-
-
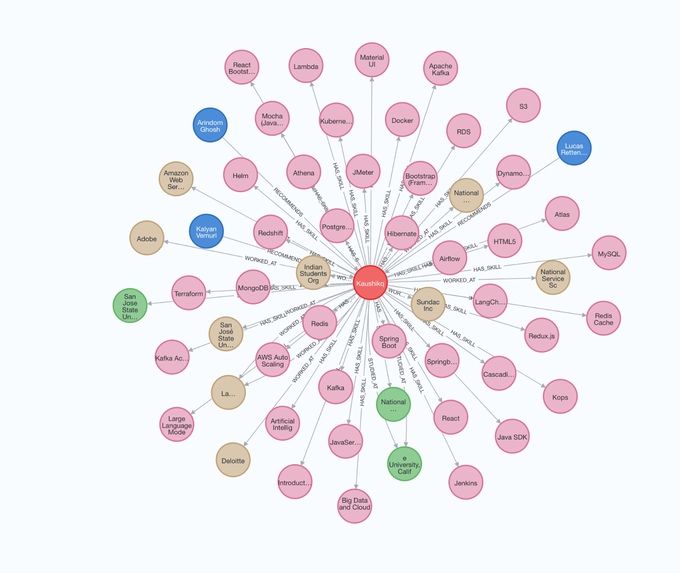
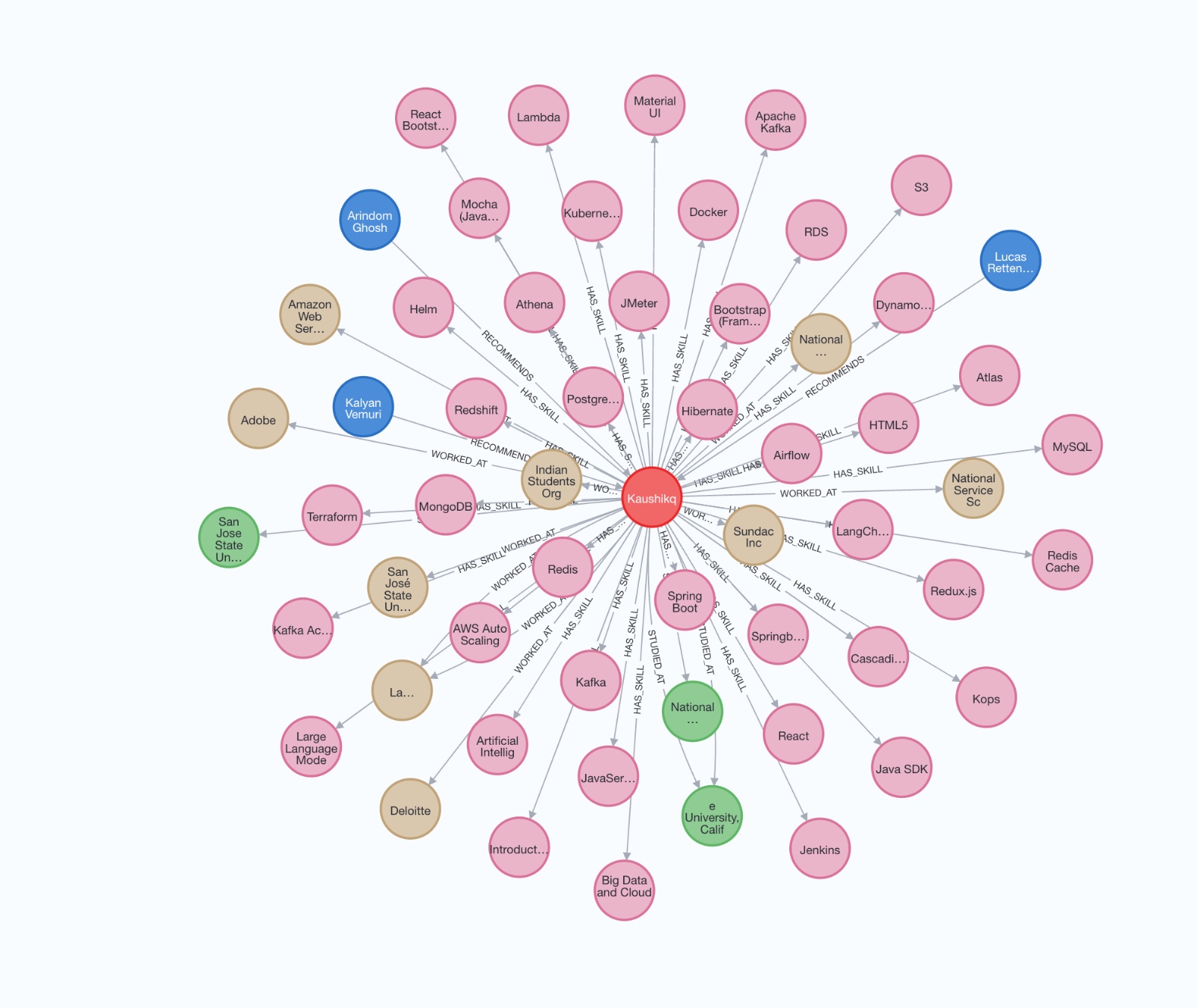
Knowledge Graph
-
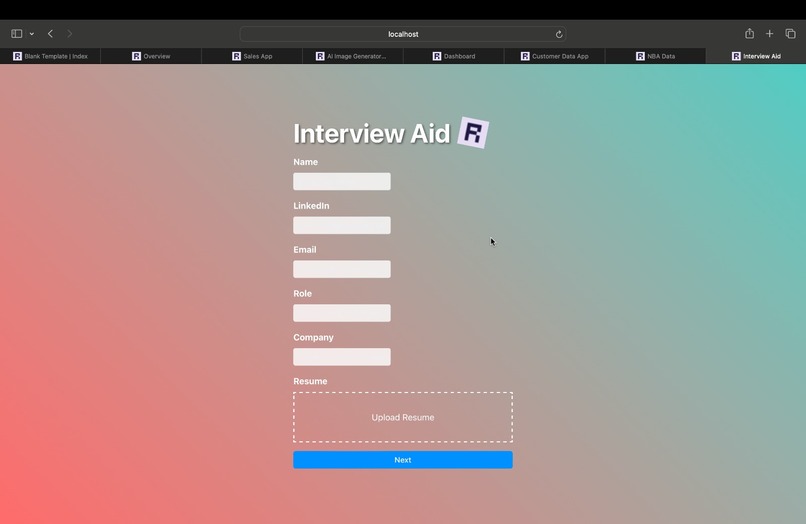
Landing Page
-
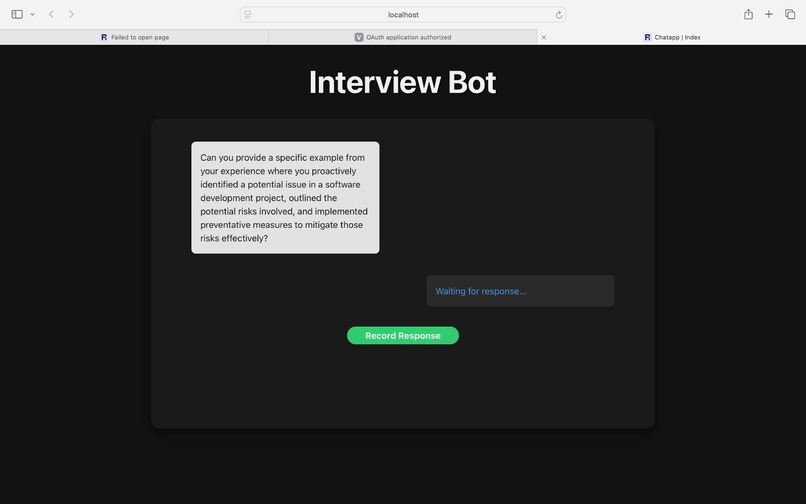
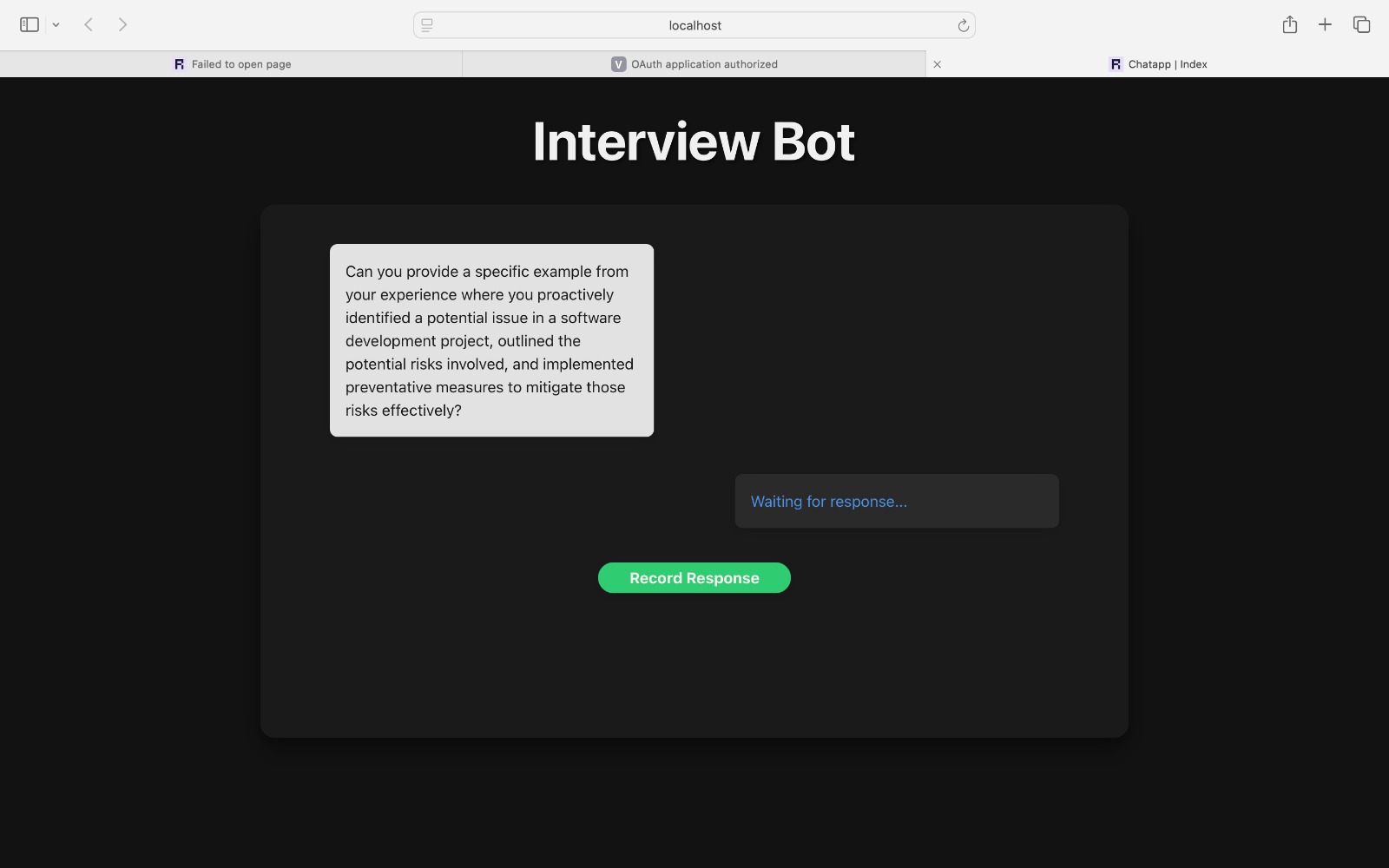
Speech To Text and Text To Speech - AI Interview
-
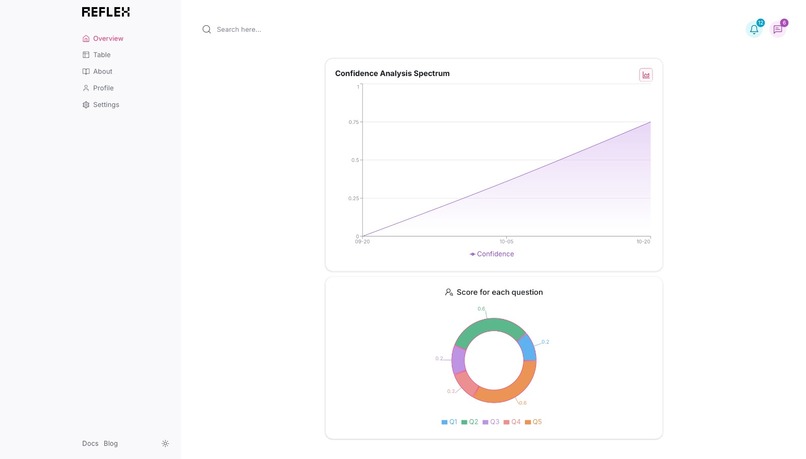
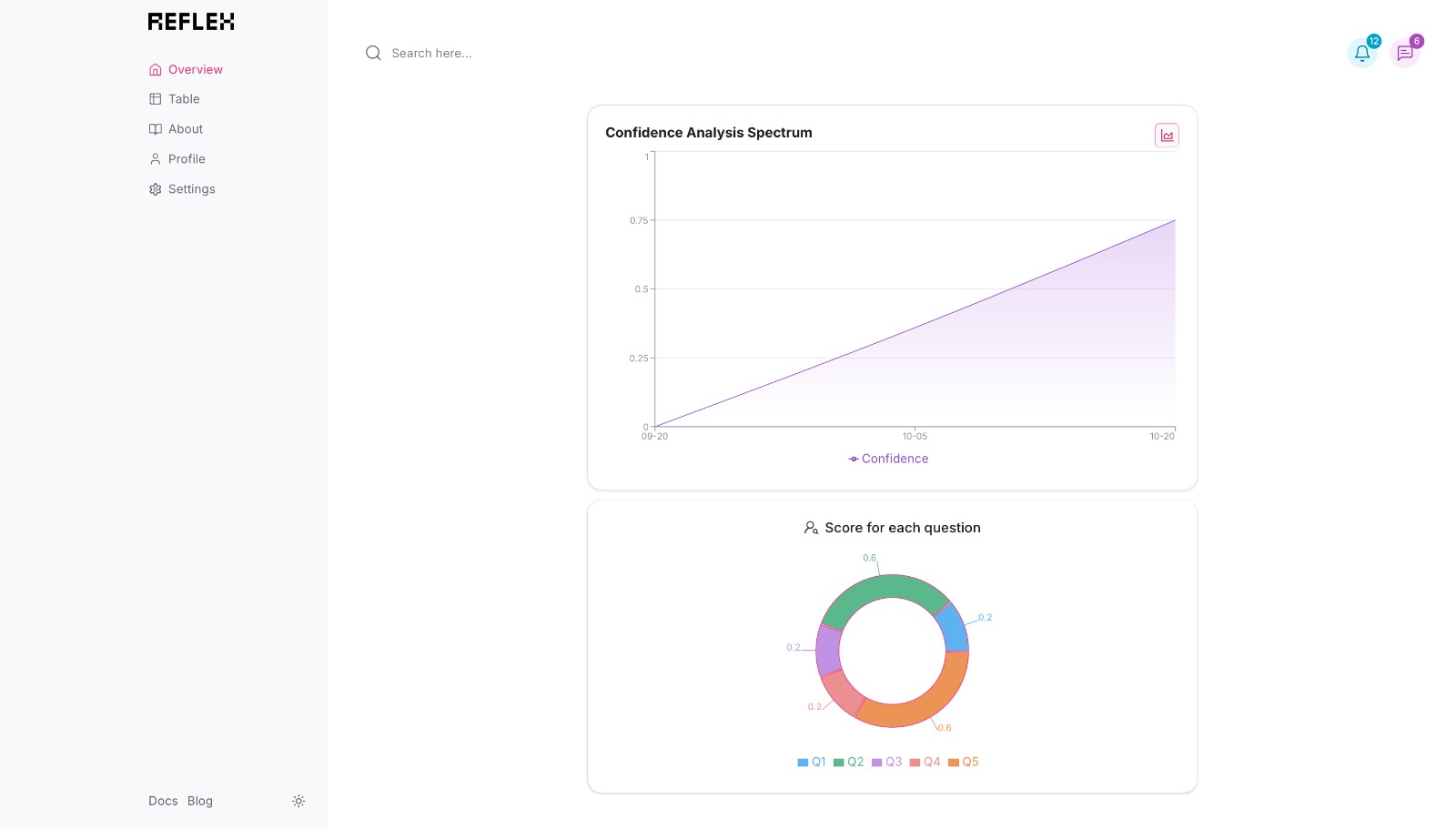
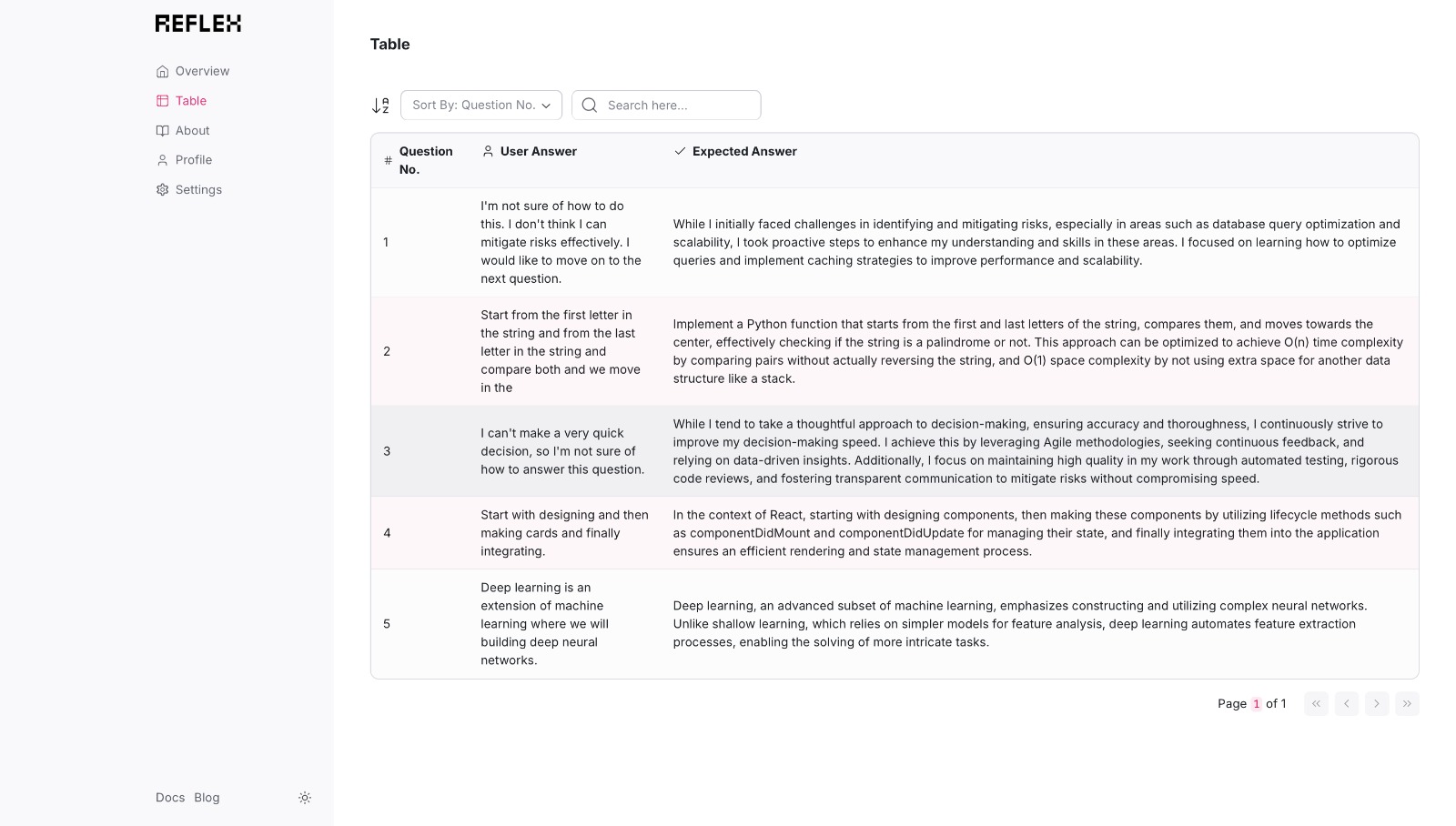
Statistics on User Confidence and Progress Tracking
-
Suggestions on how the User can improve his answers
-
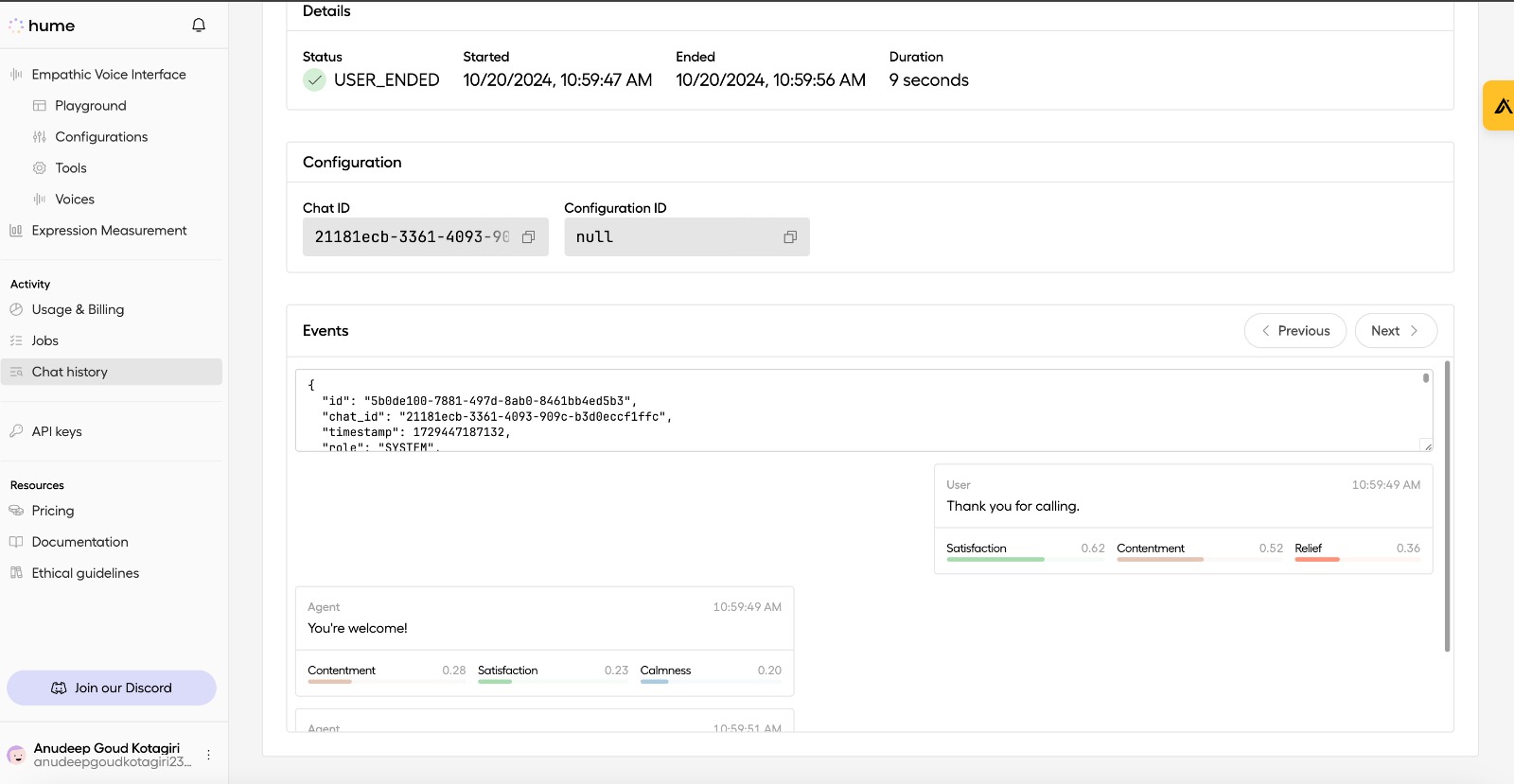
Hume AI portal
-
-
Inspiration
The post-COVID era has seen a significant rise in underconfidence among job seekers. According to a recent study by the Society for Human Resource Management, 61% of unemployed job seekers reported feeling less confident about their skills and employability compared to pre-pandemic levels. This lack of confidence is particularly pronounced in the tech industry, where rapid advancements and increased competition have created a challenging landscape for job seekers.
With the tech job market becoming increasingly competitive – LinkedIn reports a 98% year-over-year increase in tech job applications in 2023 – it's more essential than ever for candidates to present themselves confidently and effectively during interviews.
This realization inspired us to create CodeConfident, a platform designed to boost confidence and preparedness for tech interviews. By leveraging AI to scrape and analyze a user's public data and skills, our system generates personalized, AI-driven mock interviews that closely mimic real-world scenarios. This allows users to practice in a low-stakes environment while receiving tailored feedback and guidance.
With CodeConfident, we aim to level the playing field and empower job seekers to showcase their true potential, ultimately helping to bridge the gap between talent and opportunity in the ever-evolving tech industry.
What it does
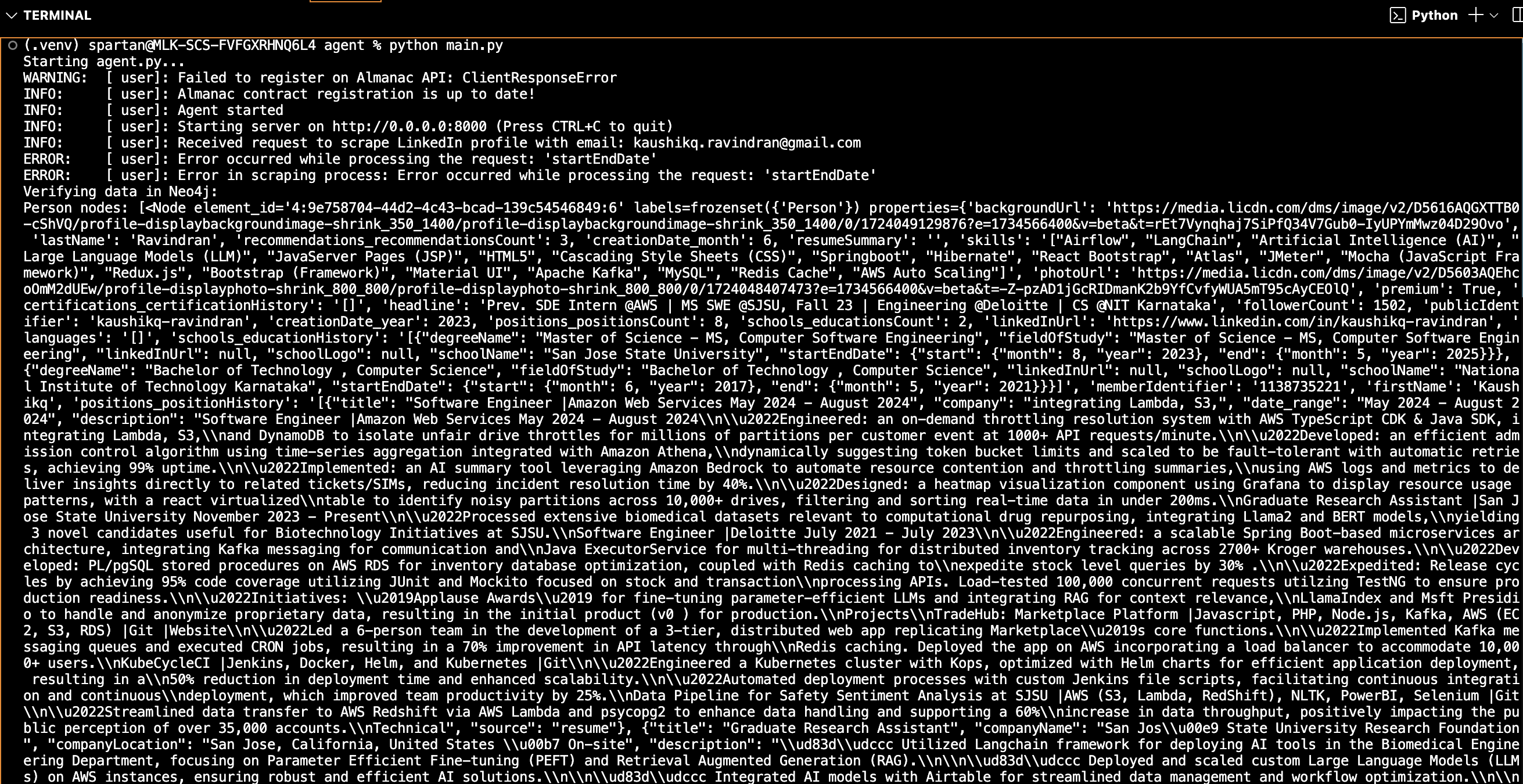
Our platform begins by gathering crucial information: the company name, the specific role the user is applying for, their resume, and LinkedIn email. This data serves as the foundation for a tailored interview simulation. CodeConfident then performs real-time scraping of the user's public professional data and transforms their resume into a knowledge graph. This process allows our AI to gain a deep understanding of the user's technical experience and skillset.
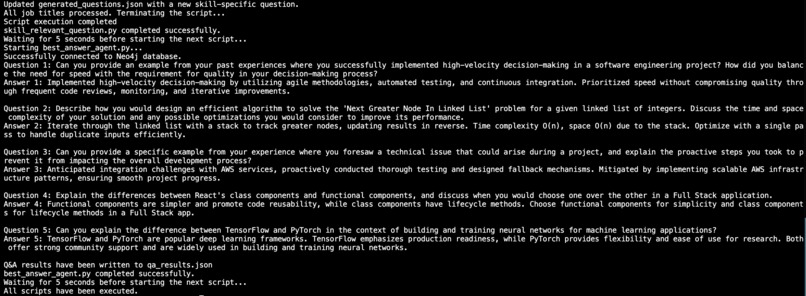
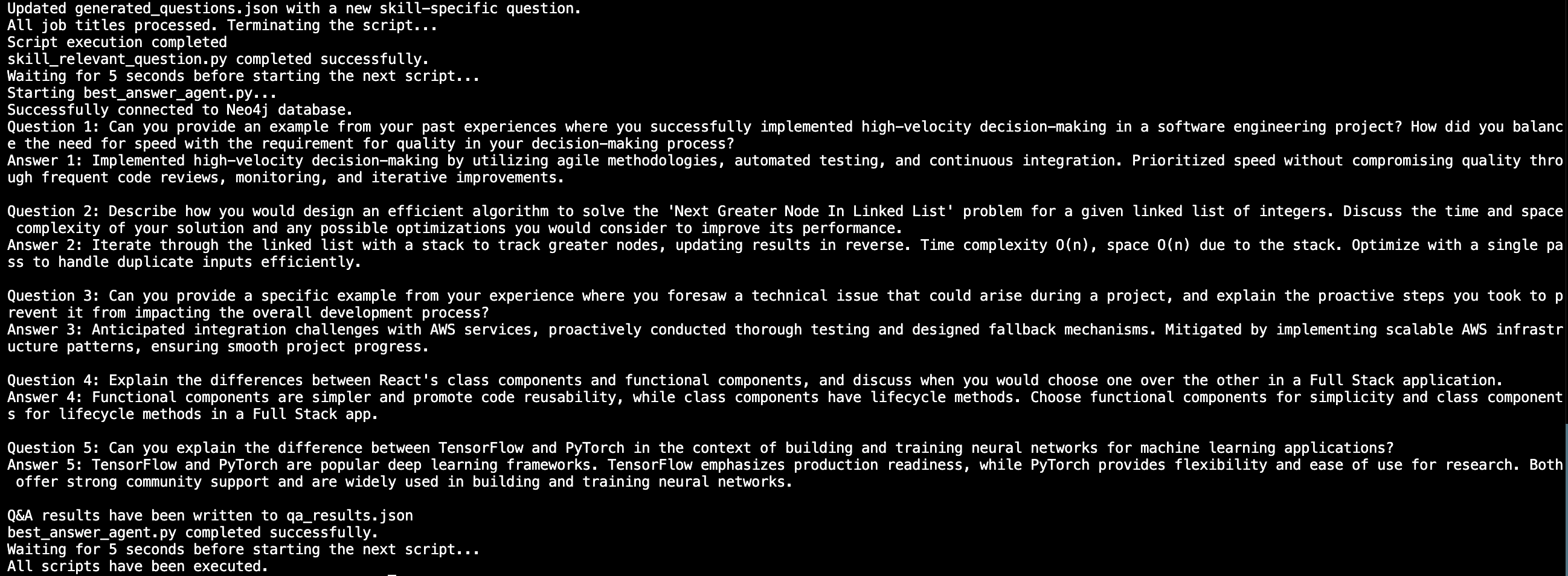
Simultaneously, CodeConfident taps into a vast knowledge base stored in a vector database. This database contains information on companies' most frequently asked interview questions, including technical problems, behavioral questions, and cultural fit assessments. By mapping this data to the user's profile, our AI creates a realistic and relevant interview scenario.
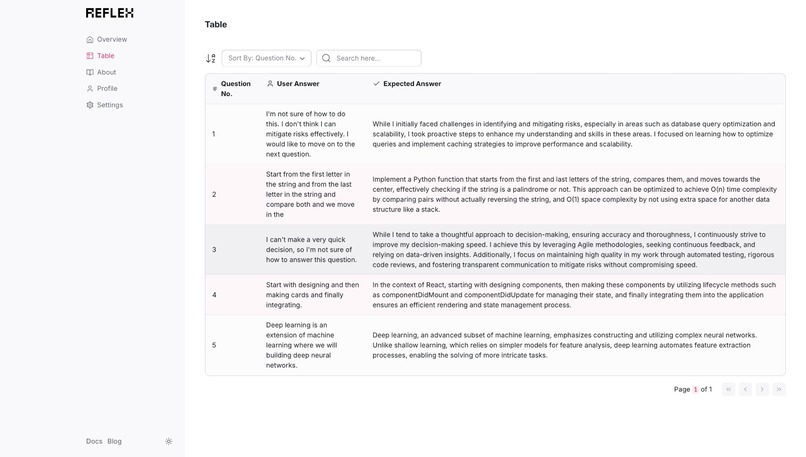
During the simulated interview, CodeConfident presents a series of questions tailored to the user's background and the target company's requirements. As users respond, the AI records their voice and analyzes their answers. Each response is then compared to an optimal answer derived from the knowledge graph and vector store. This comparison generates a confidence score based on three key factors: tonality, brevity, and technical depth.
After the interview simulation, users receive a comprehensive report detailing their performance. This report highlights areas where they demonstrated confidence and expertise, as well as suggesting improvements for responses that fell short. Users can see how comfortable they are with various aspects of their skills and receive actionable advice on enhancing their interview performance. CodeConfident doesn't just stop at providing feedback. It offers users the opportunity to practice repeatedly, tracking their progress over time. This iterative process allows candidates to refine their responses, build confidence, and ultimately present the best version of themselves during actual interviews.
How we built it
We built the web application using Reflex, a Python-based framework that seamlessly integrates frontend and backend development, allowing for efficient use of frontend components. The website design was crafted using Figma, ensuring a user-friendly and visually appealing interface.
For data management and processing, we employed a multi-faceted approach. Neo4j was utilized for creating and managing knowledge graphs, providing a robust foundation for complex data relationships. We implemented Fetch AI for RAG (Retrieval-Augmented Generation) agentic workflows, orchestrating more than five agents working in concert to gather and process data efficiently.
To handle the vast database of repeated questions for the top 50 companies in the US, we integrated ChromaDB as our vector store. This choice allowed for quick and efficient retrieval of relevant information, enhancing the overall performance of our question-answering system.
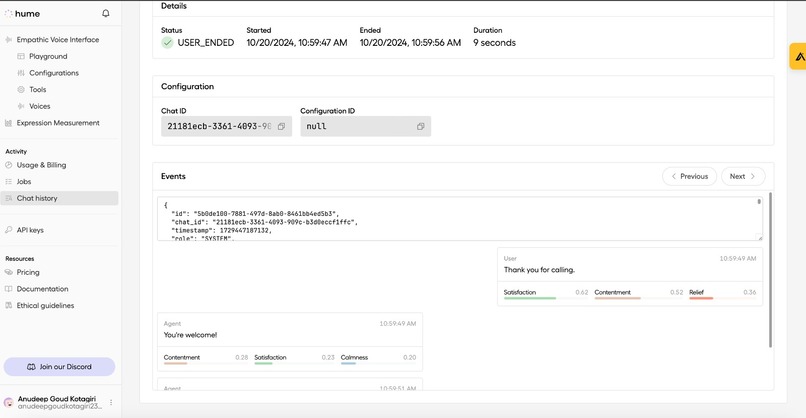
For audio processing and speech-to-text conversion, we leveraged OpenAI's Whisper model, enabling accurate transcription and facilitating seamless conversation interfaces. To add an extra layer of insight to our application, we incorporated Hume for emotion analysis, providing valuable emotional context to user interactions.
Challenges we ran into
Integrating Multiple Technologies: One of our primary challenges was integrating the diverse range of technologies we employed. Combining Reflex, Neo4j, Fetch AI, ChromaDB, OpenAI's Whisper, and Hume into a cohesive system required careful planning and execution. Ensuring that these technologies worked seamlessly together while maintaining optimal performance was a complex task that demanded significant effort and problem-solving.
Knowledge Graph Implementation: Utilizing Neo4j for our knowledge graphs presented challenges in terms of data modeling and query optimization. Designing an effective graph structure that could accurately represent complex relationships while allowing for efficient querying was a significant hurdle we had to overcome.
Accomplishments that we're proud of
Implementing RAG Agentic Workflows with Fetch.AI: Developing and coordinating more than five agents for our Retrieval-Augmented Generation (RAG) workflows using Fetch AI presented a unique challenge. Ensuring that these agents could effectively gather and process data while working in harmony required intricate programming and extensive testing.
Frontend-Backend Integration with Reflex: While Reflex provided a seamless way to integrate frontend and backend development, adapting to its Python-based approach for frontend components required a shift in our development paradigm. Ensuring that all team members were proficient in this framework and could effectively leverage its capabilities was a learning curve we had to navigate.
What we learned
Integration of Reflex, Neo4j, Fetch AI, ChromaDB, OpenAI's Whisper, and Hume.
Gained expertise in implementing RAG workflows and managing large-scale data with vector stores.
What's next for CodeConfident
Enhance emotion analysis capabilities and expand the knowledge graph for more comprehensive insights.
Implement advanced NLP techniques to improve question-answering accuracy and personalize user experiences.


Log in or sign up for Devpost to join the conversation.