-
-

Our primary features
-
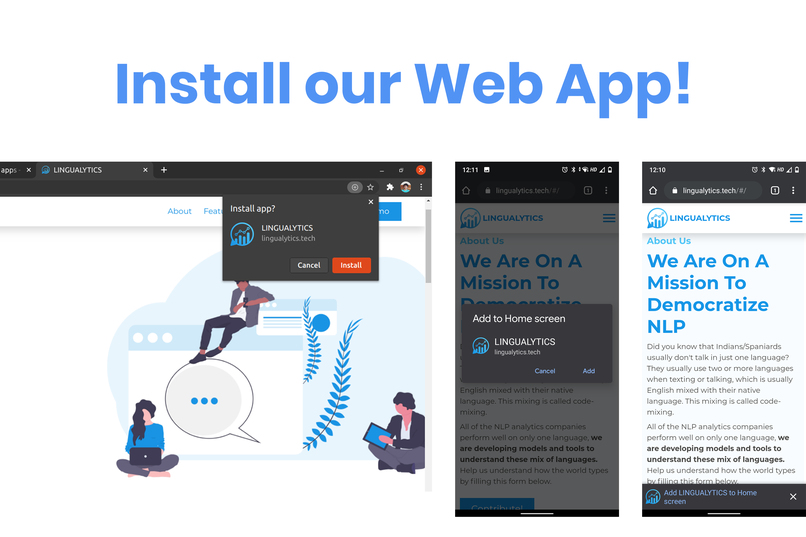
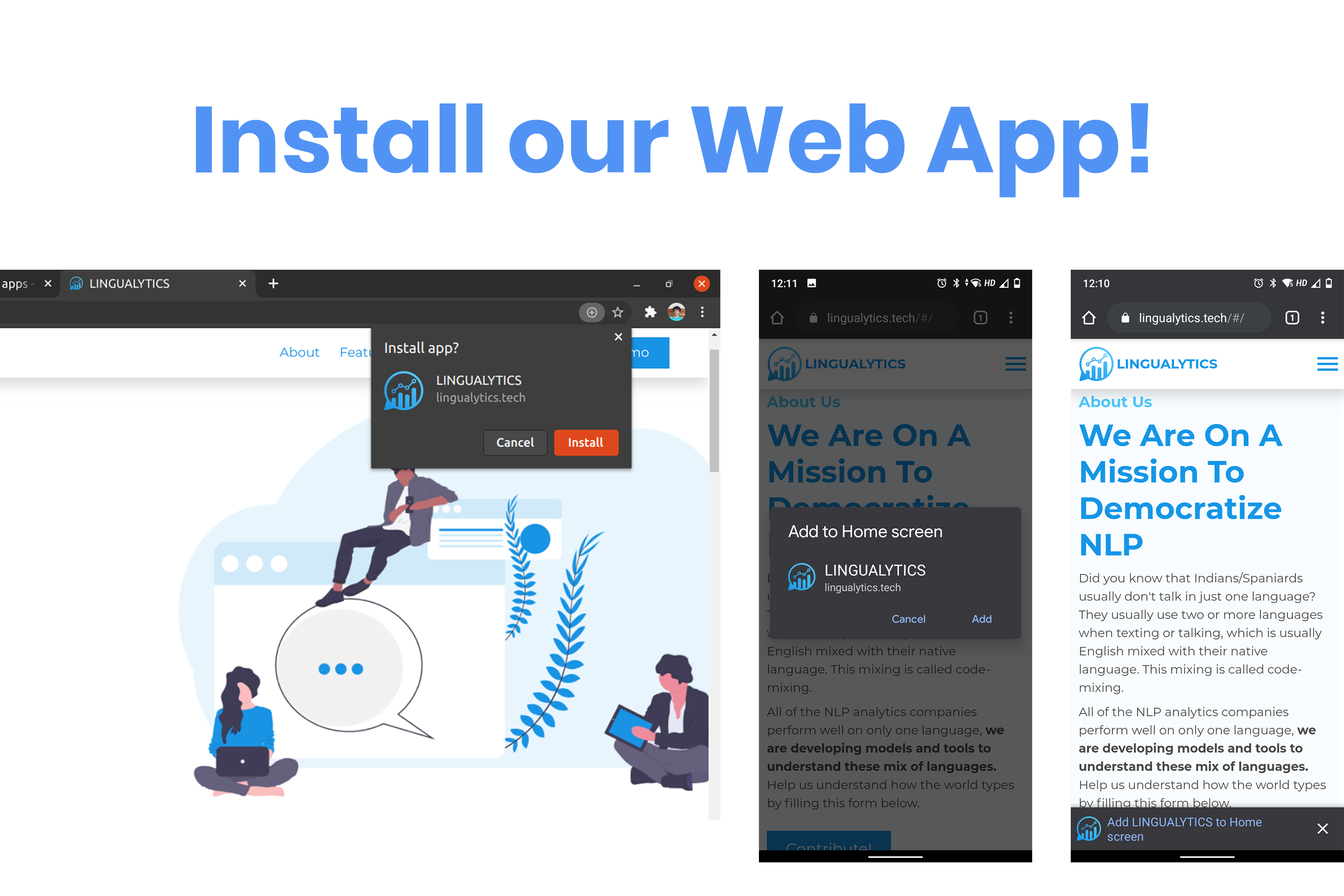
Our webite is also a Progressive Web App, check it out!
-
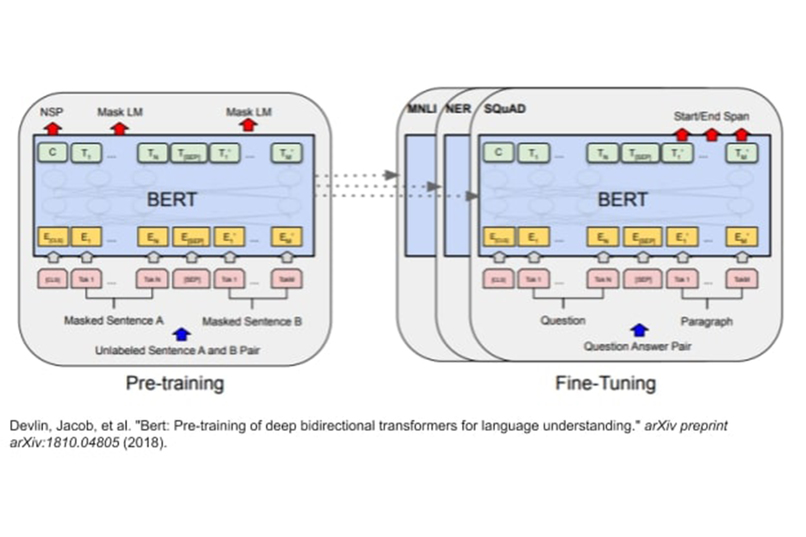
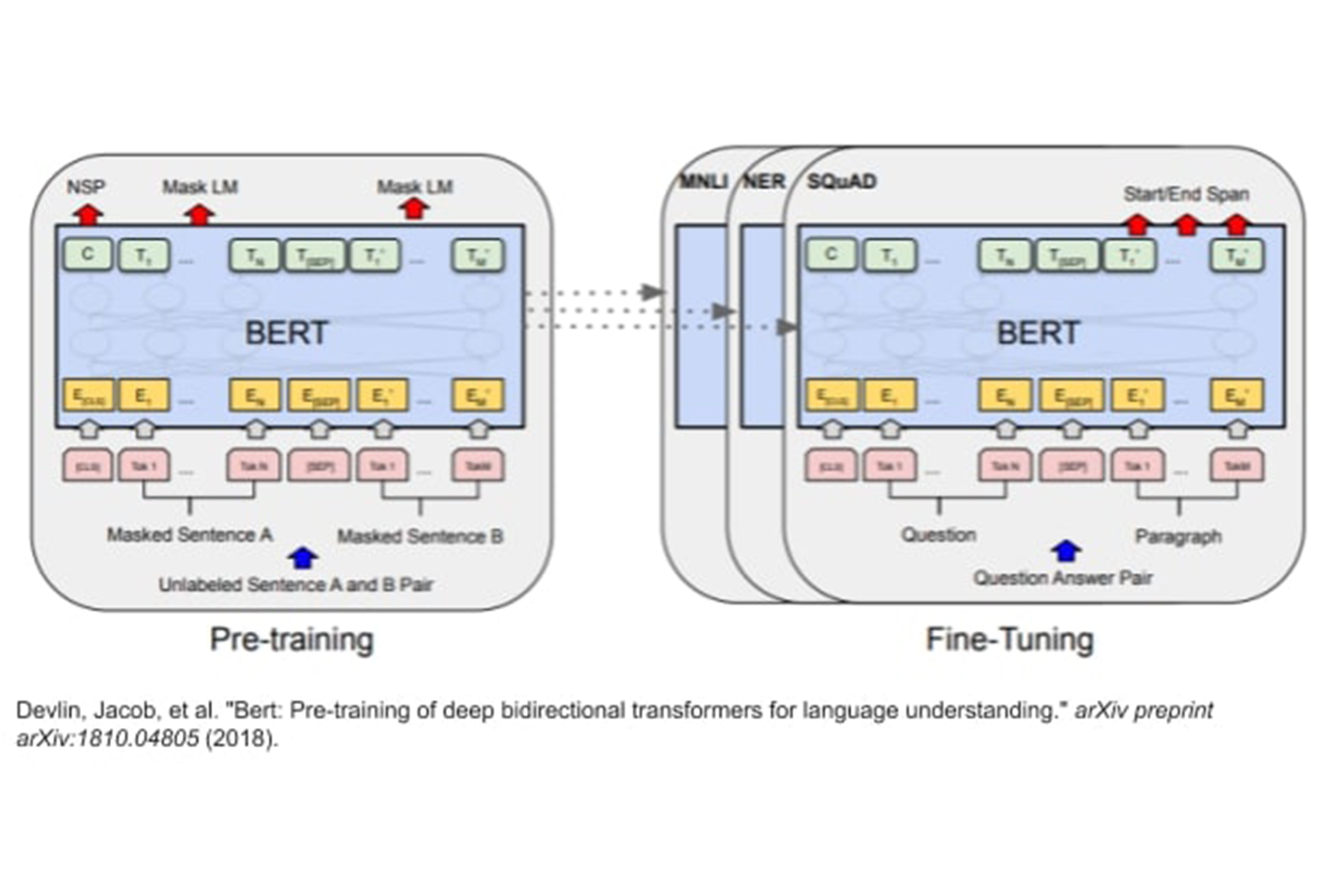
The model we are using to understand code-switched data
-
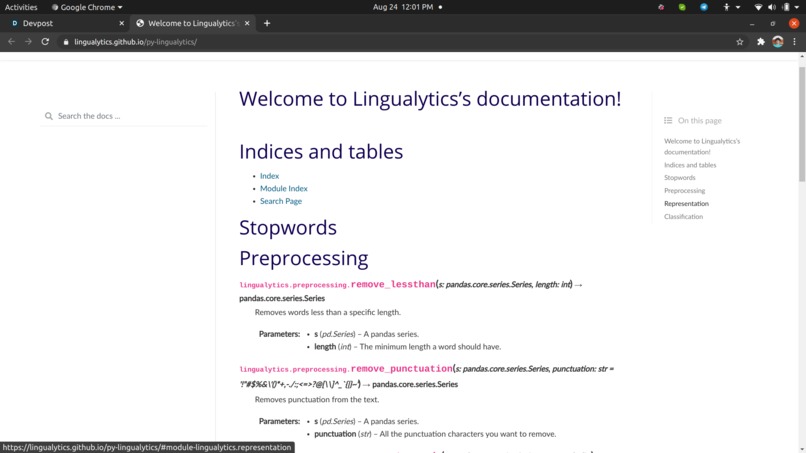
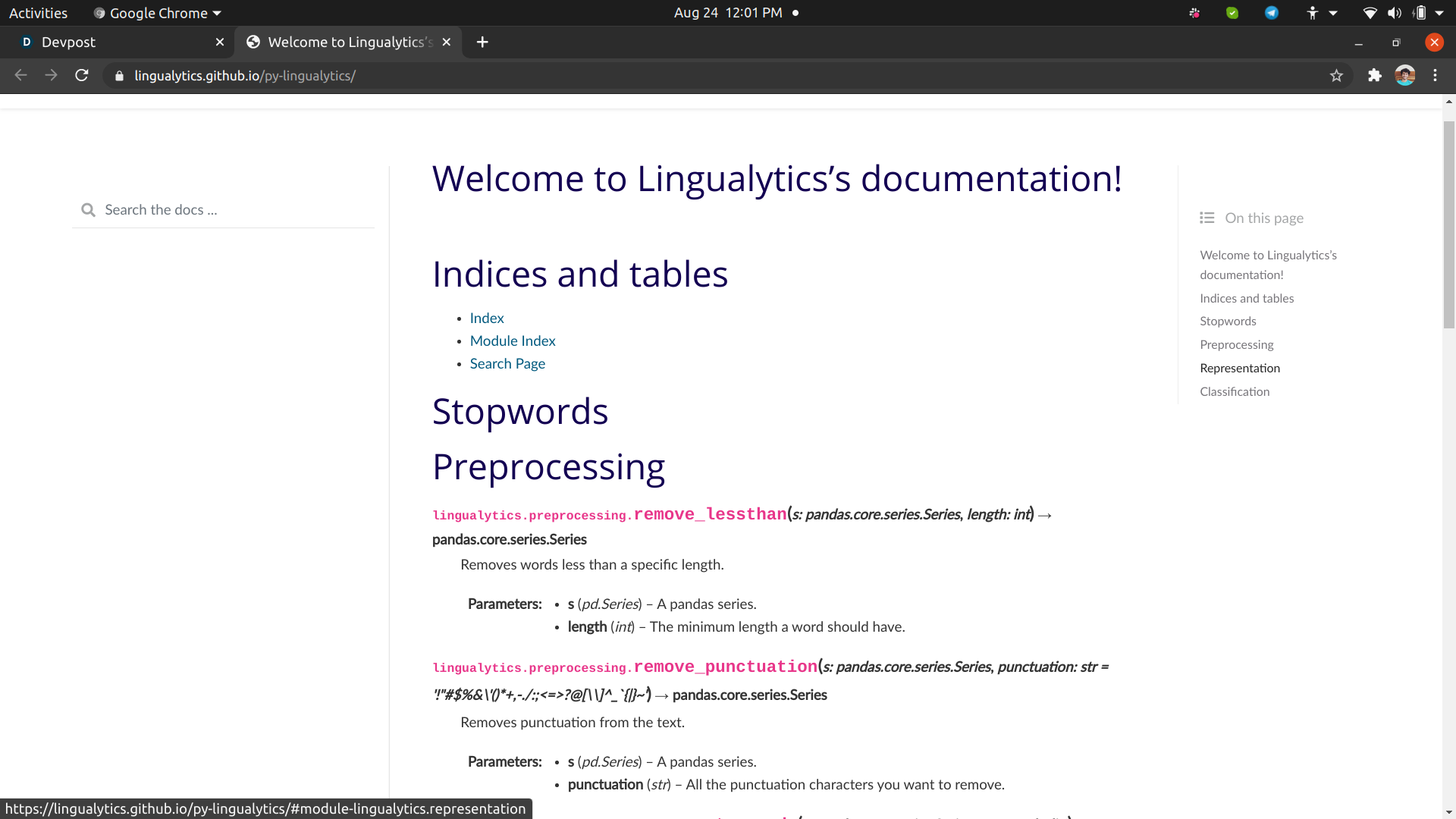
Our Python package also has a documentation. Checkout https://lingualytics.github.io/py-lingualytics/
-
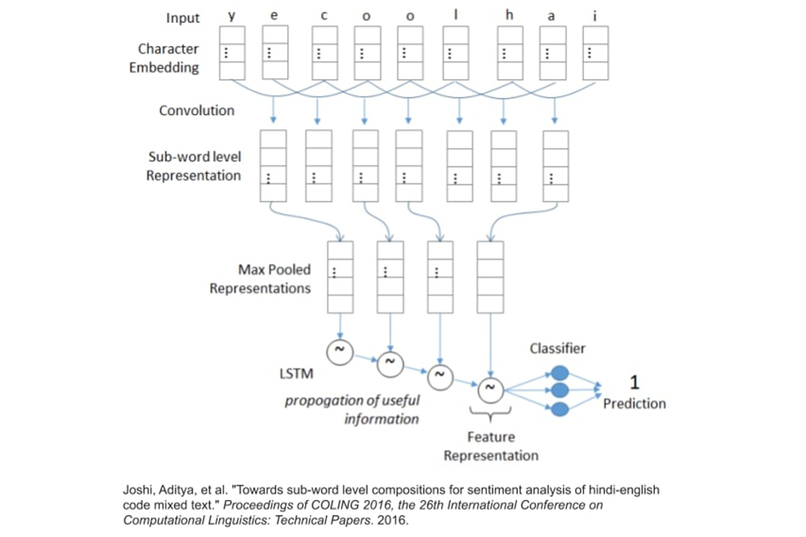
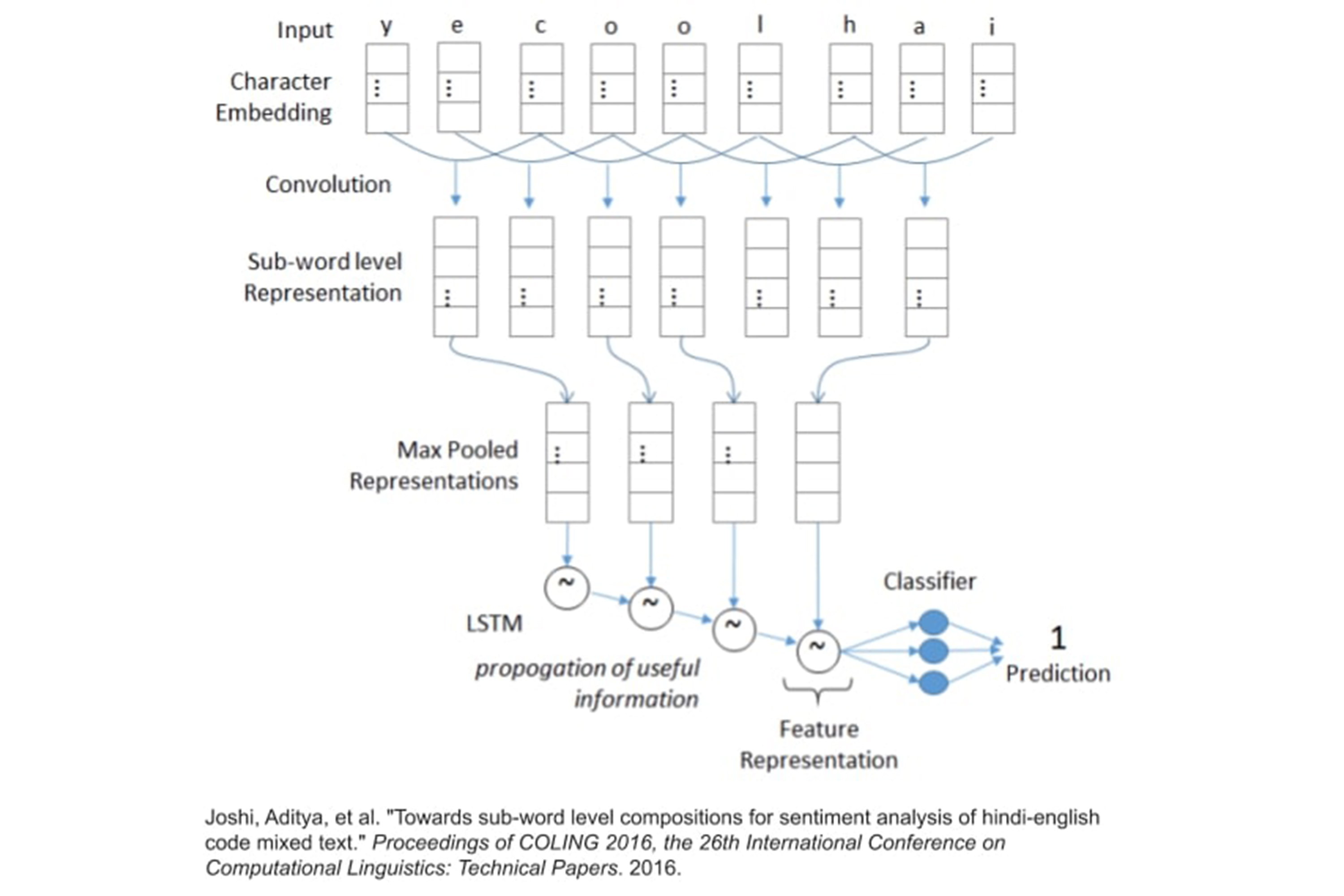
We tried to use other models than transformer like this one, but transformers outperformed them.

Inspiration
Spanish and Hindi are the 2nd and 4th most spoken languages in the world. However, most people in these countries communicate in a mix of languages, like English mixed with their native language. All of the current NLP models fail to understand such mixing. We have developed models and tools to solve this problem.
This mixing of languages is formally called code-switching.
What it does
Lingualytics, with the help of Pytorch, provides tools for both developers and businesses to process, analyze, and develop models for code switched data. For developers and data scientists, we have developed a python package, and we also have deployed a web app to test out our models.
Python package
The developer tool is a Python package. Py-Lingualytics helps you to
- Download code-switched datasets. Available datasets are
- CS-En-Es-Corpus Vilares, D. et al. 2015
- SAIL-2017 Dipankar Das., et al. 2017
- Sub-Word LSTM Joshi, Aditya, et al. 2016
- Preprocess data
- Removal of code-switched stopwords.
- Digit, punctuation and excessive whitespace removal
- Train any state of the art model for classification, using Pytorch
- You can use any model and tokenizer on Huggingface and train it on a dataset
- Represent text with the help of n-grams
If you're confused at any point. You can refer to the library's documentation.
To try Py-Lingualytics, you can install it with pip install lingualytics. You can also get started with the getting-started notebook ![]()
The library is available on PyPi. You can also find the source code on Github.
The Web App
- You can input text into the Progressive Web App, and it will show the sentiment of the input. It currently supports English, Hindi, and a mix of both as well.
To install the web app, open the website
- On the phone, you'll automatically see an option on the bottom to install the app.
- On Desktop, click on the
+on the right side of the address bar to add it.
Pretrained models
We also have uploaded pretrained models that can work with English-Hindi and English-Spanish data. Check them out here.
How we built it
The Model
We first had to figure out the right preprocessing techniques to interpret a code-switched text. We did some extensive research to find the right stopwords, punctuations, and tokenizers to get the right word embeddings.
The next step was to decide a model that could work with multiple languages simultaneously, and we finally went ahead with Multilingual Bert (Devlin, Jacob, et al. 2018) which is compatible with 104 languages. We then fine-tuned this model on English-Hindi and English-Spanish codemixed datasets. There is another approach of using Sub-Word LSTM (Joshi, Aditya, et al. 2018), but BERT outperformed that approach.

The Web App
We used React for the front end and Axios to build the API. Our CSS framework was bootstrap and we used Github Pages to deploy the website. We used the latest practices like using hooks in react and functional components and the ECMAScript 6 syntax. The source code of the website is available on Github.
The Python Library
We generalized each of the steps we used to make the model and developed a python library for downloading, preprocessing, training, and representation of code switched data.
Design of the library
The design of using Pytorch for training was majorly inspired by Fastai as they have a friendly API built on top of PyTorch. For the rest of the operations, the design was inspired by Texthero as we found it to be the easiest to use along with excellent documentation.
Documentation
We used Sphinx to convert the docstrings of each function into full documentation. We also have a getting-started notebook.
Pretrained Models
We used our own library to train models on English-Hindi and English-Spanish datasets and uploaded them on Huggingface for anyone to use.
Challenges we ran into
Even though Spanish and Hindi are the 2nd and 4th most spoken languages in the world, very few research on how people communicate in these languages. Therefore finding relevant literature to do code-switched NLP was not an easy task. PyTorch was helpful in this case as it's easy to customize the training procedure as per our needs.
We also couldn't find quality datasets or preprocessing techniques to work with English-Spanish or English-Hindi data. The existing NLP libraries didn't support code-switched data out of the box, and we ended up rewriting a lot of functions in those libraries.
Accomplishments that we're proud of
We're proud of
- Helping in democratizing NLP by developing the first library to work with code switched data.
- Develop the first web app where users can do sentiment analysis on code-switched data.
What I learned
We didn't have much knowledge about NLP but had a firm grip on Machine Learning and Deep Learning. We understood that NLP is an application of ML and developed an understanding of the following techniques
- Preprocessing: Stopwords, Tokenization, Stemming, Lemmatization
- Transformers and why are they currently the best models to work with text
We also learned how to develop a Python package to PyPi and how to document it using Sphinx.
What's next for Lingualytics
Add Spanish and Spanglish compatibility to our web app.
The next step is to collect quality code-switched data. We realized the publically available datasets were not enough and richer datasets have to be collected.
We also plan to add support for additional NLP tasks like:
- Language Identification (LID)
- POS Tagging (POS)
- Named Entity Recognition (NER)
- Sentiment Analysis (SA)
- Question Answering (QA)
- Natural Language Inference (NLI)
Built With
- bootstrap
- gh-pages
- github
- hugggingface
- nltk
- photoshop
- python
- python-package-index
- pytorch
- react
- react-native
- sass
- sphinx
- texthero
- torch
- transformers







Log in or sign up for Devpost to join the conversation.