-
-
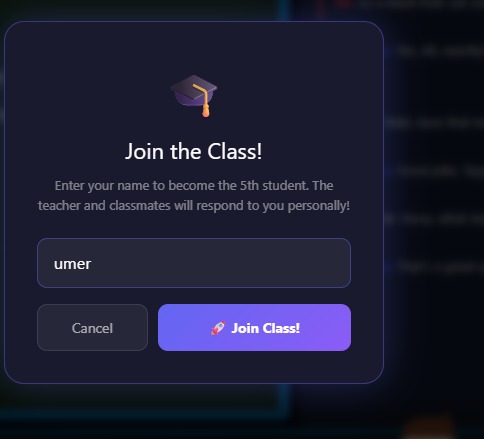
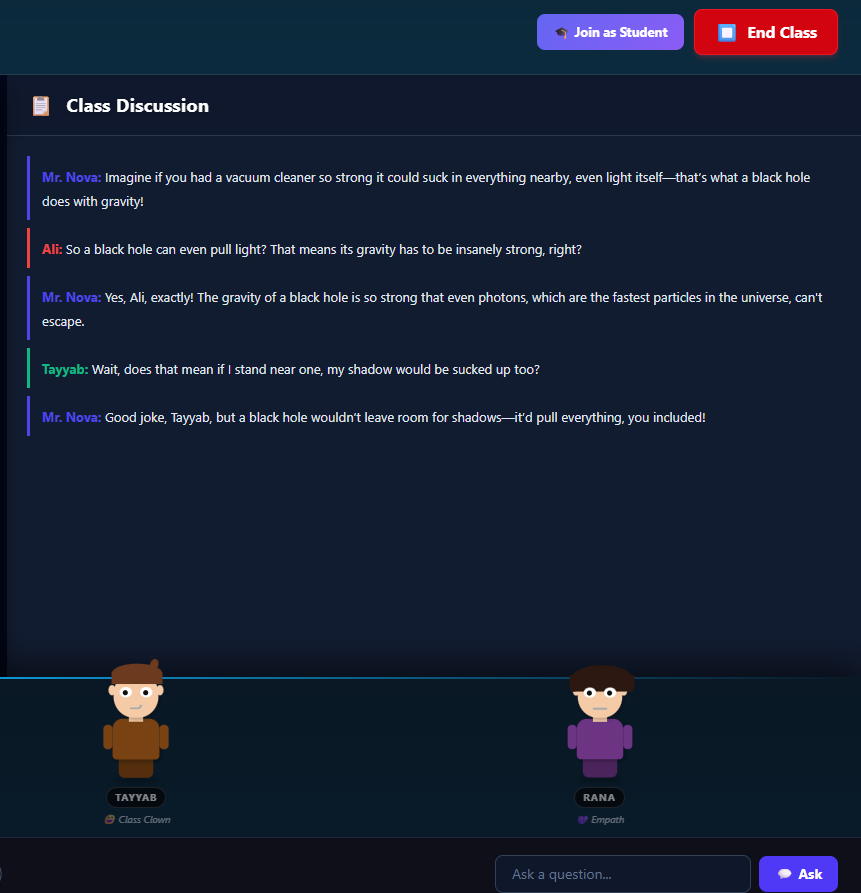
Became 5th Member with your own name
-
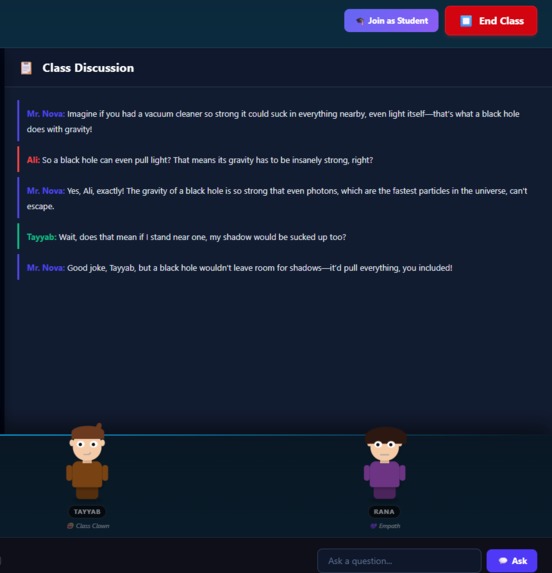
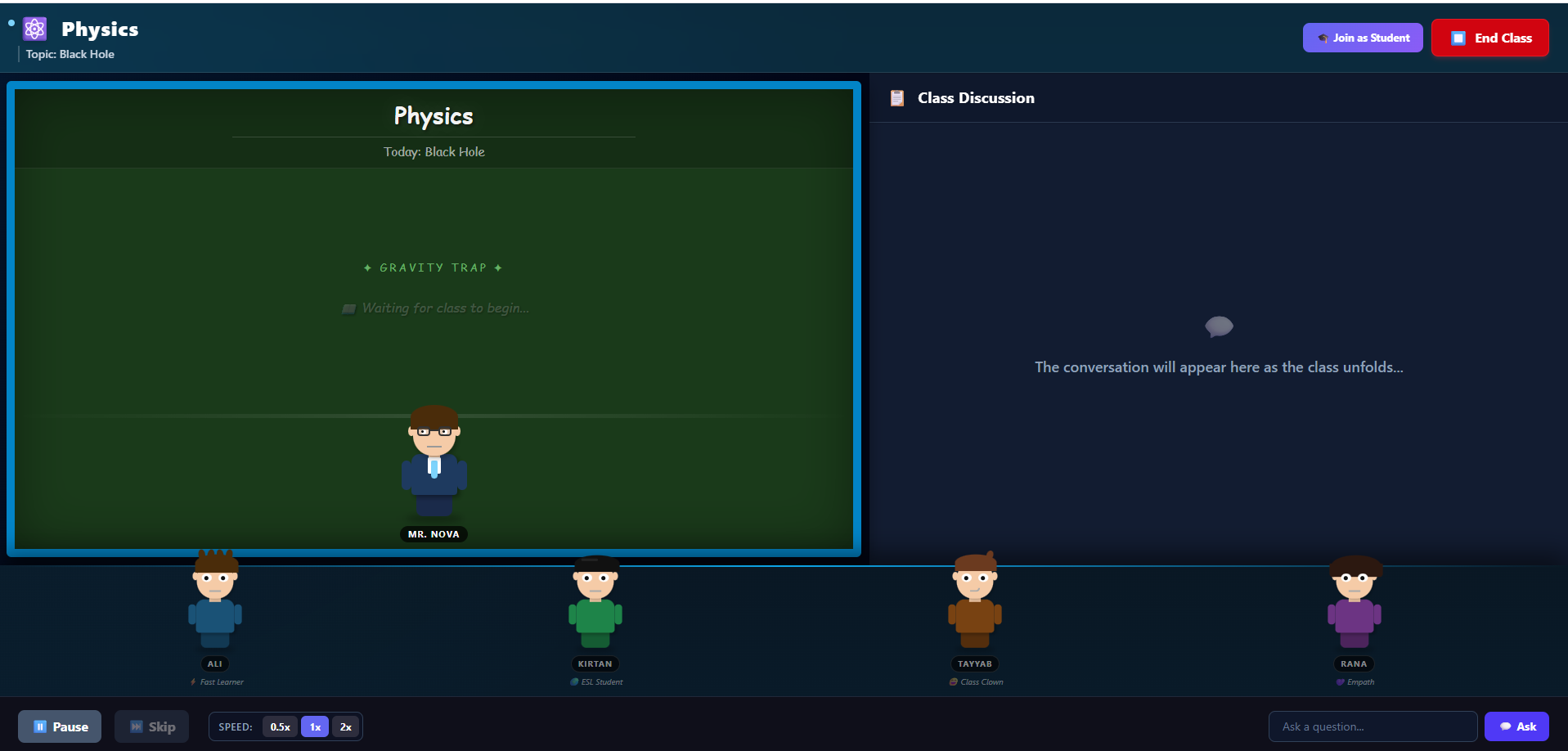
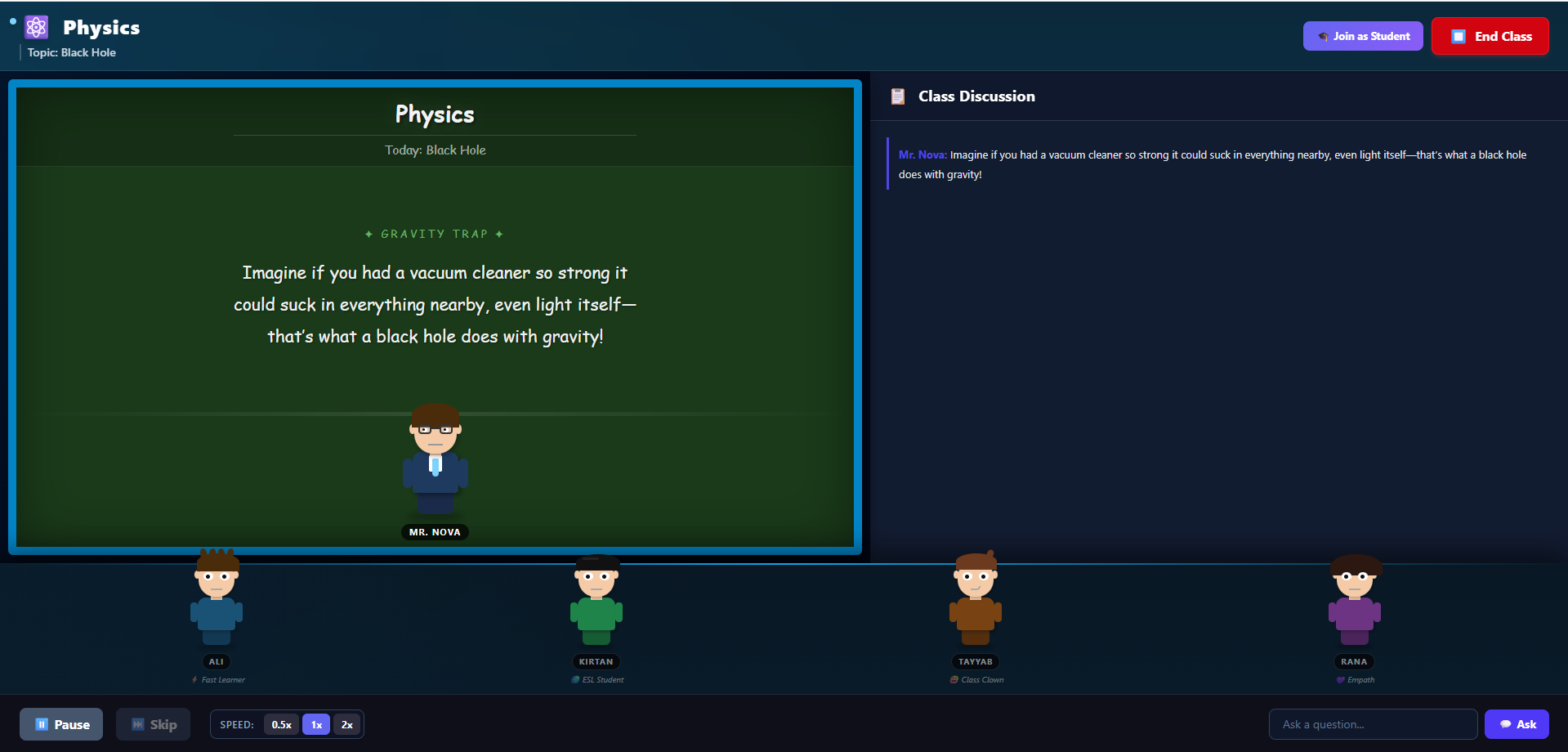
Class Discussion
-
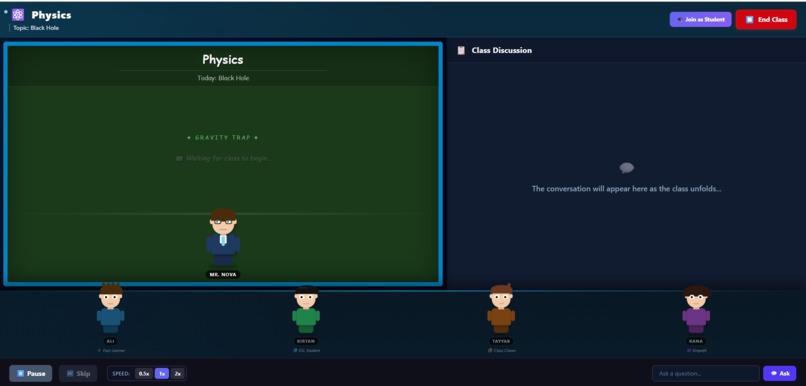
Classroom Simulation
-
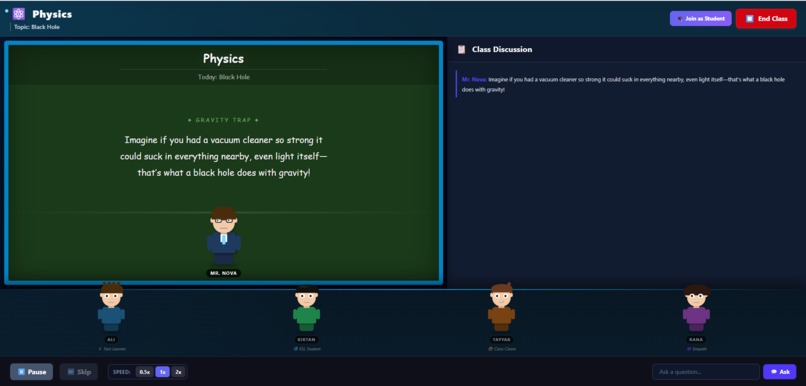
AI Student Avatars with Distinct Personas
-
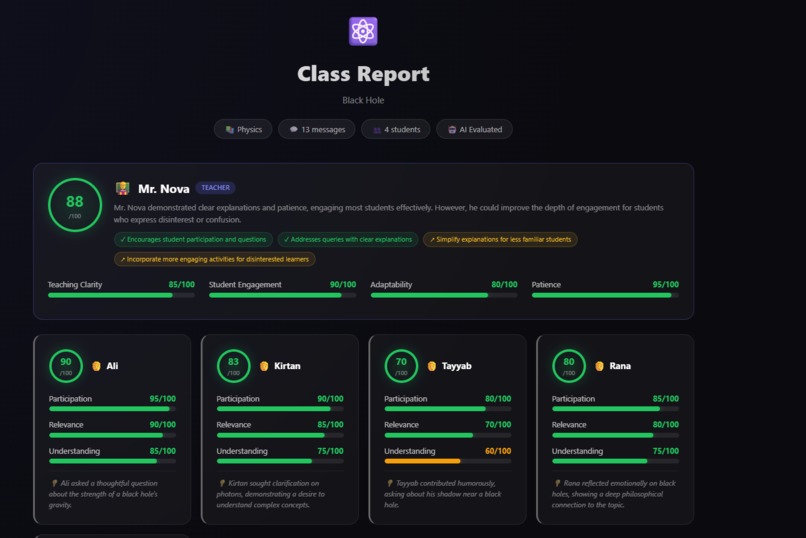
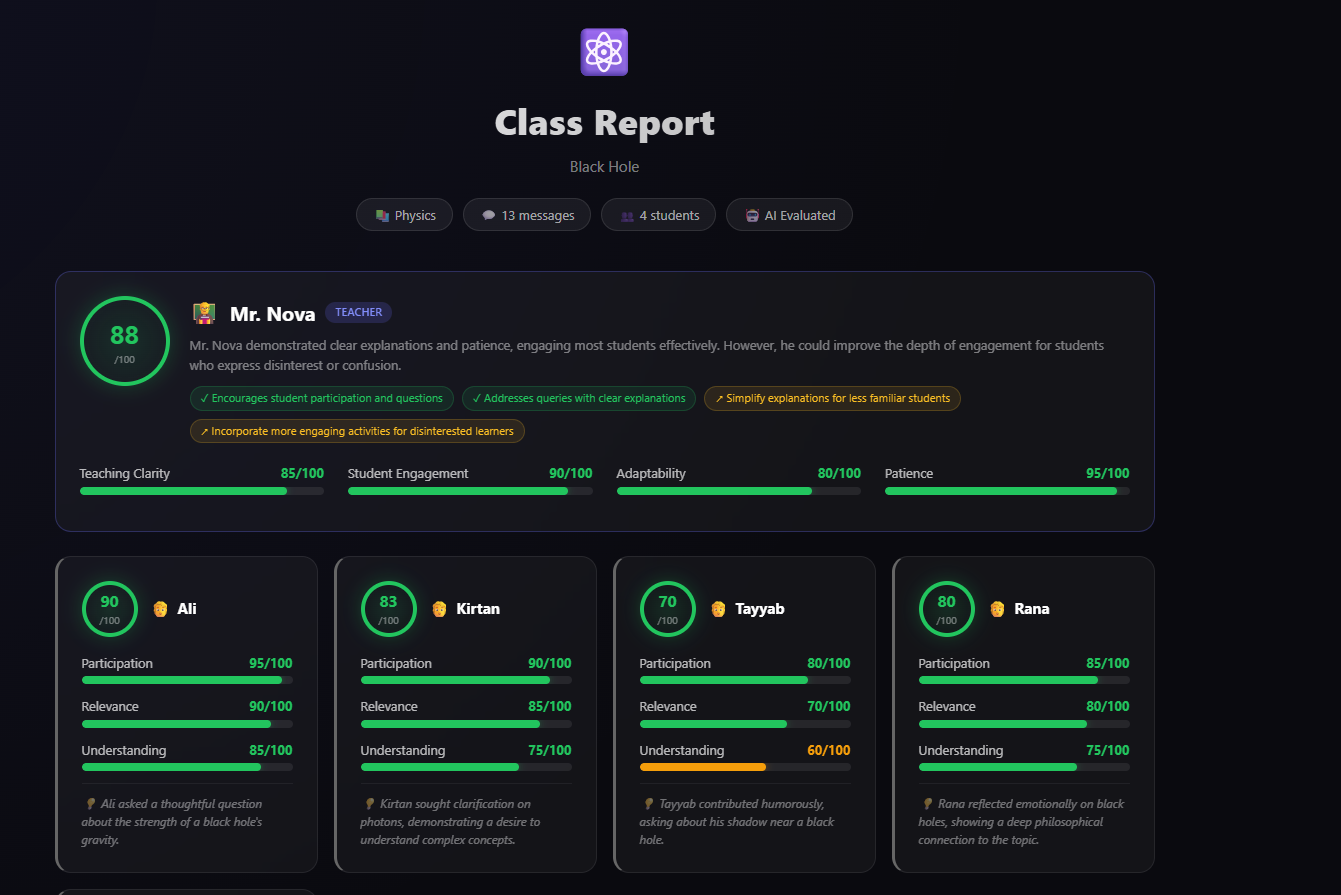
Class Evaluation Report
-
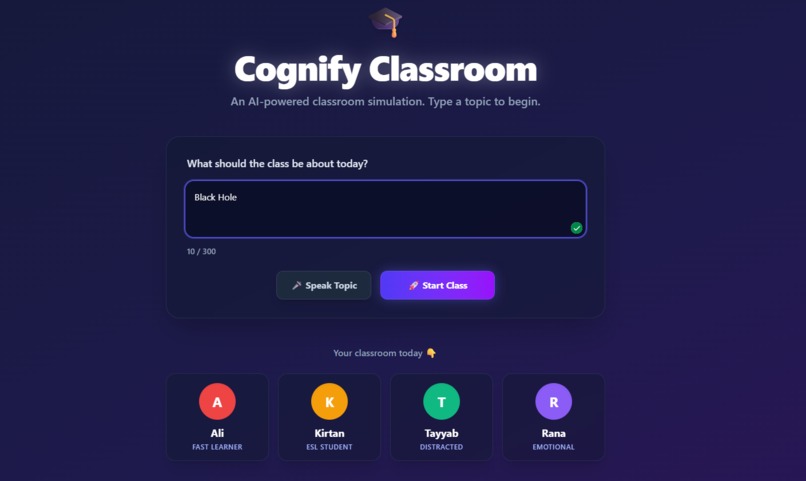
Interface
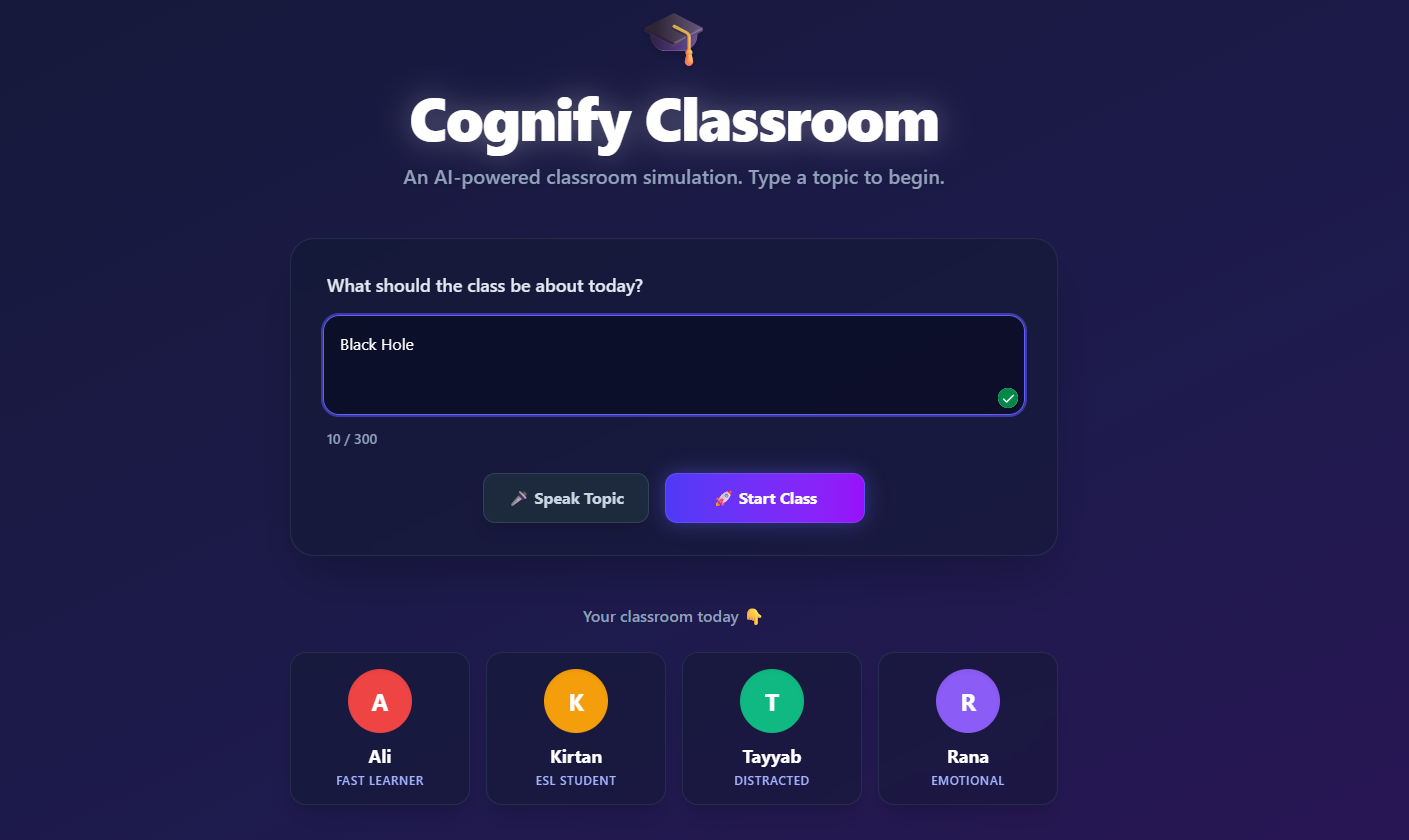
🎓 Cognify Classroom
"Practice teaching. Without real consequences."
💡 The Spark — What Inspired Us
It started with a simple but uncomfortable question:
Why do we let pilots practice in flight simulators for hundreds of hours before flying a real plane — but we throw teachers straight into real classrooms with real kids and just hope for the best?
A student's entire academic year can be shaped by how well their teacher handles a distracted student in row three, or how patiently they respond when an ESL student asks what a word means for the third time. Yet teachers get almost no safe space to practice these moments before they happen.
At the same time, we kept seeing AI being used in education in the most boring way possible — flashcard generators, quiz makers, content summarizers. All one-directional. All passive. None of them felt like learning. None of them felt alive.
We wanted to build something that actually put you inside a classroom. Not watching one. Not reading about one. Inside one.
That became Cognify Classroom.
🏗️ How We Built It
We built Cognify Classroom as a full-stack React application powered by a multi-agent AI architecture. Here is the honest story of how it came together.
The Core Idea — Multi-Agent Personas
The heart of the system is four AI student agents, each with a completely distinct personality, speaking style and behavioral pattern. We spent a significant amount of time on the prompt engineering for each character — because getting Ali to sound genuinely overconfident while Kirtan sounds genuinely careful while Tayyab sounds genuinely chaotic required dozens of iterations.
Each student has a system prompt that defines not just what they say but how they react to specific situations. When Tayyab makes a joke, the other students do not just ignore it — they react in character. Rana gets mildly offended. Ali rolls his eyes. Kirtan looks confused. Mr. Nova tries to bring everyone back on topic.
The Conversation Engine
The conversation pipeline works in three phases:
Phase 1 — Teaching
When the user types a topic, detectSubjectWithAI() sends it to GPT-4o which classifies it into one of eight subjects. This drives the entire visual theme of the classroom. Then generateTeachingSlides() creates one concise teaching slide that Mr. Nova delivers via animated chalk text on the blackboard — character by character — while ElevenLabs simultaneously speaks it in his deep British voice.
Phase 2 — Conversation
generateConversation() sends the full persona context, the teaching content, and the conversation history to GPT-4o which returns a structured JSON array of $6$–$7$ conversation turns. Each turn has a speaker, message type, and text written in that character's voice. The engine then plays through these turns sequentially.
Phase 3 — Evaluation
generateEvaluation() sends the full transcript to GPT-4o for structured evaluation. Meanwhile Azure Text Analytics runs sentiment analysis on every message to produce per-speaker emotional profiles.
⏱️ The Math Behind Timing
Getting voice and text to feel synchronized required careful timing. For a text of length $n$ characters typed at speed multiplier $s$, each character appears after a delay of:
$$\Delta t(s) = \frac{28}{s} \text{ ms}$$
So the total time to type a full slide of $n$ characters is:
$$T(n, s) = \frac{28n}{s \times 1000} \text{ seconds}$$
For a typical teaching slide of $n = 200$ characters:
$$T(200, 1) = \frac{28 \times 200}{1000} = 5.6 \text{ s} \quad \text{(normal speed)}$$
$$T(200, 2) = \frac{28 \times 200}{2000} = 2.8 \text{ s} \quad \text{(2x speed)}$$
$$T(200, 0.5) = \frac{28 \times 200}{500} = 11.2 \text{ s} \quad \text{(0.5x speed)}$$
The ElevenLabs audio is pre-fetched before typing begins so both finish at roughly the same time, creating the illusion of a teacher physically writing while speaking. The synchronization condition we aim for is:
$$|T_{\text{typing}}(n, s) - T_{\text{audio}}| < \epsilon \quad \text{where } \epsilon \approx 0.5 \text{ s}$$
This is achieved by adjusting $\Delta t$ dynamically using a speedRef — a React ref that mirrors the speed state so the async loop always reads the current speed, not a stale closure value:
$$\Delta t_i = \frac{28}{\texttt{speedRef.current}} \text{ ms} \quad \forall \, i \in [0, n]$$
📊 Evaluation Scoring
Each participant is scored across multiple dimensions. For the teacher, the overall score $S_T$ is the mean of four metrics:
$$S_T = \frac{C + E + A + P}{4}$$
Where:
- $C$ = Teaching Clarity $\in [0, 100]$
- $E$ = Student Engagement $\in [0, 100]$
- $A$ = Adaptability $\in [0, 100]$
- $P$ = Patience $\in [0, 100]$
For each student, the overall score $S_i$ is:
$$S_i = \frac{\text{Participation}_i + \text{Relevance}_i + \text{Understanding}_i}{3}$$
The class average across all participants:
$$\bar{S} = \frac{S_T + \sum_{i=1}^{4} S_i}{5}$$
Score thresholds for visual feedback:
$$\text{Color} = \begin{cases} \color{green}{\text{green}} & \text{if } S \geq 70 \ \color{orange}{\text{amber}} & \text{if } 50 \leq S < 70 \ \color{red}{\text{red}} & \text{if } S < 50 \end{cases}$$
🛠️ The Tech Stack
| Layer | Technology | Purpose |
|---|---|---|
| Frontend | React + Vite | UI framework |
| Styling | Tailwind CSS | Utility-first styling |
| Animation | Framer Motion | Avatar reactions, transitions |
| State | Zustand | Global classroom state |
| AI Model | Azure OpenAI GPT-4o | All conversation generation |
| Analytics | Azure Text Analytics | Sentiment + key phrases |
| Voice | ElevenLabs Neural TTS | Distinct character voices |
| Realtime | Firebase RTDB | Live audience sync |
| QR Code | qrcode.react | Session sharing |
| STT | Browser Speech API | Voice topic input |
📚 What We Learned
Honestly? We learned that prompt engineering is a craft, not a science.
Getting four AI agents to maintain distinct personalities across a 7-turn conversation without breaking character, without contradicting each other, and without going off-topic took far more iteration than any of the technical work. The difference between a conversation that feels alive and one that feels robotic is entirely in how precisely you describe the character's inner world to the model.
We also learned that perceived synchronization matters more than actual synchronization. Users do not notice a $200\text{ ms}$ gap between voice and text starting. They notice a $2000\text{ ms}$ gap. Pre-fetching the audio blob before the typing loop begins was a tiny technical change that made the whole experience feel dramatically more polished.
And we learned something genuinely surprising — educational conversations naturally score as "negative" in sentiment analysis because they involve challenge, critique, uncertainty and questioning. A student saying "I don't understand" is not a negative event — it is the most important positive event in a classroom. We had to rethink how we present sentiment data to make it meaningful in an educational context.
🧱 Challenges We Faced
1. Making Four Voices Sound Actually Different
This was harder than expected. Browser TTS gives pitch $f_p$ and rate $r$ controls but all voices ultimately come from the same synthesis engine. We went through three different TTS solutions:
$$\text{Browser TTS} \xrightarrow{\text{too similar}} \text{ResponsiveVoice} \xrightarrow{\text{better}} \text{ElevenLabs} \checkmark$$
ElevenLabs gives genuinely distinct neural voices with independently configurable stability, similarity_boost and style parameters per character.
2. The Blackboard Typing Problem
Getting text to appear character by character while a voice speaks simultaneously sounds trivial. It was not. React's state batching means rapid setState calls inside a loop do not always trigger renders at the expected frequency. We had to force a render on every character using:
await new Promise(r => setTimeout(r, Math.floor(28 / speedRef.current)))
Rather than any React-native timing mechanism. The speedRef pattern was critical — without it, speed changes mid-typing would not take effect until the next slide because the async closure captures a stale value of speed at loop start.
3. Subject Detection Reliability
Our first fuzzy match failed because GPT returned "ComputerScience" while our array stored "Computer Science". The fix was a four-tier matching function:
$$\text{match}(q, s) = \begin{cases} \text{true} & \text{if } q = s \ \text{true} & \text{if } q_{\text{stripped}} = s_{\text{stripped}} \ \text{true} & \text{if } s \subset q \ \text{true} & \text{if } q \subset s \ \text{false} & \text{otherwise} \end{cases}$$
Where $q_{\text{stripped}}$ means all whitespace removed from string $q$.
4. Real-Time Audience Sync Without Blocking the Engine
Firebase felt simple until we realized the classroom engine runs entirely inside an async pipeline with no natural event hooks. Every addMessage and setCurrentSpeaker call needed a corresponding Firebase push without ever blocking or crashing the main engine. The solution:
pushMessage(sessionIdRef.current, msg).catch(() => {})
Fire-and-forget with silent catch — Firebase failures become invisible to the classroom engine while still attempting to sync.
5. Avatar Head Detachment
Tayyab's head kept floating above his body. The root cause was that transform: rotate() on a child element creates a new stacking context that subtly shifts the visual centroid without changing the layout box. The fix was removing all transforms from hair container elements and using transformOrigin: 'bottom center' only on individual strand divs.
🔮 Where This Goes Next
Cognify Classroom is a prototype but it points at something genuinely important.
Imagine this as a teacher training tool integrated into education colleges — every student teacher runs fifty simulated classes before entering a real one. Imagine it as a corporate training platform where companies test how content lands with different learner types before rolling it out globally. Imagine it multilingual — the same four students but Kirtan speaks Punjabi mixed with English, and the teacher has to adapt in real time.
The infrastructure is already there. The hardest part — making AI agents feel like real people in a real conversation — is already working.
$$\text{Cognify Classroom} = \sum_{\text{agent} \in {T, A, K, R, N}} \text{Persona}(\text{agent}) \times \text{GPT-4o} \times \text{Context}$$
We did not just build a demo. We built a foundation.
Built at MIT Minds & Machines Hackathon · February 2026
Powered by Azure OpenAI GPT-4o · Azure Text Analytics · ElevenLabs · Firebase Realtime Database










Log in or sign up for Devpost to join the conversation.