-
-
CloseIt Analysis Page 1
-
CloseIt Analysis Page 2
Inspiration
One of the most burdensome parts of being a student today is finding a job that a) we like and b) that likes us. With the internet and GenAI, it's become increasingly easy to learn new skills--and increasingly difficult to stand out. But while it's up to the individual to bolster their resume, we thought that if we could design a software that would train people for the interview—the final, winner-takes-all stage of the job application process—we'd be doing a service to ourselves and to others. If recruiters use AI when searching through applicants, there's no reason that applicants shouldn't use AI to make themselves stand out to recruiters (in a fair and honest way).
What it does
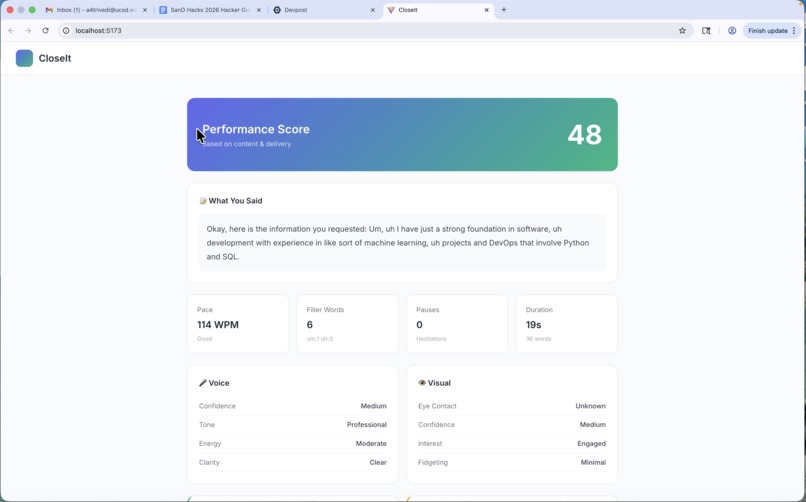
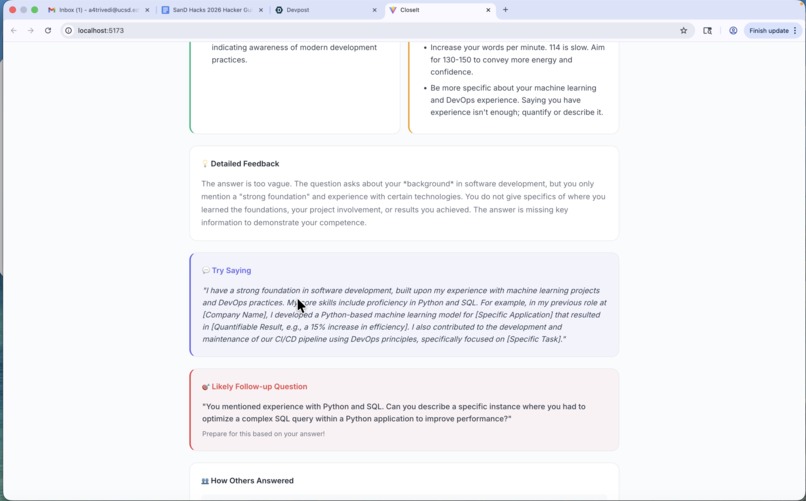
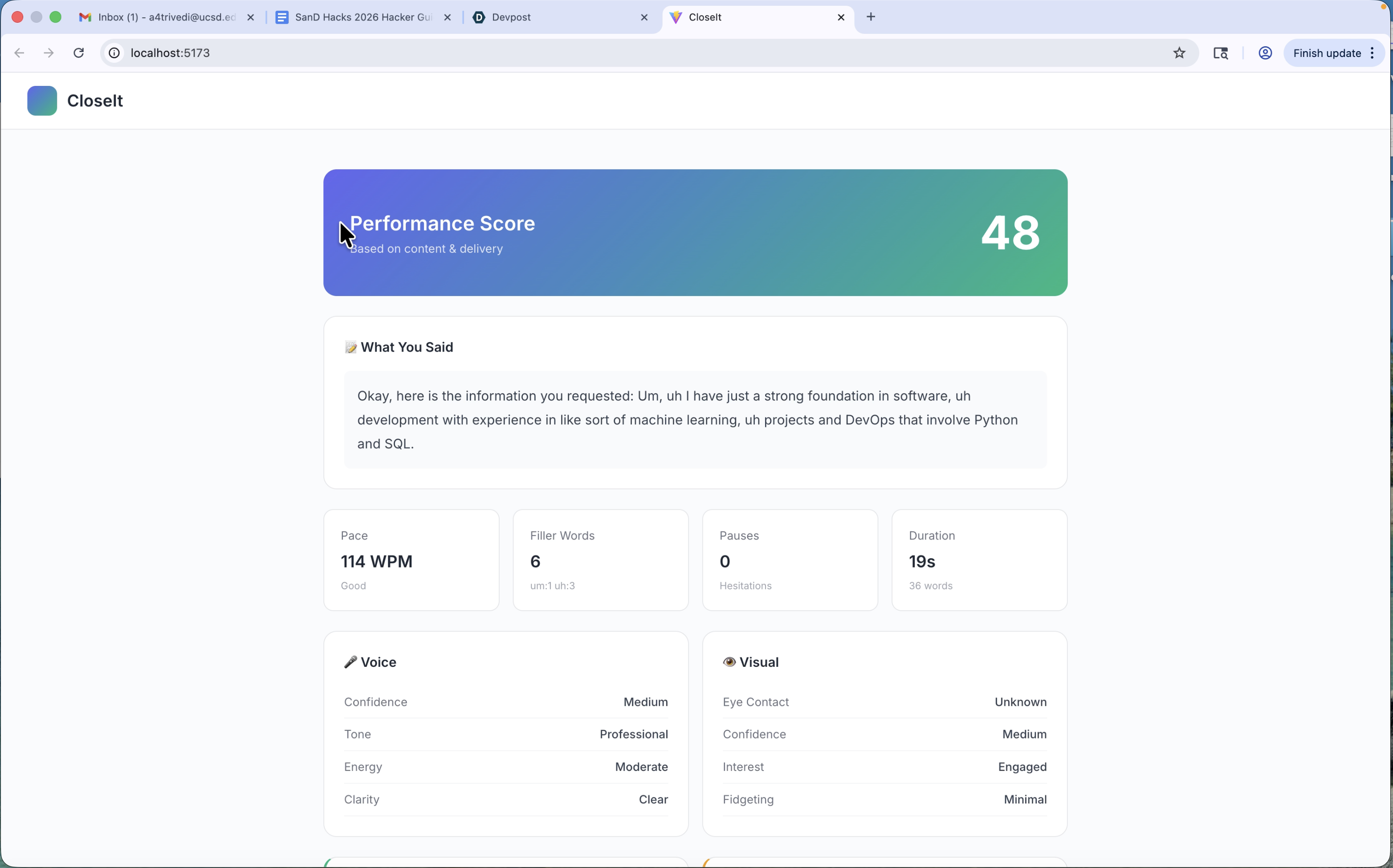
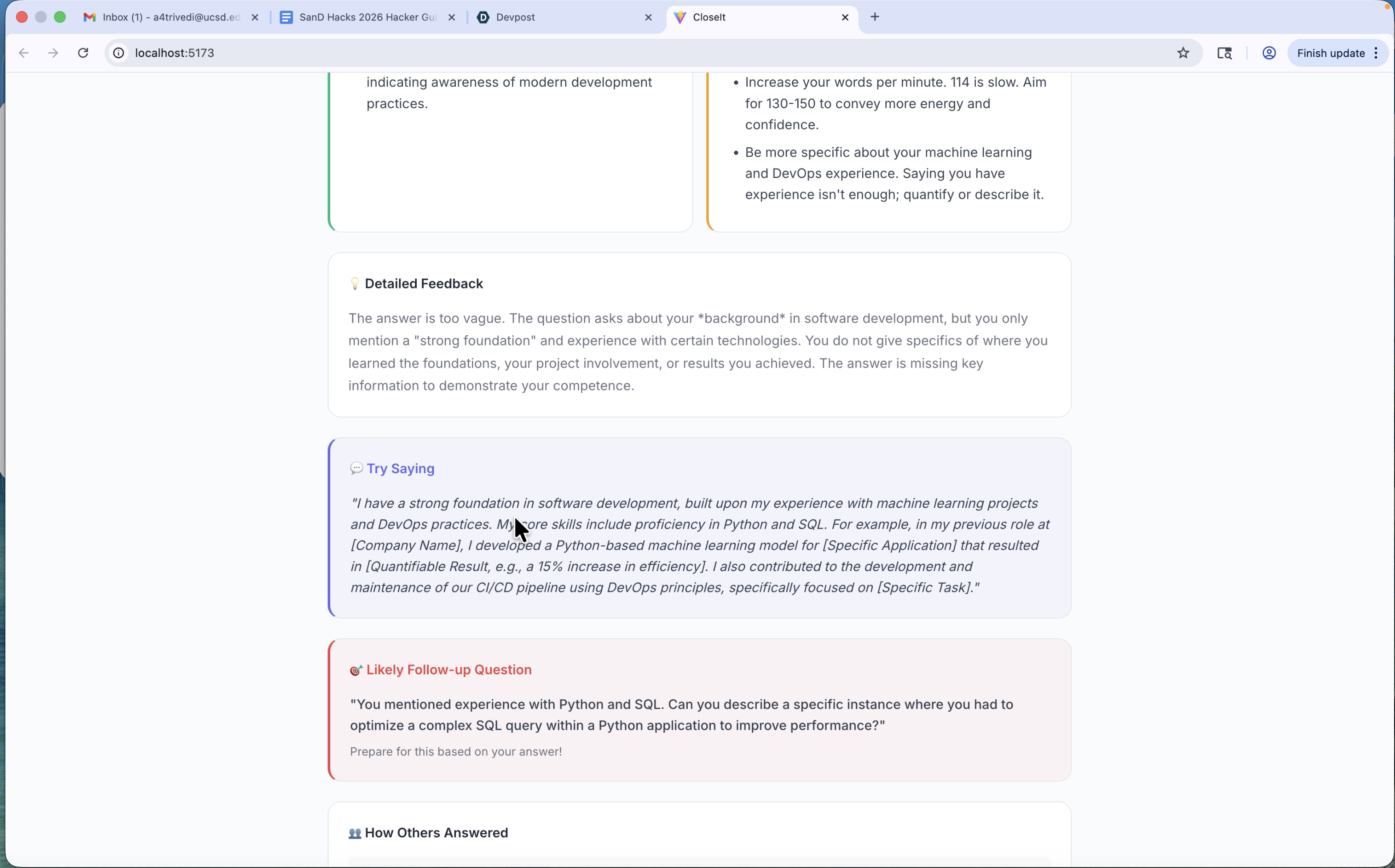
CloseIt starts with an inputted resume from the user, from which relevant interview questions are then generated. The user will see these questions displayed on screen, and has the opportunity to have then spoken as well. They'll record a brief (<60s) response to the interview, and CloseIt will respond with a detailed analysis. Aside from the content of the response, it gives feedback on how the user delivered their response using visual and tone indicators. This includes fidgeting, eye contact, confidence, energy, clarity, interest level, WPM, and how many filler words were used. After combing through the content and delivery of the response, it gives a complete analysis of the response with strengths, weaknesses, suggestions, possible follow up questions, and how others responded to similar questions (which is simulated for now).
How we built it
After we were set on the idea, we divided the project into different stages from which the inputs (the resume and later the responses) were to flow. This meant first creating a way for Gemini to read resumes and output their responses. The second stage, and probably the most time-intensive, was creating and training a model to analyze the users body language. At first, this was through an EyePop.AI model. We took hundreds of photos of ourselves to train it, which in sum ran the gamut of what a user would look like an interview. The data from the interview was then analyzed and sent back to Gemini, which displays it and offers strengths and areas for growth. However, since EyePop's models didn't really work for us (which I'll elaborate on in a moment) we had to pivot to using Gemini for the visual aspects of the project instead. The video is passed to Grok then Gemini for speech-to-text and text analysis respectfully, before being returned to the user.
Challenges we ran into
One of the major challenges that we ran into was the use of EyePop.AI. Before we'd really tested that a model could be created and trained using EyePop, we designed nearly every other part of CloseIt. So when after 8+ hours of programming we realized we couldn't upload a single photograph to the AI, we were pretty worried. We didn't know if that meant that we should take the parts that we had already and combine them with another object-identifying AI like YOLO, or pivot altogether. For a few hours, we gained false hope when we realized we could upload pictures from an incognito tab. But after sinking even more time into training the model, we then realized that their API keys didn't work.
From there, we realized we had to pivot. There wasn't enough time to create a new project from scratch, but there was also no chance we could get EyePop to work. So we decided to use Gemini for the video analysis too. This meant shaving off most of the work we did to provide EyePop with the relevant frames. Most of our energy in those first 7-8 hours involved taking the user's response, stopping the video and immediately restarting it, passing the old video to our script, breaking it down into specific frames and audio, and passing the frames to EyePop and the audio to Grok. But again, since EyePop didn't work, only the grok component of that was used.
Accomplishments that we're proud of
One thing that we're proud about is the comprehensiveness of the feedback that CloseIt provides. It doesn't just take content of the user's words, but of their expressions and mannerisms too. An interview is just the same. You can't interview a person's words; whether in person or on zoom, knowing how to speak slowly, clearly, and confidently are what separates the CloseIt candidates from the rest.
What we learned
For our entire group, this was our first real hackathon, so the experience of a 2-day coding binge was a new experience in and of itself. Only two of us were friends going into it, but we quickly learned to work cohesively and divided the work fittingly.
I would say that knowing how to work with a team was one of the greatest lessons. Like most classes, CS is usually taught as an individual activity, something that people must learn to do by themselves. Teamwork skills are rarely emphasized in the same way as technical skills. So working with 3 others to create something as multi-faceted as CloseIt was new for all of us. Personally, my favorite part of the project was talking with my teammates about what they built, even if the internal structure of their script had little or nothing to do with my portion of the project.
Another, more technical educational aspect of our project was seeing how different models/ways of looking at an input could create much greater understanding of the input as a whole. When we started out on the project, the only functionality that we were really thinking of was having EyePop tell the user how the visual aspects of their responses could be improved. But after seeing how barren this model was, and how easily EyePop couldn't do what they advertised to do, we decided to add more features for the same end. Specifically in the context of AI, it was interesting to see how different networks that all focus on different fractions of the data could be put together to create a greater whole. For example, Grok's speech-to-text was worse than Gemini's, but Gemini's analysis of the text and the video was better than Grok's. Together, they created something better than could've been made by either one by themselves.
What's next for CloseIt
If we had more time, the first thing that we would change about our project is how it processed the visual component of the interview. What we liked about EyePop when we started was that we thought we'd be able to choose what to measure. When we realized that EyePop wasn't going to work, there wasn't enough time to pivot to another more proven, more complex object-identification software, so the ease-of-access to Gemini was our saving grace. But if we could've restarted, we almost certainly would've used YOLO.
With YOLO, we could pick exactly which features to measure and seen exactly how those features were quantified, contrasted to Gemini which is a bit of a black box. Some matrix that we'd want to measure, would be facial expressions, eye contact, eye direction, blink rate, eyebrow angle, and hand gestures, which in conjunction with textual analysis would've created an even richer picture of how a user would come across to an in interviewer. As Marshall McLuhan said, "the medium is the message". In other words, how you say something is equally important to what's being said. All together, YOLO's visual analysis, Grok's tone analysis, and Gemini's textual analysis would have been able to tell you things such as whether a joke was well-delivered or off putting, by measuring your facial expressions, (e.g. a smile) your tone (e.g. friendly) and what was actually being said (i.e. the joke).
The functionality would've been about the same, but it would've been an even greater opportunity to get an under-the-hood look at how the video input was being processed. But aside from analyzing the video differently we intend on creating features that allow the user to adjust what kind of questions are being asked. If a user is comfortable asking technical questions but nervous about answering more personality-focused ones (e.g. "how would you survive the zombie apocalypse") they could adjust the model to so. In a similar vein, users could get questions that large companies such as Google use in their own hiring process.
The final thing that we would add would be a progress tracker. Any kind of data that's quantifiable can be tracked, and through multiple practices patterns could be inferred.




Log in or sign up for Devpost to join the conversation.