-
-
ClockChain architecture diagram.
-
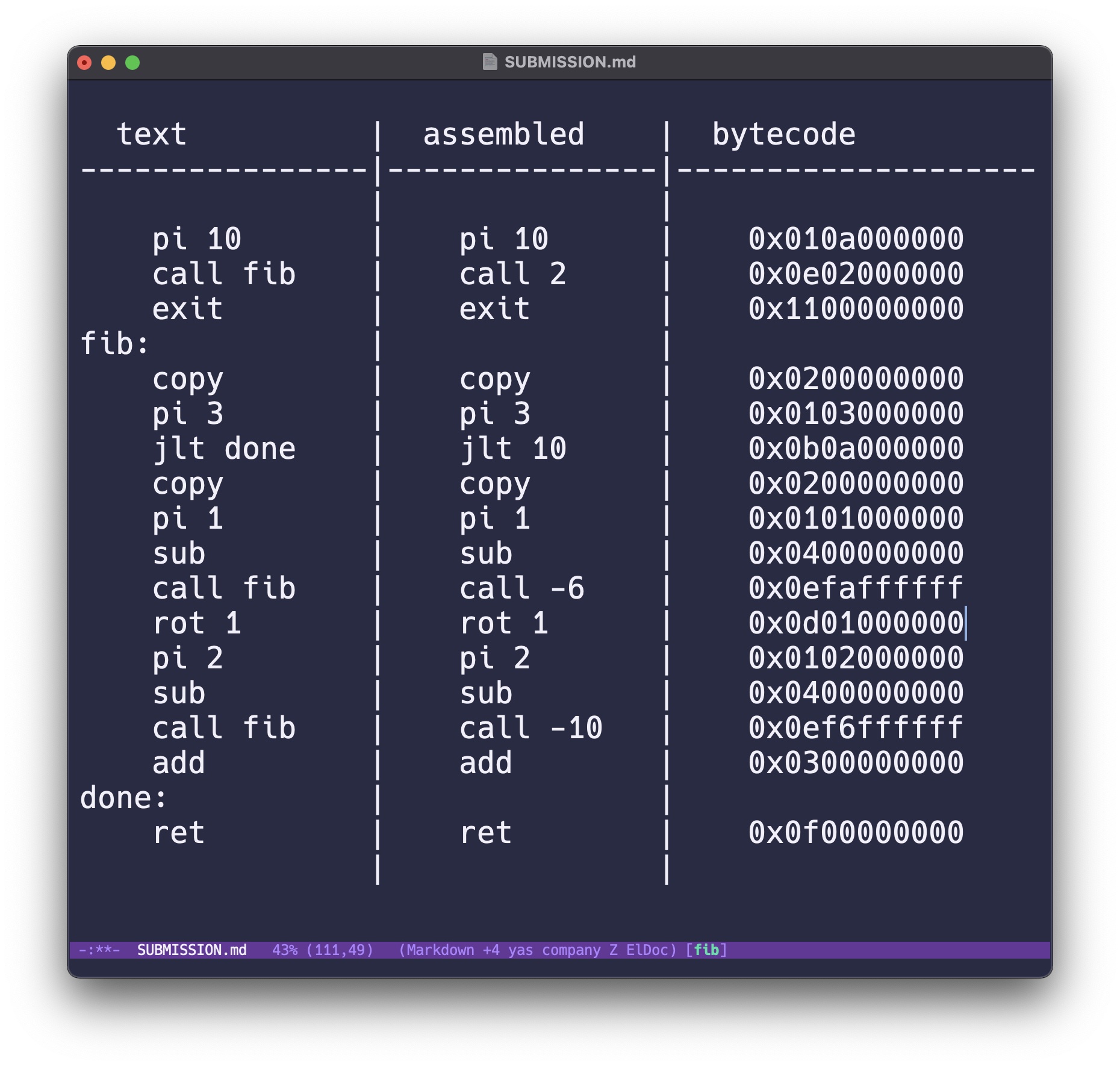
The compilation phases for a ClockChain program.
-
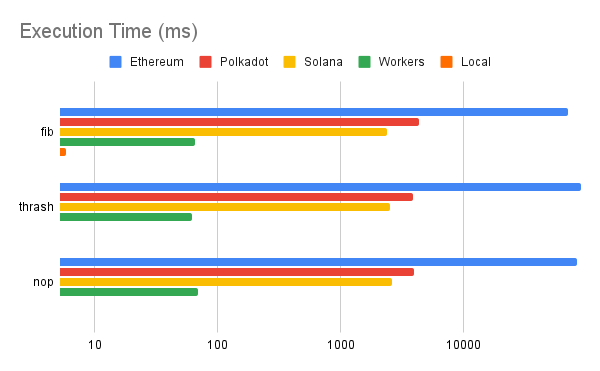
Measured smart contract execution times across platform and task.
-
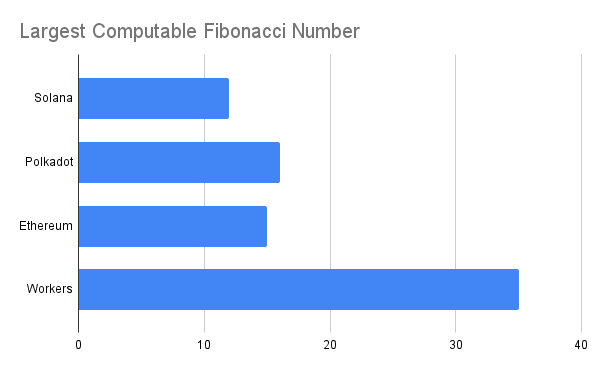
Largest computable Fibonacci number by platform.
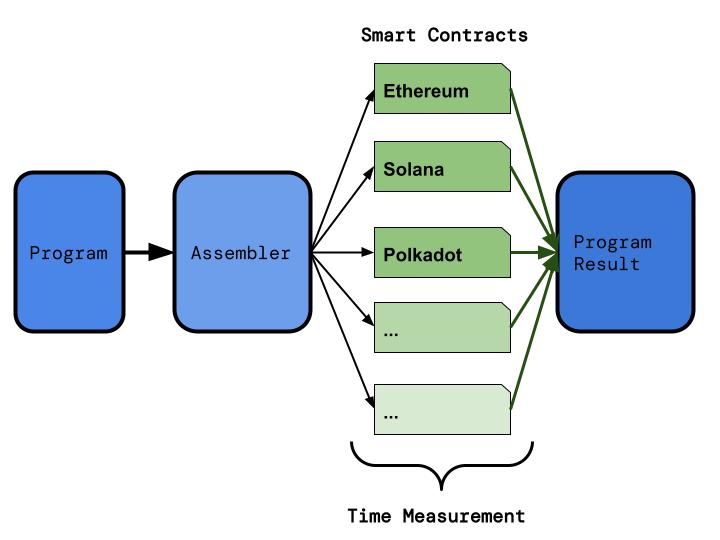
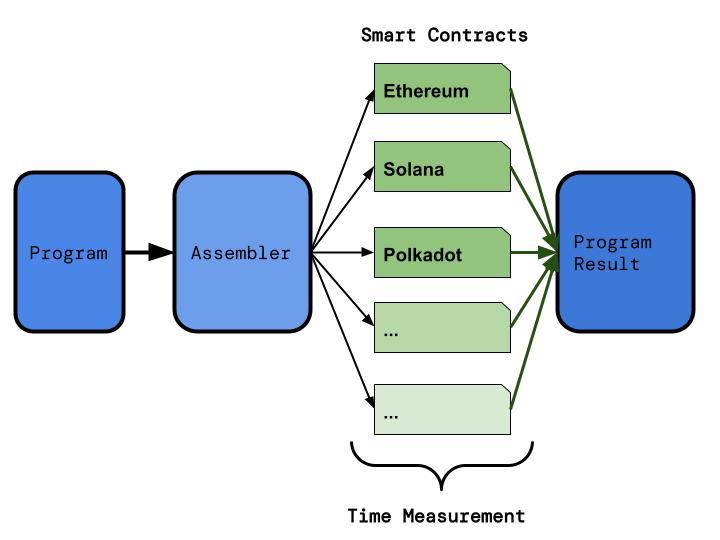
We present a blockchain agnostic system for benchmarking smart contract execution times. To do this we designed a simple programming language capable of running small performance benchmarks. We then implemented an interpreter for that language on the Ethereum, Solana, and Polkadot blockchains in the form of a smart contract. To perform a measurement we then submit the same program to each chain and time its execution.
Deploying new smart contracts is expensive and learning the tooling and programming languages required for their deployment is time consuming. This makes a single blockchain agnostic language appealing for developers as it cuts down on cost and time. It also means that new blockchains can be added later and all of the existing tests easily run after the deployment of a single smart contract.
You can think of this as "a JVM for performance measurements." To demonstrate how this can be used to measure non-blockchain runtimes we also implemented an interpreter on Cloudflare Workers and present some benchmarks of that. Cloudflare Workers was an order of magnitude faster than the fastest blockchain we tested.
Our results show that network and mining time dominate smart contract execution time. Despite considerable effort we were unable to find a program that notably impacted the execution time of a smart contract while remaining within smart contract execution limits. These observations suggest three things:
- Once a smart contract developer has written a functional smart contract there is little payoff to optimizing the code for performance as network and mining latency will dominate.
- Smart contract developers concerned about performance should look primarily at transaction throughput and latency when choosing a platform to deploy their contracts.
- Even blockchains like Solana which bill themselves as being high performance are much, much slower than their centralized counterparts.
Results
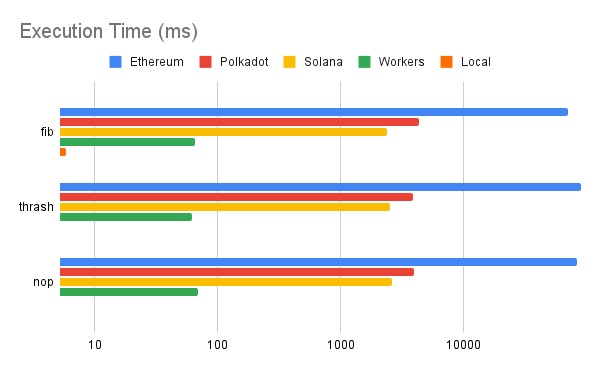
We measured the performance of three programs:
- An inefficient, recursive fibonacci number generator computing the 12th fibonacci number.
- A program designed to "thrash the cache" by repeatedly making modifications to dispirate memory locations.
- A simple program consisting of two instructions to measure cold start times
In addition to running these programs on our smart contracts we also wrote a runtime on top of Cloudflare Workers as a point of comparison. Like these smart contracts Cloudflare Workers run in geographically distributed locations and feature reasonably strict limitations on runtime resource consumption.
To compute execution time we measured the time between when the transaction to run the start contract was sent and when it was confirmed by the blockchain. Due to budgetary constraints our testing was done on test networks.
We understand that this is an imperfect proxy for actual code execution time. Due to determinism requirements on all of the smart contract platforms that we used, access to the system time is prohibited to smart contracts. This makes measuring actual code execution time difficult. Additionally as smart contracts are executed and validated on multiple miners it is not clear what a measurement of actual code execution time would mean. This is an area that we would like to explore further given the time.
In the meantime we imagine that most users of a smart contract benchmarking system care primarily about total transaction time. This is the time delay that users of their smart contracts will experience and also the time that we measure.

Our results showed that Solana and Polkadot significantly outperformed Ethereum with Solana being the fastest blockchain we measured.
Additional observations
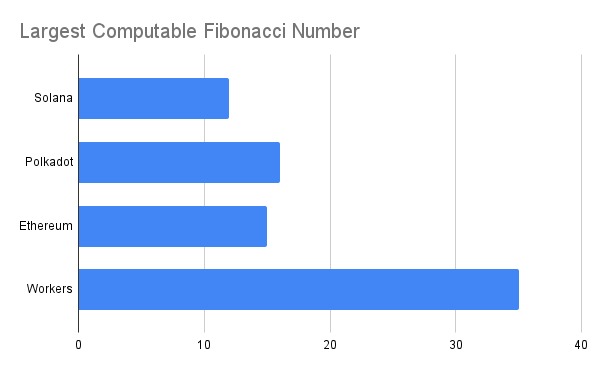
While Solana was faster than Polkadot and Ethereum in our benchmarks it also had the most restrictive computational limits. The plot below shows the largest fibonacci number computable on each blockchain before computational limits were exceeded. Once again we include Cloudflare Workers as a non-blockchain baseline.

The benchmarking language
To provide a unified interface for performance measurements we have designed and implemented a 17 instruction programming language called Arcesco. For each platform we then implement a runtime for Arcesco and time the execution of a standard suite of programs.
Each runtime takes assembled Arcesco bytecode through stdin and prints the execution result to stdout. An example invocation might look like this:
cat program.bc | assembler | runtime
This unified runtime interface means that very different runtimes can be plugged in and run the same way. As testament to the simplicity of runtime implementations we were able to implement five different runtimes over the course of the weekend.
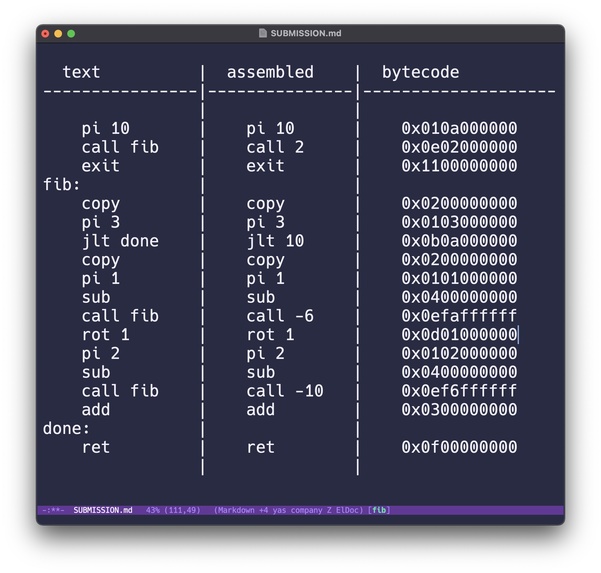
Arcesco is designed as a simple stack machine which is as easy as possible to implement an interpreter for. An example Arcesco program that computes the 10th fibonacci number looks like this:
pi 10
call fib
exit
fib:
copy
pi 3
jlt done
copy
pi 1
sub
call fib
rot 1
pi 2
sub
call fib
add
done:
ret
To simplify the job of Arcesco interpreters we have written a very simple bytecode compiler for Arcesco which replaces labels with relative jumps and encodes instructions into 40 bit instructions. That entire pipeline for the above program looks like this:
text | assembled | bytecode
----------------|---------------|--------------------
| |
pi 10 | pi 10 | 0x010a000000
call fib | call 2 | 0x0e02000000
exit | exit | 0x1100000000
fib: | |
copy | copy | 0x0200000000
pi 3 | pi 3 | 0x0103000000
jlt done | jlt 10 | 0x0b0a000000
copy | copy | 0x0200000000
pi 1 | pi 1 | 0x0101000000
sub | sub | 0x0400000000
call fib | call -6 | 0x0efaffffff
rot 1 | rot 1 | 0x0d01000000
pi 2 | pi 2 | 0x0102000000
sub | sub | 0x0400000000
call fib | call -10 | 0x0ef6ffffff
add | add | 0x0300000000
done: | |
ret | ret | 0x0f00000000
| |
Each bytecode instruction is five bytes. The first byte is the instructions opcode and the next four are its immediate. Even instructions without immediates are encoded this way to simplify instruction decoding in interpreters. We understand this to be a small performance tradeoff but as much as possible we were optimizing for ease of interpretation.
0 8 40
+--------+-------------------------------+
| opcode | immediate |
+--------+-------------------------------+
The result of this is that an interpreter for Arcesco bytecode is just a simple while loop and switch statement. Each bytecode instruction being the same size and format makes decoding instructions very simple.
while True:
switch opcode:
case 1:
stack.push(immediate)
break
# etc..
This makes it very simple to implement an interpreter for Arcesco bytecode which is essential for smart contracts where larger programs are more expensive and less auditable.
A complete reference for the Arcesco instruction set is below.
opcode | instruction | explanation
-----------------------------------
1 | pi <value> | push immediate - pushes VALUE to the stack
2 | copy | duplicates the value on top of the stack
3 | add | pops two values off the stack and adds them pushing
the result back onto the stack.
4 | sub | like add but subtracts.
5 | mul | like add but multiplies.
6 | div | like add but divides.
7 | mod | like add but modulus.
8 | jump <label> | moves program execution to LABEL
9 | jeq <label> | moves program execution to LABEL if the two two
stack values are equal. Pops those values from the
stack.
10 | jneq <label> | like jeq but not equal.
11 | jlt <label> | like jeq but less than.
12 | jgt <label> | like jeq but greater than.
13 | rot <value> | swaps stack item VALUE items from the top with the
stack item VALUE-1 items from the top. VALUE must
be >= 1.
14 | call <label> | moves program execution to LABEL and places the
current PC on the runtime's call stack
15 | ret | sets PC to the value on top of the call stack and
pops that value.
16 | pop | pops the value on top of the stack.
17 | exit | terminates program execution. The value at the top
of the stack is the program's return value.
Reflections on smart contract development
Despite a lot of hype about smart contracts we found that writing them was quite painful.
Solana was far and away the most pleasant to work with as its solana-test-validator program made local development easy. Solana's documentation was also approachable and centralized. The process of actually executing a Solana smart contract after it was deployed was very low level and required a pretty good understanding of the entire stack before it could be done.
Ethereum comes in at a nice second. The documentation was reasonably approachable and the sheer size of the Ethereum community meant that there was almost too much information. Unlike Solana though, we were unable to set up a functional local development environment which meant that the code -> compile -> test feedback loop was slow. Working on Ethereum felt like working on a large C++ project where you spend much of your time waiting for things to compile.
Polkadot was an abject nightmare to work with. The documentation was massively confusing and what tutorials did exist failed to explain how one might interface with a smart contract outside of some silly web UI. This was surprising given that Polkadot has a $43 billion market cap and was regularly featured in "best smart contract" articles that we read at the beginning of this hackathon.
We had a ton of fun working on this project. Externally, it can often be very hard to tell the truth from marketing fiction when looking in the blockchain space. It was fun to dig into the technical details of it for a weekend.
Future work
On our quest to find the worst performing smart contract possible, we would like to implement a fuzzer that integrates with Clockchain to generate adversarial bytecode. We would also like to explore the use of oracles in blockchains for more accurate performance measurements. Finally, we would like to flesh out our front-end to be dynamically usable for a wide audience.
Built With
- blockchain
- cloudflare
- ink!
- node.js
- rust
- solana
- solidity





Log in or sign up for Devpost to join the conversation.