-
-
asking the user to select which problem.
-
shows which problem it is solving
-
asking user to select model from registry.
-
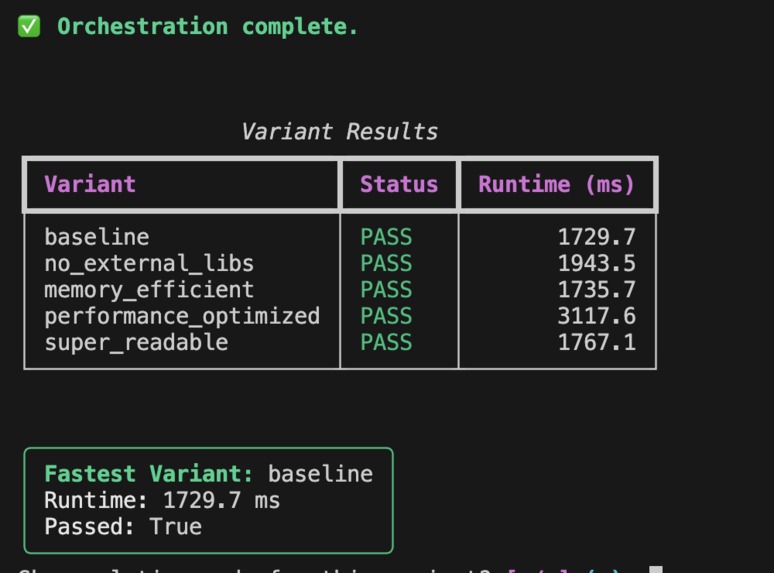
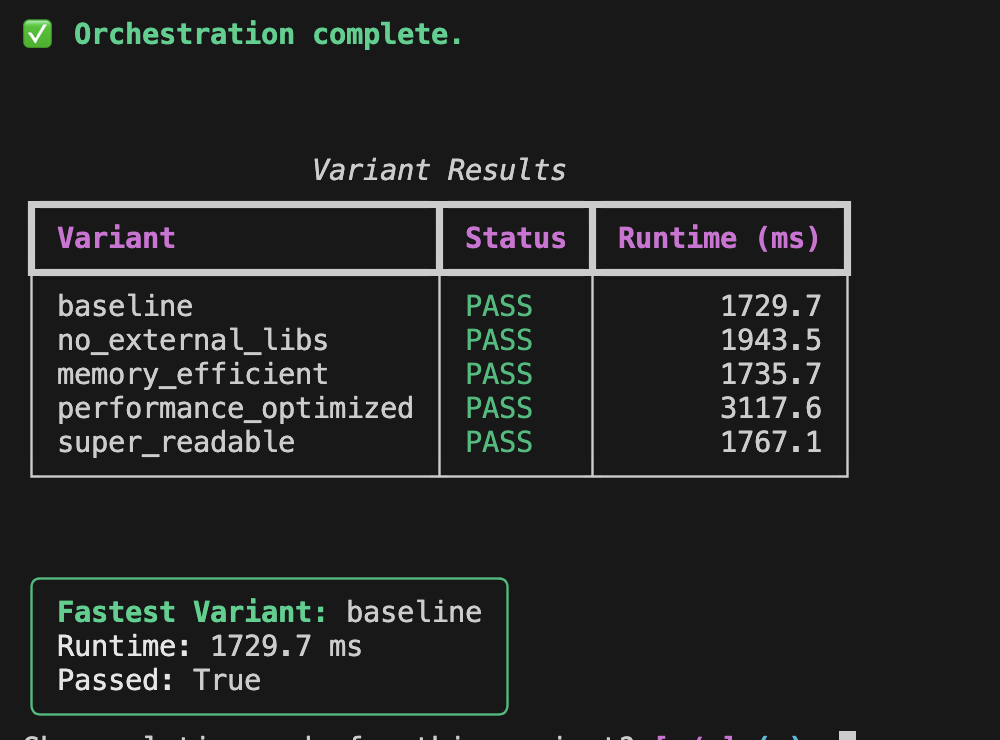
list of results + fastest variant.
-

Logo

Inspiration
I’ve always felt that coding with LLMs is a bit too “take it or leave it.” You get one answer, and if it’s wrong or not in the style you want… tough. But devs have preferences. Sometimes I want the fastest solution, sometimes I want something clean and readable that fits my codebase, and sometimes I want something super memory-efficient.
So I built Code Quintet to flip that dynamic. Instead of one answer, you get five—each optimized differently—and you pick the one that fits your goals.
What it does
Code Quintet takes a coding problem, generates five solution variants with different styles, runs them in isolated Daytona sandboxes, and gives you a clean comparison of correctness, runtime, errors, and overall performance.
The whole thing is human-in-the-loop: I don’t assume what you want. You tell me your priority—speed, correctness, memory, readability—and Code Quintet will capture the right choice.
How I built it
I built a small pipeline around HumanEval, pulling the prompt, function signature, and tests. Then I designed five “personalities” for the LLM—baseline, fast, memory-efficient, no-external-libs, and ultra-readable.
Each variant is generated with a different prompt modifier. I pass the code into Daytona sandboxes, run the tests, measure runtime, and collect everything into a summary table.
On top of that, I added a clean CLI, JSON artifacts for every run, and a nice little user flow to tie it all together.
Challenges I ran into
Latency. Latency. Latency.
Running five LLM calls and five sandbox executions back-to-back was painfully slow at first—plus my WiFi was very slow. The initial version ran everything sequentially...
To fix that, I parallelized the whole pipeline, slimmed down the code, reduced unnecessary network calls, and used TQDM to track everything cleanly as it ran. Once I got concurrency dialed in, the whole system felt way snappier.
I also had the usual fun bugs with sandboxes, code extraction, and test imports.
Accomplishments I’m proud of
- Built a working ensemble system end-to-end as a solo builder
- Integrated Daytona sandboxes seamlessly
- Ran real HumanEval tests—no mock data
- Made the whole workflow feel surprisingly nice from the CLI
- And honestly, just seeing five solutions race against each other feels awesome
- Really fun idea for a variant marketplace.
- added a HTML UI for users to look at their runs!
What I learned
I learned that LLMs benefit a lot from diversity. Asking for five different approaches surfaces totally different trade-offs.
I also learned that sandboxing is essential if you want to trust code. HumanEval reminded me how subtle “correctness” can be. And the human-in-the-loop pattern—letting people choose their preferred solution—feels like a direction more coding tools should embrace.
What’s next for Code Quintet
I want to turn this into a Cursor extension that works live inside the editor. Imagine highlighting a function and instantly seeing five solution variants appear in real time—tested, ranked, and ready to drop into your codebase.
The long-term dream is a system that learns from developer preferences and adapts its variants to each person’s style.
Built With
- daytona
- pydantic
- python
- tqdm
- uv

Log in or sign up for Devpost to join the conversation.