-
-
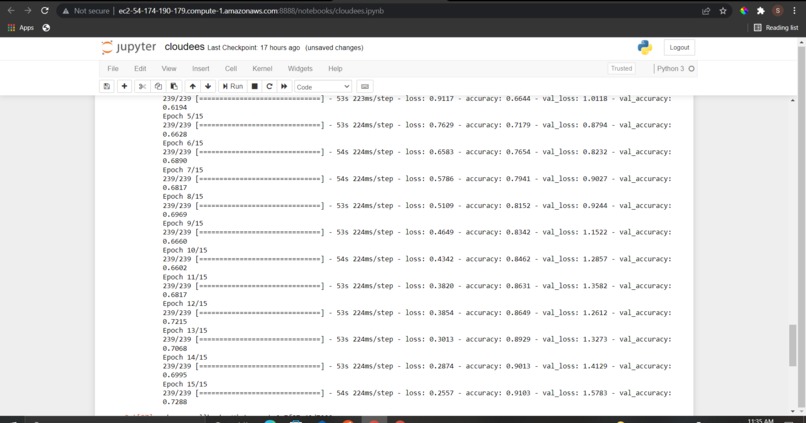
training model
-

(flutter app) Cloudees flutter app homescreen
-

(flutter app) clicking a picture
-

(flutter app) getting prediction
-
(flutter app) more options
-
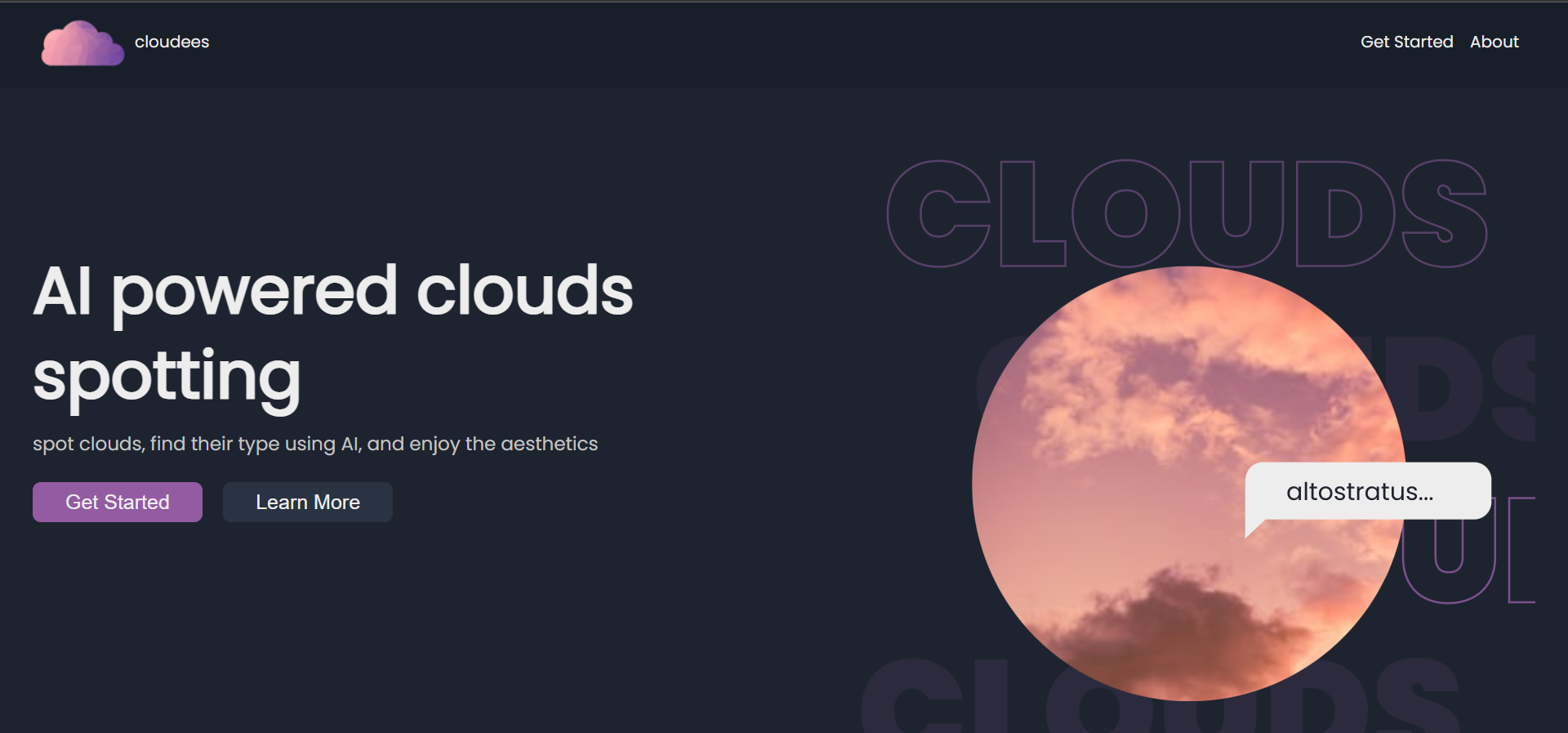
(website) landing page
-

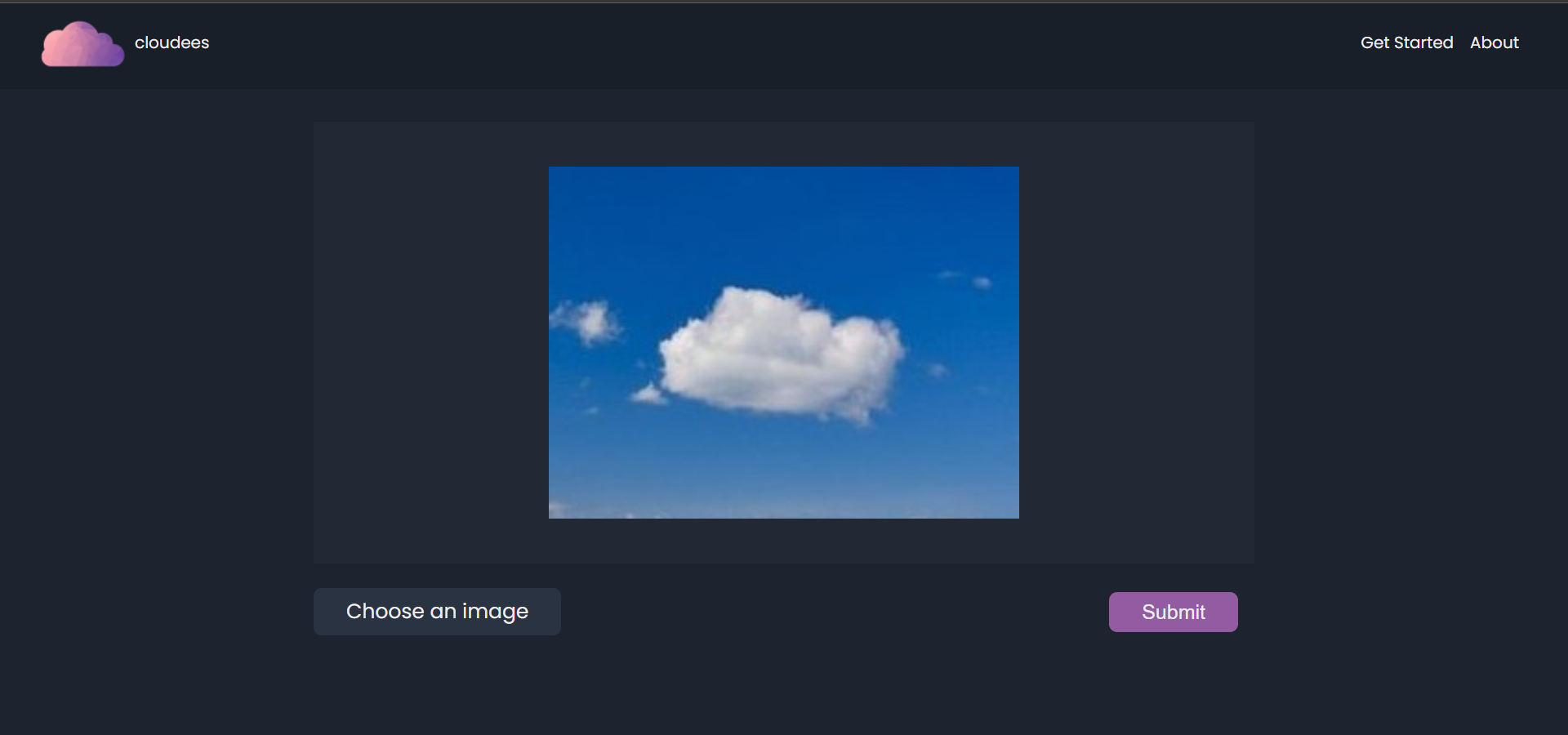
(website) upload image
-
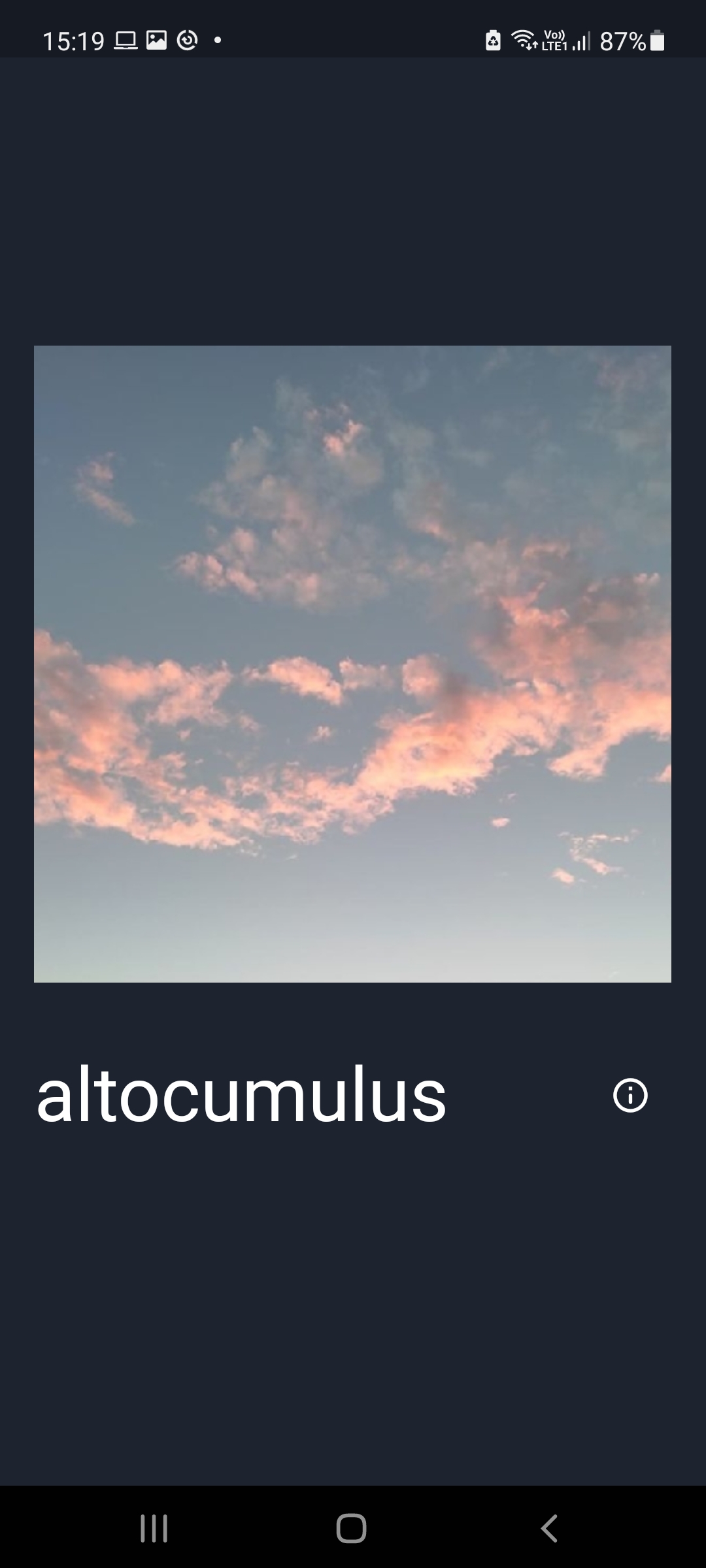
(website) get results


⚡Inspiration
We as a team are very fond of aesthetics, especially when the nature becomes an integral part of it, when it carries the aesthetics with it. Clouds are one such perfect example. They come in various patterns, color, shapes and sizes, and looking at them is very soothing. Moreover, there is a whole field of study, which is a sub category of Meteorology, referred as Nephology, meaning the scientific study of clouds. So both curiosity and study potential drove us towards this project. Also when we found out that the clouds that we in the sky are not just randomized completely, but instead they are properly categorized in various categories based on their properties such as size, shape, color, height and more, we were pretty fascinated! Even if you know specific properties of a specific kind of cloud, making a calculated guess always might be tedious and not accurate enough. This is what we had for our inspiration. So we ended up making something that'll let the users classify the clouds into categories. Presenting you our deep learning model project, Cloudees
⚡What it does
Cloudees is a whole platform on its own, powered by deep learning models made using Tensorflow libraries including Keras, by optimizing the powers of Habana Gaudi DL1-EC2 instances. Cloudees is available on web with a Flask backend, and on android mobile platform as a Flutter application. A user would need to either click a picture of the sky, or upload an existing one. Cloudees sends the image to our Deep Learning model hosted as a flask API, in form of a POST request, with the image file as an attachment. The API resize the image accordingly and performs the prediction. The app thereafter, receives the response, the most probable category the cloud belongs to, and portrays that to our user in a visually appeasing manner.
⚡How we built it
For our kind of idea to work, we needed huge amount of images of sky, of different kinds of clouds and in different orientations and scaling. So we handpicked about initial 500 images, and categorized them into 9 major cloud categories, namely:-
Altocumulus
Cirrus
Cirrocumulus
Cirrostratus
Cumulonimbus
Cumulus
Nimbostratus
Stratocumulus
Stratus
Here's a typical look of each kind of cloud

After doing this, we did data augmentation through rotating, scaling and applying sunset overlays, and then our data was ready to be trained. We had 9500+ pictures to train, which we trimmed to exactly 1000 images per class (a total of 9000), for fair training.
For training, we used Habana Gaudi dl1.24xlarge instance type and connected it to our local machine via ssh. For setting it up, we installed python 3.7 into it, activated conda environment and installed jupyter notebook package. Then, we used image_dataset_from_directory method of tensorflow which doesn't require you to convert the images into numpy manually, instead it all happens in the background. Then, we split the data into test and train with a conventional ratio of 20:80. We trained it using Convolutional Neural Networks, which is preferred for image classification problems specifically. With the error function being Sparse Categorical Cross Entropy, final activation function being relu, image size being 224x224 pixels over 3 channels (RGB), we normalized the pixel value and reached our maximum accuracy of 93%, and a maximum validation accuracy of 82.3% on test dataset. After our model was built, we saved it as our Keras model for the Flask API calls. For
The Flask API and the Flask web app are hosted collectively on AWS EC2 instance, and the flutter app makes direct post request to the Flask API to get the prediction data.
⚡Challenges we ran into
- We actually faced lot of challenges, a major one being DATA. There was no specific data available for the types of clouds, except the satellite images data. But, that wasn't even close to what we needed, so as a team we decided that we'll make our own data. And we literally spend around 30% of the hackathon to just make and refactor our data properly. We handpicked images, and put them into categories by our knowledge, and augmented the data to be well enough to train a deep learning model nicely, and were having 9000 images to train.
- One more major challenge was our inexperience with Machine Learning, Deep Learning and Habana Gaudi accelerators. All of these topics were totally new to us, so we had to start from the start. And that was indeed a bit time consuming in itself, but we got through it.
- We also were having some issues regarding the loss factor being so high, so we had to spend quite a long time to tune it correctly and to find the most appropriate configurations for the same.
⚡Accomplishments that we're proud of
- We're very proud of completing it and getting everything to work within the time frame.
- We're also proud that we got ourselves kind of accustomed to how deep learning algorithms work and how Habana Gaudi accelerators can be really helpful for fast and cheaper processing of data and model training.
- Our decision to make the model available for prediction over 2 platforms [web and mobile app] as an addition was also a bit time taking to implement, but we managed it quite nicely and are really proud of that.
⚡What we learned
Being very honest here, this project was our first major Deep Learning project, since before it we didn't really know much about how ML and DL work in general, and how to code and make our own models.
So, we learnt almost everything related to that. Also, we knew a bit about EC2 instances, but the DL1 based EC2 instances was definitely a very interesting thing to learn, and using Habana Gaudi accelerators also gave us an idea of its potential in the future.
We also learnt things related to Flask and Flutter, like making a REST API using flask, deploying it, deploying the web application, and working with POST requests in both python and dart.
As a fun part, we decided to compare the speed of training on google colab and DL1 EC2 instances, and we found out that on DL1 instances, it was more than 9 times faster as compared to colab.
⚡What's next for Cloudees
We have a lot of things planned for the future, including:-
- Availability of Cloudees on more platforms like Windows, as a Discord and Slack bot, and more
- We eventually would need more data to train our model and make it better, so we would hopefully be working on that. Maybe through crowdsourcing, we can let people upload their images of clouds and then put it in our next training round.
⚡ Try it out
- Web application: http://44.201.144.94:8080/
- Flutter application: https://play.google.com/store/apps/details?id=com.zanie.cloudees
- Alternatively, you can also send post request to api directly, wrap your image as a file under "sent_file" header and post it to this url, http://44.201.144.94:8080/predict
Built With
- amazon-ec2
- amazon-web-services
- dart
- deep-learning
- dl
- dl1-instances
- flask
- habana-gaudi
- http
- keras
- python
- tensorflow




Log in or sign up for Devpost to join the conversation.