💡 Inspiration
In an era dominated by generative AI and hyper-scaled data centers, software engineering is facing an invisible crisis: carbon emissions. A single inefficient loop executed millions of times across edge devices or cloud clusters wastes tangible electrical energy and generates measurable $CO_2$.
While industries are moving towards sustainability, developers lack intuitive tools to measure the environmental impact of their code. We were inspired to bridge the gap between "clean code" and "clean energy." CodeGreen was born out of the desire to gamify sustainable computing—turning abstract Big-$\mathcal{O}$ complexity into visceral, real-world metrics like saved CPU cycles and trees planted. We wanted developers to feel proud not just of their code's performance, but of its environmental footprint.
🚀 What it does
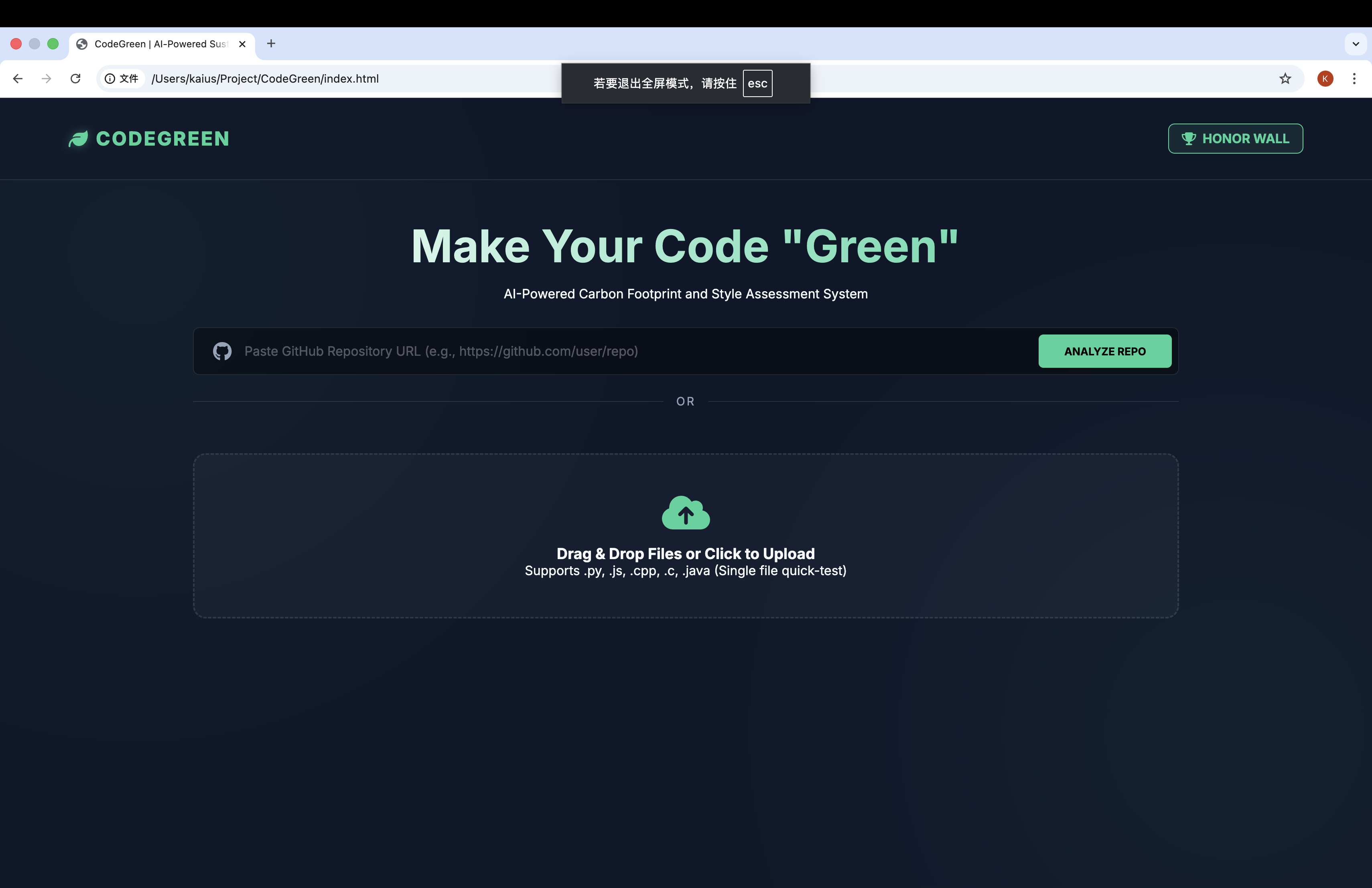
CodeGreen is a full-stack, AI-powered platform designed to audit, optimize, and gamify code sustainability.
- Eco-Auditing: Users can upload local source files or simply paste a GitHub repository URL to trigger a deep scan.
- Dual-Score System: Each project is evaluated on two axes: Eco-Efficiency (computational waste) and Coding Style (readability and best practices).
- Green Refactoring: Using Gemini 1.5 Pro’s long-context capabilities, CodeGreen provides side-by-side comparisons, automatically generating "Green Optimized" versions of inefficient functions.
- Impact Quantization: It translates abstract algorithmic improvements into human-readable metrics, such as "Estimated Carbon Saved" and "Tree-Equivalent Impact."
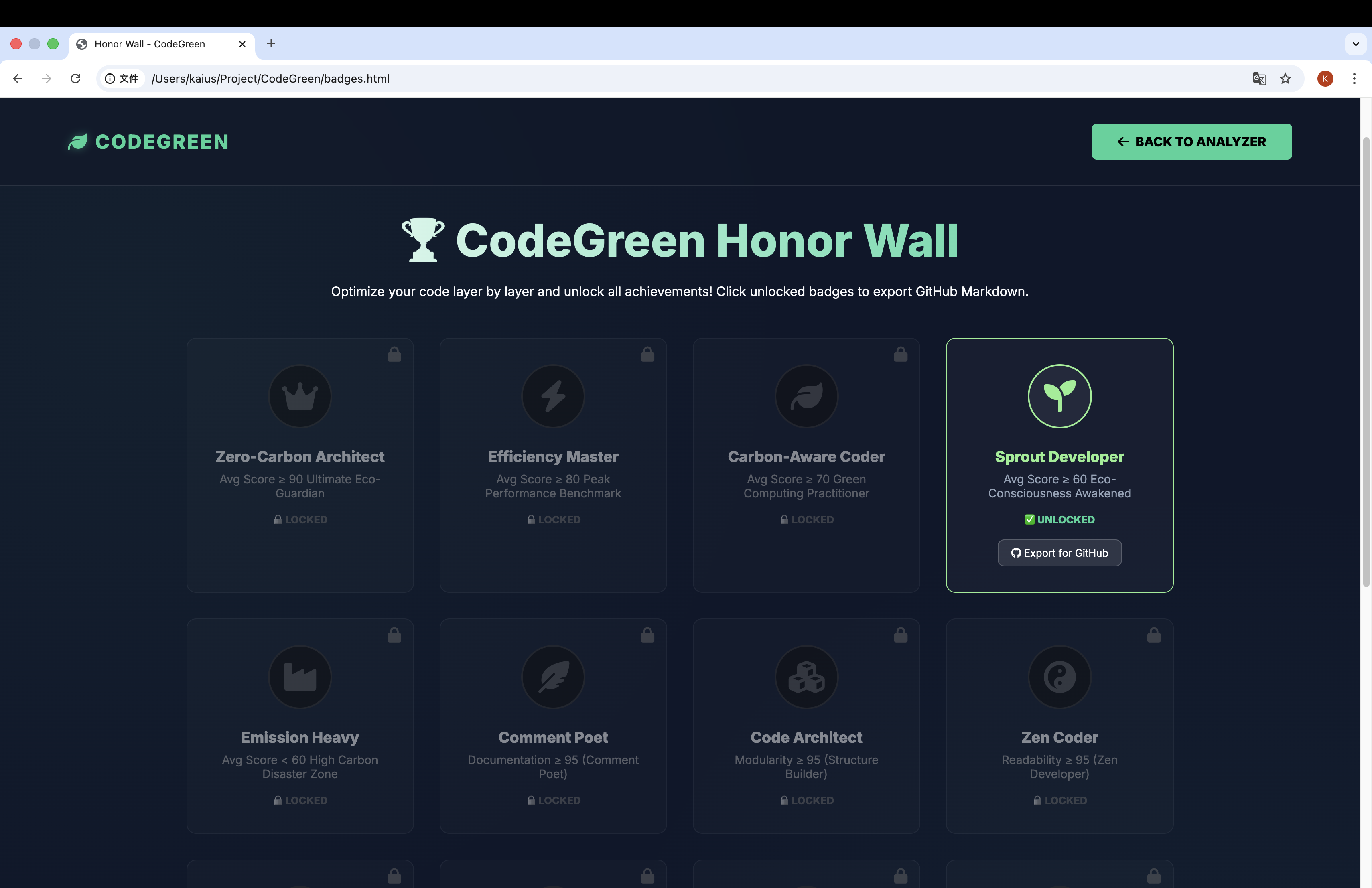
- Shareable Badges: Developers can generate dynamic GitHub Markdown badges (e.g., "Zero-Carbon Architect 👑") to showcase their commitment to green coding on their profiles.
⚙️ How I built it
We built CodeGreen as a robust AI-driven pipeline within the Google Cloud ecosystem:
- The Brain (AI Engine): We integrated Gemini 1.5 Pro via the Vertex AI Python SDK. Through precise prompt engineering, we forced the model to act as a deterministic "Green Computing" evaluator, outputting structured JSON data rather than conversational text.
- The Backend (FastAPI): Our Python-based backend serves as the orchestration layer. We implemented a Map-Reduce strategy using
asyncioto concurrently fetch, triage, and analyze the most logic-dense files in a repository. - The Math: To ground AI insights into physical reality, we developed a deterministic heuristic: $$E_{saved} = N_{lines} \times C_{base} \times \left( \frac{P_{cpu}}{100} \right)$$ Where $E_{saved}$ is the total carbon emissions saved (in grams), $C_{base}$ is a heuristic baseline representing energy overhead per million runs, and $P_{cpu}$ is the percentage of CPU cycles optimized.
- The Frontend: A sleek, cyberpunk-inspired UI built with React and Vite. We utilized Chart.js to render multi-dimensional radar charts for a visual "before-and-after" comparison of code health.
🧗 Challenges I ran into
- Taming LLM Hallucinations: Initially, Gemini would provide conflicting scores. We solved this by removing the AI's ability to dictate top-level scores, instead forcing it to provide specific technical sub-metrics which our backend then processes through deterministic arithmetic.
- The "Carbon Mirage": Measuring physical energy from static text is notoriously difficult. We had to move away from "guessing" Joules to a heuristic model based on Instruction Complexity and Cloud Energy Intensity to ensure our metrics remained scientifically grounded.
- GitHub Scalability: Processing an entire repository can hit API limits. We engineered an asynchronous triage system that ranks files by "logic density," ensuring we analyze the most impactful code within seconds.
🏆 Accomplishments that I'm proud of
- Deterministic Reliability: Creating a system where the AI provides the "why" while our math provides the "how much," resulting in consistent, trustworthy scoring.
- Design-Driven UX: Successfully merging high-level technical analysis with a gamified experience that makes "carbon auditing" feel like gaining game achievements.
- The Map-Reduce Pipeline: Successfully implementing an asynchronous system that reduced repository processing time by over 80%.
🎓 What I learned
- Prompt Engineering is Software Architecture: High-quality AI output is less about the "ask" and more about the constraints. Forcing strict JSON schemas is essential for building production-ready AI tools.
- Asynchronous Processing: Working with
asyncioandsubprocesstaught me how to manage non-blocking I/O in high-concurrency environments like cloning large repos. - Sustainability is Measurable: I deepened my understanding of how algorithmic complexity ($O(n \log n)$ vs $O(n^2)$) translates directly into physical heat and carbon in data centers.
🏁 What's next for CodeGreen
- CI/CD Pipeline Integration: We plan to package CodeGreen as a GitHub Action, automatically blocking pull requests that significantly increase a repository's carbon footprint.
- True Sandbox Execution: Transitioning from heuristic math to running code in isolated Docker environments to measure actual CPU instructions and memory spikes.
- Global Eco-Leaderboard: Upgrading our local storage to a centralized database to create a global ranking of the "Greenest Open Source Repositories."

Log in or sign up for Devpost to join the conversation.