-
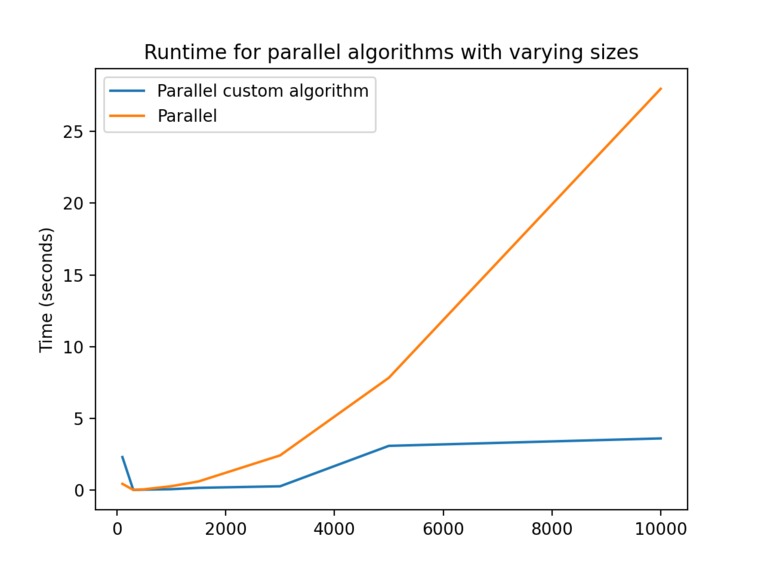
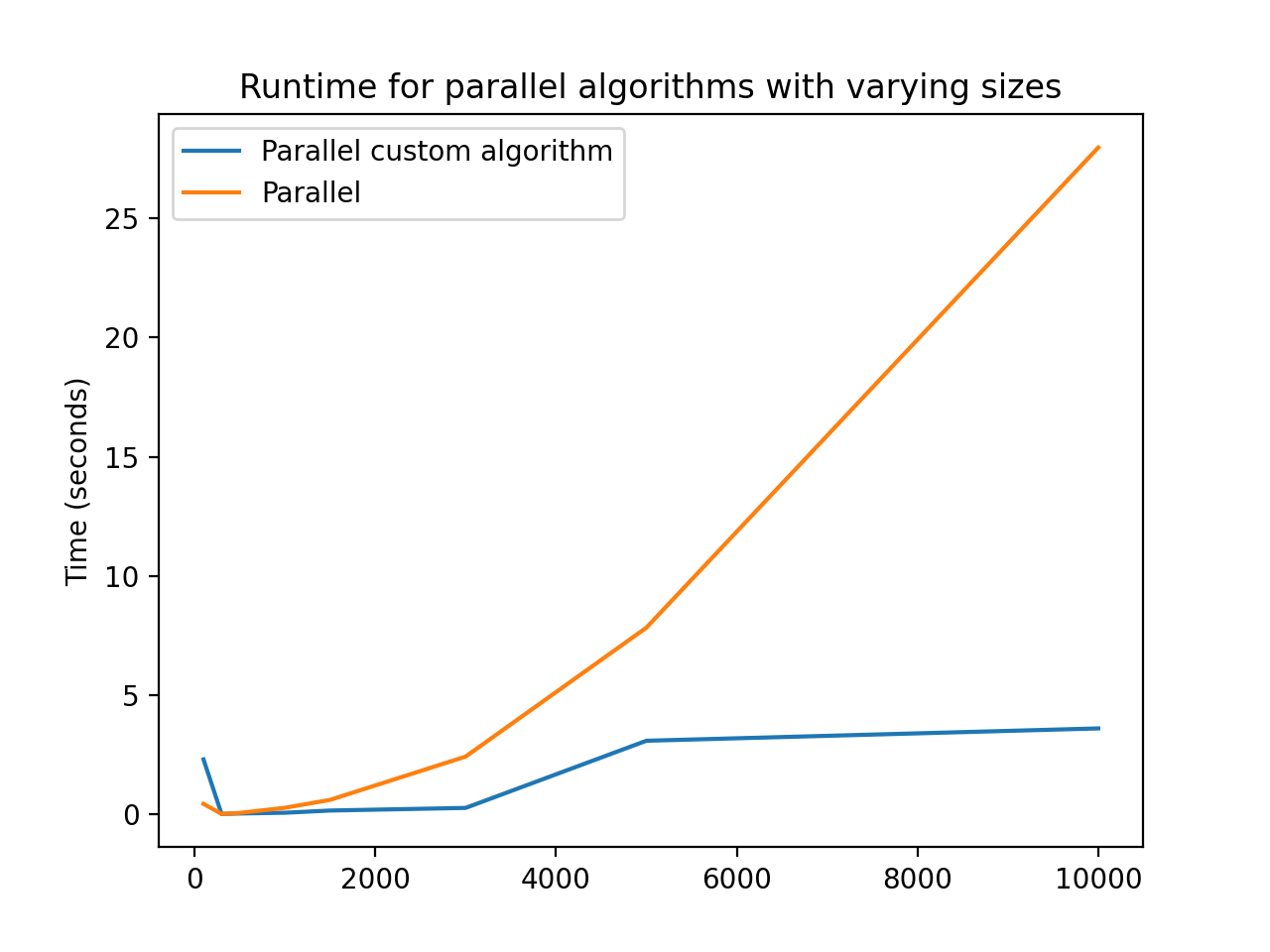
Ran on a MacBook Pro, 2.2GHz 6-core i7 (4.2GHz boost), 16GB DDR4-2400
-
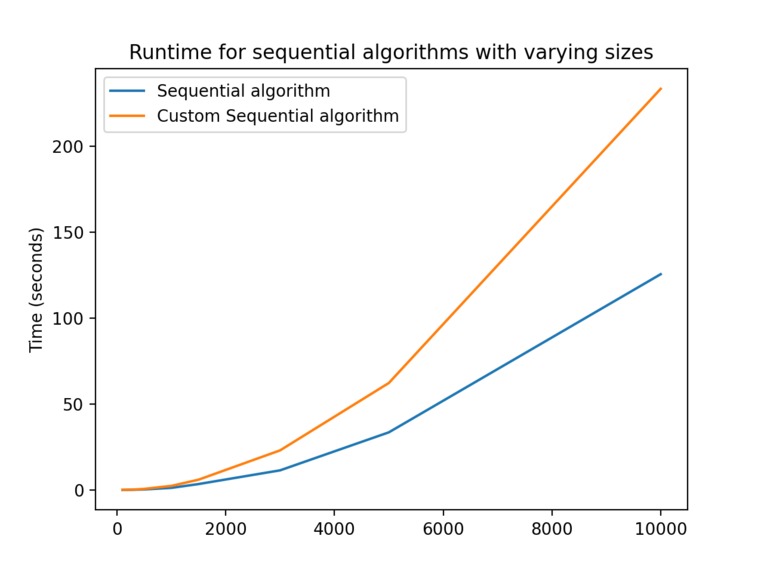
Ran on a MacBook Pro, 2.2GHz 6-core i7 (4.2GHz boost), 16GB DDR4-2400
-
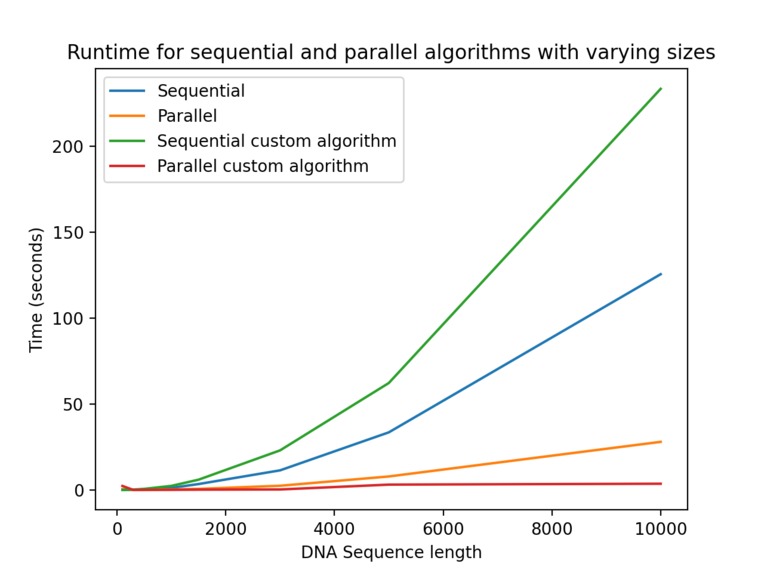
Ran on a MacBook Pro, 2.2GHz 6-core i7 (4.2GHz boost), 16GB DDR4-2400
Inspiration
Having learned about parallel programming, we decided to put our skills to the test and implement a novel parallel edit distance (Levenshtein Distance) algorithm.
What it does
It finds the minimum amount of edits needed to change one DNA sequence to another, which is a metric in determining the similarity of two DNA sequences.
How we built it
We built it using Python, Numba, Numpy, and the concepts that were taught in our parallel programming course to be able to fully take advantage of today's multi-core processors and parallel computers.
The implementation was based on the following algorithm: Sadiq, M.U., Yousaf, M.M., Aslam, L. et al. NvPD: novel parallel edit distance algorithm, correctness, and performance evaluation. Cluster Comput 23, 879–894 (2020). https://doi-org.myaccess.library.utoronto.ca/10.1007/s10586-019-02962-w
Challenges we ran into
Numba was a bit difficult to learn; unlike native Python, some variables had to be type annotated, and if it wasn't it would throw errors. We wanted to optimize this to run on a GPU so it could be even faster, but we aren't very familiar with CUDA.
Accomplishments that we're proud of
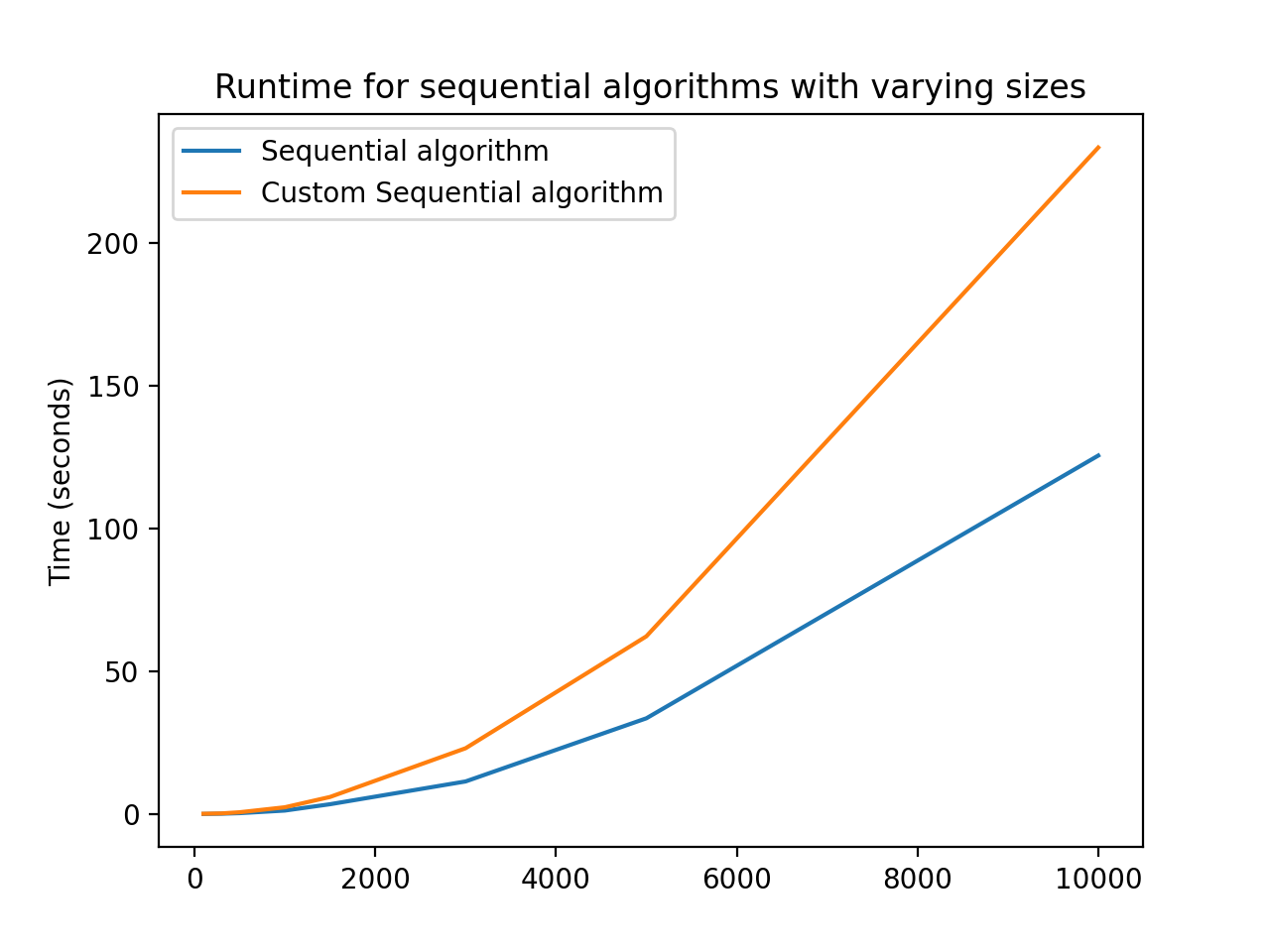
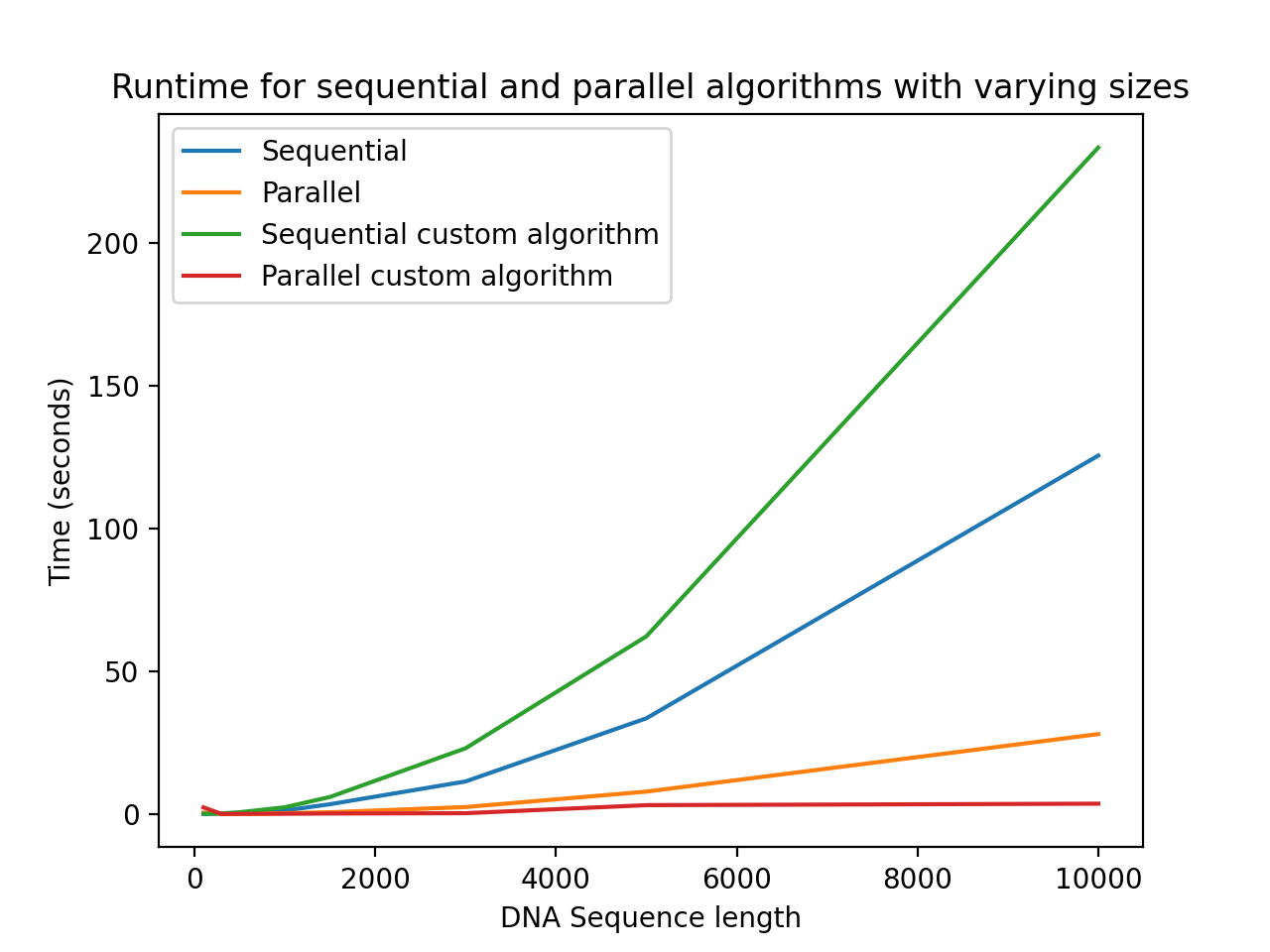
The custom algorithm indeed did greatly speed up computation compared to the regular algorithm, even when the regular algorithm was parallelized.
What we learned
How to parallelize in Python, graphing with Numba.
What's next for Closest DNA sequence
Learn CUDA so we can have it run on a GPU to optimize performance.

Log in or sign up for Devpost to join the conversation.