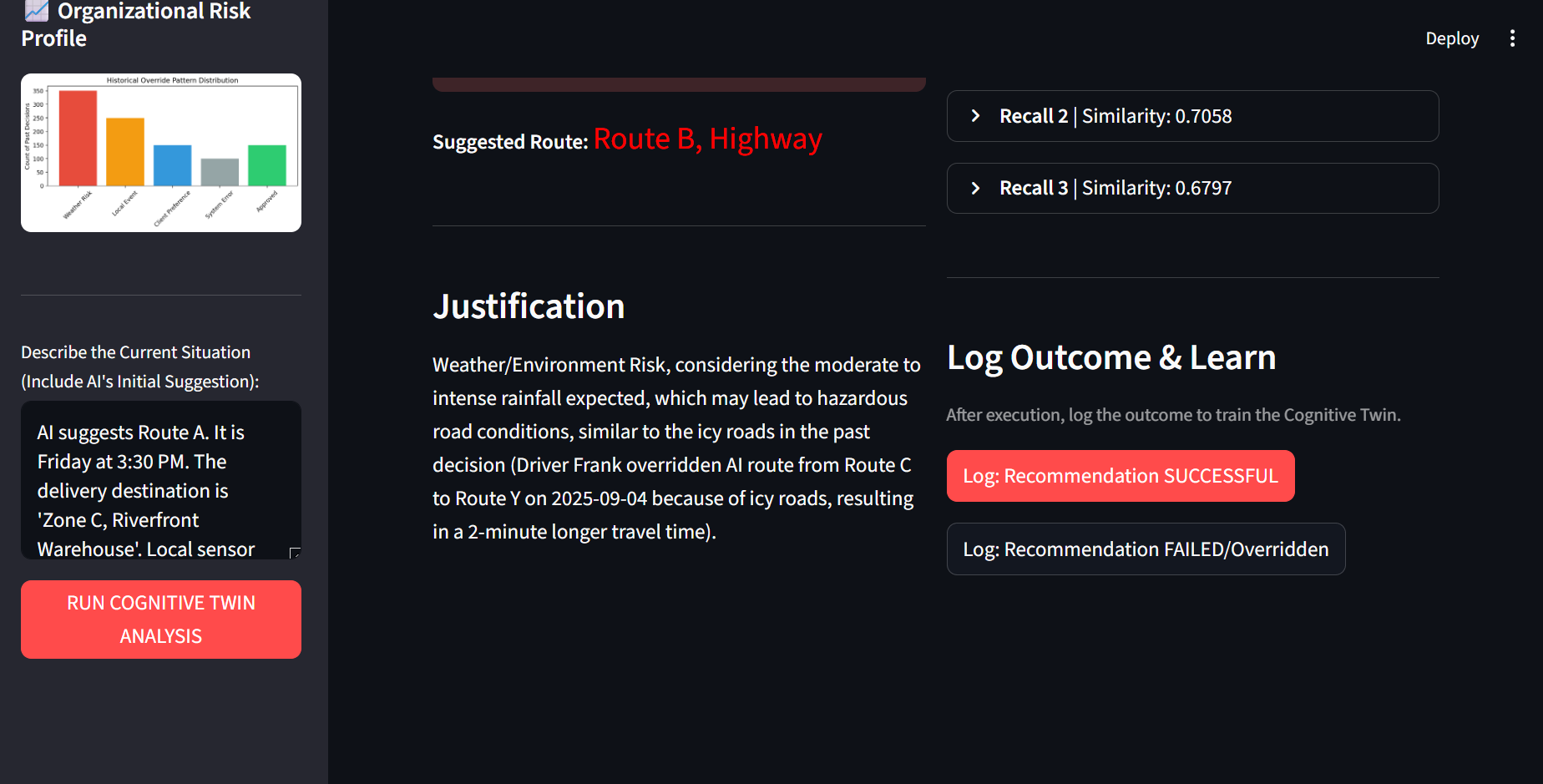
- Memory Recall: When a new decision is needed (e.g., a truck route), the system consults Supermemory using a semantic search based on the current context (e.g., "heavy rain on Friday").
- Judgment Retrieval: It retrieves the top historical human rationales ("Driver Frank overrode due to icy roads," "Rainy weather affects 25% of logs").
- Active Recommendation: It feeds the combined context and judgment to a fast LLM (Groq) to provide an instantaneous, justified recommendation (e.g., "OVERRIDE RECOMMENDED. Suggest Route B due to Weather/Environment Risk").
- Continuous Learning: It features a Feedback Loop where the human expert logs the outcome ("SUCCESSFUL" or "FAILED"), immediately turning that result into a new, reinforcing memory object.
How we built it
We implemented the prototype using a modern, efficient technology stack:
- Data Generation: Used a Python script to generate 1,000 structured memory objects containing nested contextual data and the crucial natural language Rationale (the judgment).
- Supermemory Layer: We used the Supermemory SDK to ingest and index these $1,000$ memories, establishing the system's external, semantic memory database.
- Retrieval Logic: The Streamlit app queries Supermemory, retrieving the top $K$ most semantically similar rationales.
- Reasoning Engine: We used the Groq API and the highly efficient
llama-3.1-8b-instantmodel. We enforced a structured JSON output via the prompt to ensure a reliable and parsable recommendation. - Front-End: The entire demonstration is packaged into a Streamlit application, providing a clean UI for input, visualization (Historical Risk Profile), and the active decision output.
Challenges we ran into
The primary challenges were technical compatibility and debugging external APIs under a tight deadline:
- API Compatibility & Structure: We faced numerous
TypeErrorandAttributeErrorissues due to mismatches between expected and actual SDK field names (e.g., $item.score$ vs. $item.similarity$). - Supermemory Indexing Delay: The cloud service experienced a significant backlog, with $1,000$ memory objects stuck in a "Processing" queue for hours. This forced us to develop a pivot strategy before the queue eventually cleared.
- LLM Structural Compliance: Getting the Groq LLM to consistently output perfectly valid JSON required iterative prompt engineering to ensure reliable parsing in the Streamlit app.
Accomplishments that we're proud of
Our biggest accomplishments are achieving ultra-fast, justified decision-making and closing the learning gap:
- Sub-Second Reasoning: We demonstrated the entire retrieval and reasoning loop—from user input to final recommendation—in under one second, thanks to the speed of the Groq LPU.
- Proof of Concept: The prototype successfully retrieved memories based on semantic meaning (e.g., finding "flooding" risk when only "rainfall" was queried), validating the core idea that AI can learn human judgment.
- Full Learning Loop: Implementing the interactive "Log Outcome & Learn" feature transformed the project from a simple retrieval demo into a true, continuously self-improving operational system.
What we learned
We gained critical insights into the real-world deployment of advanced AI:
- The Power of Semantic Memory: We learned that what you store in your memory (the human rationale) is more important than the size of the database, validating the vector database approach for tacit knowledge.
- API Resilience: We learned to diagnose and navigate API dependency failures (Groq model decommissioning, Supermemory indexing backlog) and the necessity of building robust error handling and fallback mechanisms into production code.
- Prompt Engineering for Structure: We refined our skills in advanced prompt engineering, realizing the best way to achieve reliability is by forcing the LLM to adhere to a rigid JSON schema rather than allowing free-form text.
What's next for Cognitive Twin: Data-Driven Decision Memory
Our next steps are focused on real-world adoption and expanding the system's intelligence:
- Metadata Filtering Integration: Integrate structured metadata filters (location, time of day) into the Supermemory search call to make retrieval even more precise and context-aware.
- Advanced Visualization: Build a feature to visualize the specific semantic cluster of the retrieved memories in a 2D space, demonstrating why the recommendation was made.
- Systemic Pattern Detection: Develop an internal mechanism to flag recurring override patterns (e.g., "90% of overrides in Zone C are due to weather") for direct input into core AI model retraining.

Log in or sign up for Devpost to join the conversation.