-
-

Slides - Intro
-
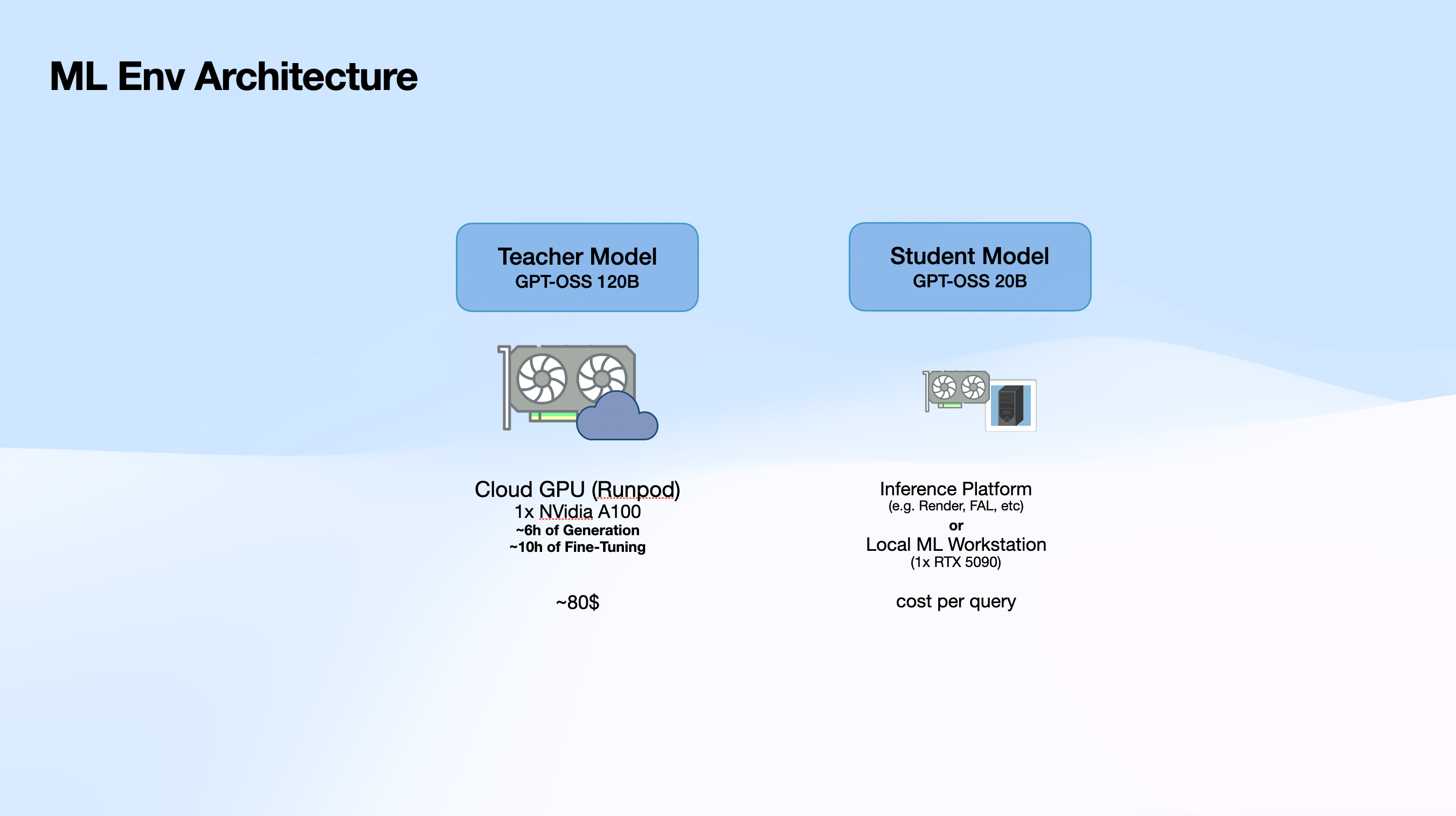
ML Env Architecture
-
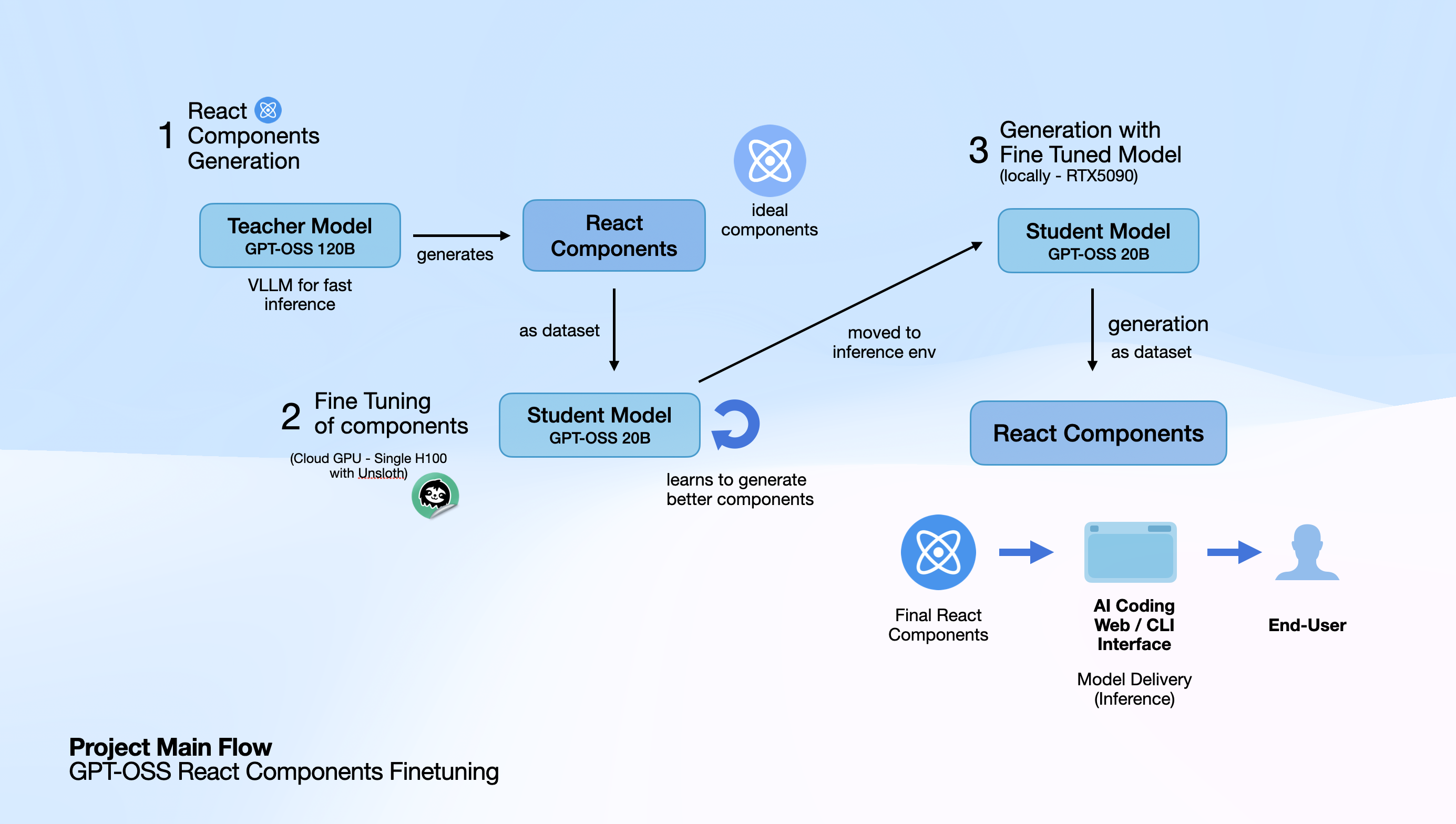
Project Main Flow
-
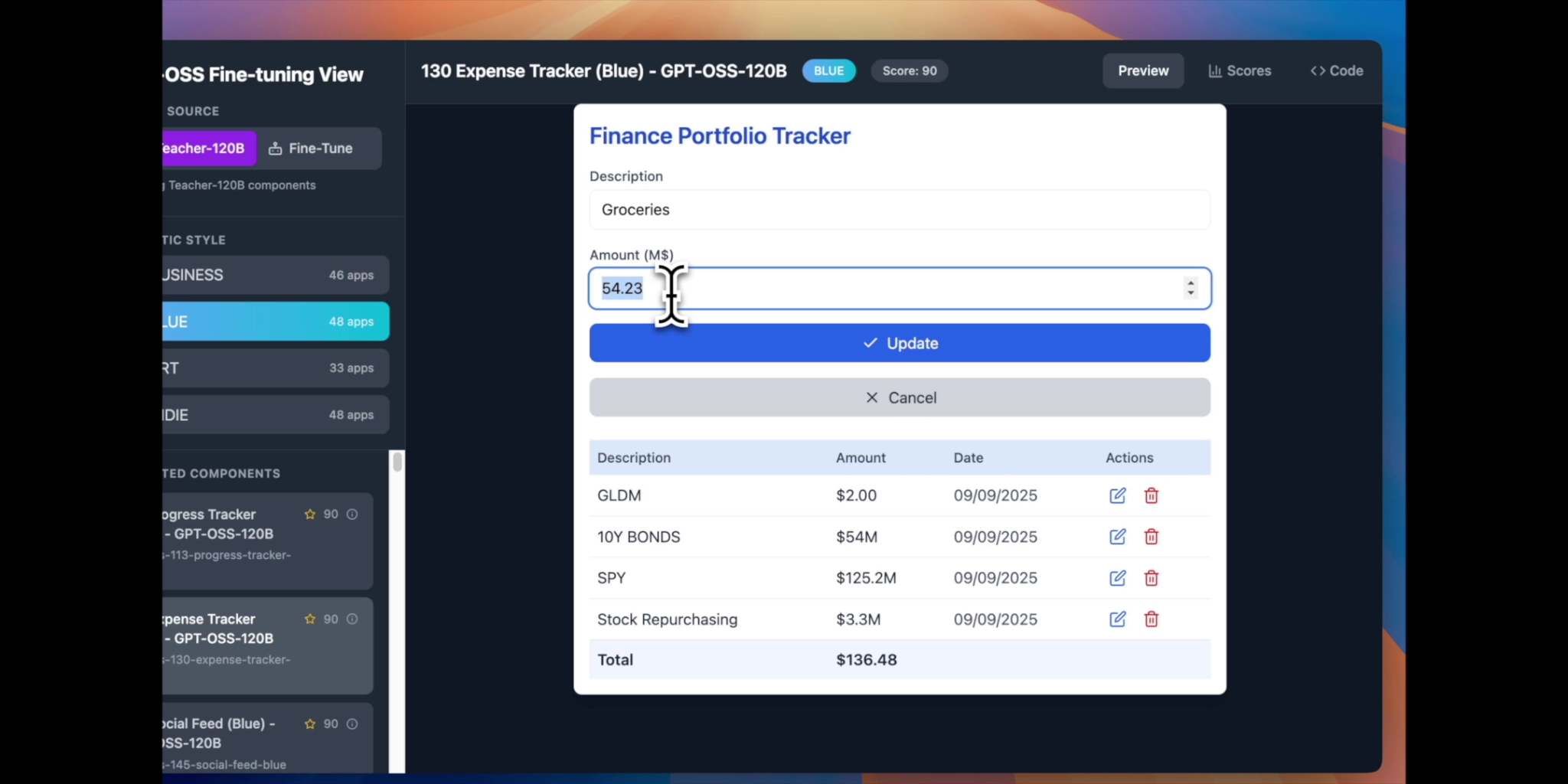
Main Finance component
-
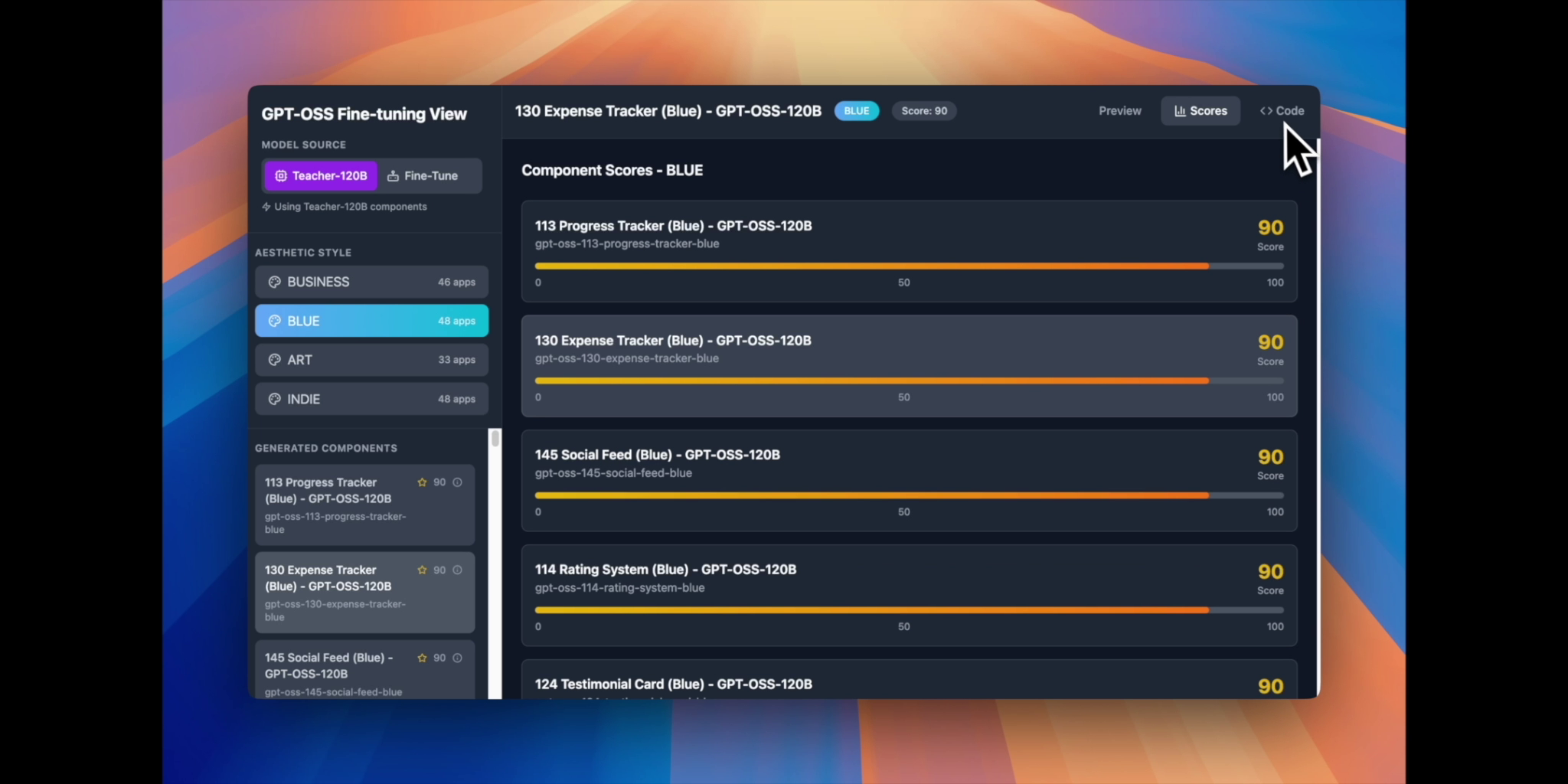
Scoring screen
-
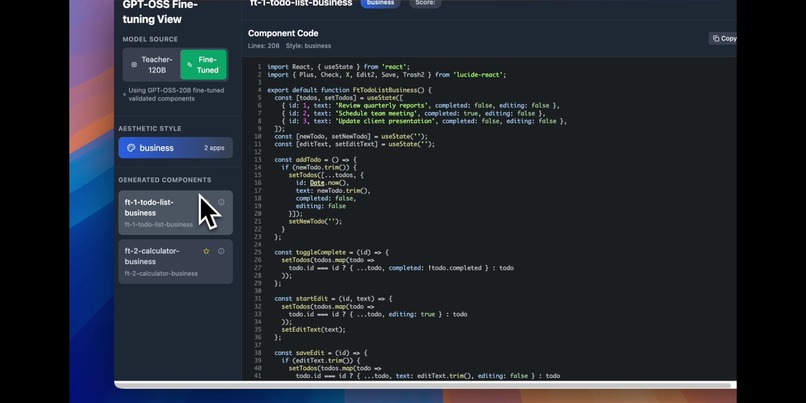
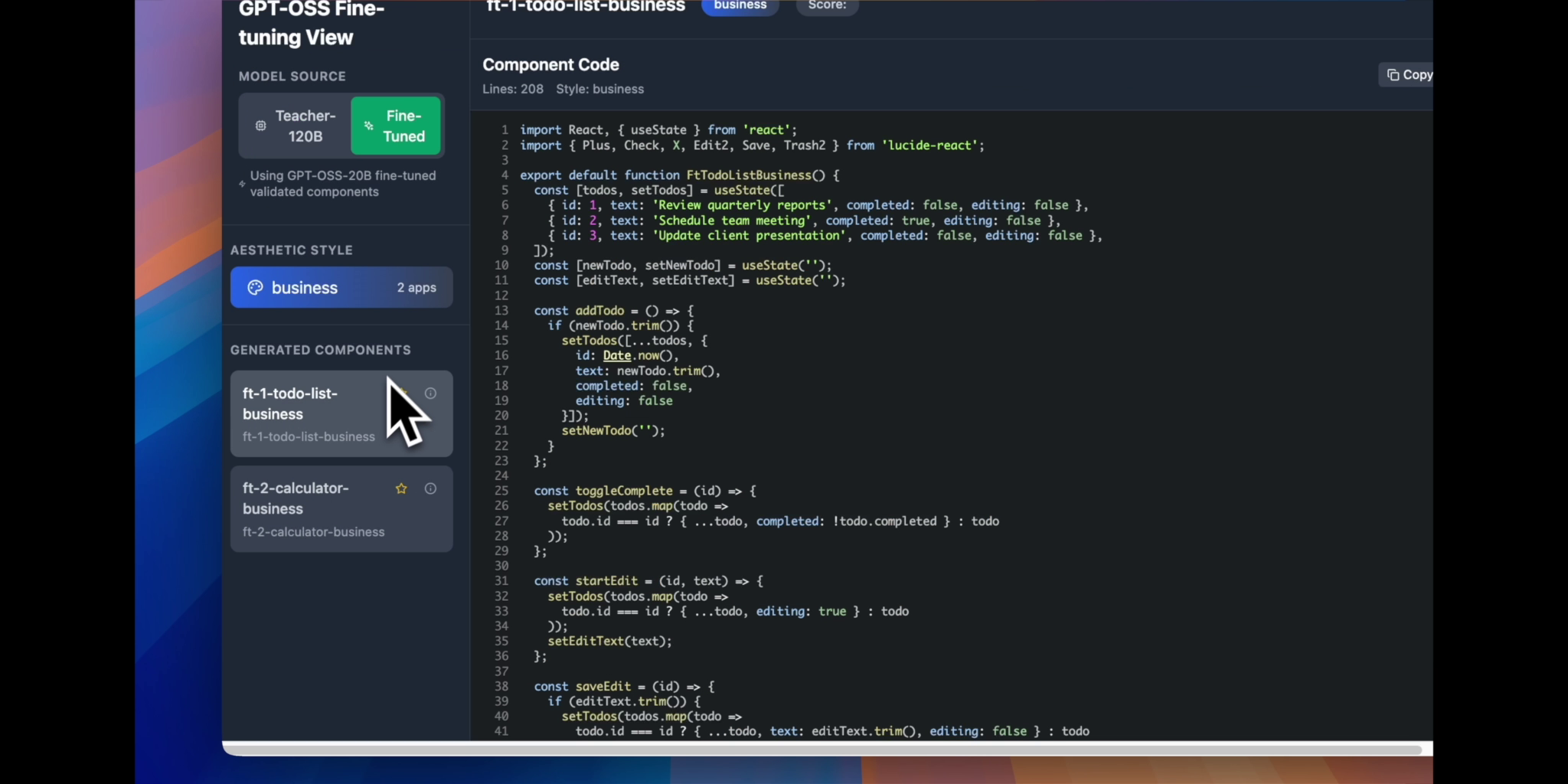
Components Code - 01
-
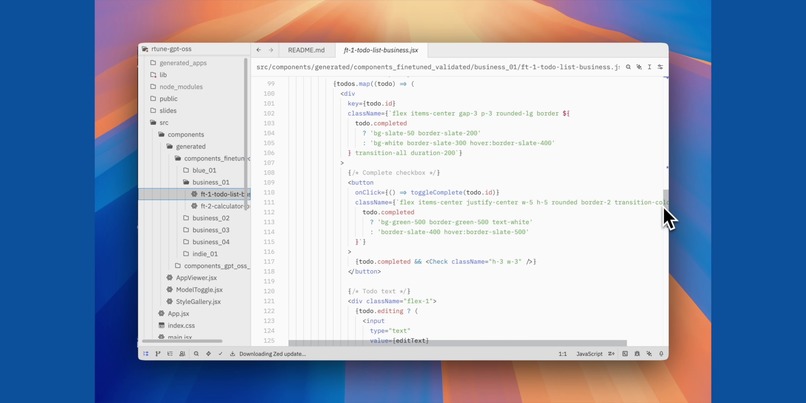
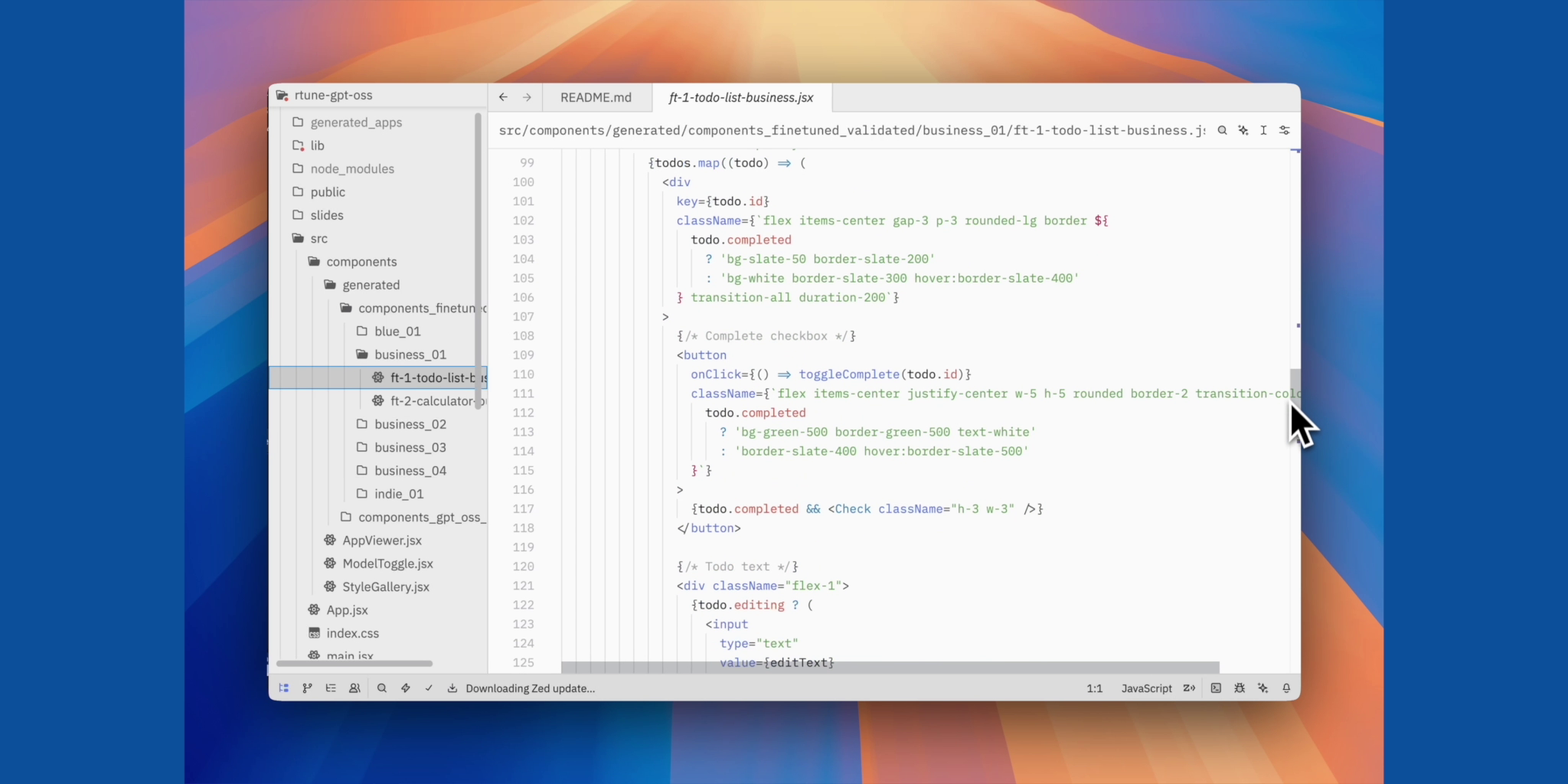
Components Code - 02

Inspiration
I was inspired by the need for high-quality React component generation that could run privately and cost-effectively. After seeing the capabilities of GPT-OSS models and experiencing the limitations of cloud-based solutions - API costs, privacy concerns, and latency - I wanted to create a system that brings enterprise-grade AI code generation to local hardware.
What it does
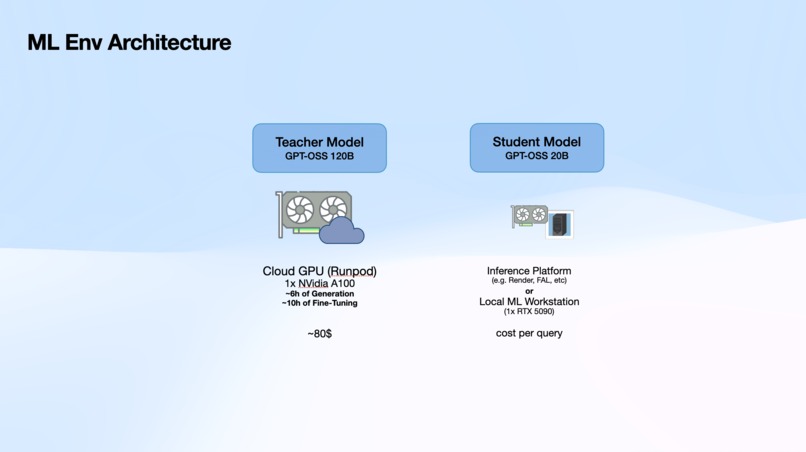
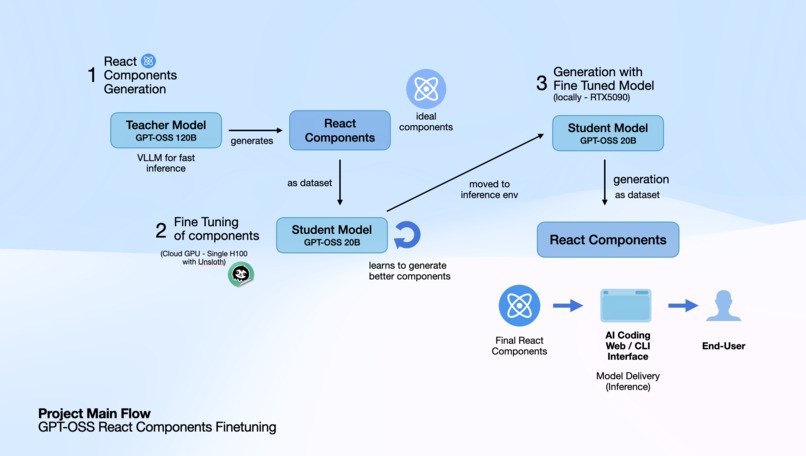
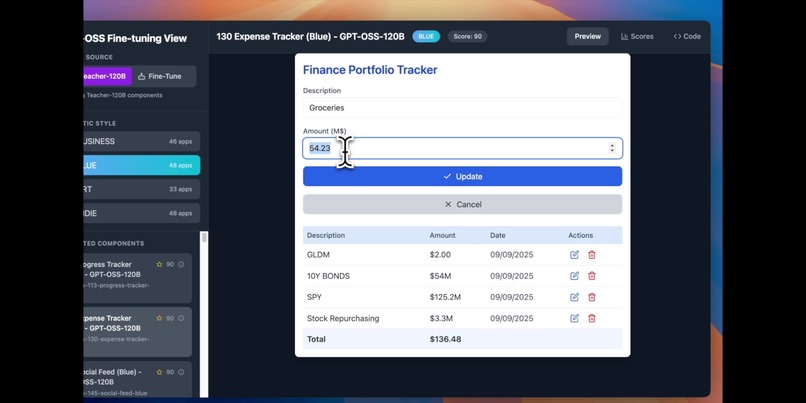
RTune fine-tunes GPT-OSS 20B to generate production-ready React components across four distinct aesthetic styles: business, indie, blue, and art. Each component includes modern React hooks, Tailwind CSS styling, semantic HTML, and realistic mock data. The system uses GPT-OSS 120B as a teacher model to generate training data, then transfers that knowledge to the smaller 20B model which can run efficiently on a single RTX 5090. A beautiful web interface showcases the generated components with live previews and code viewing.
How it was built
We built RTune using a teacher-student architecture with Unsloth optimization for efficient fine-tuning. The pipeline consists of just two main Python scripts:
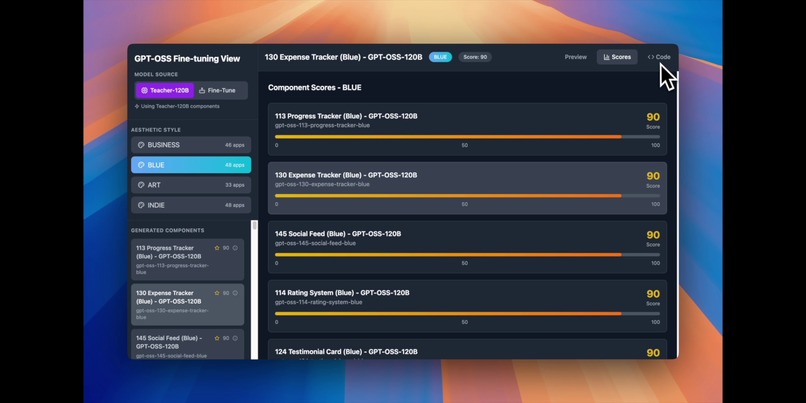
main.pygenerates 100+ React components using GPT-OSS 120B, each scored by GPT-5 for quality assurancesimple_unsloth_finetune.pyfine-tunes GPT-OSS 20B using QLoRA, fitting the model in just 15GB of VRAM
The entire training process takes about 2 hours on an RTX 5090, using 3000 training steps with components scoring above 75 as training data.
Challenges
The biggest challenge was ensuring consistent component quality across different aesthetic styles while maintaining realistic mock data. We had to iterate on our prompt engineering to generate components that were both visually distinct and functionally complete. Another challenge was optimizing the fine-tuning process to fit a 20B parameter model on consumer hardware - we solved this using 4-bit quantization and LoRA with carefully tuned hyperparameters.
Accomplishments
We're proud that RTune achieves GPT-4o level component quality with a model 6 times smaller, running completely offline. The generated components consistently score above 75 on our quality metrics, with many reaching 90+. The entire pipeline costs just $80 to run once, then provides unlimited free inference. Most importantly, this enables enterprises with strict privacy requirements to leverage AI code generation without compromising sensitive data.
Lessons learned
We discovered that GPT-OSS 120B performs exceptionally well as a teacher model for code generation tasks, trying to match GPT-4o quality on benchmarks. We learned that careful dataset curation - using only high-scoring components - dramatically improves fine-tuning results. We also developed efficient evaluation scripts using GPT-5 to ensure consistent quality across generated components.
What's next for RTune
Our roadmap includes:
- Fine-tuning GPT-OSS 20B directly for even better performance
- Adding support for Vue and Angular frameworks
- Creating domain-specific variants for finance, healthcare, and e-commerce
- Building an on-premise deployment package for enterprise customers
- Implementing real-time collaborative features for team development
- Extending to full-stack generation with backend components

Log in or sign up for Devpost to join the conversation.