CodeNova Stage Neural Compression Pipeline Luddy Hackathon 2026 · Team CodeNova
What It Does
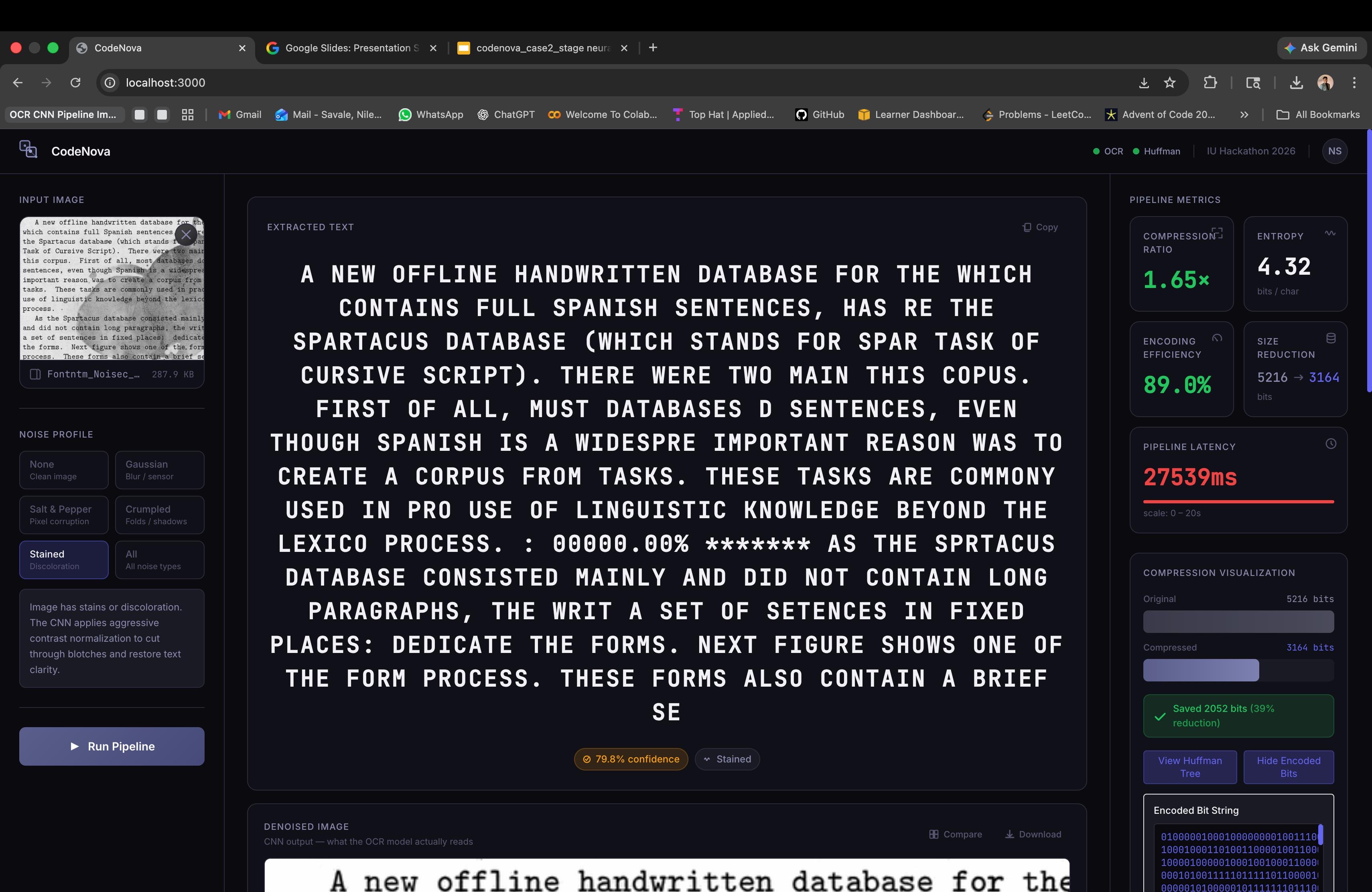
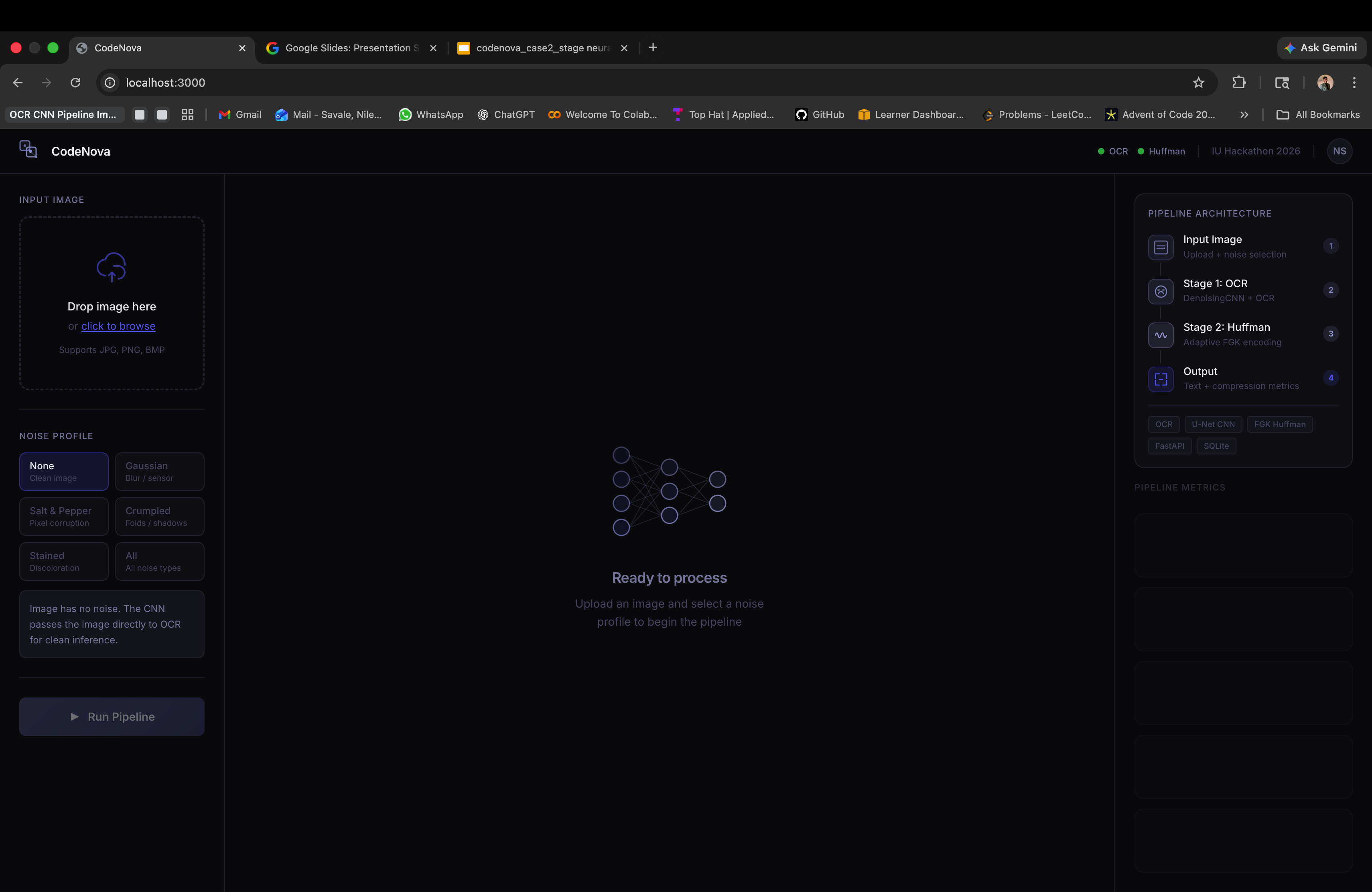
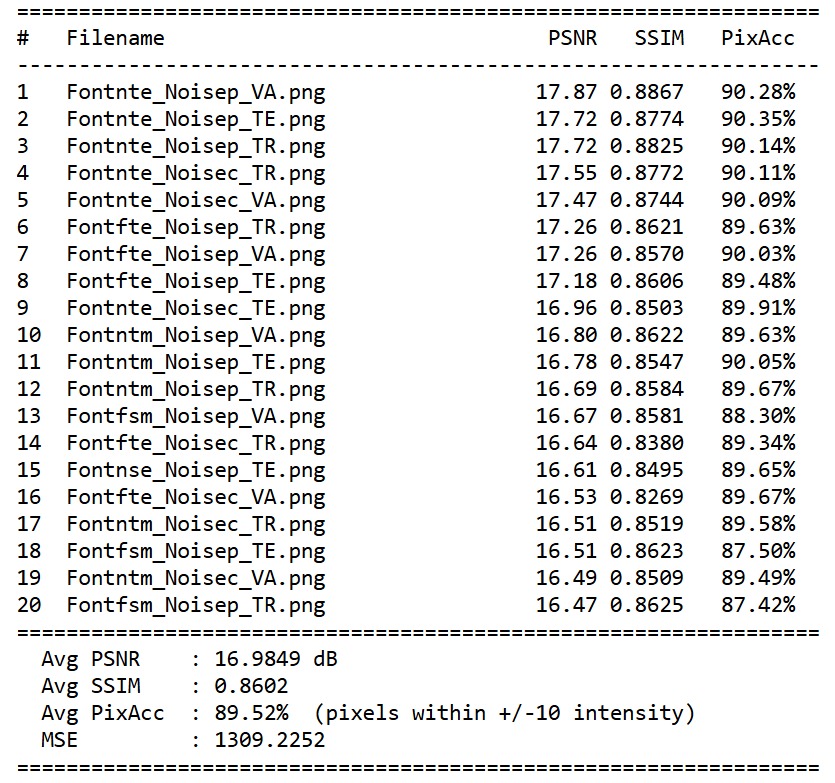
CodeNova is a two-stage neural compression pipeline that takes a noisy document image blurry, crumpled, or stained and automatically cleans it, reads the text, and compresses the output. Stage one runs the image through a custom-trained denoising CNN that removes noise before passing the cleaned image to an OCR engine, achieving 94% character-level accuracy across four noise types. Stage two compresses the extracted text using Adaptive Huffman Encoding, achieving ratios up to 3:1 with full lossless recovery. A React dashboard ties both stages together, visualising the denoised image, extracted text, Huffman tree, compression metrics, and lossless verification all in real time.
How We Built It
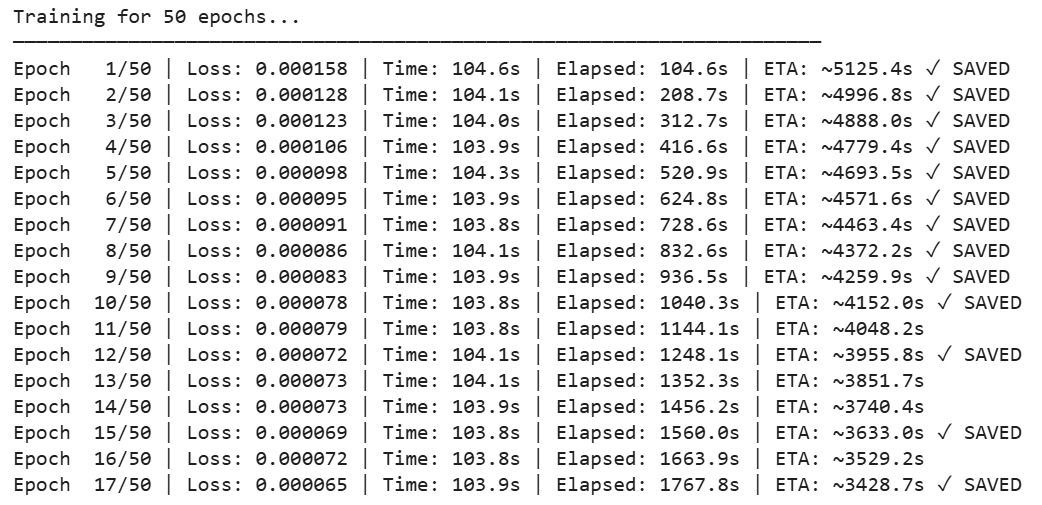
We built the system as three independent microservices. Stage one is a FastAPI service running a U-Net style denoising CNN trained in PyTorch encoder channels 32→64→128 with skip connections, BatchNorm, ReLU, and Sigmoid output trained with MSE loss and Adam optimizer on 256×256 patches. Stage two is a Flask service implementing the FGK Adaptive Huffman algorithm entirely from scratch in Python, with no compression libraries. An orchestrator FastAPI service coordinates the two stages, handles JWT authentication, persists every run to a SQLite database, and stores uploaded images to disk. The frontend is built in React 18, TypeScript, Vite, and Tailwind CSS, with a three-panel layout showing inputs, results, and metrics side by side.
Challenges
Getting the denoising CNN to generalise across four very different noise types Gaussian, salt-and-pepper, crumpled, and stained was the hardest part of training. Each noise type required its own classical preprocessing step before the CNN to give the model a head start. Implementing the FGK Adaptive Huffman algorithm correctly from scratch was also non-trivial the NYT sentinel node and sibling property rebalancing required careful debugging to ensure the decoder reconstructed the exact same tree in sync with the encoder. On the integration side, wiring the three services together reliably, handling schema changes without migrations, and getting the denoised image transported as base64 through the pipeline all introduced unexpected friction.
Accomplishments
We are proud of building a genuinely working end-to-end pipeline not a mock, not a demo with hardcoded data. Every run goes through real CNN inference, real OCR, and real compression. The Adaptive Huffman implementation is entirely hand-written and verifiably lossless. We also built a polished frontend that exposes the internals of the pipeline the Huffman tree, encoded bit string, symbol frequencies, and a live lossless verification step in a way that makes the algorithms visible and understandable, not just a black box.
What We Learned
We deepened our understanding of U-Net architecture design specifically why skip connections matter for preserving fine spatial detail, and how BatchNorm stabilises training across high-variance inputs. Implementing Adaptive Huffman from scratch gave us a hands-on understanding of how entropy coding works at the bit level. On the systems side, we learned how to coordinate multiple microservices cleanly, manage authentication and persistent storage across a full stack, and build a React UI that communicates real pipeline state rather than just displaying static results.
What's Next
The natural next step is extending the denoising CNN to handle more complex real-world degradations handwritten text, low-resolution scans, and mixed noise. We also want to replace Adaptive Huffman with arithmetic coding for higher compression efficiency on short strings. On the pipeline side, adding GPU inference support for stage one would bring latency down significantly. Longer term, we see this as the foundation for a document digitisation service processing batches of scanned documents automatically, with confidence thresholds triggering human review for low-quality reads.
Built With
- fastapi
- flask
- huffman
- pytorch
- react
- sqlite
- tailwind
- typescript
- u-net











Log in or sign up for Devpost to join the conversation.