## Inspiration
Every engineering team has the same silent tax: the week a new developer disappears into a codebase, reading files, tracing imports, and interrupting senior engineers with "where should I even start?" The onboarding problem isn't a lack of documentation — it's that the knowledge lives inside the graph of relationships between code, people, and history, and there's no easy way to surface it.
When I saw that GitLab Orbit indexes the entire SDLC — projects, files, modules, merge requests, pipelines, and ownership — into a queryable knowledge graph, the idea was immediate: what if you could turn that graph into a personalized onboarding guide in minutes?
## What It Does
Codebase Onboarding Agent takes a GitLab group or project path and produces a complete onboarding package grounded entirely in Orbit's Knowledge Graph:
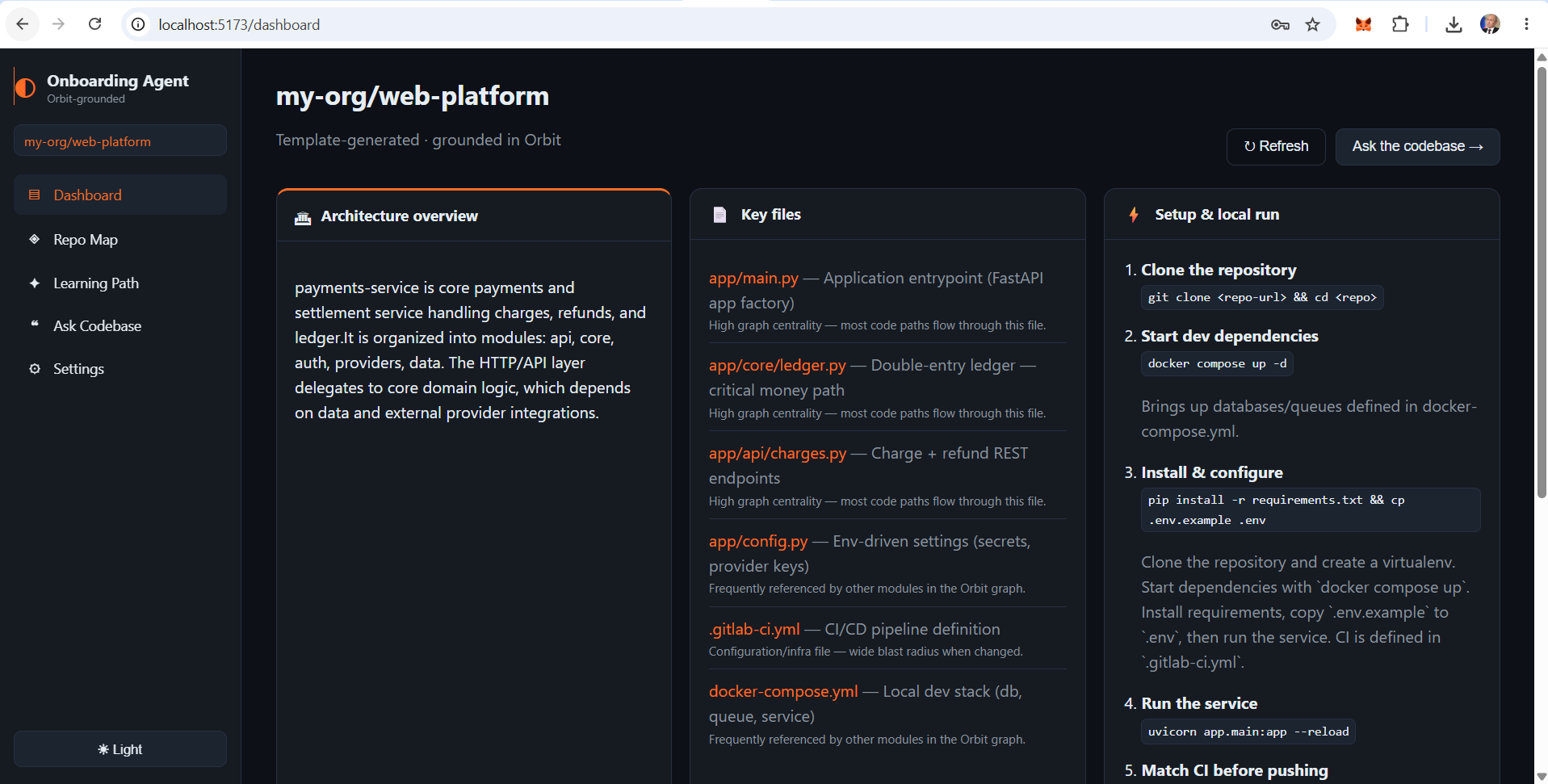
- Architecture overview — plain-English description of what the system does and how it's organized
- Key files — the most central files in the graph, each with its role and a direct GitLab source link
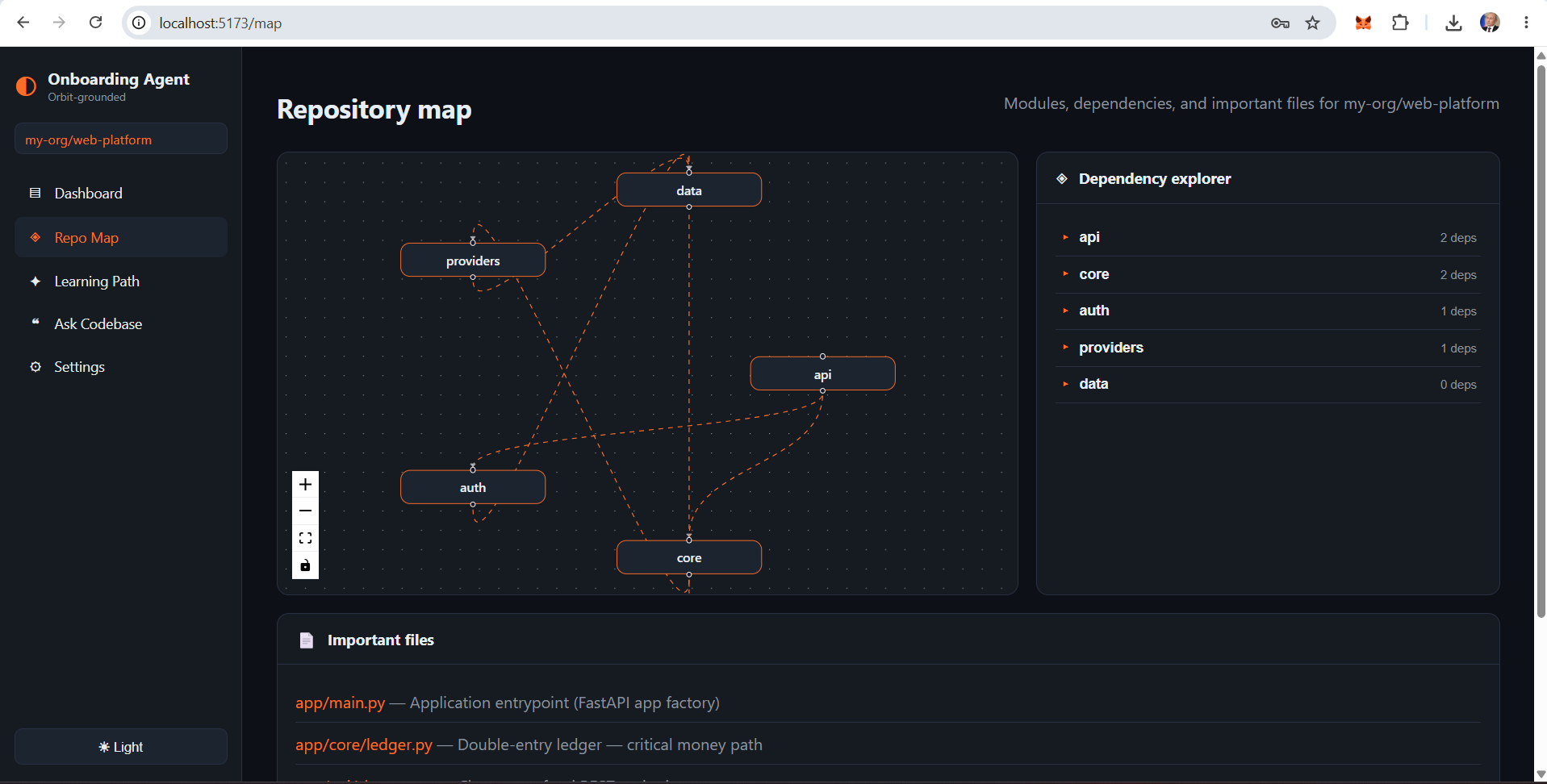
- Module dependency map — an interactive React Flow graph of DEPENDS_ON edges so new engineers can identify safe change zones
- Setup & local run — steps derived from the CI/compose files Orbit indexed, not from assumptions
- Ownership table — "who do I ask before touching
core?" answered from Orbit's OWNS/CODEOWNER_OF edges - Non-obvious risks — high-centrality files and critical paths flagged with severity badges
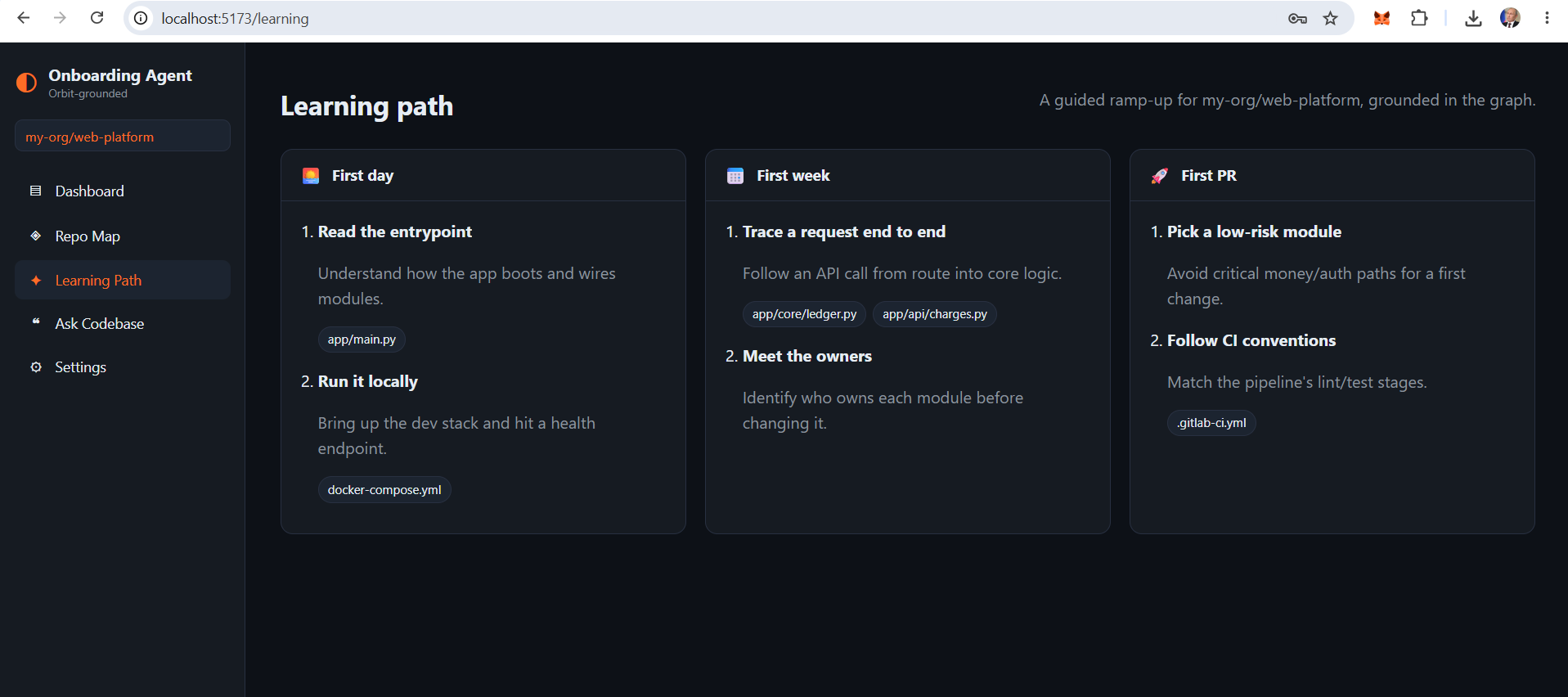
- Learning path — first day / first week / first PR tasks, each pointing at relevant files in the graph
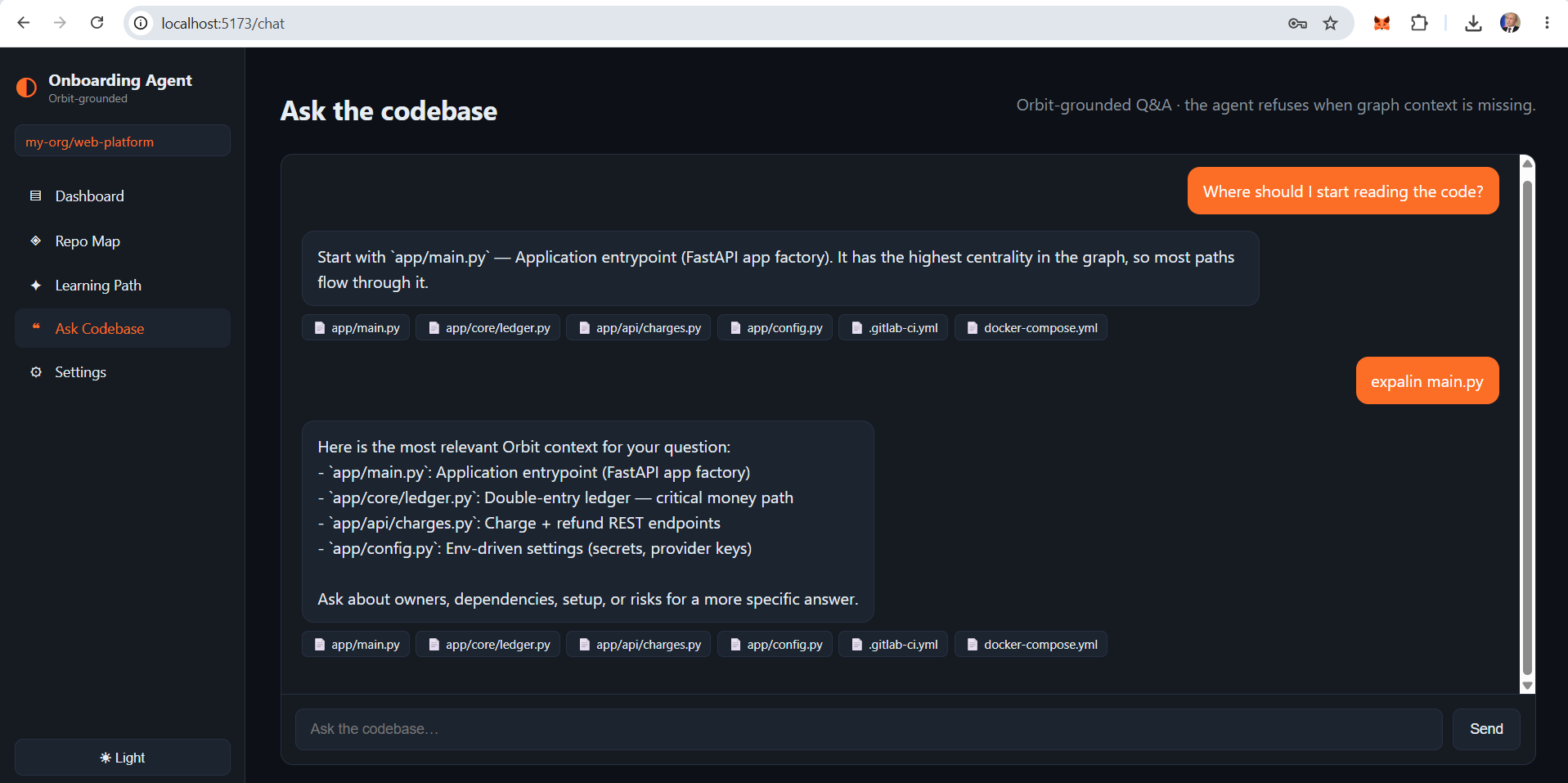
- Ask the codebase — a grounded Q&A chat where the agent refuses when Orbit has no context, rather than hallucinating
The grounding constraint is a deliberate design choice. Every summary, every answer, every citation traces back to a node or edge in the Orbit graph. An unanswered question surfaces a refusal, not a confident guess.
## How I Built It
The architecture is a three-layer pipeline:
$$ \text{Orbit Graph} \xrightarrow{\text{Cypher-like queries}} \text{Context Bundle} \xrightarrow{\text{Claude}} \text{Structured Summary} \xrightarrow{\text{React}} \text{Onboarding UI} $$
Backend — FastAPI + Python
An OrbitClient runs six targeted graph queries against the Orbit REST API for any given target:
MATCH (p:Project {path: $target})-[:CONTAINS]->(f:File) WHERE f.centrality > 0.4 OR f.is_entrypoint = true RETURN f.path, f.role, f.centrality, f.web_url ORDER BY f.centrality DESC LIMIT 20
The results are bundled into a structured context payload. An LLMService then passes that payload to Anthropic Claude with a strict grounding prompt — Claude's job is to
synthesize the graph data into readable prose and structured JSON fields (architecture overview, risks, learning path), not to answer from training knowledge.
Results are cached in MongoDB (via the async motor driver) with a configurable TTL, so repeated visits to the same target are instant.
Graceful degradation in two layers
I wanted the app to work in any environment — no GitLab token, no Anthropic key, no problem:
ORBIT_API_URLnot set →OrbitClientswitches to a realistic mock graph that simulates a payments service with modules, owners, MRs, and pipelinesANTHROPIC_API_KEYnot set →LLMServicefalls back to deterministic template functions that still produce Orbit-grounded output
Zero code changes are needed to switch between modes — it's all driven by environment config.
Frontend — React + Vite
Six pages built as a SPA: Landing, Dashboard, Repo Map (React Flow), Learning Path, Ask the Codebase (chat), and Settings. A TargetContext persists the active project across
pages via localStorage. Dark/light mode is supported via a ThemeContext.
The Vite dev server proxies /api to the FastAPI backend, keeping the frontend origin-agnostic between development and production.
## Challenges
Staying strictly grounded
The hardest design challenge was enforcing grounding as a hard constraint, not a guideline. The temptation is to let the LLM "fill in gaps" when Orbit returns sparse data — but a
hallucinated file path or a fabricated owner is worse than no answer. I solved this by making the refusal path a first-class feature: if fetch_context_bundle returns an empty
graph, the service raises OrbitError('empty') rather than proceeding, and the UI surfaces a clear, actionable message.
Citation integrity
Every file path and MR link in the UI had to trace back to an actual Orbit node. I built the citations list directly from the raw query rows — f.web_url, mr.web_url,
pl.web_url — rather than constructing URLs from string templates, so there's no risk of a citation pointing to a non-existent resource.
Port contention in development
A less glamorous challenge: Docker Desktop was binding 0.0.0.0:8000 on my machine (for an unrelated container), which intercepted API calls from the Vite proxy before they
could reach the FastAPI backend on 127.0.0.1:8000. Debugging this required reading Windows netstat output, identifying the conflicting PID, and pinning the Vite proxy target to
127.0.0.1:8000 explicitly.
Structuring LLM output reliably
Claude returns JSON inside the structured fields, but LLM output isn't perfectly reliable — code fences, trailing text, encoding artifacts. I wrote a _strip_fences() helper and
wrapped every json.loads() in a try/except that falls back to the deterministic template, so a malformed LLM response degrades gracefully rather than breaking the onboarding
flow.
## What I Learned
- Orbit's Knowledge Graph is genuinely rich. The DEPENDS_ON, CONTAINS, OWNS, and pipeline edges together tell a story about a codebase that static analysis alone can't — because it includes people and history, not just code.
- Refusals are a product feature. Users trust a tool more when it says "I don't know" cleanly than when it guesses plausibly. Making the agent refuse on missing context was the right call.
- Graceful degradation should be designed in from day one. Building mock → template → LLM as three independent layers meant the app was always demoable, even when working on live Orbit integration.
- Graph centrality is a surprisingly good proxy for "where should I look first." Files with high centrality scores — many inbound and outbound edges — almost always turn out to be the entry points, routers, or core domain objects a new engineer should read before anything else.

Log in or sign up for Devpost to join the conversation.