-
-

Clutch — AI how-to agent for smart glasses and phone
-
 GIF
GIF
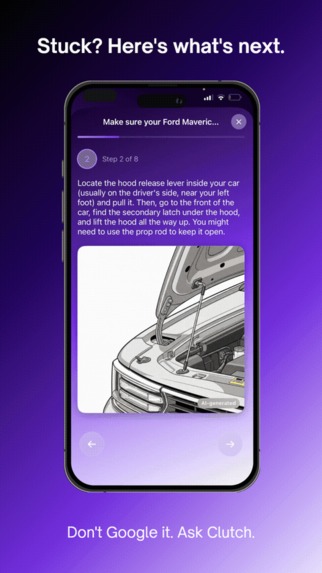
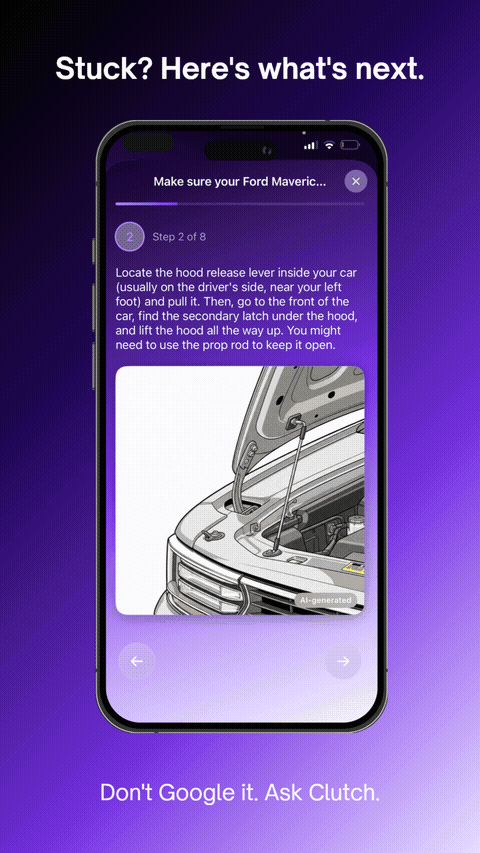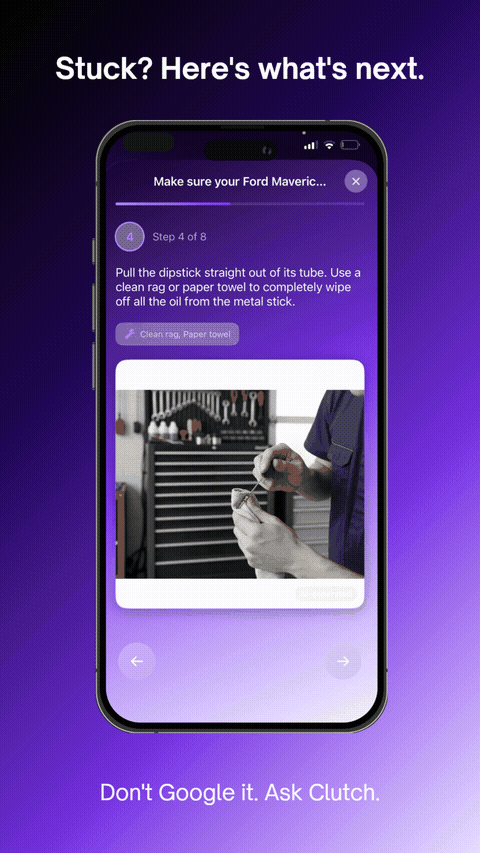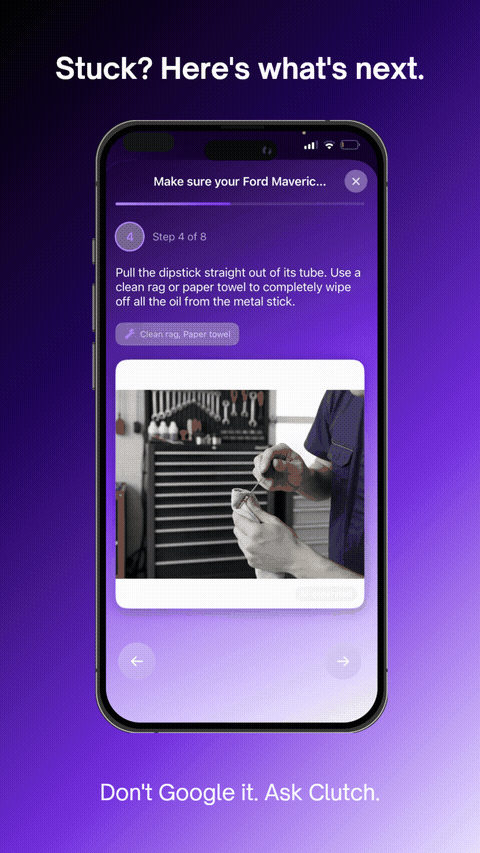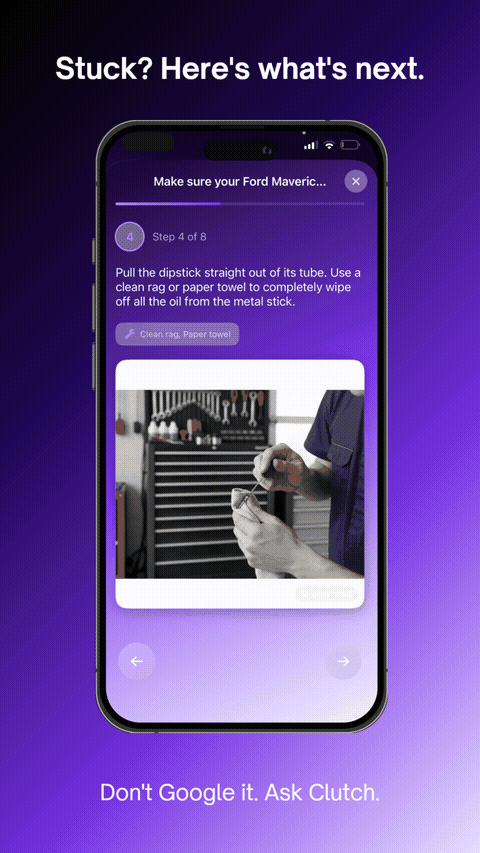
Stuck? Here's what's next.
-

AI-generated steps with Imagen 4 reference images guide you hands-free
-
 GIF
GIF
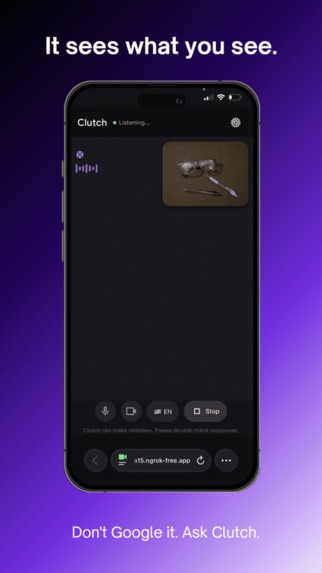
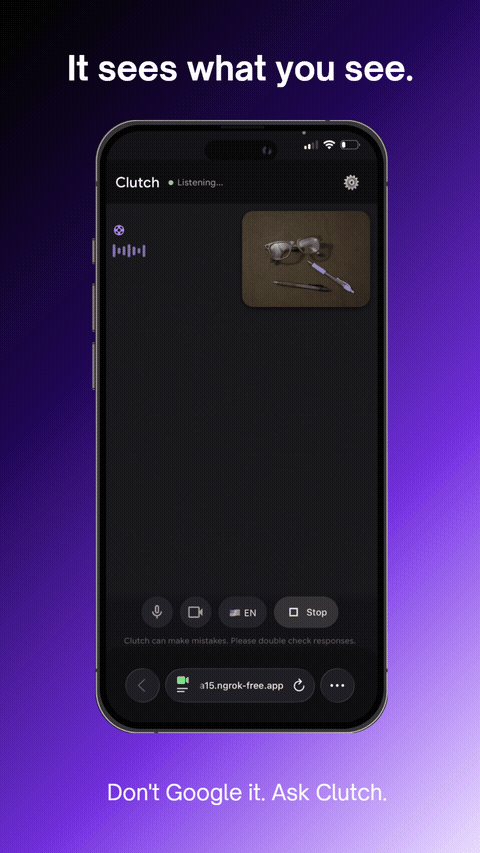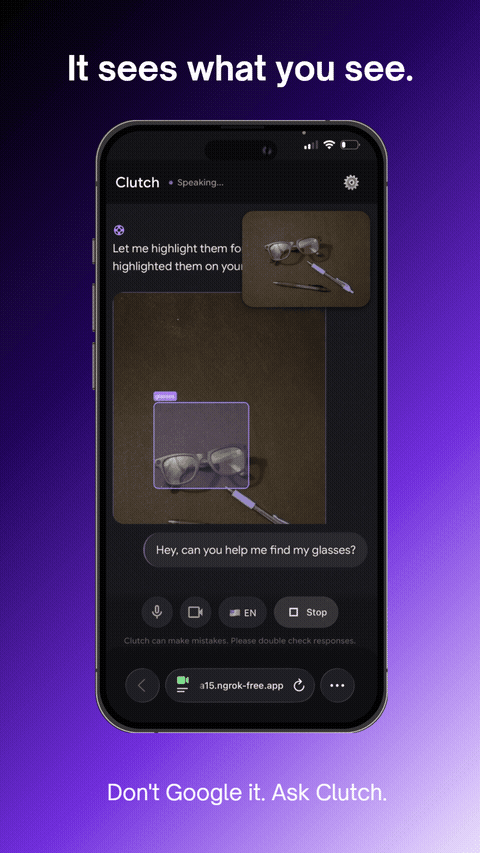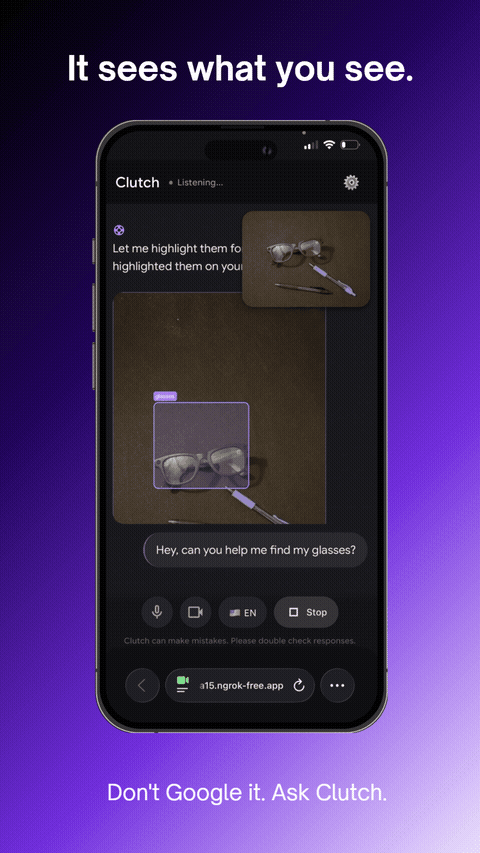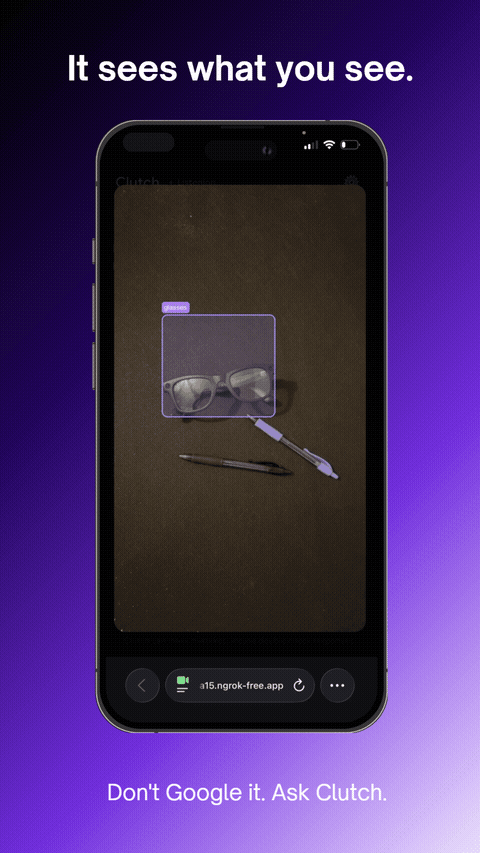
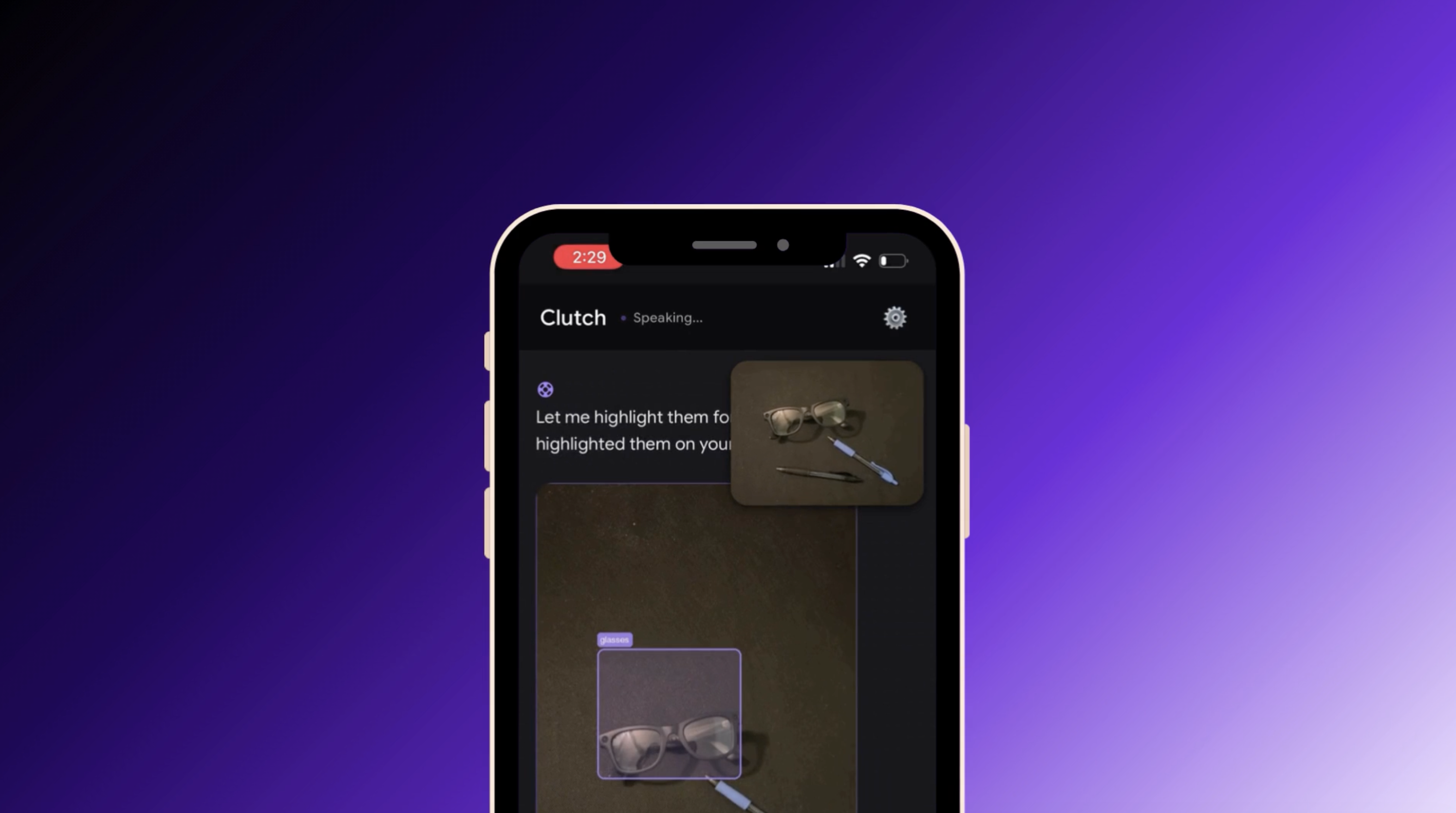
It sees what you see.
-
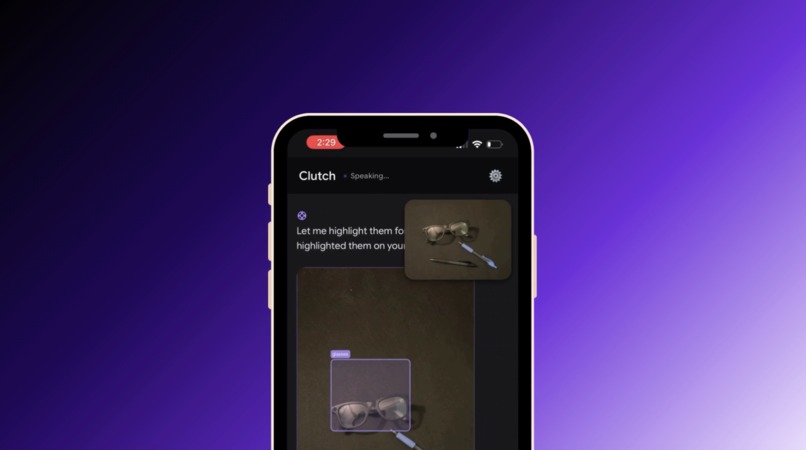
Real-time object annotation — agent sees and labels what's in frame
-
 GIF
GIF
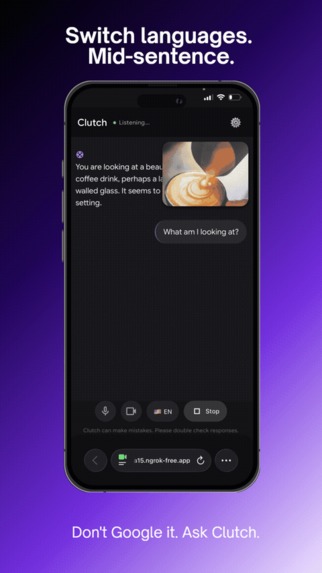
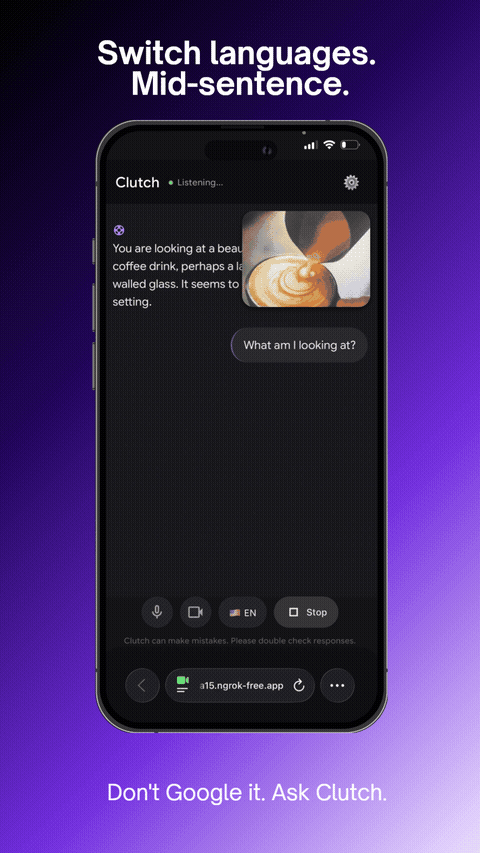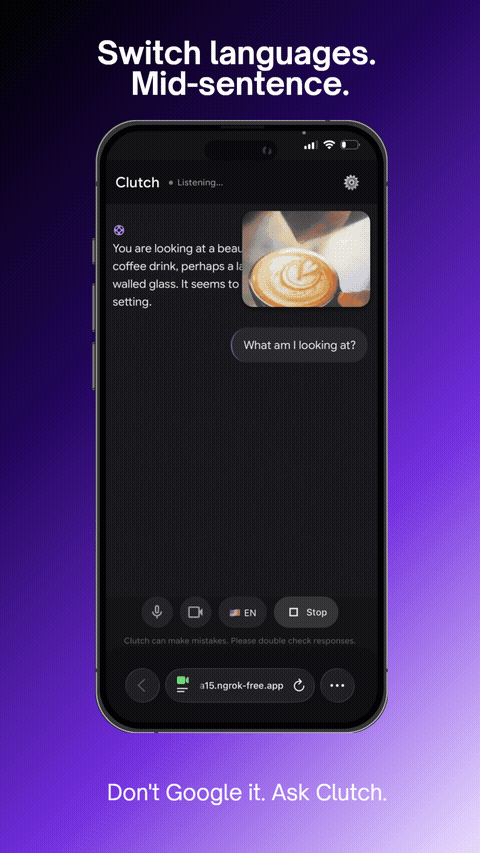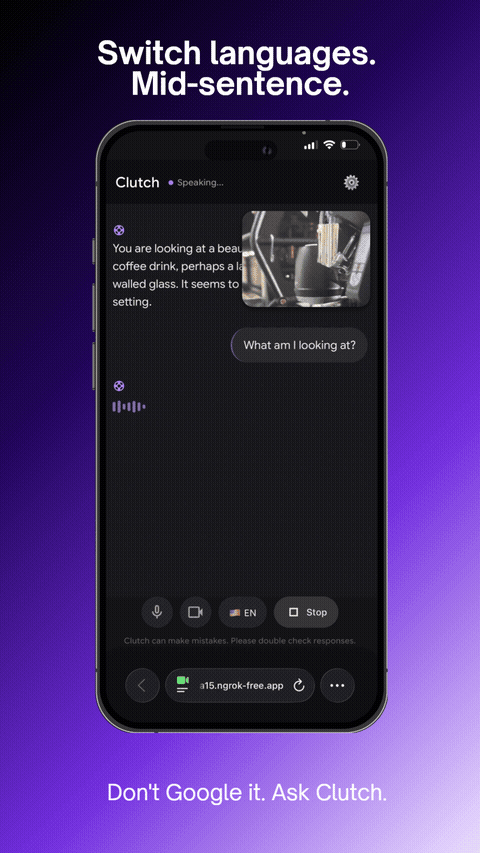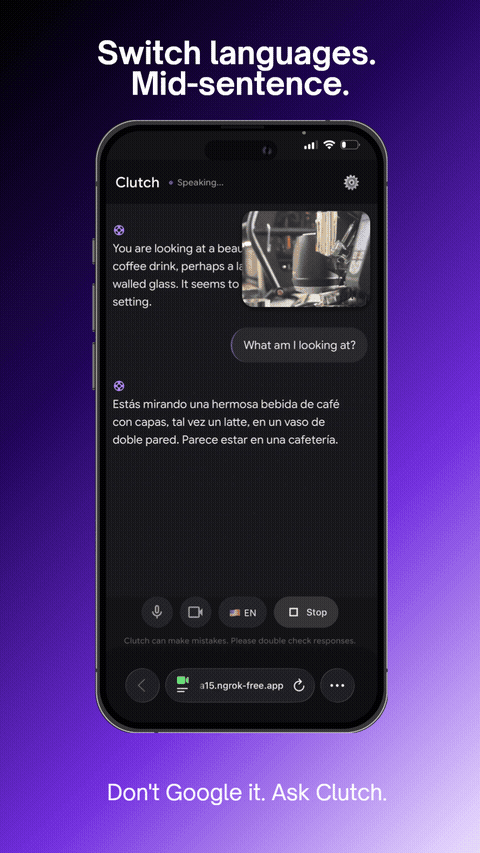
Switch languages. Mid-sentence.
-
 GIF
GIF
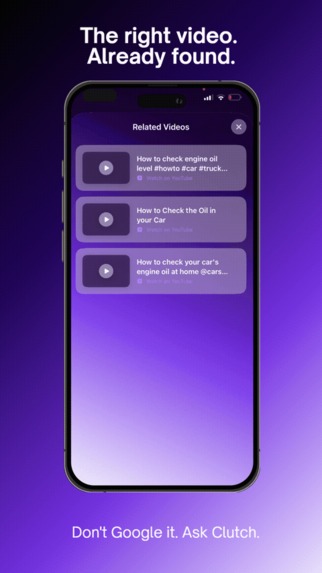
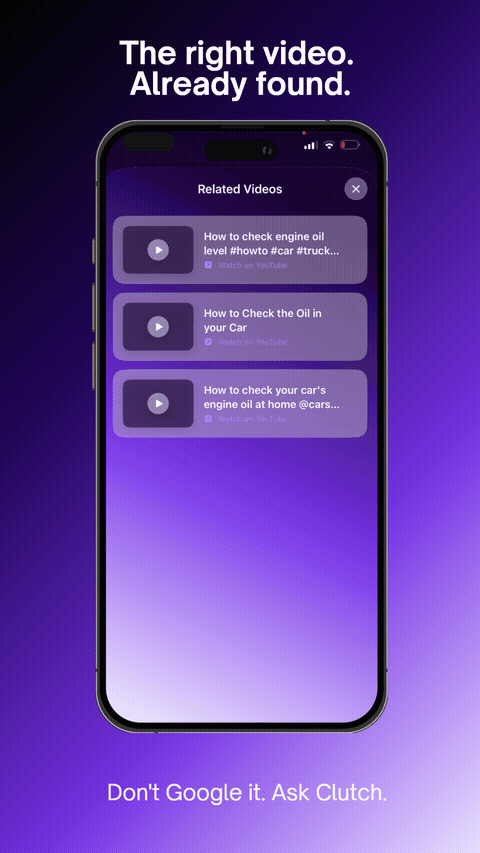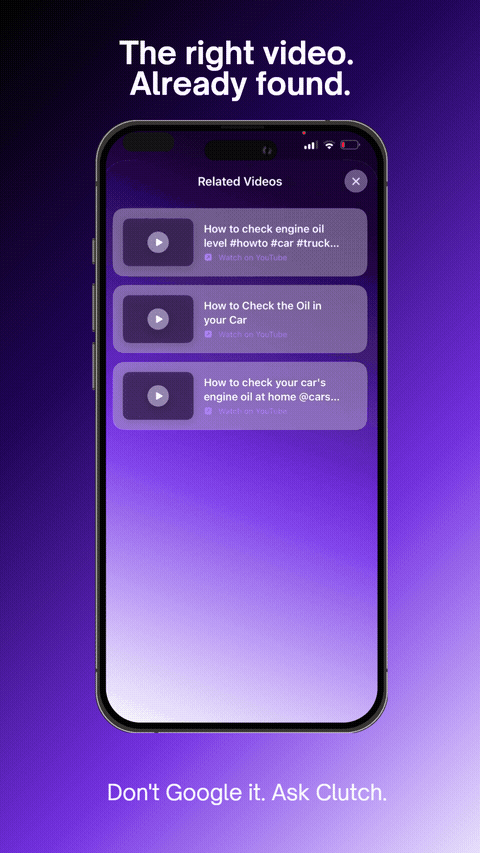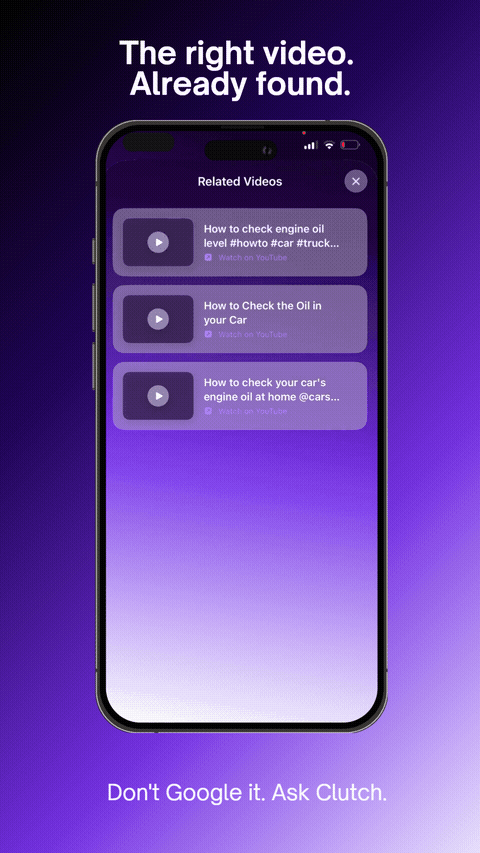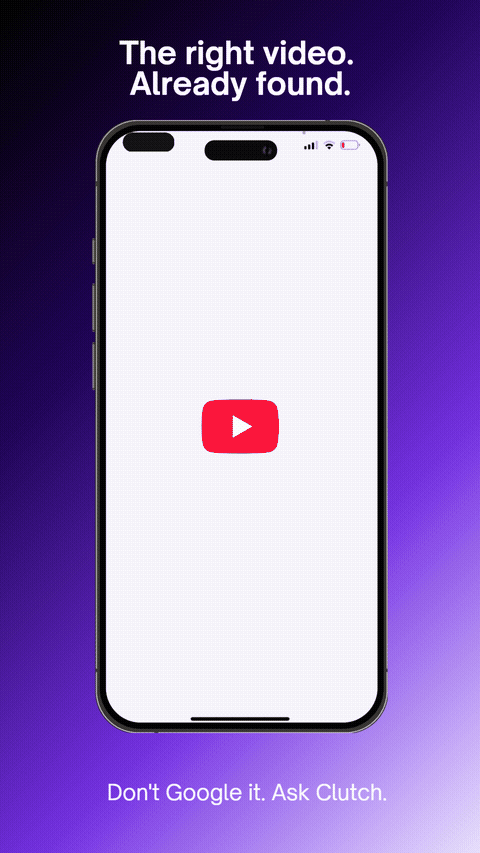
The right video. Already found.
-
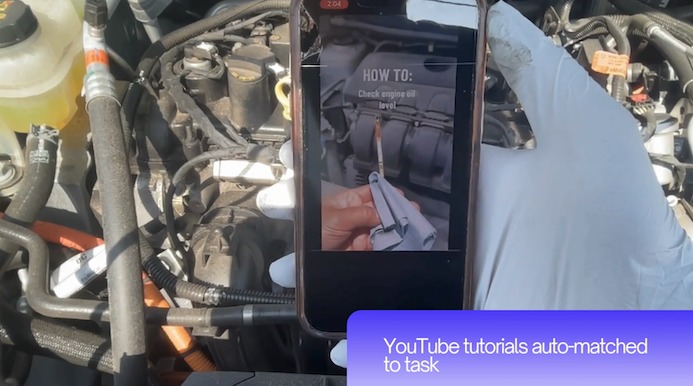
YouTube tutorials auto-matched to your task via YouTube Data API v3
-

Ray-Ban Meta Wayfarer streams live video to Clutch via Bluetooth
-
End-to-end architecture: glasses → Cloud Run → Gemini Live API → tools




Inspiration
We've all been there: you're under the hood of your car with greasy hands, trying to follow a 14-minute YouTube video that has 3 minutes of actual content. You can't scroll, you can't pause, and you definitely can't hold your phone and a wrench at the same time.
Enterprise AR platforms like PTC Vuforia solve this with holographic step-by-step overlays — but they cost thousands and require pre-authored content. Consumer smart glasses like Meta's Ray-Ban line can see your environment, but ask "how do I check my oil?" and you get a paragraph of text. No structured steps. No images. No progress tracking.
Nobody has bridged the gap: glasses that see your task → AI that generates structured guidance → multimedia steps delivered to your phone. That's Clutch.
What it does
Clutch is an AI agent that sees real-world tasks through Ray-Ban Meta smart glasses (or a phone camera) and provides step-by-step how-to guidance with voice narration, AI-generated reference images, and YouTube tutorials.
You put on your glasses, ask a question, and Clutch:
- Sees what you're looking at through the camera in real-time
- Generates step-by-step instructions with Gemini 2.5 Flash
- Creates AI reference images for each step using Imagen 4 Fast (4 images in parallel, ~5 seconds)
- Finds relevant YouTube tutorials matched to your task
- Guides you through each step with voice narration
- Annotates objects in your camera view on request ("circle the dipstick")
- Switches languages mid-conversation (English, Spanish, Vietnamese, French, Chinese)
- Recommends products you might need for the task with store info and pricing
- Exports steps as a PDF to save for offline use
All in real-time. All voice-controlled. All while your hands are busy doing the actual task.
How I built it
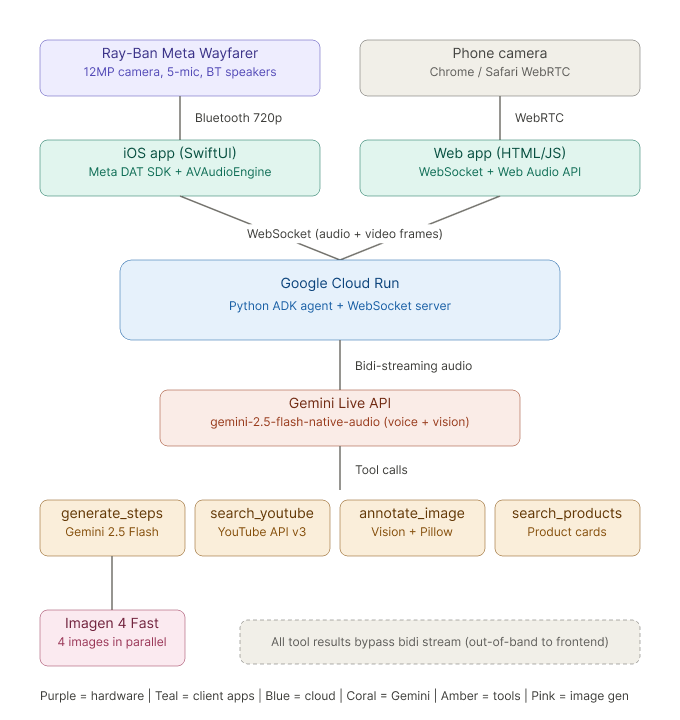
Backend (Python on Google Cloud Run):
The core is a Google ADK agent connected to the Gemini Live API via bidirectional WebSocket streaming. The agent has a system prompt with strict rules for concise voice responses and five tools: generate_steps (creates structured how-to steps + Imagen 4 images), search_youtube (finds relevant tutorials via YouTube Data API v3), annotate_image (highlights objects in camera frames using Gemini Vision + Pillow bounding boxes), search_products (recommends nearby products for the task), and advance_step (signals the frontend to move to the next step).
A critical architectural decision was the out-of-band pattern: all tools that return heavy payloads (base64 images, video data) store results server-side and return only lightweight summaries through the bidi stream. The server intercepts these summaries, retrieves the full data, and forwards it directly to the frontend via WebSocket — bypassing the bidi stream's size limits entirely.
iOS App (SwiftUI): The companion app uses the Meta Wearables DAT SDK to stream 720p/30fps video from Ray-Ban Meta Wayfarer glasses via Bluetooth. It captures audio at 16kHz PCM, routes playback to Bluetooth speakers, and displays the full wizard UI with step navigation, AI images, YouTube cards, product recommendations, and annotation overlays.
Web App (HTML/JS): A single-page web app that works in any browser as a fallback. Uses WebRTC for camera access and WebSocket for real-time communication with the backend. Features the same wizard UI, chat interface, voice spectrum visualization, language selector, and PDF export.
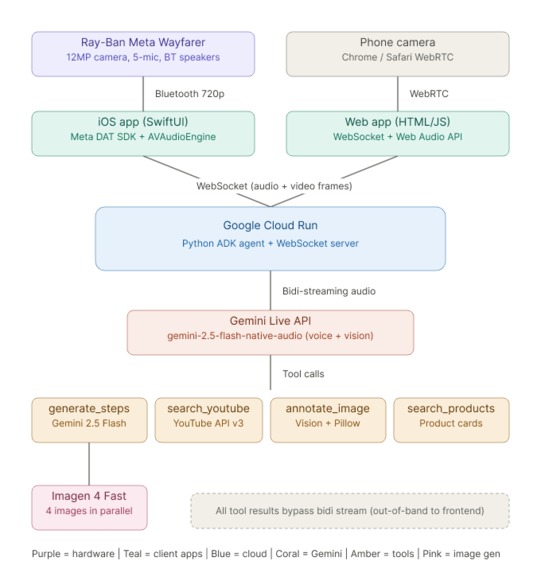
Architecture
Ray-Ban Meta Wayfarer (12MP camera, 5-mic array, BT speakers)
↓ Bluetooth (720p/30fps via Meta Wearables DAT SDK)
iPhone Companion App (SwiftUI) / Chrome Web App (WebRTC)
↓ WebSocket
Google Cloud Run (Python ADK Agent)
↓ Gemini Live API (bidi-streaming audio + vision)
↓ Tools:
→ generate_steps (Gemini 2.5 Flash + Imagen 4 Fast parallel)
→ search_youtube (YouTube Data API v3)
→ annotate_image (Gemini 2.5 Flash Vision + Pillow)
→ search_products (product recommendations)
→ advance_step (wizard navigation)
Challenges I ran into
Bidi stream size limits: The Gemini Live API crashes with 1008 errors when tool responses exceed its WebSocket message size limit. Returning base64 images through the stream was impossible. The solution — storing payloads out-of-band and intercepting tool responses server-side — became the architectural backbone of the entire app.
Model hallucination of tool calls: The Gemini model sometimes says "I've highlighted it" without actually calling the annotation tool. The user sees nothing. Stronger prompting helped but didn't eliminate the issue. This is a fundamental challenge of building on real-time LLM APIs.
Model deprecation mid-hackathon: Google deprecated gemini-2.0-flash-exp-image-generation during the build. I had to migrate to gemini-2.5-flash-native-audio models, which required discovering that only specific preview versions support both bidirectional streaming AND function calling.
API instability: The Gemini Live API goes through periods where connections open but audio isn't processed. No errors — just silence. Building a reliable demo on top of intermittent infrastructure required patience, multiple takes, and resilience.
Accomplishments that I'm proud of
- Built a complete end-to-end system — glasses → phone → cloud → AI → multimedia output — as a solo developer in 12 days
- Solved the bidi stream size limit with an elegant out-of-band pattern that works for all tool types
- Achieved real-time object annotation from live camera frames with labeled bounding boxes
- Generated 4 AI reference images in parallel in ~5 seconds using Imagen 4 Fast
- Cross-lingual support that switches mid-conversation seamlessly
- Both native iOS app with glasses integration AND web app fallback for any browser
What I learned
- The Gemini Live API is incredibly powerful for real-time multimodal interaction but requires careful architecture to work around its constraints
- LLM tool calling reliability is still an unsolved problem — prompt engineering can only do so much
- Building on bleeding-edge APIs means adapting constantly as models get deprecated and behavior changes
- The gap between "AI can do this" and "AI reliably does this every time" is where all the engineering happens
What's next for Clutch
- Auto-advancing steps via voice detection
- Real Google Shopping API integration (currently mock data)
- Spatial AR overlays when glasses hardware supports it
- Collaborative mode — an expert watches your glasses feed remotely
- Egocentric learning — record yourself completing a task, extract it into a reusable how-to for others
Built With
- css
- gemini
- gemini-2.5
- gemini-2.5-flash
- gemini-live-api
- gemini2.5flash
- geminiliveapi
- google-adk
- google-cloud
- google-cloud-run
- googleadk
- googlecloudrun
- html
- image-4-fast
- imagen4fast
- javascript
- meta-wearables
- meta-wearables-dat-sdk
- metawearablesdatsdk
- pillow
- python
- swiftui
- websocket
- youtube-data-api
- youtubedataapi


Log in or sign up for Devpost to join the conversation.