Inspiration
Great technical talks aren’t won by “sounding smooth” — they’re won by surviving stress tests. In real audiences, even a small gap can derail understanding:
\begin{itemize} \item an undefined symbol \item a motivation that doesn’t land \item a logical jump that feels “obvious” to the speaker \item a claim that silently assumes conditions that aren’t true \end{itemize}
CoachCat AI started from a simple question:
How do we make rehearsal a process of systematically reducing communication risk, not just repeating the same draft?
I wanted an always-available “audience panel” that challenges your story like a tough but helpful colleague—so you can find the fragile parts early and fix them fast.
What it does
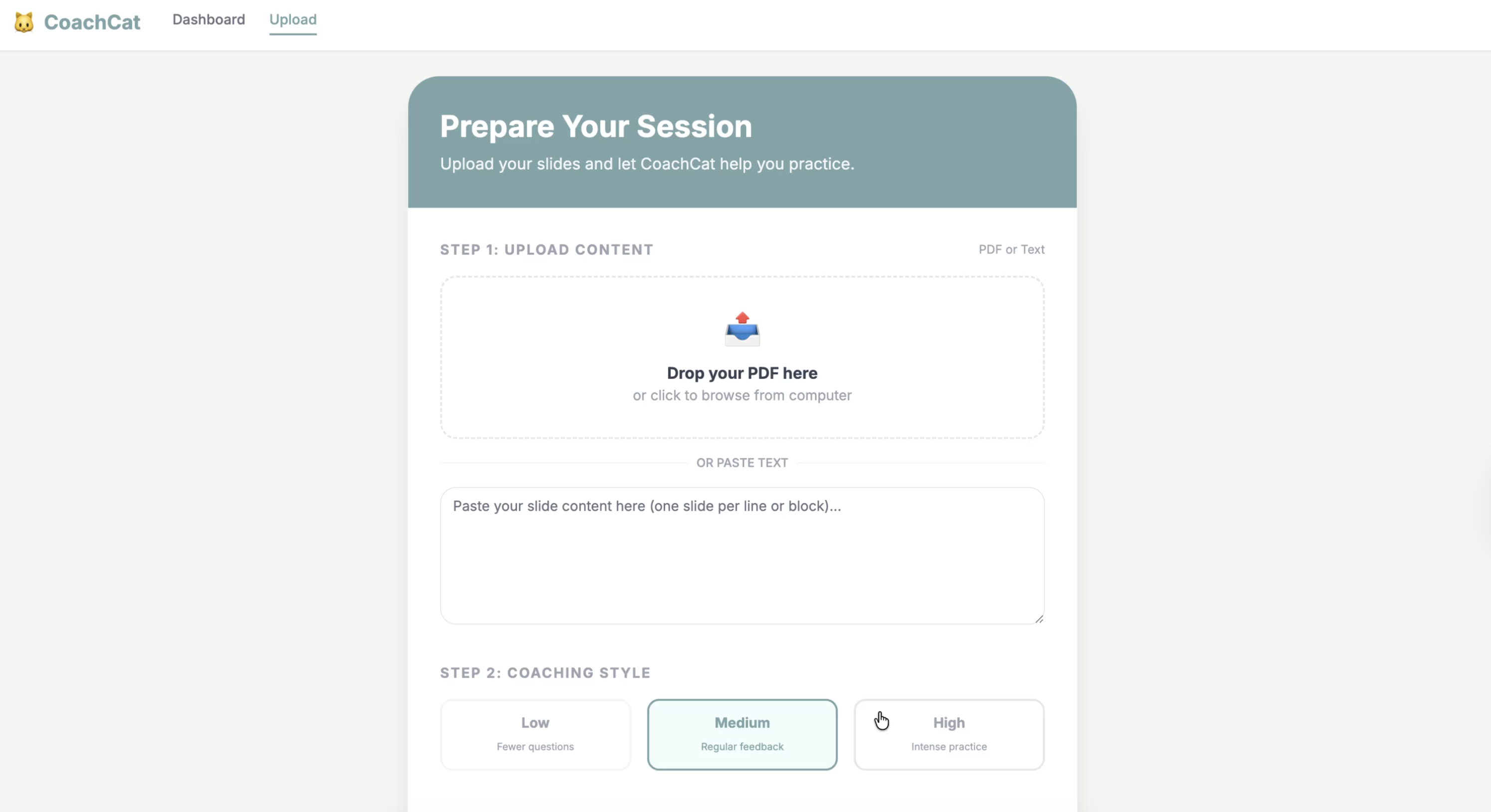
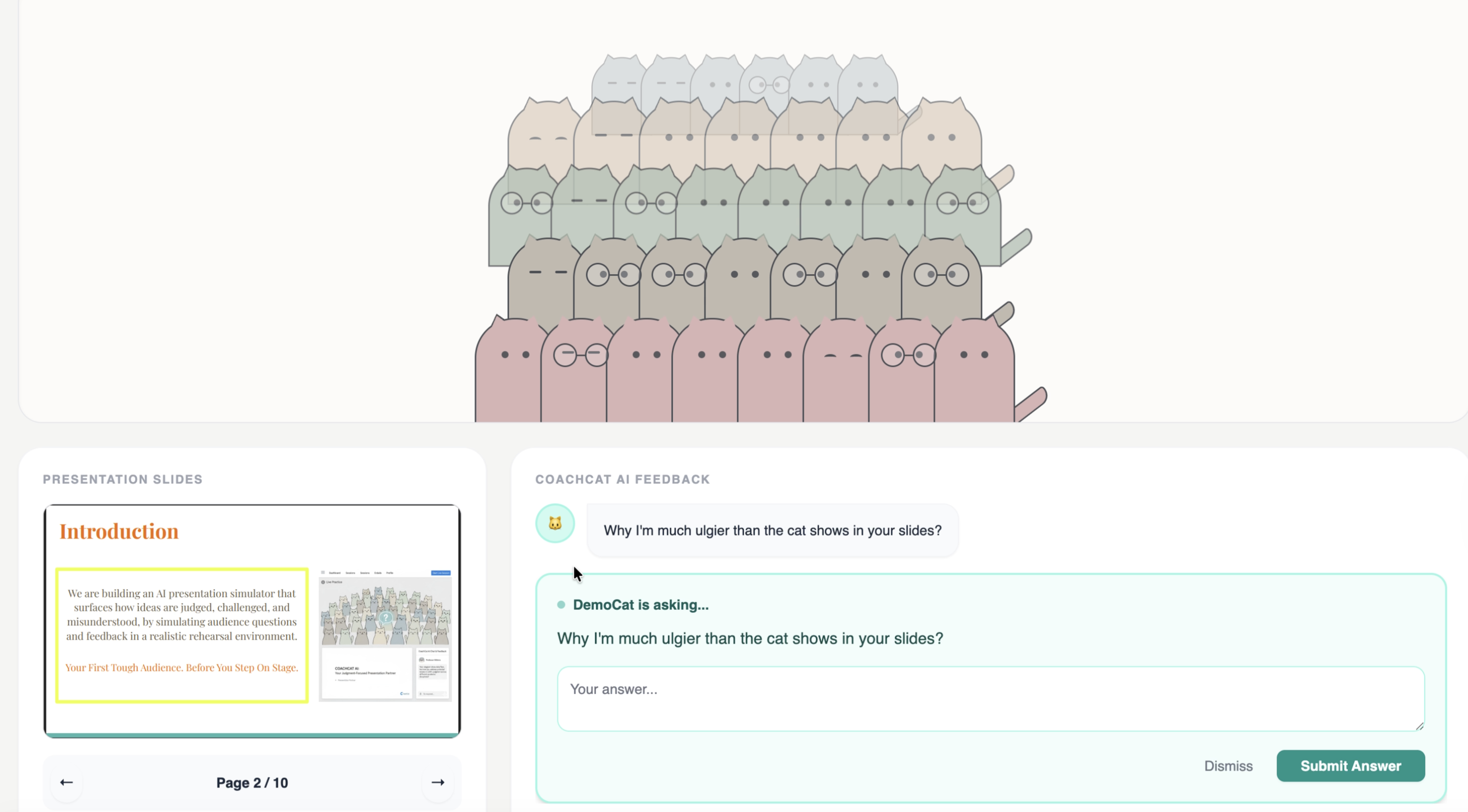
CoachCat AI is a rehearsal assistant for research talks, technical presentations, interviews, and demos. You provide a draft (outline, script, or slide text), and CoachCat runs a multi-persona critique loop:
\begin{itemize} \item LogicCat: finds gaps, contradictions, missing steps \item DefinitionCat: checks terminology, symbols, precision, and consistency \item MotivationCat: pushes on \emph{why it matters}, who it’s for, and what changes if it works \item SkepticCat: challenges assumptions, edge cases, and over-claiming \end{itemize}
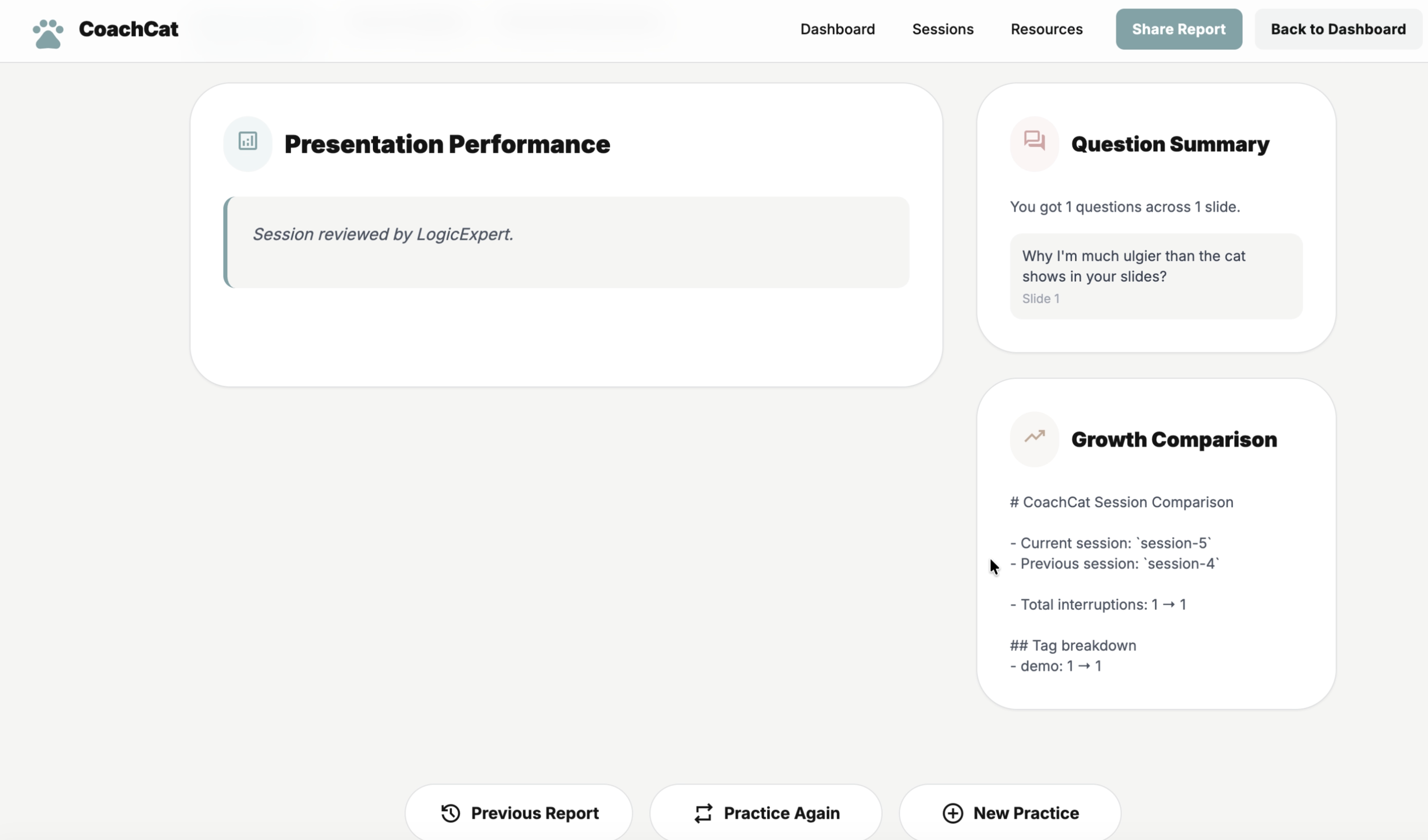
After each round, CoachCat produces a structured report that prioritizes the highest-risk issues and proposes concrete fixes tied to specific sections—turning rehearsal into an iterative risk-reduction process.
How we built it
We designed CoachCat as three layers: understanding $\rightarrow$ multi-agent critique $\rightarrow$ structured evaluation.
\begin{enumerate} \item Input & parsing. We normalize outlines/scripts/slide text into a consistent internal representation so the system can reference exact sections when giving feedback. \item Multi-persona orchestration. A “host cat” routes the same content to specialized persona agents, reduces redundancy, and keeps the critique focused and non-repetitive. \item Scoring & reporting. All feedback is converted into a shared schema (issue type, severity, evidence snippet, suggested fix), then merged into one actionable rehearsal report. \end{enumerate}
We prioritized structure and extensibility: adding personas, rubrics, or output formats is configuration-driven rather than a rewrite.
Challenges we ran into
Building an AI that is both sharp and reliable is harder than it sounds. The main challenges were:
\begin{itemize} \item Sharp critique without hallucination. We pushed for evidence-based feedback that cites the user’s own text, not generic advice. \item Turning critique into edits. “Be clearer” is not actionable; we needed concrete rewrite suggestions that a user can apply immediately. \item Multi-agent redundancy and conflicts. Personas can repeat each other or disagree; orchestration and deduplication were necessary to keep the experience tight. \item Measuring improvement. Communication quality is hard to quantify, so we tracked severity-weighted issue counts and recurring issue types across iterations. \end{itemize}
Accomplishments that we're proud of
\begin{itemize} \item Built a working multi-persona rehearsal loop that reliably surfaces risks across logic, definitions, motivation, and assumptions. \item Produced structured, prioritized, actionable reports instead of unorganized chat feedback. \item Developed a risk-oriented rehearsal workflow that makes practice iterative and measurable, not just repetitive. \end{itemize}
What we learned
\begin{itemize} \item The fastest improvement comes from fixing*high-severity failure points*, not polishing delivery first. \item Persona-based critique increases coverage: a “panel” catches more than a single assistant. \item Strong structure (schemas, priorities, references) matters as much as model capability for real usability. \end{itemize}
What's next for CoachCat AI
\begin{itemize} \item Voice rehearsal + timestamped feedback: record a run-through, transcribe it, and tag issues to exact moments. \item Risk dashboards: show issue trends across sessions, recurring weaknesses, and highest-ROI fixes. \item Scenario templates: different rubrics for research talks, interviews, and startup demos. \item Stronger grounding:* enforce that critiques include evidence (quotes/locations) and propose minimal concrete rewrites. \item **Shareable rehearsal reports: export to Markdown/PDF so mentors or teammates can comment on the same structured feedback. \end{itemize}
Built With
- indexeddb;-audio:-web-audio-api
- languages:-python
- llm);-storage:-in-memory-(python-dicts)
- pcm16;-protocols:-websocket
- pytest
- react-18;-apis:-google-gemini-(live-asr
- rest;-tools:-pydantic
- typescript/javascript;-backend:-fastapi
- uvicorn;-frontend:-next.js-14


Log in or sign up for Devpost to join the conversation.