-
-

APP ICON
-
Hugging Face space
-
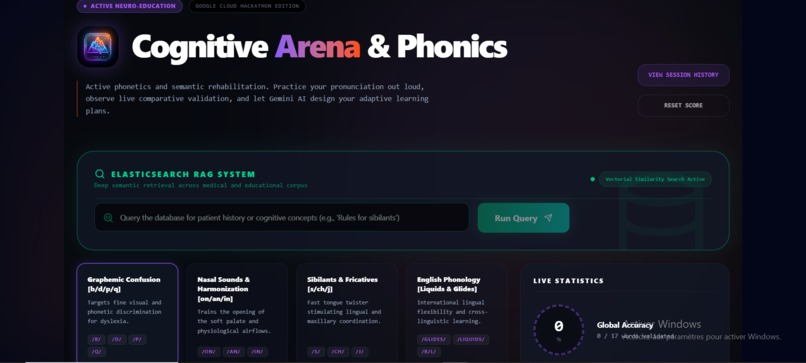
Dashboard

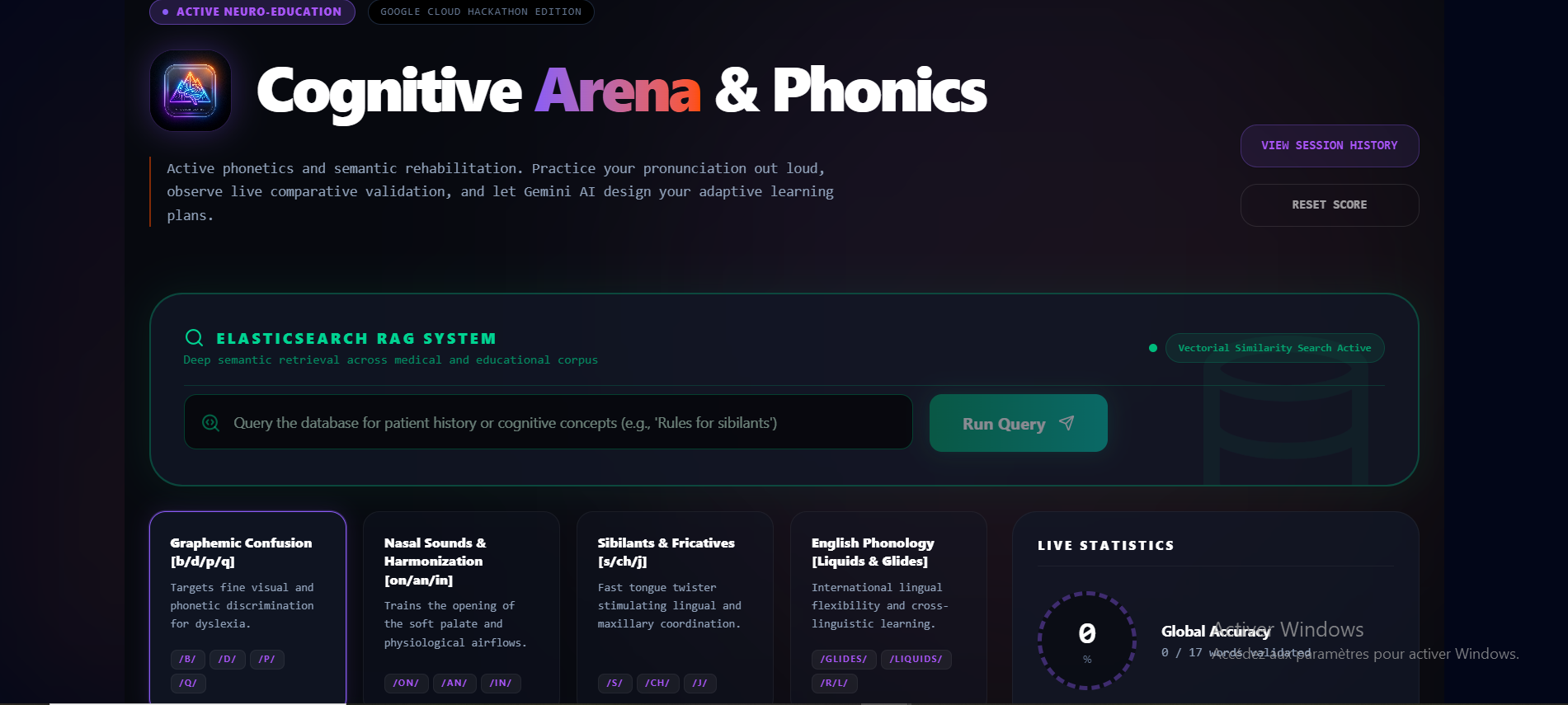
🧠 Inspiration
The inspiration for the Cognitive Arena module of Mount AI Scholar stemmed from a critical gap in modern EdTech: the lack of real-time, privacy-first cognitive remediation for dyslexia and phonological processing disorders. The complexity of mapping phoneme-grapheme correspondence requires more than just flashcards; it requires a dynamic environment that listens, analyzes, and adapts. I wanted to build an engine that doesn't just score a student, but algorithmically understands their phonetic deviation and generates instant, customized remediation pathways.
⚙️ What it does
The Cognitive Arena is a secured neuro-cognitive session environment. It provides:
- Active Phonetic Rehabilitation: Users practice pronunciation while the system performs live comparative validation against expected transcripts.
- AI-Driven Remediation: Leveraging Gemini (as a bridge toward my ultimate Gemma 4 Edge local inference architecture), the system detects specific graphemic confusions (e.g.,
b/d/p/qor Sibilants/Fricatives) and instantly creates adaptive practice regimens. - Secure Patient Sessions: Every session is securely logged with 100% data segregation, ensuring absolute privacy and allowing for historical progress tracking.
🔨 How I built it
I engineered the platform using a modern, scalable full-stack approach:
- Frontend Architecture: React 18, TypeScript, and Tailwind CSS. The UI is heavily optimized using functional components, hook-based state management, and strict render control to prevent UI blocking during real-time cognitive processing.
- Backend & Security: Google Firebase. I implemented Google Authentication married with Firestore. For absolute data integrity, I wrote strict Firestore Security Rules ensuring that
arena_sessionsare inaccessible to anyone but the authenticated user. - AI & Voice Pipeline: I integrated the Web Speech API for zero-latency voice ingestion, passing the transcript delta to our AI remediation engine to construct the patient's cognitive profile in real-time.
Mathematically, the core challenge is minimizing the phonetic deviation $D$. If $p_i$ is the target phoneme and $\hat{p}i$ is the spoken phoneme, the system's objective function for the remediation engine is to construct exercises that minimize the error over $N$ speech samples: $$ \mathcal{L}{cognitive} = \frac{1}{N} \sum_{i=1}^{N} \omega_i \cdot \delta(p_i, \hat{p}_i) $$ Where $\omega_i$ represents the contextual weight of the specific phoneme based on the user's historical dyslexia profiles.
⚠️ Challenges I ran into
Building a synchronous AI pipeline over asynchronous voice streams in the browser was structurally complex.
- State Management: Handling continuous audio transcripts without causing recursive render loops in React required heavy memoization and strict
useEffectdependency arrays. - Privacy-by-Design Compliance: Writing standard NoSQL queries wasn't enough. I had to design compound queries and granular Firebase security rules to ensure patient data could theoretically pass highly strict medical/educational compliance frameworks.
🏆 Accomplishments that I'm proud of
I am incredibly proud of the seamless UX/UI integration. The Arena doesn't look like a standard, clunky medical or educational app. It features a dark, immersive "Cosmic-Slate" UI with glassmorphism, instant visual feedback, and a highly performant session history dashboard. It looks and feels like elite software, while housing highly technical cognitive-computing operations under the hood.
📚 What I learned
Managing real-time interaction between a client-side Speech API, a NoSQL data stream (Firestore), and an AI generation layer forced me to think deeply about architectural bottlenecks. I leveled up my ability to structure non-blocking UI threads and manage secure, scoped data streams in Firebase.
🚀 What's next for Mount AI Scholar
The Cognitive Arena is Phase 1. The Master Plan is to transition the cloud-based AI calls entirely to local edge inference (deploying Gemma 4 locally via Python/FastAPI) to achieve true, offline "Privacy by Design" with zero data leaving the device. Following that, Phase 2 targets the WWDC 2027 Swift Student Challenge: porting this entire engine into the Apple ecosystem using CoreML and projecting these neuro-cognitive sessions into spatial environments via ARKit and SwiftUI.


Log in or sign up for Devpost to join the conversation.