





Inspiration
Most AI writing tools feel like an overexcited intern — constantly interrupting, flooding the screen with suggestions, and breaking the writer’s flow. As both a writer and a builder, that always felt wrong to me. Real collaboration isn’t loud; it’s intentional.
The inspiration behind Co-Author came from a simple question I kept asking myself: What if AI behaved like a disciplined, thoughtful co-author instead of a reactive chatbot?
I wanted silence to mean intelligence, and intervention to mean value.
What it does
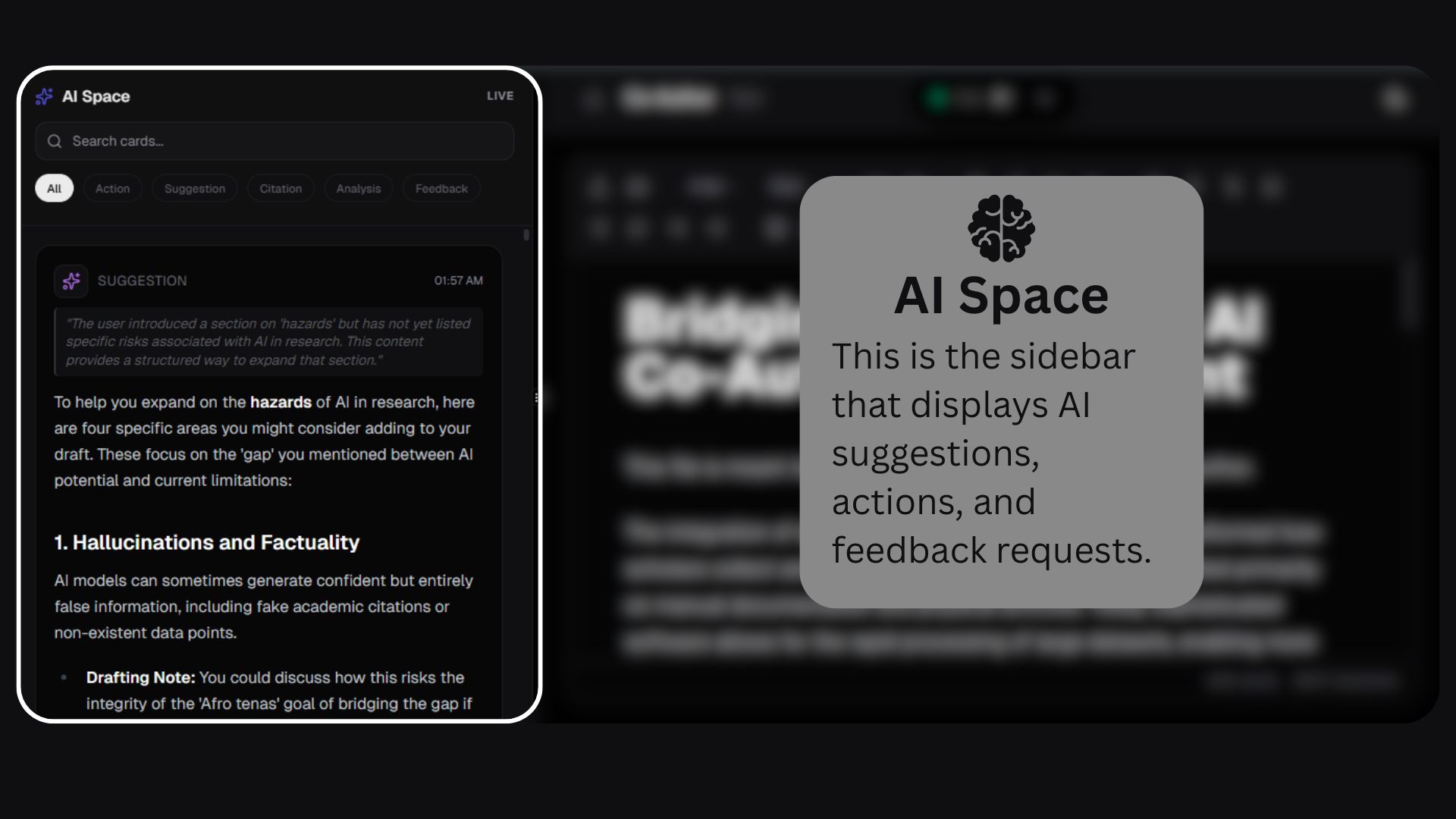
Co-Author is an autonomous AI writing partner that observes my writing in real time and contributes only when it has something genuinely useful to add. It combines a Notion-style research editor with a dedicated AI space that never overwrites my work.
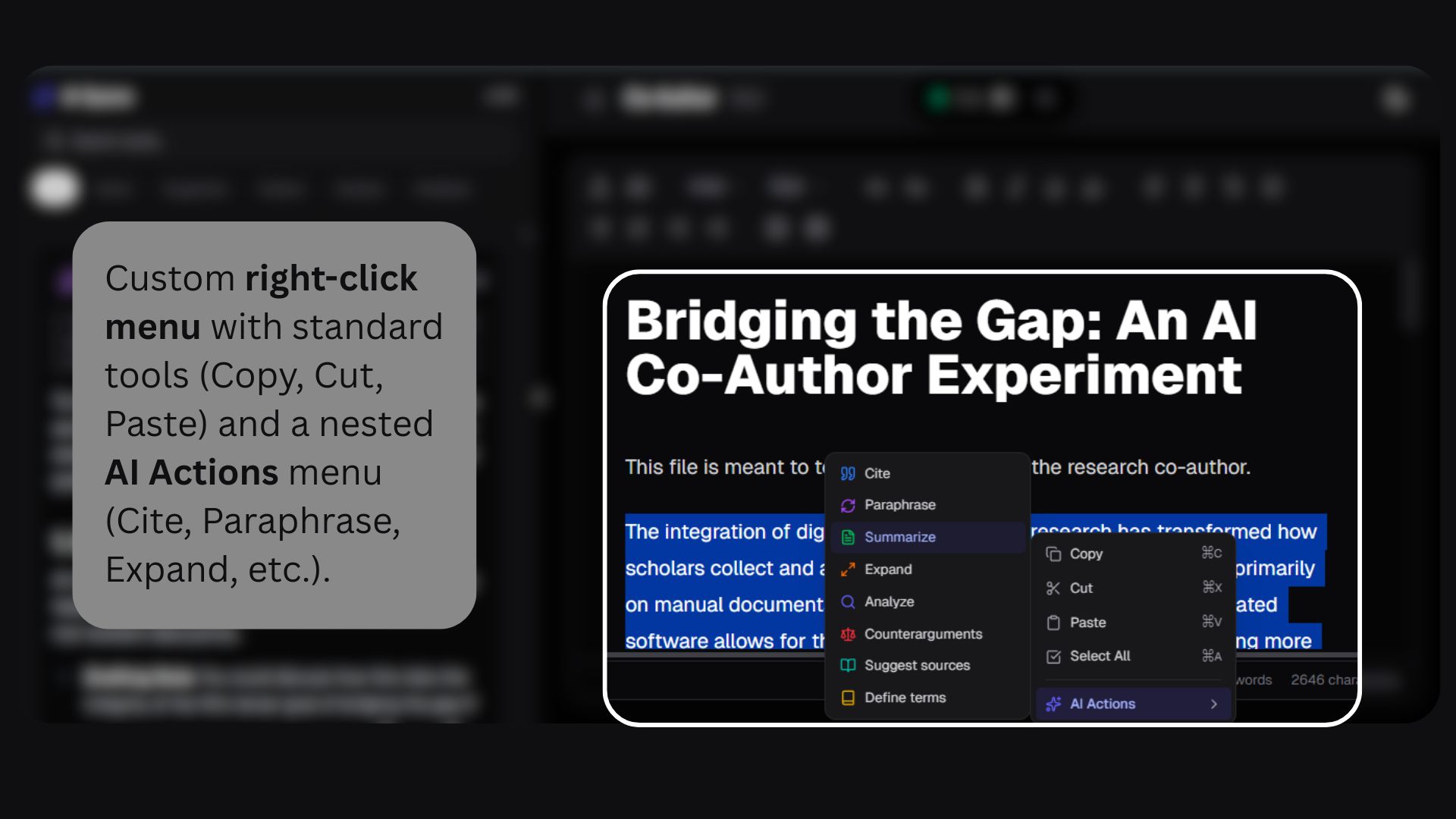
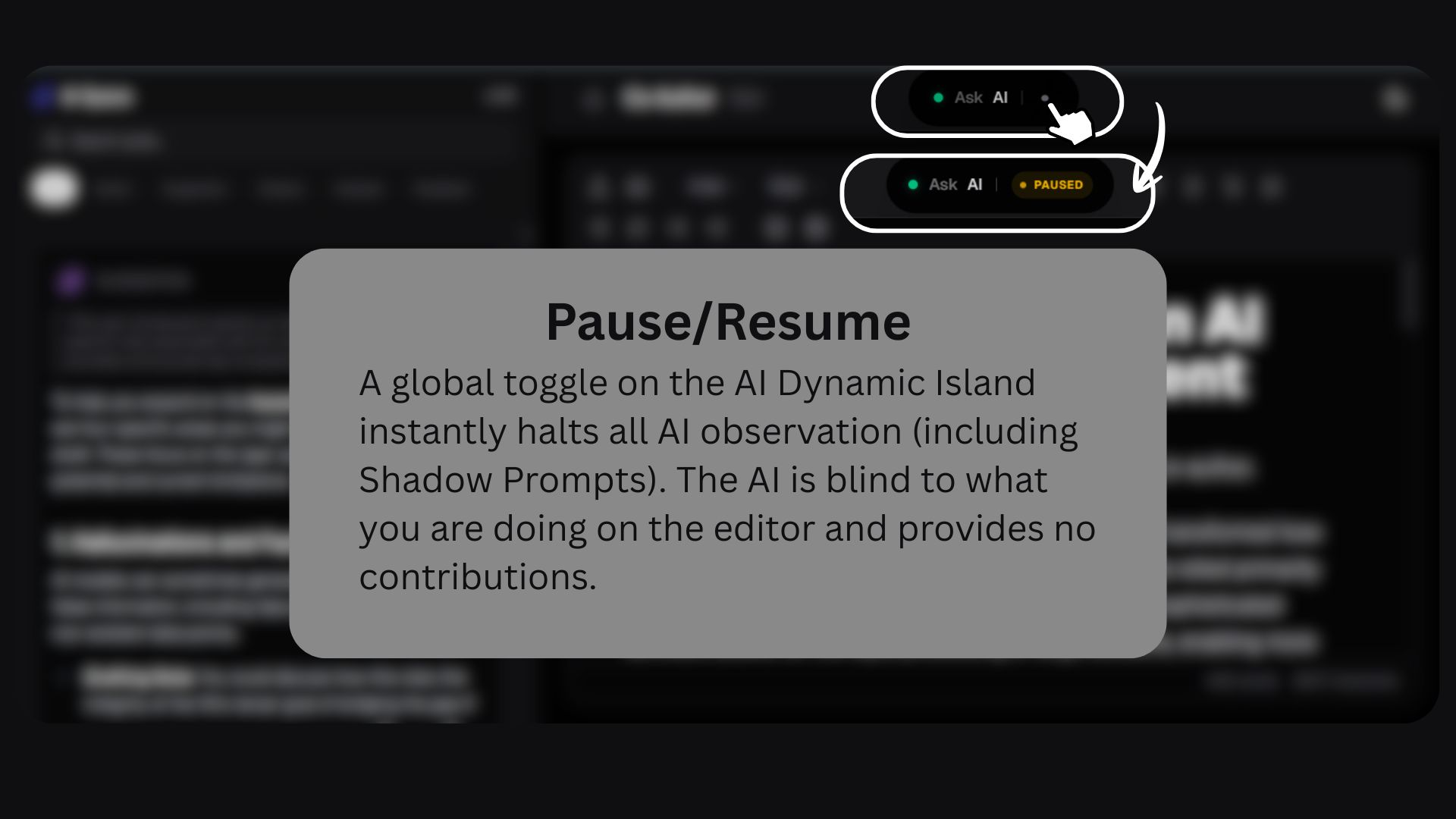
Using a 7-Layer Maturity Stack, the AI waits, evaluates intent, enforces cooldowns, justifies interruptions, and respects contribution limits. The result is an AI that helps with outlining, citations, analysis, paraphrasing, and research — without hijacking the writing process.
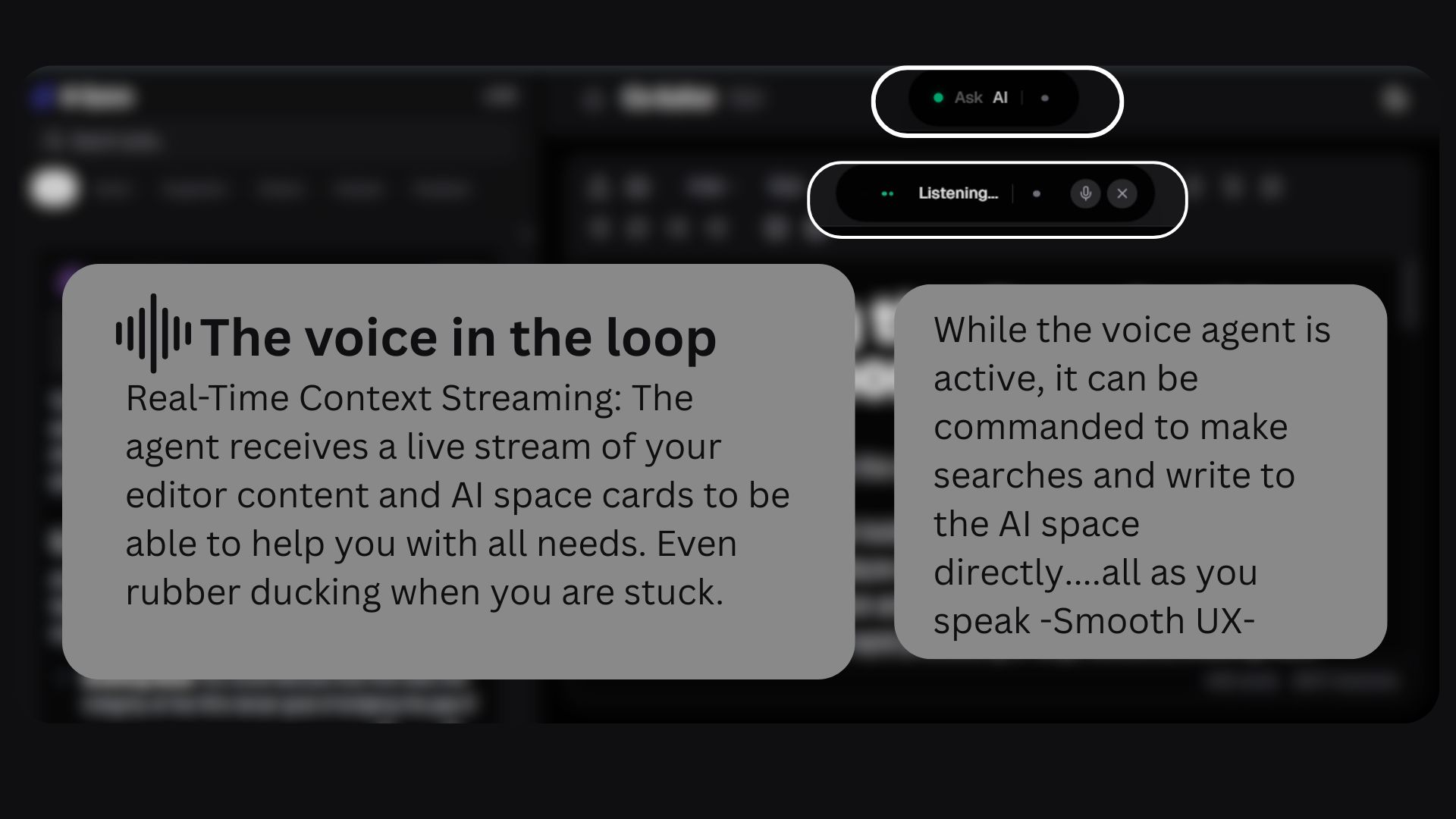
A real-time voice agent adds a human layer, allowing me to talk through ideas while the AI quietly handles background research.
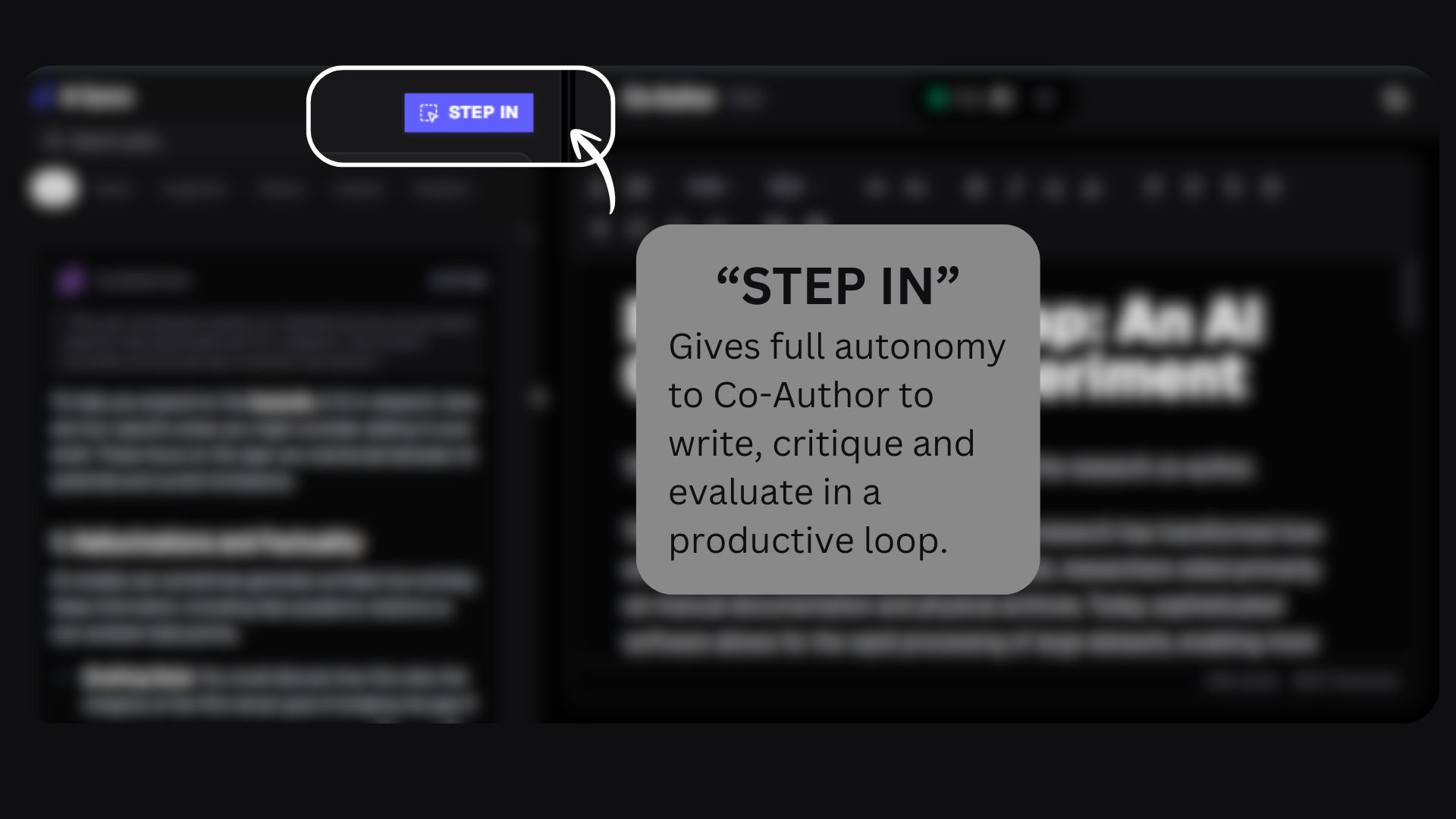
The “Step In” feature allows for delegated authorship; with a single click, I can hand over full editorial control to the AI. It reads my instructions, develops a plan, executes the writing, evaluates its own work, and refines the draft until it meets a high standard—all while maintaining complete transparency through "Thought Cards."
How I built it
I built the app on Next.js (App Router) with Tiptap as a headless, extensible editor. State is managed with Zustand, and persistence is handled through Supabase.
The AI layer uses Google Gemini 3 Flash, leveraging long-context capabilities to treat the entire document as living context. I designed a custom Context Engine to power the 7-layer decision stack, supported by a secure API layer that sanitizes and validates every request.
The voice agent relies on real-time WebSockets and an AudioWorklet-based playback system to achieve smooth, uninterrupted audio without blocking the UI.
Challenges I ran into
The hardest challenge was teaching the AI when not to speak. Preventing constant interruptions meant implementing multiple layers of restraint rather than relying on simple debouncing.
Real-time voice streaming was another major hurdle — audio jitter, buffering issues, and clock synchronization problems forced me to move playback logic off the main thread entirely.
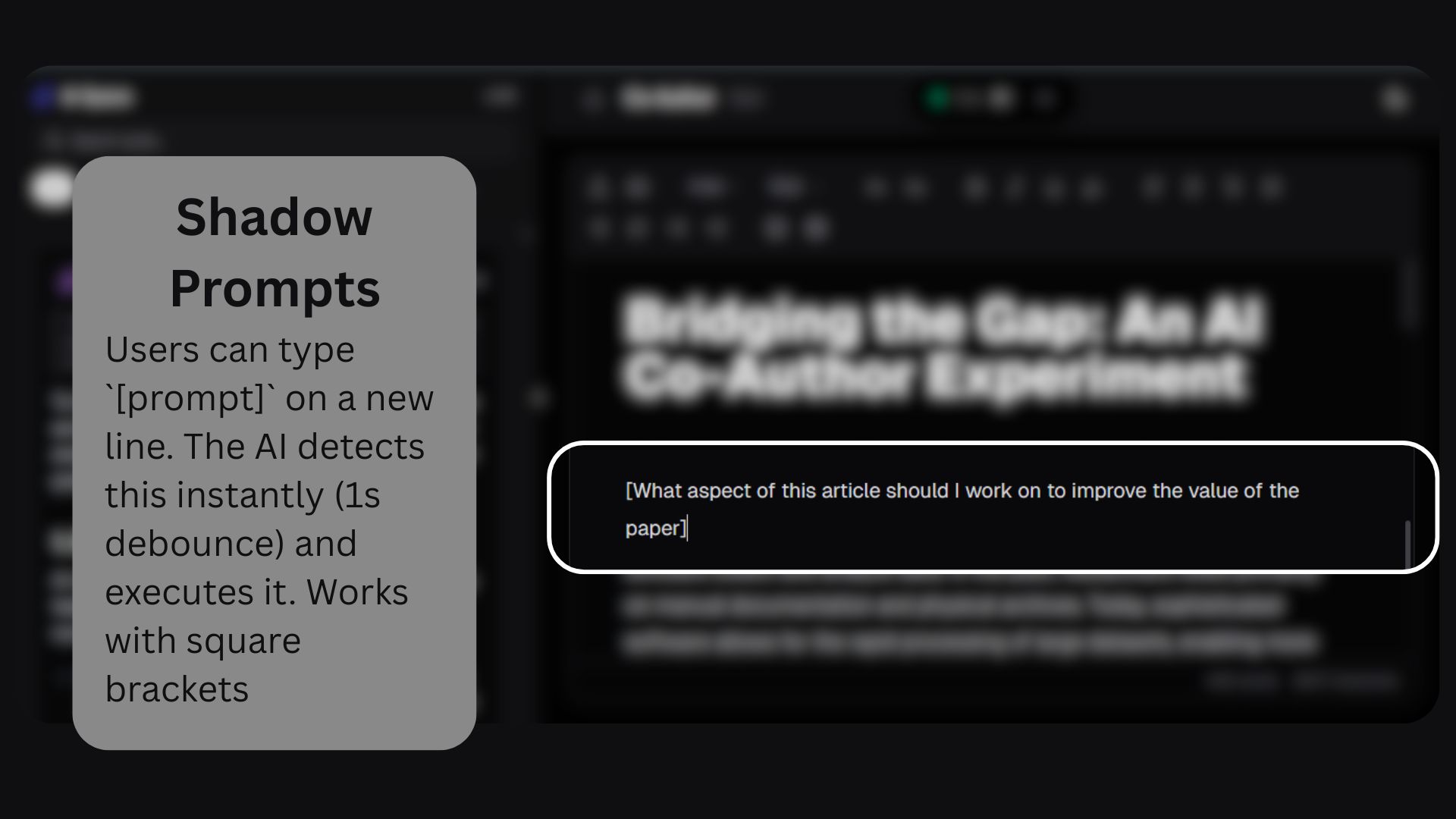
Security was also critical; preventing prompt injection and malicious inputs while still allowing “Shadow Prompts” required careful validation and intent scanning.
Accomplishments that I'm proud of
- Building a genuinely non-intrusive AI that earns the right to interrupt.
- Designing and implementing the 7-Layer Maturity Stack from scratch.
- Achieving smooth real-time voice interaction using AudioWorklets.
- Creating a clean separation between the writing space and the AI’s contribution space.
- Implementing a security layer that actively blocks jailbreak attempts.
What I learned
I learned that good AI UX is more about restraint than raw intelligence. Latency, silence, and timing matter just as much as model quality. I also learned that real-time systems demand real engineering — shortcuts in audio, scheduling, or buffering always surface as UX problems later.
Most importantly, I learned that users trust AI more when it behaves like a collaborator, not a performer.
What's next for Co-Author AI Autonomous writing agent
Next, I plan to expand collaborative intelligence with multi-document reasoning, cross-paper citation mapping, and adaptive writing styles per section. I want to refine the voice agent into a true thinking partner and introduce collaborative modes for teams.
Long-term, Co-Author aims to become the standard environment where humans and AI co-write — calmly, deliberately, and at scale.
Built With
- antigravity
- gemini
- geminiliveapi
- nextjs
- supabase
- tailwindcss
- tiptap-lab
- zustand

Log in or sign up for Devpost to join the conversation.