-
-

landing page pt4
-
landing page
-
landing page pt5
-
landing page pt7
-

landing page pt8
-
landing page pt6
-

landing page pt2
-
landing page pt3



Inspiration
We ideated closely with our mentors Weslyn and Galin throughout the hackathon — asking questions in person and over WhatsApp. They gave us macro guidance on positioning and micro feedback on execution. Weslyn's experience in Google's AI startup program meant she'd seen the same problem surface across dozens of pre-seed to Series B companies: technical debt compounds like interest.
The numbers are brutal. Roughly 42% of developer time is lost to technical debt. It would take an estimated 61 billion work days to pay off the world's current technical debt. In the US alone, $2.41 trillion is lost annually.
At the same time, vibe coding is everywhere. Code appears instantly and refactors feel effortless. But the hidden tax is real — tokens up front, debugging later — because you can't trust an LLM's "this is faster" on faith.
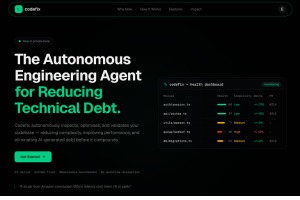
CodeRex closes that gap. It turns vibe-coded changes into validated PRs: benchmarking and testing every optimisation, rejecting regressions automatically, and only shipping improvements that come with proof.
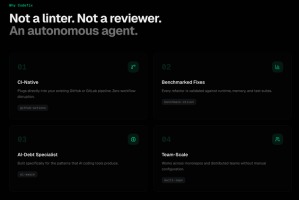
What it does
CodeRex is like hiring a senior engineer who reviews your codebase, finds the slow parts, rewrites them to be faster, and then proves the new version is better before submitting the change — except it does all of this autonomously in under two minutes.
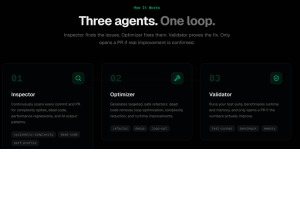
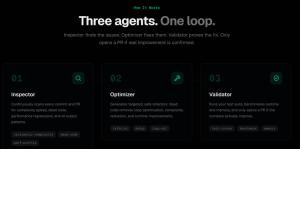
Under the hood, eight specialised AI agents collaborate inside a sandboxed Docker environment:
• A Triage agent scans every function via static analysis and flags side effects like database writes as unsafe to touch. • An Analyst autonomously selects from 10+ diagnostic tools to investigate bottlenecks — profiling complexity, benchmarking performance, even searching the web for optimal algorithms. • An Optimizer generates improved code and self-validates it. • A Test Designer invents tests from scratch and self-fixes any failures. • A Validator runs a fully deterministic rubric — five hard vetoes on correctness, memory, and runtime, plus a statistical significance test at every input size — with zero AI judgment on the final decision.
All code execution happens inside isolated Docker containers, so optimisations are tested safely without affecting the host system. If rejected, the system loops back with the rejection context and the Analyst forms a new hypothesis, up to three rounds.
The result: complexity class improvements like O(n²) → O(n), speedups of up to 18×, all backed by p < 0.05 statistical proof, delivered as a merge-ready pull request.
How we built it
CodeRex is a multi-agent system built on Claude's native tool-use API — not prompt chains. Each agent provides tool schemas and Claude autonomously decides which tools to call, in what order, and when to stop.
The Analyst (11 tools), Optimizer (5), and Test Designer (3) run on Sonnet with extended thinking enabled (5,000-token budget, temperature = 1), streaming live reasoning traces and tool events to the frontend via SSE across 17 event types so you can watch decisions unfold in real time.
When the agents hit unfamiliar patterns, the Analyst and Optimizer can trigger web search through a nested Haiku call using the web_search_20250305 tool type, then fold results back into their hypothesis — an agentic call inside an agentic call.
To keep costs down we use prompt caching ( cache_control: {"type": "ephemeral"} ) so repeated turns in long tool loops become cache hits, and we route tasks across models: Sonnet for deep reasoning, Haiku for fast planning and summaries. Every API call is logged into a thread-safe UsageTracker that records input/output tokens and cache reads/creates from response.usage , broken down by agent and function for full cost transparency.
The deterministic validation layer makes zero LLM calls. It benchmarks runtime and memory, computes static metrics via lizard and radon, estimates Big-O via log-log regression, and applies Welch's t-test at p < 0.05. If it rejects an optimisation, Claude reads the rejection reasons, diagnoses root cause using shared ConversationContext memory, and adapts its strategy for up to three rounds — until the math approves.
Challenges we ran into
Sandboxed execution without losing provable metrics. We built a Docker harness that runs original versus optimised code with identical serialised inputs, captures stdout/stderr plus runtime ( perf_counter ) and memory ( tracemalloc ), enforces CPU, memory, and time limits, and tears down per run so verification stays deterministic and safe.
Agents duplicating work instead of converging. We introduced a shared ConversationContext that persists snapshot metrics, diffs, veto reasons, and prior hypotheses across agents and rounds. Pre-seeding prompts with baseline evidence cut redundant tool calls while keeping tool autonomy intact.
Invalid statistical proof from miswired benchmarking. We rewired the Validator to run like-for-like trials per input size, separated timing from memory profiling, standardised warmups and run counts, and only accept improvements when Welch's t-test is computed on comparable timing distributions.
Accomplishments we're proud of
We built an eight-agent system where Claude autonomously analyses, optimises, and mathematically proves improvements to Python code — all inside sandboxed Docker containers — in under 24 hours.
Each agent reasons independently with real tool access. The Analyst chooses from 10+ diagnostic tools based on what it discovers. The Optimizer self-validates its own code. The Test Designer invents tests from scratch, catches failures, and fixes them without human intervention. When the deterministic Validator rejects an optimisation, agents read the rejection reasons and adapt their approach. Not a retry loop — a genuine multi-agent conversation.
Our core technical moat is the Validator itself: zero AI judgment on pass/fail, five hard vetoes on correctness and performance, Welch's t-test at every input size with p < 0.05 required. This makes CodeRex structurally different from every other AI coding tool — the AI cannot influence whether its own work passes.
On our demo function the system achieved an O(n²) to O(n) complexity class improvement with 18.5× measured speedup, 25/25 generated tests passing, and statistical significance at all input sizes. The system also exercises judgment about what not to touch — AST-based triage correctly identifies database writes, network calls, and file I/O as unsafe to optimise.
What we learned
Making AI generate better code is easy. Making AI prove its work is an order of magnitude harder.
At 3am we found our "p < 0.05" pitch was backed by dead code — the significance function existed but was never called, and our one reachable t-test compared 2 samples against 2 samples. We rebuilt the entire benchmarking path from scratch: 10 runs per input size, warmup runs, timing separated from memory profiling, per-size Welch's t-test.
We learned that agents do redundant work by default. Pre-seeding them with existing metrics made them faster and more purposeful without removing any autonomy.
On the team side, we learned to delegate aggressively — splitting agent architecture, frontend, and pitch prep in parallel — and leaned on mentors to pressure-test our framing and HackEurope organisers to clarify judging criteria, which is what shaped the deterministic proof layer as our central differentiator.
The most counterintuitive lesson: the system got more powerful when we stopped trusting the AI. Five hard vetoes, zero LLM judgment — plausible-sounding work gets rejected.
What's next for CodeRex
First, expand beyond Python. The agent architecture is language-agnostic; only the AST triage layer is Python-specific.
Then, CI/CD integration — so CodeRex runs automatically on every pull request with merge-ready PRs for approved optimisations.
From there, a shared ConversationContext so agents reference each other's full reasoning across runs, not just summaries. That persistent memory enables the most ambitious step: a student-teacher meta-learning engine where successful optimisation patterns get indexed by the deterministic Validator and fed back to future agent runs. The agents are the students, the Validator is the teacher — it gives a hard pass/fail reward signal on every attempt, and over time the system learns which strategies work for which code patterns. The Validator's deterministic nature makes this uniquely powerful: the reward signal is mathematically grounded, not vibes.
Finally, expanding the proof layer itself to cover concurrency safety and API contract preservation — not just performance and correctness.



Log in or sign up for Devpost to join the conversation.