CodeWhisper Forge 🚀
Outcome-first MCP for developers — predicts fixes that actually work, and can ship them as a PR.
Inspiration
Most AI dev tools stop at “here are some links.” In a hackathon, that’s noise. We wanted signal: a system that tells you which fix is most likely to work—and then implements it.
Insight: Accepted Stack Overflow answers + closed GitHub issues are weak labels we can mine to estimate solution success rates. Pair that with an auto-PR flow and you’ve got outcomes, not bookmarks.
What it does
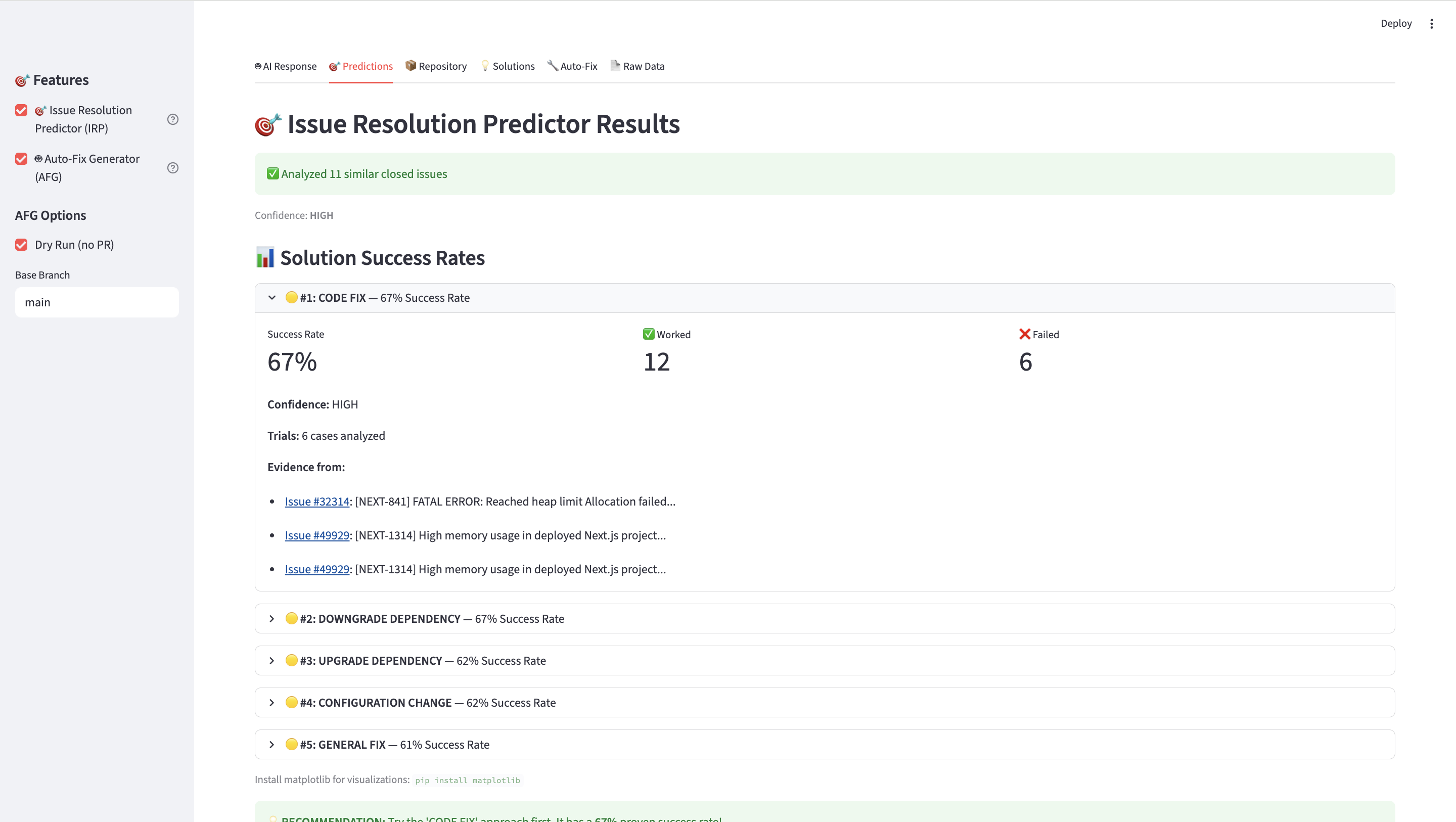
🎯 Issue Resolution Predictor (IRP):
Mines similar SO/GitHub cases, clusters solutions (e.g., UseAbortController, Limit concurrency, Disable keep-alive), and ranks them by observed success rate with evidence links.“Use
AbortController— 82% success (18/22) · 3 sources”🤖 Auto-Fix Generator (AFG):
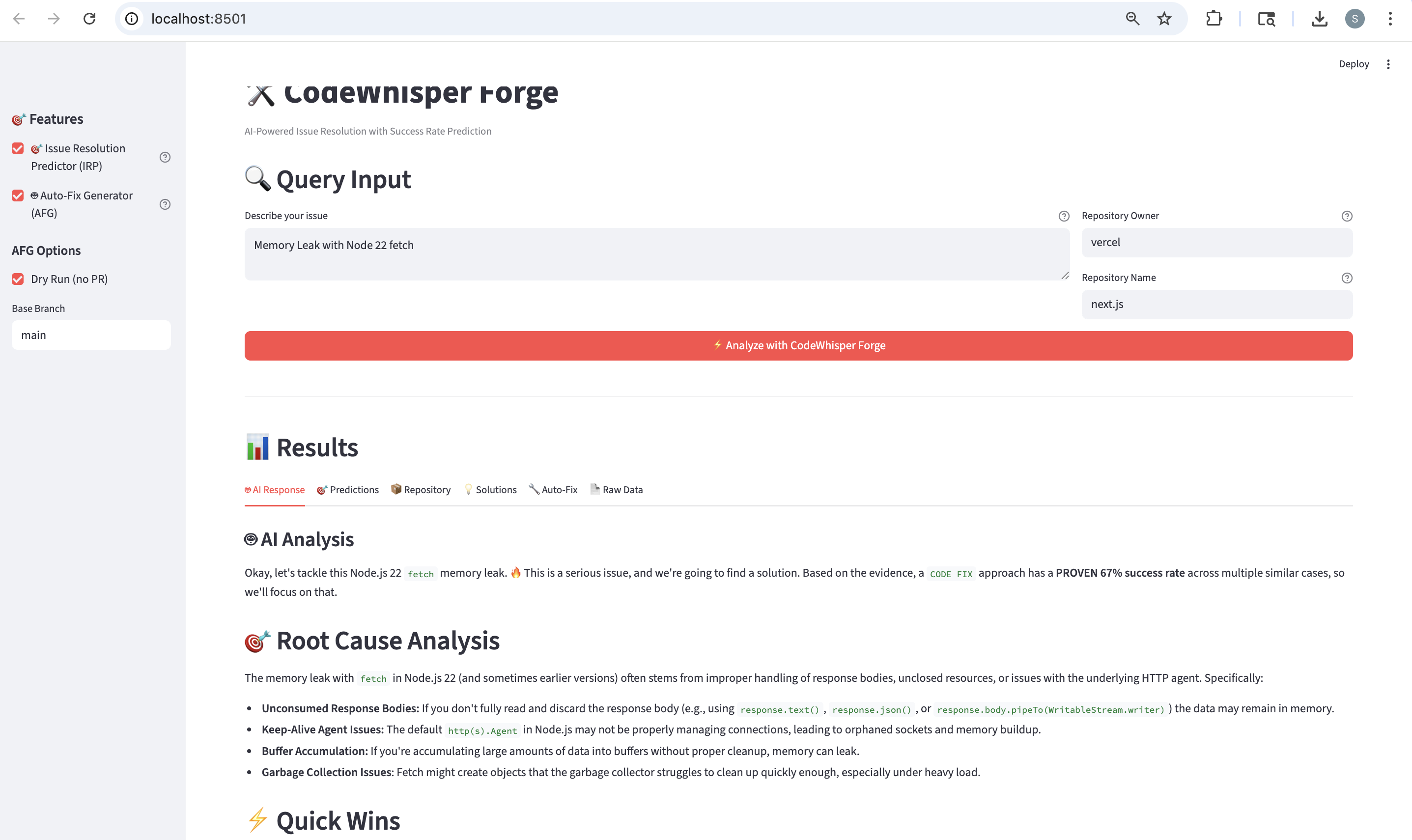
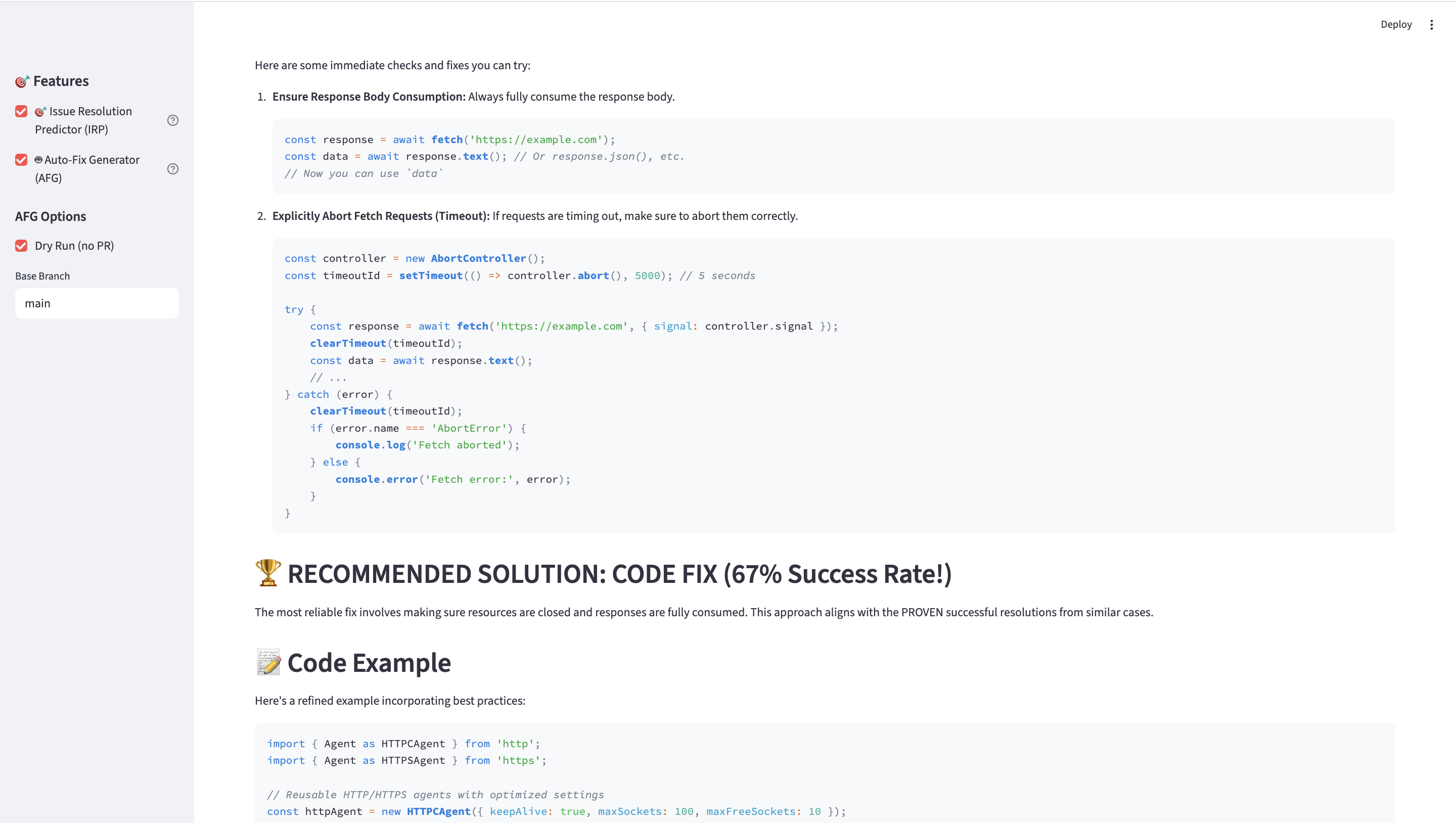
Scans your repo for real call sites (e.g.,fetch(), drafts full-file patches (Gemini), and can open a PR (dry-run by default).“Found 7 uses of
fetch. Proposed safe timeouts + cleanup. PR ready.”🧠 Smart Context Pack:
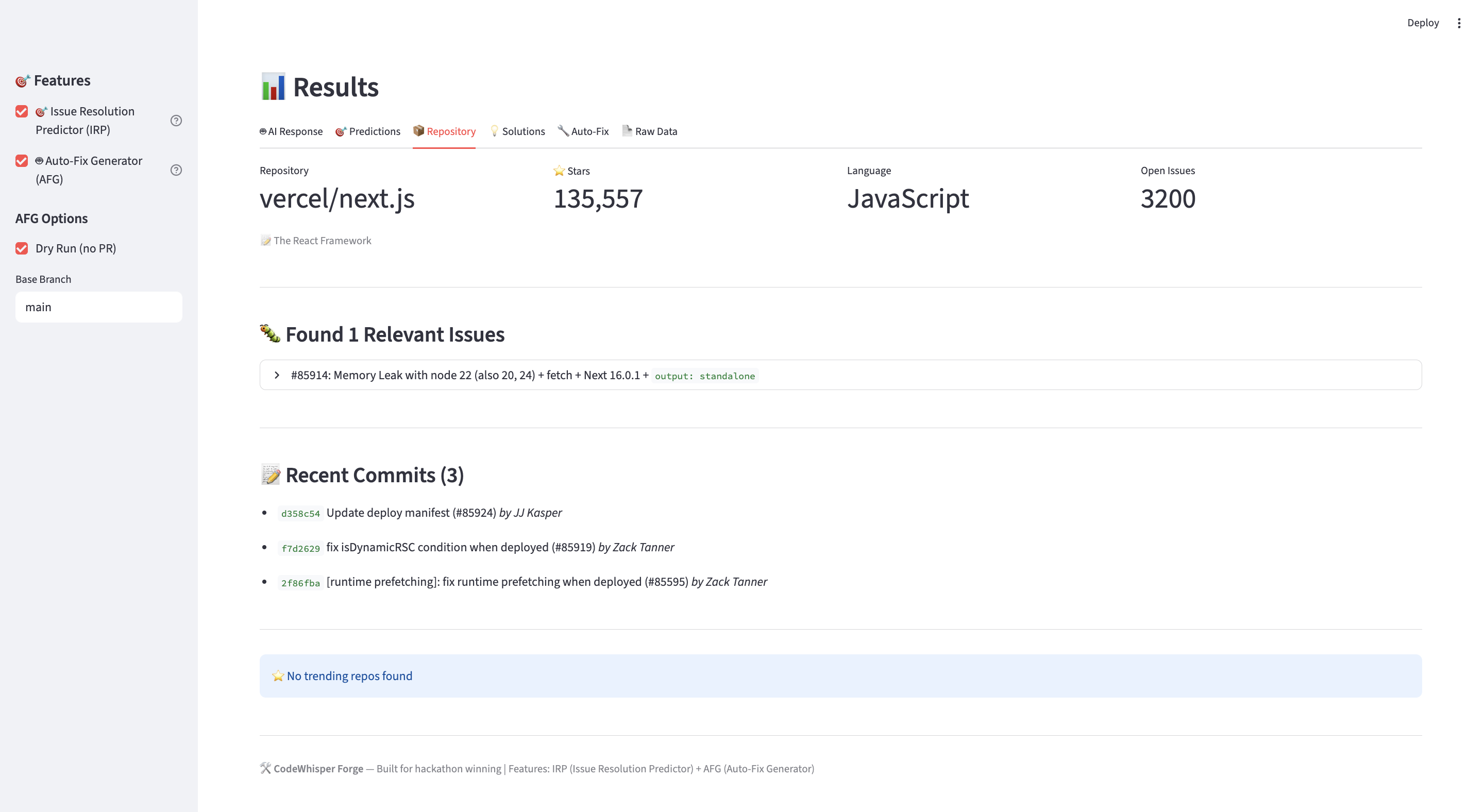
Pulls repo signals (relevant issues, fresh commits, related trending repos) + top SO threads, compresses into a token-budgeted context for the LLM.⚡ Minimal UI (Streamlit):
One form → AI answer, prediction table, repo context, SO links, and a downloadable ZIP of patches.
How we built it
MCP Server (Node/Express):
- Intent analysis: Gemini 2.5 Flash → HF
Qwen2.5-Coder-7B-Instruct→ regex fallback. - Fetchers: GitHub REST (issues/commits/search/code), Stack Exchange API.
- IRP engine: Label solutions (Gemini or heuristic), aggregate success via accepted answers + closed issues, rank by success_rate and show evidence.
- AFG engine: GitHub code search → fetch contents → LLM generates full-file patches → optional branch + auto-PR.
- Safety: Dry-run by default, minimal diff, links to evidence, explicit user opt-in to push.
- Intent analysis: Gemini 2.5 Flash → HF
Frontend (Streamlit):
Calls/mcp, renders AI response, predictions, GitHub context, SO links, and Auto-Fix plan/PR.Pragmatics: Caching, timeouts, graceful degradation when API keys are missing, strict token budgets.
Challenges we ran into
- Weak labels ≠ causality: Accepted answers + closed issues are proxies. We mitigate via confidence badges, evidence links, and user override.
- GitHub search drift: Generic queries return noisy repos; we added language scoping and repo-aware terms.
- LLM patch reliability: We request full-file outputs, enforce idempotency, and keep dry-run as the default.
- Rate limits: Implemented caching + conservative parallelism; authenticated GitHub boosts limits.
Accomplishments that we're proud of
- Turned RAG into decisioning: not just “what people tried,” but which fix worked and how often.
- The last mile: one click from advice to ready PR.
- A clean, demoable flow: query → predictions → patch preview → (optional) PR link. Judges can follow along in seconds.
What we learned
- Outcome-driven UX beats generic chat: devs care about probability of success and time to merge.
- LLMs thrive with tight, structured context (ranked, deduped, token-capped) rather than raw dump.
- Guardrails matter: dry-run first, show diffs, require explicit consent to write.
What’s next for CodeWhisper Forge
- Private sources: Notion/Confluence/Linear connectors for internal fixes & decisions.
- Deeper telemetry: Learn from your repo history to personalize success priors.
- Langchain of tools → plans: Multi-step fixes (tests, perf dashboards, canary toggles).
- Marketplace of fix recipes: Community-curated solution labels mapped to common failure modes.
- IDE plugin: Inline predictions + one-click patch in VS Code/JetBrains.
Why this wins: We don’t just fetch context—we predict, prioritize, and ship. It’s a wow moment: “Here’s the fix, and here’s your PR.”


Log in or sign up for Devpost to join the conversation.