-
-
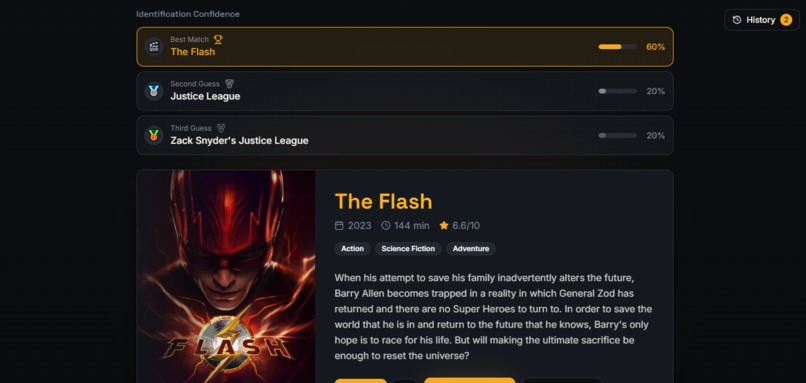
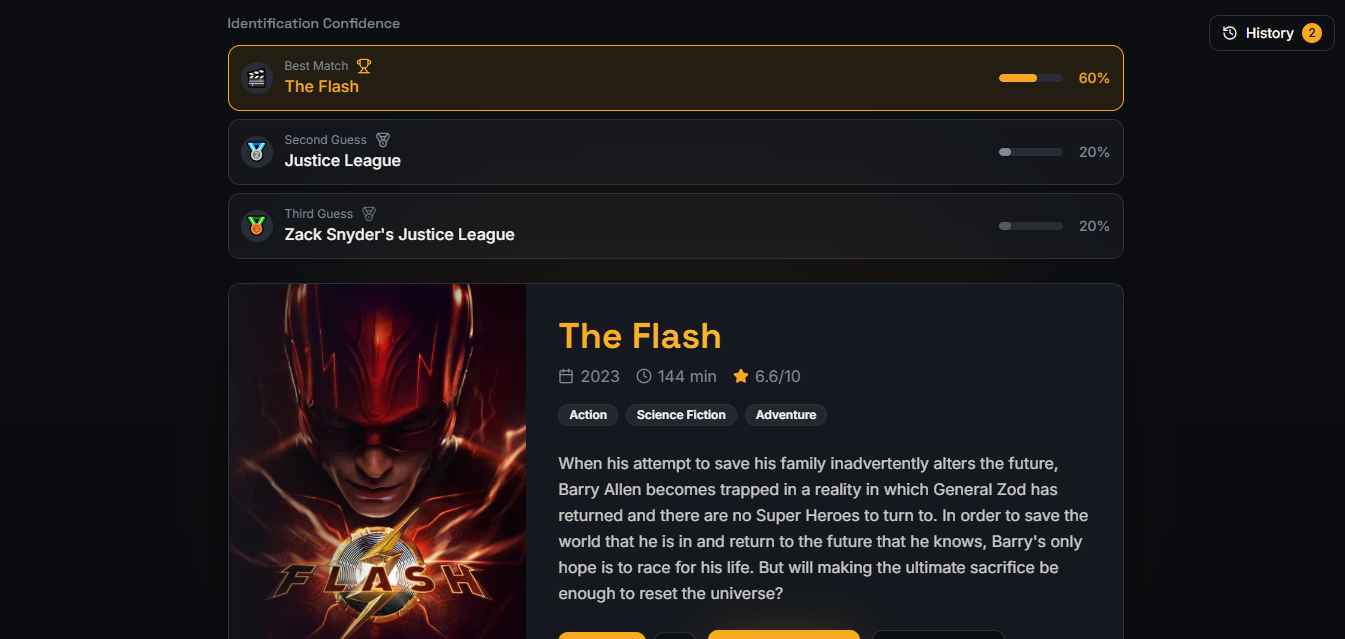
See Clipit’s AI-powered movie recognition in action, ranking the best match and close guesses.
-

Clipit: Instantly identify any movie from a YouTube clip using AI.
-
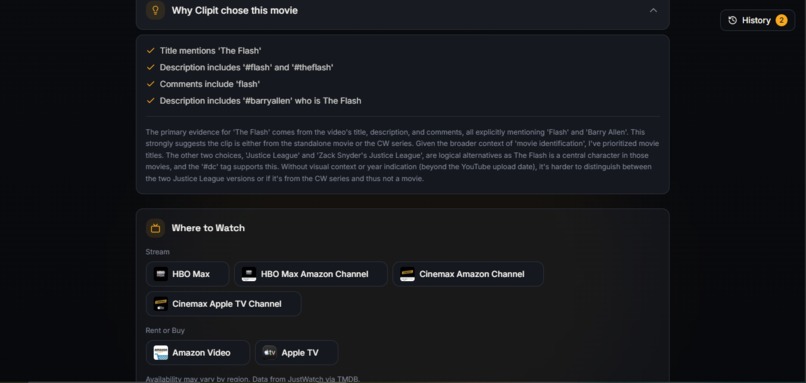
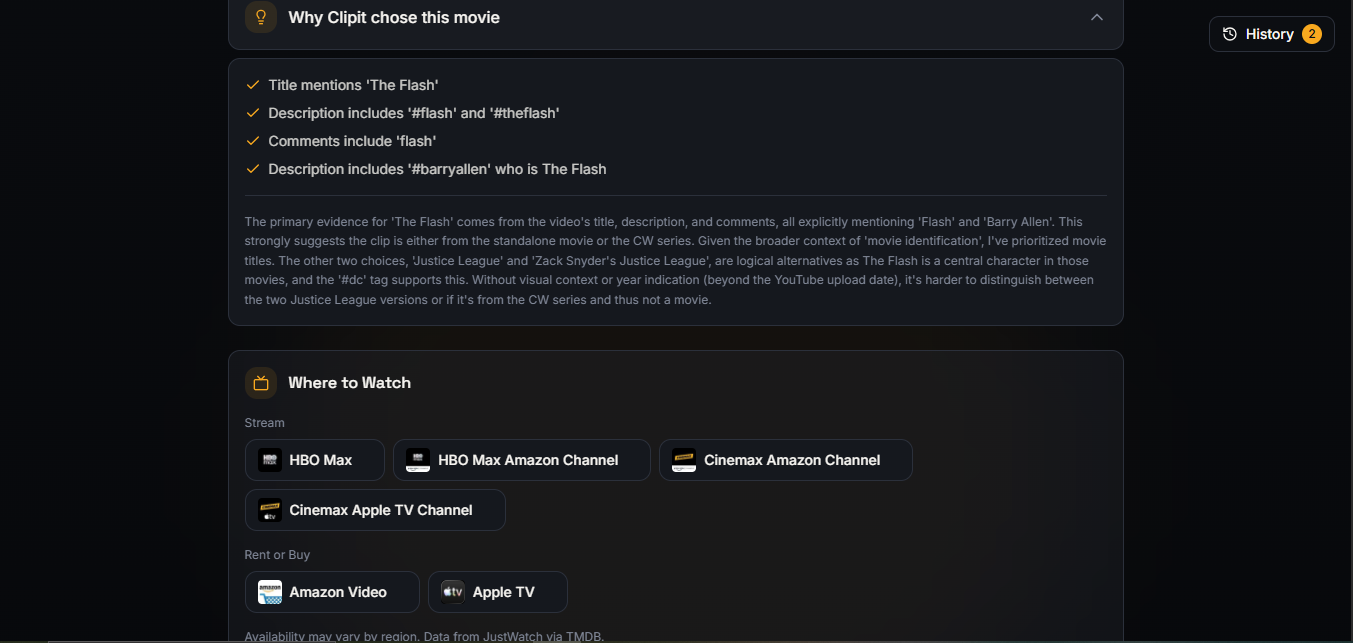
Clipit explains its movie identification logic and shows where to stream or buy the result.
-
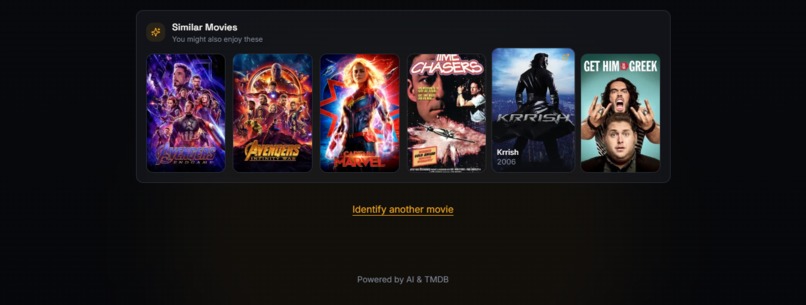
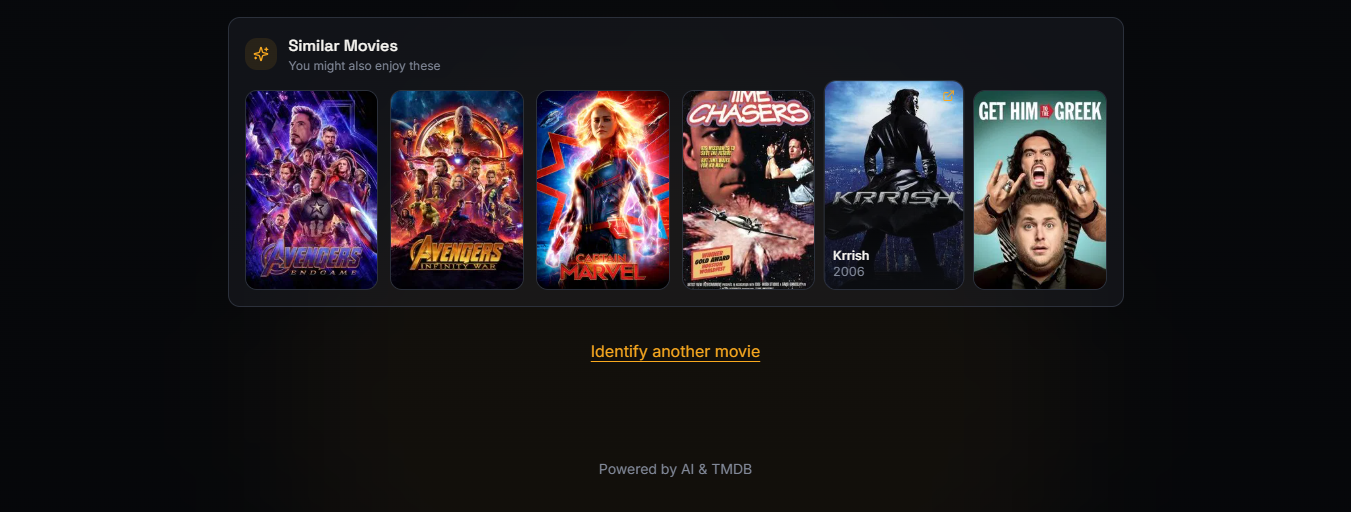
Clipit recommends similar movies you might enjoy based on your search.
-
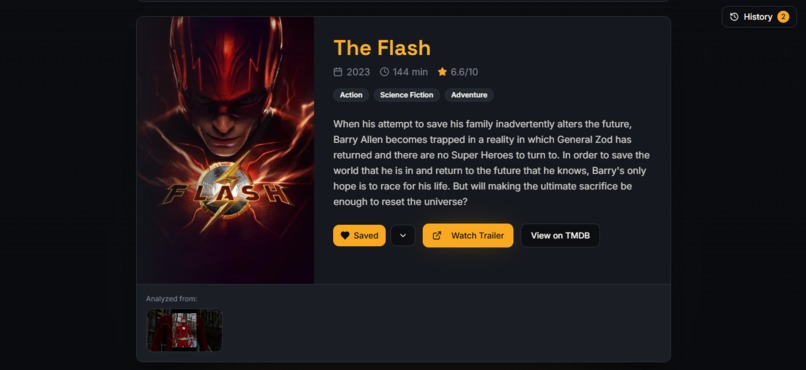
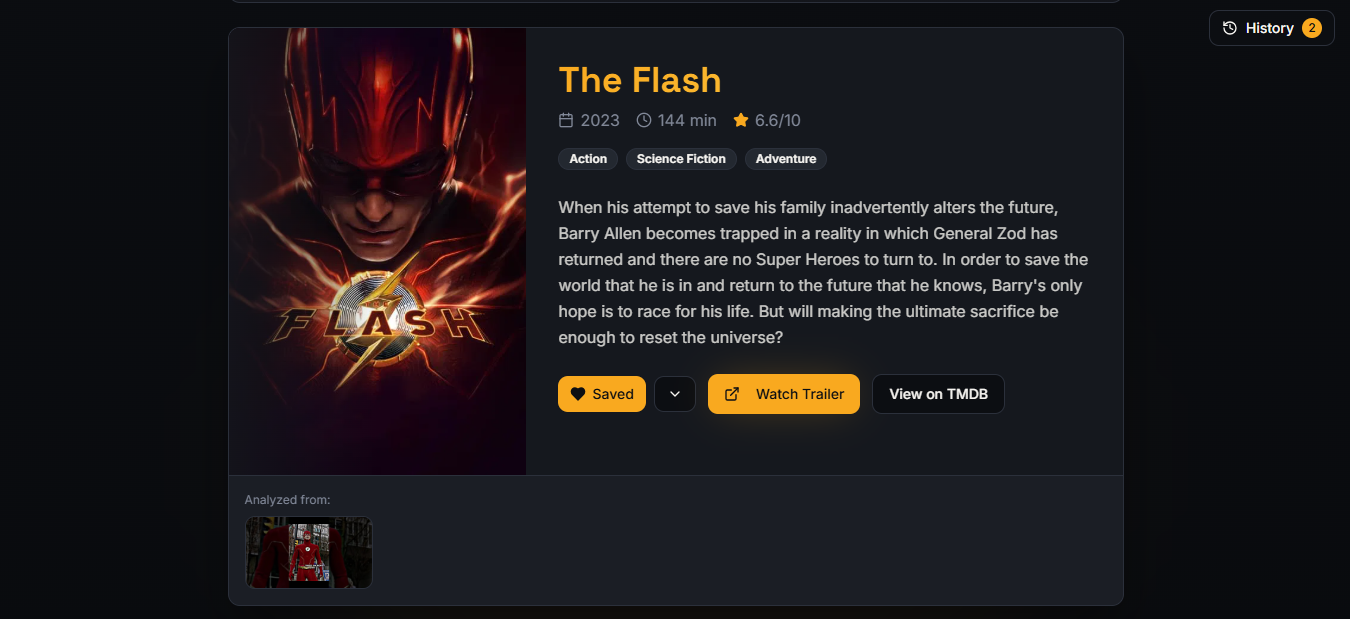
Clipit delivers detailed movie information, including synopsis, genres, and quick access to trailers and TMDB.
-
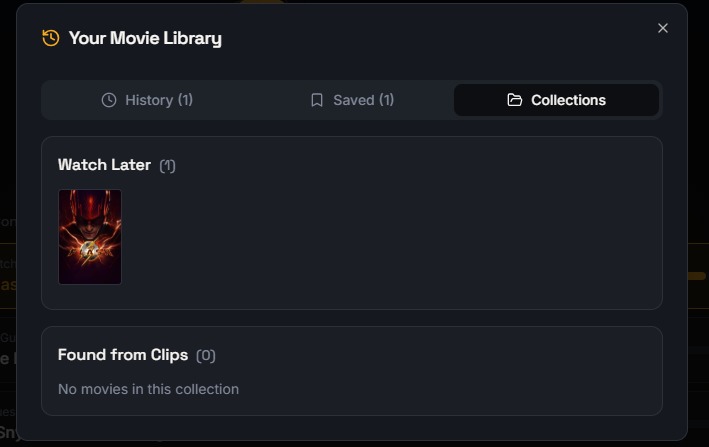
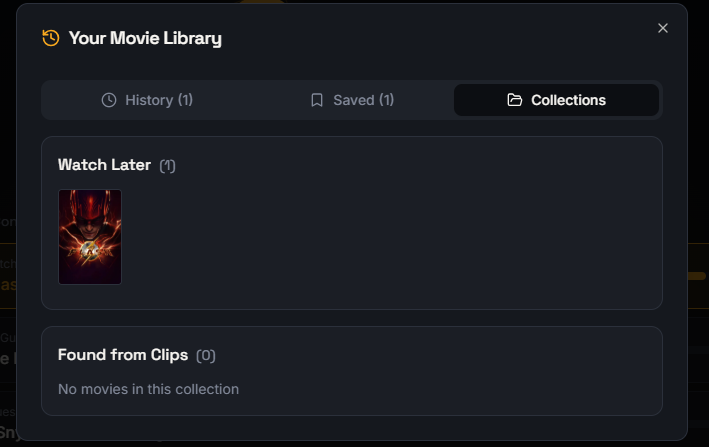
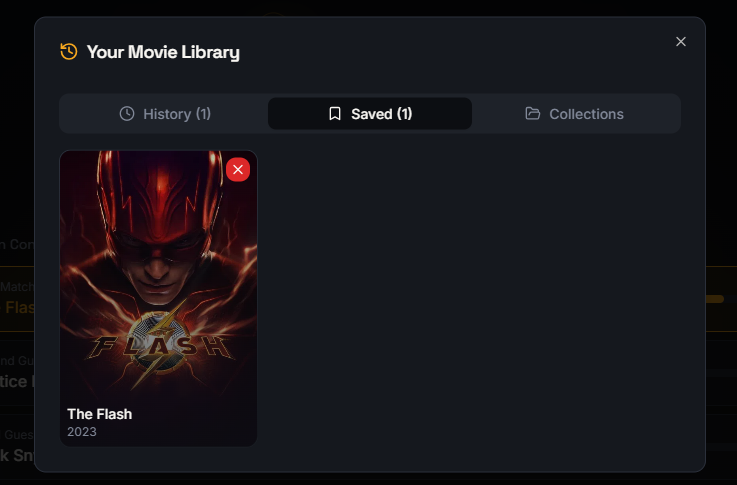
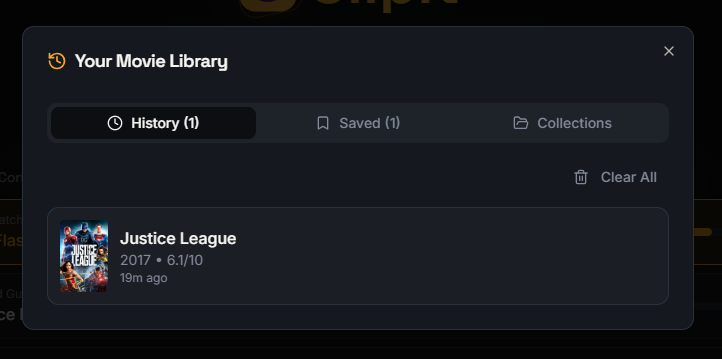
Organize your discovered movies with Clipit’s personal movie library and collections.
-
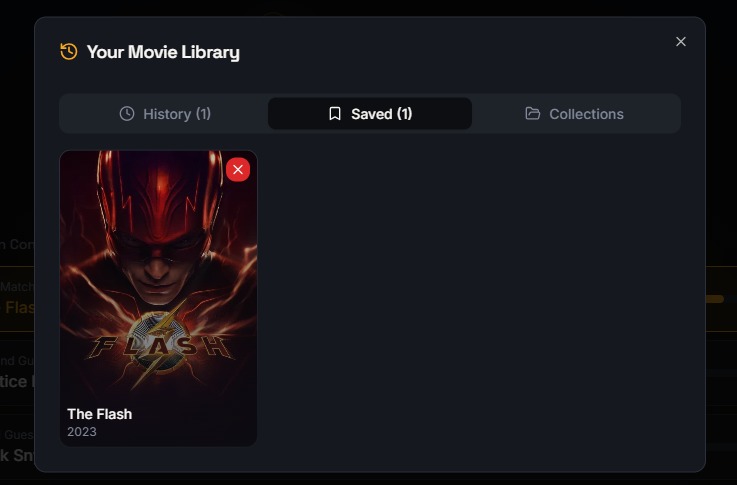
Save your favorite identified movies to your personal Clipit library.
-
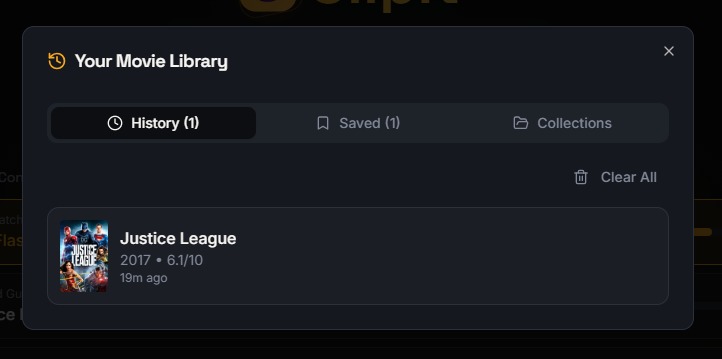
Easily revisit previously identified movies in your personal Clipit library.

🎬 Clipit — About the Project
Inspiration
Clipit was inspired by a simple but common frustration:
- You see a short movie clip online, but you don’t know the movie — and searching by characters or vague descriptions often gives the wrong result.
- Unlike music, where tools like Shazam instantly identify a song, there is no reliable, easy way to identify a movie from a short video clip.
- Existing search results are often biased toward popular ensemble movies or shared characters, which leads to incorrect identification.
Clipit was built to solve this gap — a “Shazam for movies” that focuses on accuracy, transparency, and user trust.
What Clipit Does
Clipit allows users to paste a public video link (starting with YouTube Shorts and clips). Using AI-assisted reasoning and movie databases, Clipit:
- Identifies the most likely movie
- Ranks multiple possible matches with confidence scores
- Explains why a movie was chosen
- Fetches verified movie details
- Shows where the movie can be streamed
Instead of acting like a black box, Clipit is designed to show its reasoning, helping users understand and trust the result.
How We Built It
Input Processing
- Users submit a YouTube clip link.
- Metadata is extracted using the YouTube Data API:
- Title
- Description
- Tags
- Available captions ### Context Analysis
- Key signals such as character names, locations, and story keywords are extracted.
- Ensemble vs standalone context is inferred using heuristics. ### AI-Assisted Matching
- The extracted context is compared against movie data from TMDB.
- Matches are ranked using weighted signals such as:
- Confidence Ranking
- The system returns:
- 🎬 Best Match
- 🥈 Second Guess
- 🥉 Third Guess ### Streaming Availability Streaming providers are fetched via TMDB and shown with region-aware links when possible. ### User Engagement Features deposit: Save movies; View identification history; Create collections; Explore similar scenes.
What We Learned
Building Clipit taught us several key lessons:
- Accuracy alone is not enough — users want to understand why a result was chosen.
- Popular characters can appear in multiple movies, so relying only on character detection leads to misclassification.
- Combining lightweight heuristics with AI reasoning produces better results than either alone.
- Good UX can dramatically increase trust, even when confidence is not 100%.
- We also learned how to balance AI power with practical constraints like API limits, latency, and cost.
Challenges We Faced
the following challenges were encountered during development:
- Character Overlap e.g., Characters like Flash appear in multiple movies. Early versions incorrectly identified ensemble movies (e.g., Justice League) instead of standalone films. solution: Added contextual checks using captions, keywords, and scene tone to distinguish standalone narratives from ensemble settings.
- Incomplete or Noisy Metadata some clips lack descriptions or accurate titles. solution: Designed the system to degrade gracefully, relying on multiple weak signals instead of a single strong one.
- Avoiding Heavy ML Infrastructure e.g., full video analysis or embeddings would increase cost and complexity. solution: Focused on lightweight intelligence: metadata, captions, heuristics, and explainability instead of heavy vision models.
Why Clipit Is Different
yes: a) Transparent decision-making; b) Confidence-ranked results; c) Actionable next steps (where to watch); d) Designed for curiosity, not just answers; e) Helping users discover stories with confidence.
Built With
- bun
- eslint
- framer-motion
- lucide-react
- node.js
- postcss
- react
- supabase
- tailwindcss
- tmdb-api
- typescript
- vite


Log in or sign up for Devpost to join the conversation.