-
-
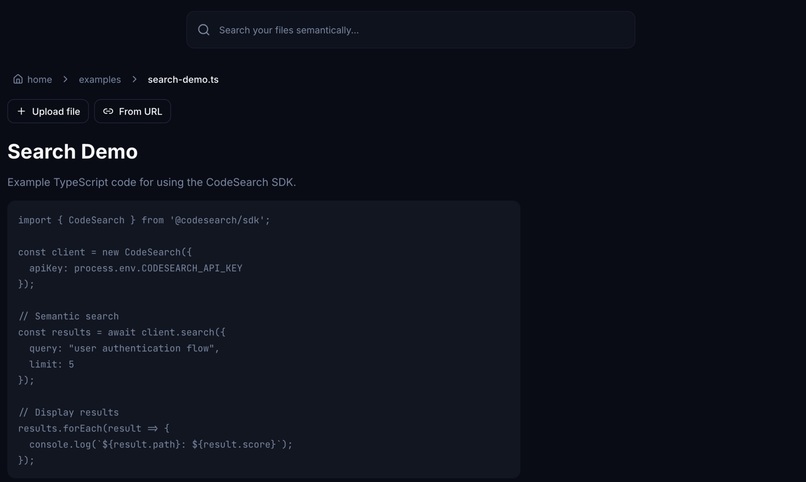
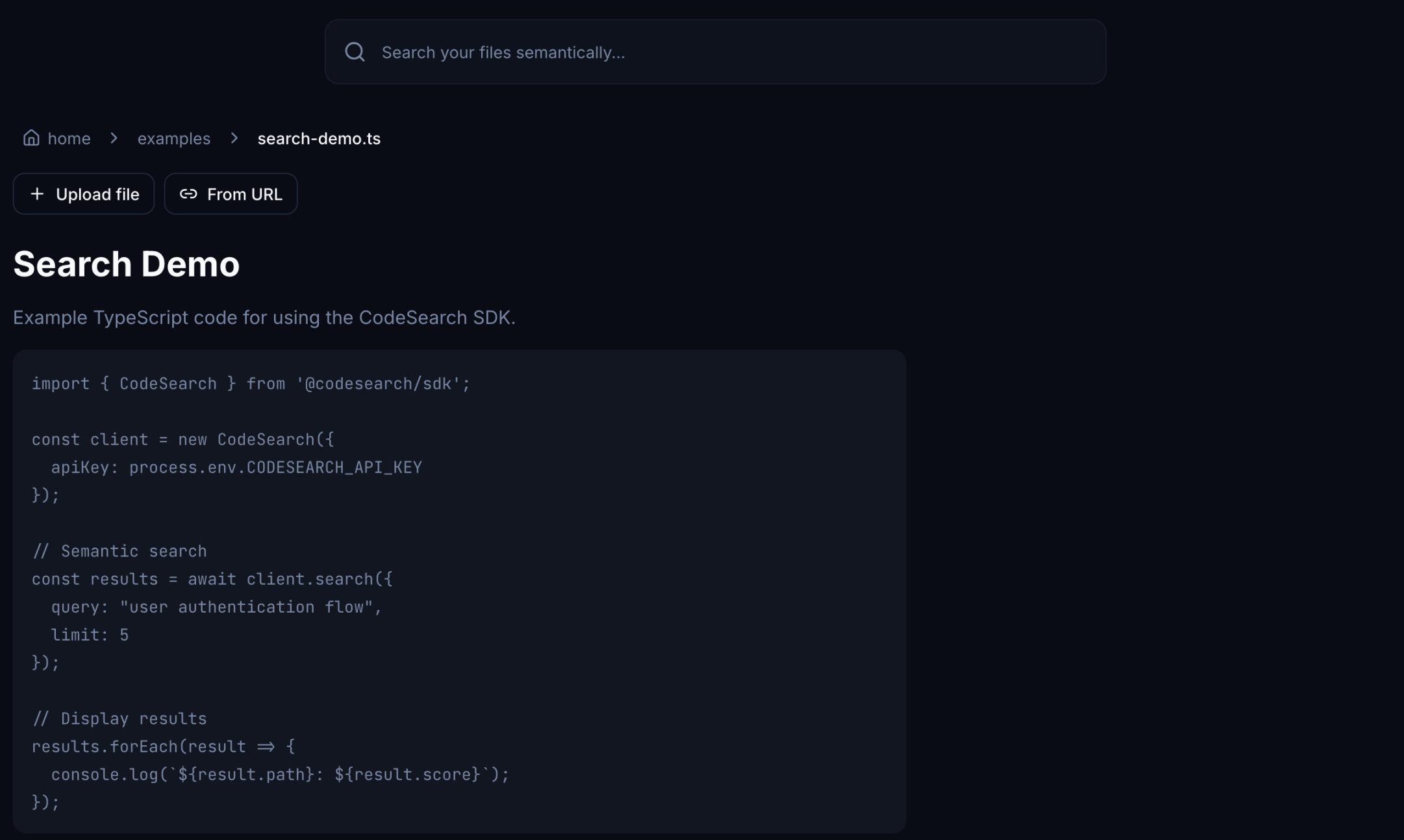
Recherche sémantique via la plateforme web
-
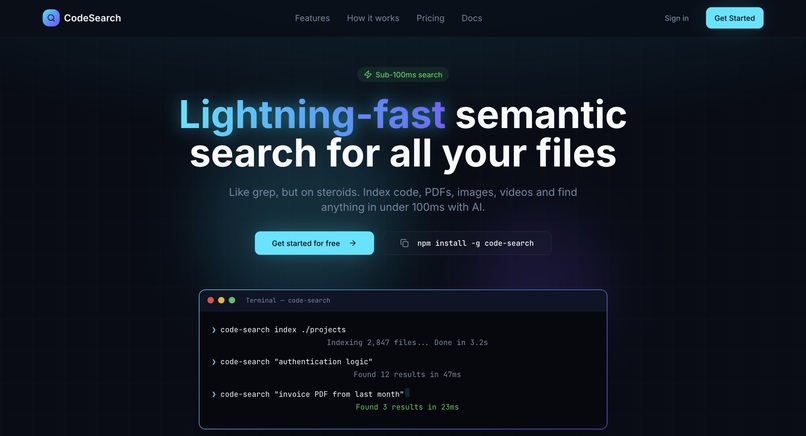
Page Index du site du projet
-
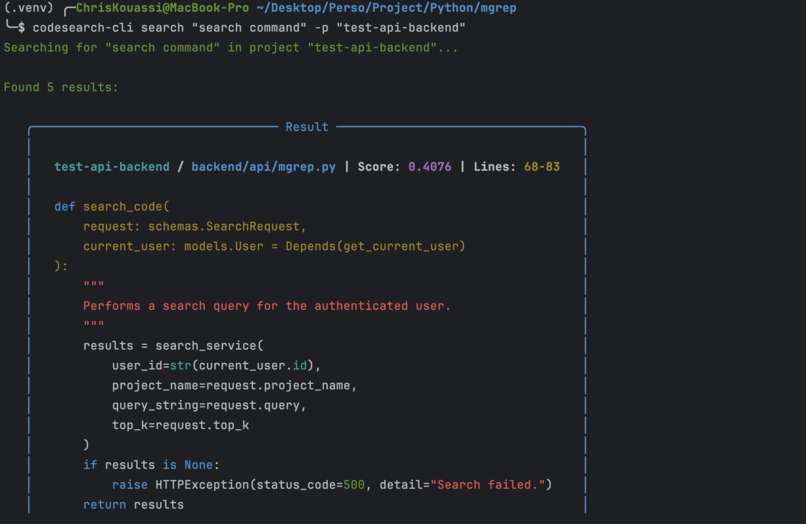
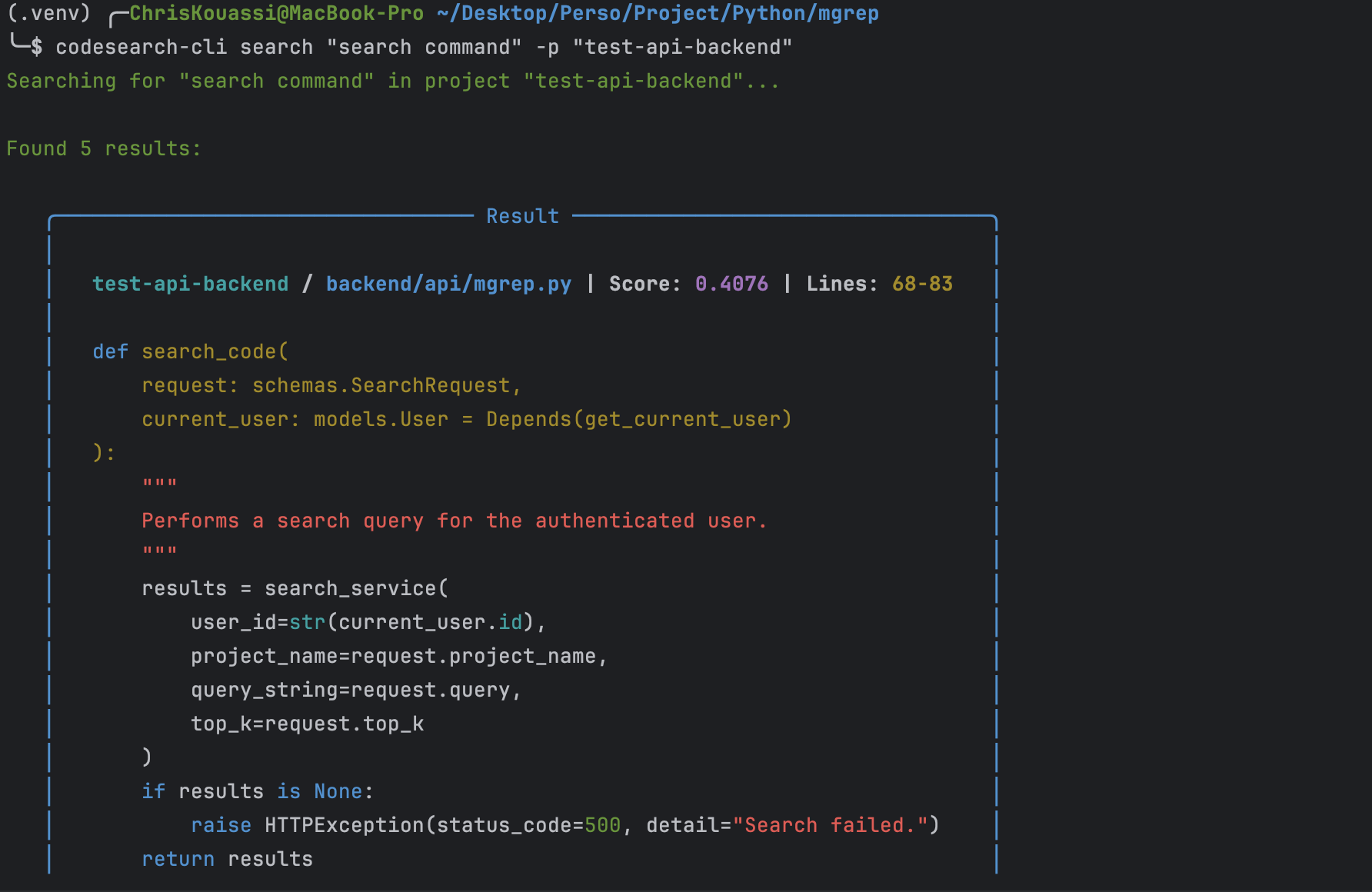
Recherche via le CLI
-
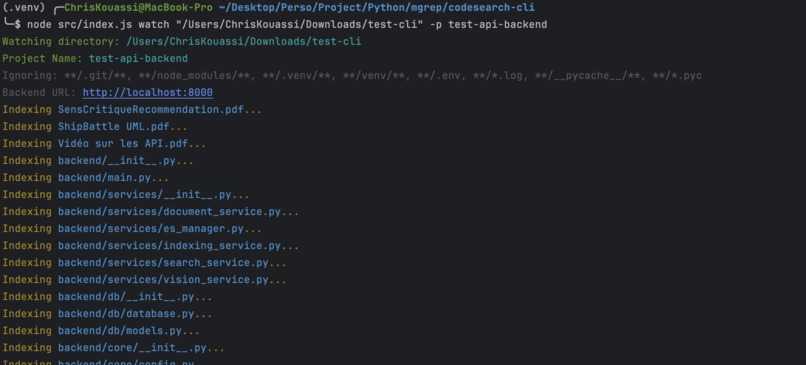
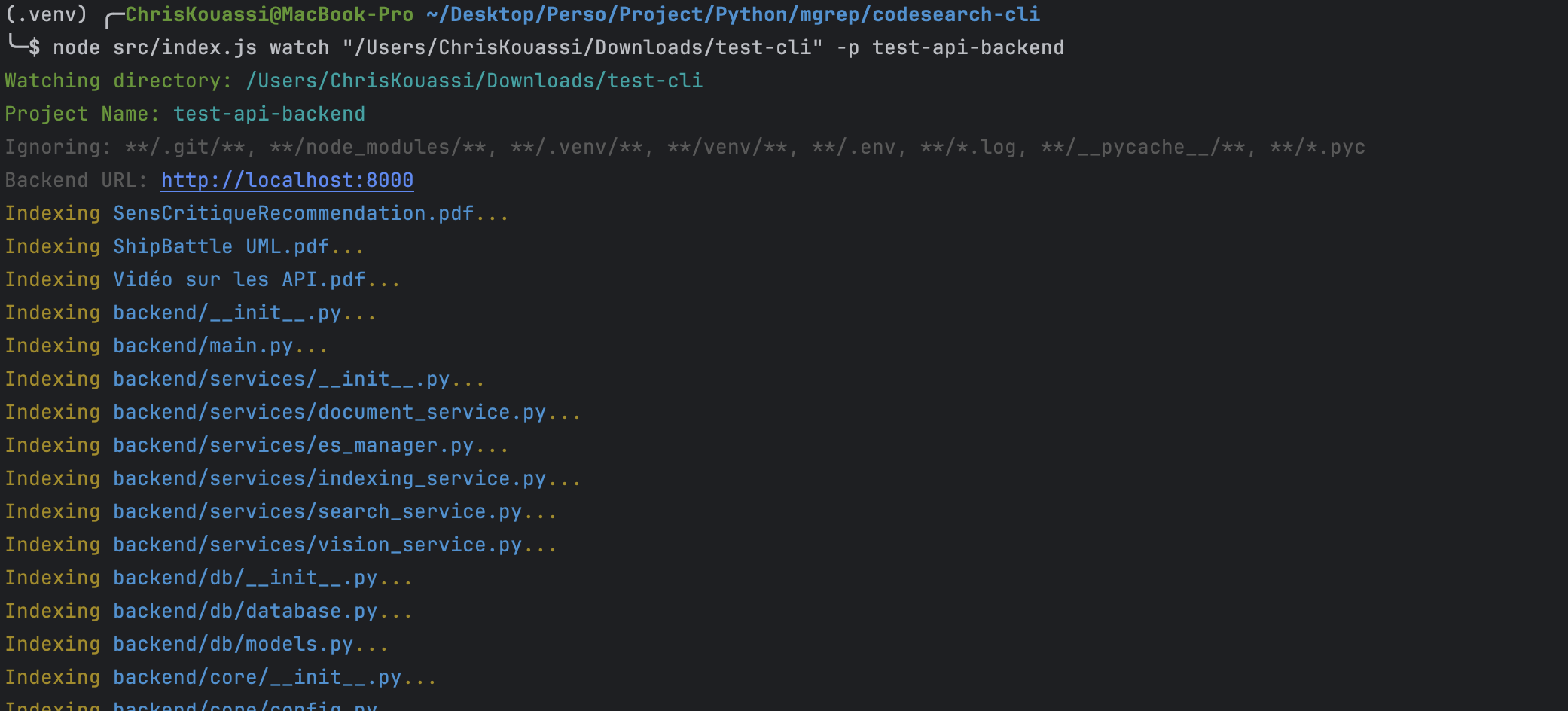
Indexation des fichiers via le CLI
💡 Inspiration
Les développeurs passent environ 20 % de leur temps simplement à chercher des informations existantes. Nous avons réalisé que la recherche traditionnelle type "Ctrl+F" ou grep est cassée : elle repose sur une correspondance exacte de mots-clés. Si vous cherchez "ajouter", vous passez à côté de la fonction nommée sum. De plus, nos ressources numériques sont cloisonnées : le code est dans l'IDE, la documentation dans des PDF et les maquettes dans des dossiers d'images. Nous voulions construire un "Google pour notre environnement de développement local" — un outil qui comprend l'intention derrière une requête, pas seulement la syntaxe, et qui unifie le code, la documentation et les images dans une barre de recherche intelligente.
🚀 Ce que fait le projet (What it does)
CodeSearch est un moteur de recherche sémantique et une intelligence multimodale pour les développeurs et les équipes.
- Recherche sémantique de code : Vous pouvez taper "calculer la somme" et il trouve
def add(a, b)car il comprend que ces concepts sont liés. - Recherche visuelle (Vision Search) : Il indexe les images (comme les captures d'écran ou les maquettes) en générant des descriptions via IA. Vous pouvez retrouver une capture d'écran de connexion simplement en tapant "interface de login".
- Base de connaissances unifiée : Il supporte simultanément Python, JS, Java, les PDF, le Markdown et les images.
- Interface Rocket Search : Un frontend web moderne qui organise les ressources en Namespaces (par exemple, par projets ou équipes), rendant la technologie accessible à toute l'équipe, pas seulement aux utilisateurs du CLI.
- Indexation en temps réel : Un outil CLI surveille vos répertoires et indexe automatiquement les changements au fur et à mesure que vous codez.
⚙️ Comment nous l'avons construit (How we built it)
Nous avons conçu une architecture hybride séparant le traitement IA lourd de l'expérience utilisateur :
- Le Cerveau (IA) : Nous utilisons SentenceTransformers (
all-MiniLM-L6-v2) pour générer des embeddings vectoriels de 384 dimensions pour le texte et le code. Pour les images, nous avons intégré le modèle FeatherlessAI Vision (llama-3.2-11b-vision-instruct) pour convertir le contenu visuel en descriptions textuelles consultables. - Le Parseur : Nous utilisons Tree-sitter pour parser le code source en arbres syntaxiques abstraits (AST). Cela nous permet de découper ("chunker") le code intelligemment par fonctions et classes plutôt que par lignes arbitraires.
- Le Backend : Un serveur FastAPI orchestre le flux de données, stockant les vecteurs dans Elasticsearch et les métadonnées utilisateurs/auth dans PostgreSQL.
- Le Frontend : Nous avons construit "Rocket Search Magic" (via Lovable/React) pour offrir une expérience web fluide avec gestion des namespaces et visualisation des résultats.
🚧 Les défis rencontrés (Challenges)
- Chunking intelligent : Découper le code pour le modèle d'IA est difficile. Un découpage fixe de 20 lignes coupe souvent une fonction en deux, faisant perdre le contexte. Nous avons dû travailler sur la logique pour mieux respecter les limites des fonctions.
- Coûts de l'IA Vision : Analyser chaque image avec un grand modèle de Vision est coûteux en calcul. Nous avons dû réfléchir à des stratégies pour ne réanalyser les images que lorsque leur hash change afin d'éviter les appels API inutiles.
- Définir la similarité : Trouver le bon seuil de pertinence pour la recherche était délicat. Un seuil de similarité cosinus fixe de
0.1est parfois trop permissif, renvoyant des résultats non pertinents.
🏆 Nos fiertés (Accomplishments)
- Intégration multimodale : Avoir réussi à combiner la recherche de texte, de code et d'images dans une seule liste de résultats classés.
- Watcher temps réel : La construction d'un CLI robuste qui surveille les événements du système de fichiers et déclenche la réindexation instantanément sans bloquer le flux de travail du développeur.
- Parsing AST : Être allé au-delà de la simple lecture de texte pour comprendre réellement la structure du code (Classes/Fonctions) en utilisant Tree-sitter.
- L'UI Rocket Search : Avoir réussi la transition d'un pur outil CLI vers une belle application web accessible.
🧠 Ce que nous avons appris (What we learned)
- Nuances de la recherche vectorielle : Nous avons appris que la recherche sémantique nécessite un réglage minutieux. Les modèles d'embedding ont des limites de tokens (environ 512 tokens), ce qui signifie que nous ne pouvons pas simplement donner un fichier entier à l'IA ; une segmentation intelligente est clé.
- La valeur du contexte : Du code sans contexte (imports, noms de classes) est difficile à chercher. Nous avons appris l'importance de préserver la hiérarchie du code lors de l'indexation.
- Complexité de l'infrastructure : Orchestrer PostgreSQL, Elasticsearch et les services Python nécessite une configuration Docker et environnementale solide.
🔮 La suite pour CodeSearch (What's next)
- Chat avec votre Code (RAG) : Nous prévoyons d'ajouter une interface de Chat où un LLM utilise les résultats de recherche pour répondre à des questions comme "Comment refactoriser cette fonction ?".
- Extension VS Code : Intégrer la recherche directement dans l'éditeur pour que les développeurs n'aient jamais à changer de contexte.
- Indexation plus intelligente : Implémenter un indexeur basé sur Git pour suivre les changements par commit et améliorer notre stratégie de chunking pour mieux gérer les longues fonctions.
- Optimisation : Implémenter des seuils dynamiques pour les résultats de recherche et un système de "garbage collection" pour supprimer automatiquement les fichiers effacés de l'index.
Built With
- elastic
- node.js
- postgresql
- python
- react


Log in or sign up for Devpost to join the conversation.