-
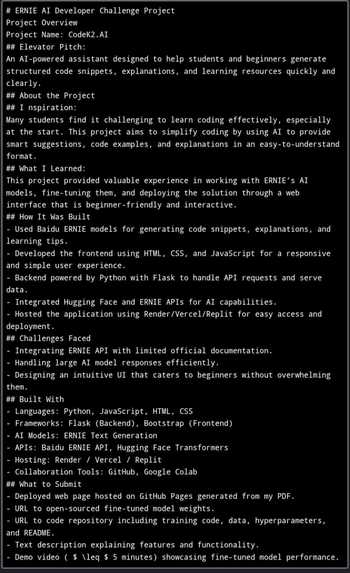
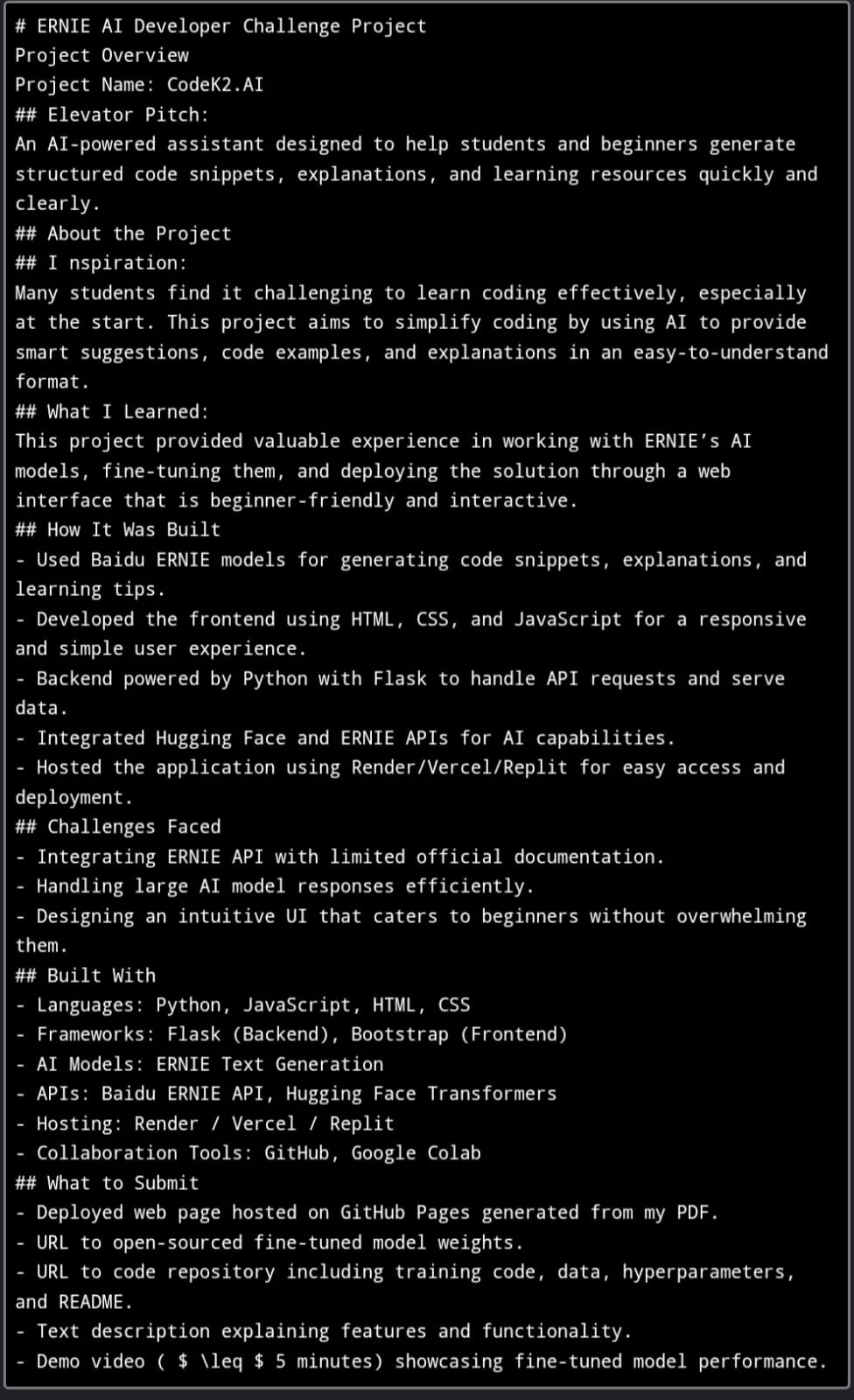
Markdown-formatted project overview for the ERNIE AI, showcasing the inspiration, learning outcomes and deployment of the Codek2.AI web app
-
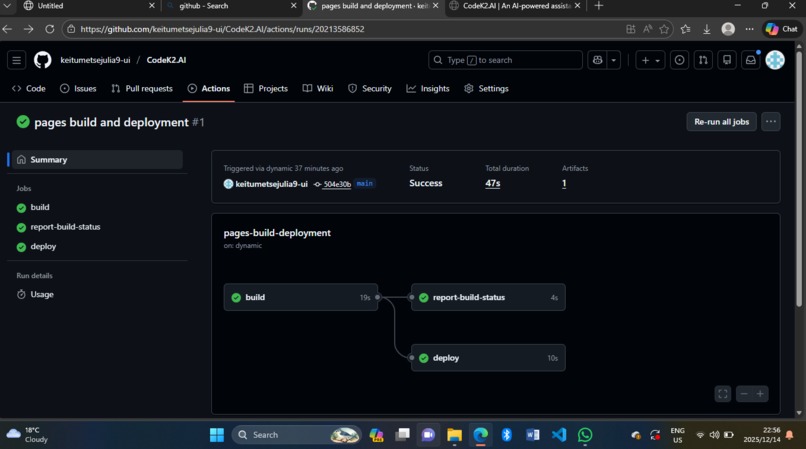
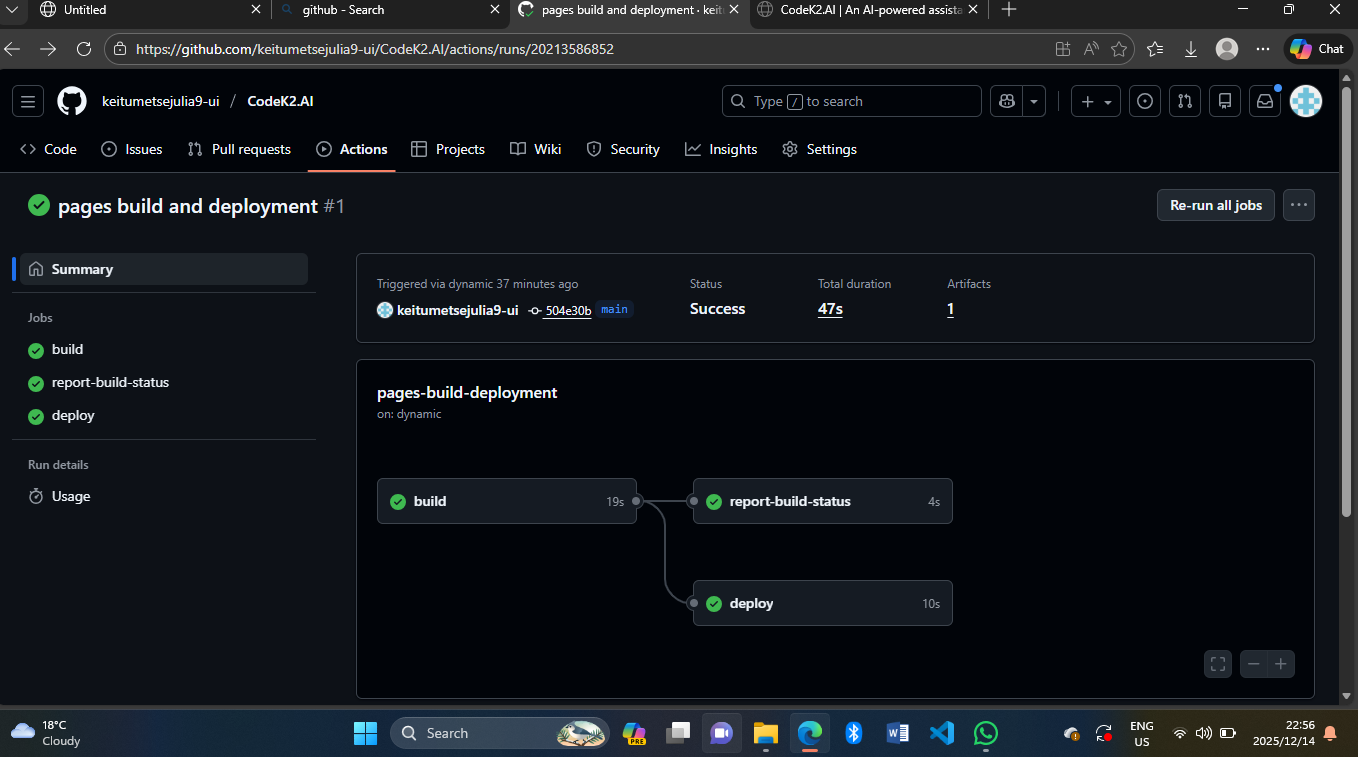
The GitHub Actions workflow for "pages build and deployment" ran smoothly with all jobs—*build*, *report-build-status*, and *deploy*
🌟 Inspiration
The idea behind this project was sparked by the challenge of turning static PDF documents into live, usable web content. I was inspired by the power of AI tools like "PaddleOCR" and "ERNIE" and how they can automate tedious tasks like extracting and presenting information in a clean format.
🛠️ What I Learned
Through this project, I learned how to:
- Use "PaddleOCR-VL" to extract both text and layout from a PDF document.
- Convert extracted content into "Markdown" format.
- Use "ERNIE" to generate a basic webpage based on that content.
- Deploy a website using 'GitHub Pages'.
🧱 How I Built It
I followed these main steps:
- Chose a sample PDF file.
- Ran 'PaddleOCR-VL' to extract its content and layout structure.
- Converted that into Markdown format.
- Used the 'ERNIE model' to build a simple web page from the Markdown.
- Published the final page using 'GitHub Pages'.
⚠️ Challenges Faced
- Understanding how to properly format the extracted layout in Markdown.
- Getting GitHub Pages to deploy correctly.
- Handling PDF files with complex formatting or images.

Log in or sign up for Devpost to join the conversation.