-
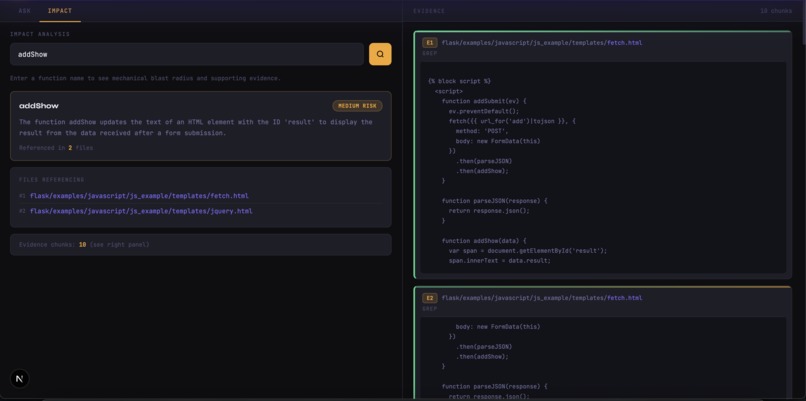
Impact Tab
-
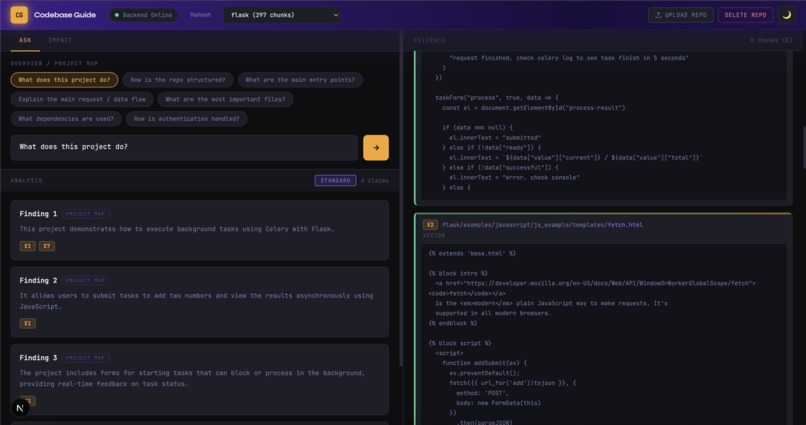
Ask Tab
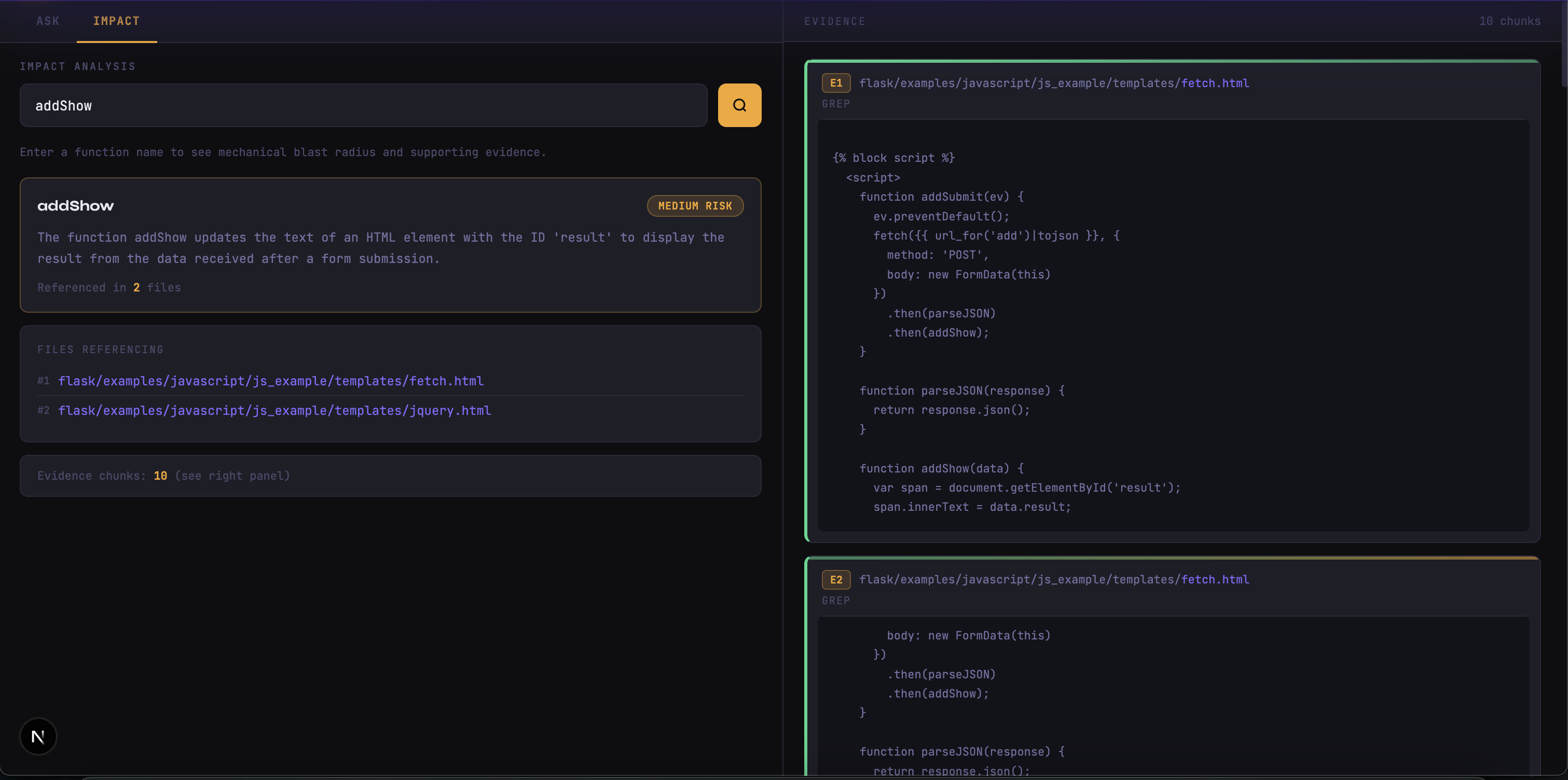
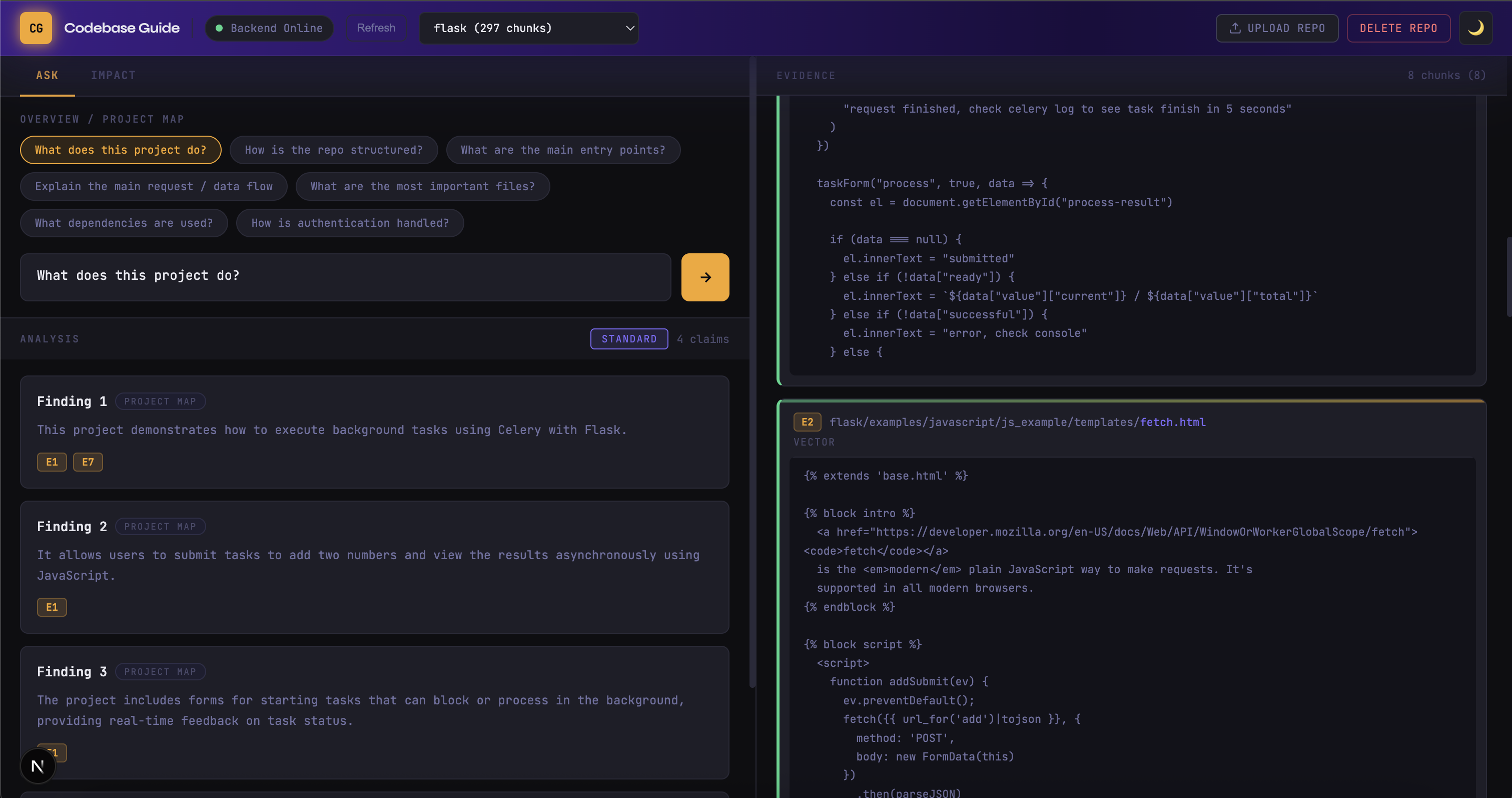
Inspiration
The idea for AI Codebase Guide did not come from theory. It came from frustration. Several of our friends and family who are working professionals mentioned that onboarding into new repositories was one of the most painful parts of software development. New developers were spending days just trying to understand structure, data flow, and hidden dependencies before they could contribute anything meaningful. At the same time, we were experiencing the same issue ourselves while working with open-source projects. Looking at unfamiliar code without context is exhausting, you scroll, you guess, you search, you piece things together manually. The pattern was obvious where developers were not struggling to write code, but rather they were struggling to understand existing code. We asked a simple but serious question: why does understanding a repository still take hours when retrieval systems and vector embeddings exist? That question became AI Codebase Guide.
What it does
AI Codebase Guide is a retrieval-first system that analyzes a repository using a full Retrieval-Augmented Generation (RAG) pipeline. It is a structured system where every explanation is grounded in real code. A developer can upload a repository, ask questions about its logic, and receive answers backed by exact code chunks. Each claim references specific file paths and line ranges. On the Impact tab, a user can enter a function name and instantly see its blast radius across the repository, with risk computed mechanically from actual file references. Most importantly, the model is never allowed to see the entire repository. It only sees retrieved evidence. That constraint is what enables near-zero hallucinations, it is the fact that the system is grounded by design. Instead of spending hours manually tracing logic, developers can now
How we built it
We built the system end-to-end using: • Frontend: React + JSX + Next.js • Backend: FastAPI (Python) • Vector Store: ChromaDB (persistent) • Embeddings: OpenAI text-embedding-3-small • LLM: gpt-4o-mini The architecture revolves around a properly implemented RAG pipeline. When a repository is uploaded, it is parsed and chunked into 100-line segments with 20-line overlap. Each chunk is embedded into a 1536-dimensional vector and stored in ChromaDB. When a user asks a question, we embed the query and retrieve the top 8 semantically relevant chunks because it provides enough coverage to answer properly, while keeping context controlled and grounded. Those 8 chunks form the only context sent to the model. The model returns structured output containing claims and evidence IDs. Each claim maps directly to specific chunk IDs, file paths, and line ranges, and the UI renders those references as clickable citations tied to exact blocks of code.
Challenges we ran into
We had real difficulties integrating the frontend and backend cleanly while enforcing strict contracts for responses. We also had to get the chunking mechanics right, because chunking is not “just splitting text”, it directly affects what the retrieval system can and cannot surface. Implementing the RAG system properly was the hardest part, this included, vectorizing the repository, storing embeddings, tuning retrieval, and building evidence linking so that every claim points back to a specific block of code. Getting both the Ask and Impact tabs to work end-to-end, while keeping citations accurate and clickable, required careful engineering across the full stack.
Accomplishments that we're proud of
We solved every major problem we ran into: frontend-backend integration, chunking mechanics, full RAG implementation, vector storage, retrieval, and evidence linking. The result is an end-to-end system that works cleanly, produces grounded answers with real citations, and achieves near-zero hallucinations through architectural constraints.
What we learned
We learned how to implement RAG from first principles as an engineering system. We learned how embeddings behave, how retrieval quality depends on chunking design, how persistent vector stores like ChromaDB change what’s possible, and why grounded systems require strict constraints. We also learned that if you want reliability, you cannot blindly trust some api call, you have to control the context and force evidence-driven outputs.
What's next for codebase-analyzers_Codebase Guide
The current build proves the functionality of our planned architecture. Next, we see this evolving into a serious developer workflow tool: • IDE integration (VSCode) • CI/CD impact analysis before merges • PR blast-radius prediction The vision is straightforward about understanding code should not be an interpretive art. It should be a fast, grounded, verifiable process, and that is exactly what we built the foundation for.

Log in or sign up for Devpost to join the conversation.