-
-
Homepage of Cluster AI
-
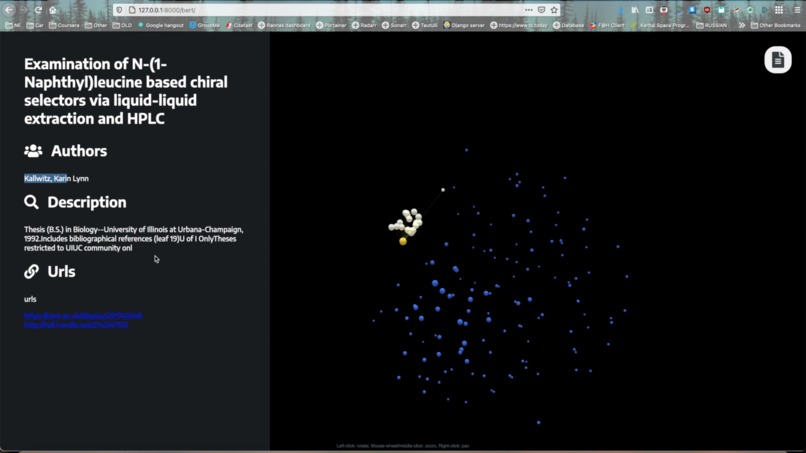
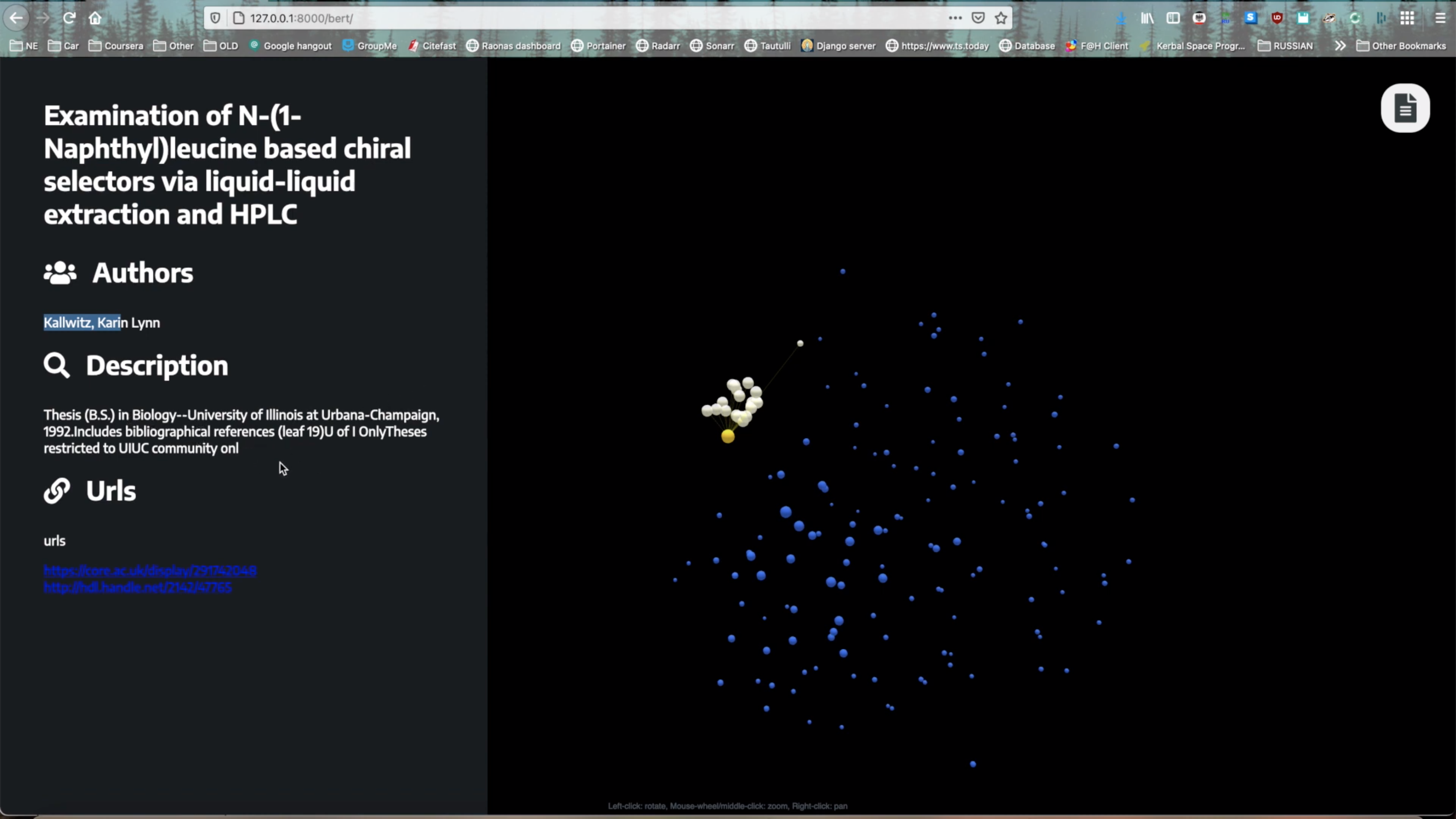
Visualization of Research Papers
Inspiration
Search engines like Google Scholar make it easy to find research papers on a specific topic. However, it can be hard to branch out from a general position to find topics for your research that need to be specified. Wouldn’t it be great to have a tool that not only recommends you research papers, but does it in a way that makes it easy to explore other related topics and solutions to your topic?
What it does
Users will input either a text query or research paper into Cluster AI. Cluster AI uses BERT (Bidirectional Encoder Representations from Transformers), a Natural Language Processing model, in order to connect users to similar papers. Cluster AI uses the CORE Research API to fetch research articles that may be relevant, then visualizes the similarity of these papers in a 3d space. Each node represents a research paper, and the distances between the nodes show the similarity between those papers. Using this, users can visualize clusters of research papers with close connections in order to quickly find resources that pertain to their topic.
Test Cluster AI here
Note: Running on CPU based server, deploying your own Django server using instructions in the Source Code is highly recommended. Demo may have delays depending on the query and number of users at any given point. 10-100 papers, but up to 20 papers requested in the query will be optimal.
Check out the Source Code!
How we built it
We used a multitude of technologies, languages, and frameworks in order to build ClusterAI.
- BERT (Bidirectional Encoder Representations from Transformers) and MDS (Multidimensional Scaling) with PyTorch for the Machine Learning
- Python and Django for the backend
- Javascript for the graph visualizations (ThreeJS/WebGL)
- Bootstrap/HTML/CSS/Javascript for the frontend
Challenges we ran into
The CORE Research API did not always provide all the necessary information that was requested. It sometimes returned papers not in English or without abstracts. We were able to solve this problem by validating the results ourselves. Getting the HTML/CSS to do exactly what we wanted gave us trouble.
Accomplishments that we're proud of
We worked with a state-of-the-art natural language processing model which successfully condensed each paper into a 3D point.
The visualization of the graph turned out great and let us see the results of the machine learning techniques we used and the similarities between large amounts of research papers.
What we learned
We learned more about HTML, CSS, JavaScript, since the frontend required new techniques and knowledge to accomplish what we wanted. We learned more about the BERT model and dimensionality reduction. The semantic analysis of each paper’s abstract the BERT model provided served as the basis for condensing each paper into 3D points.
What's next for Cluster AI
We can add filtering to the nodes so that only nodes of a given specification are shown. We can expand Cluster AI to visualize other corpora of text, such as books, movie scripts, or news articles. Some papers are in different languages; we would like to use an API to convert the different languages into a person’s native language, so anyone will be able to read the papers.





Log in or sign up for Devpost to join the conversation.