Inspiration
We've all been there — you buy a new device, open the manual, and stare at a wall of tiny text and cryptic diagrams. Visual learners, non-native speakers, and first-time device owners all hit the same wall. We wanted to remove that barrier entirely by transforming any manual step into something anyone can follow in seconds.
What it does
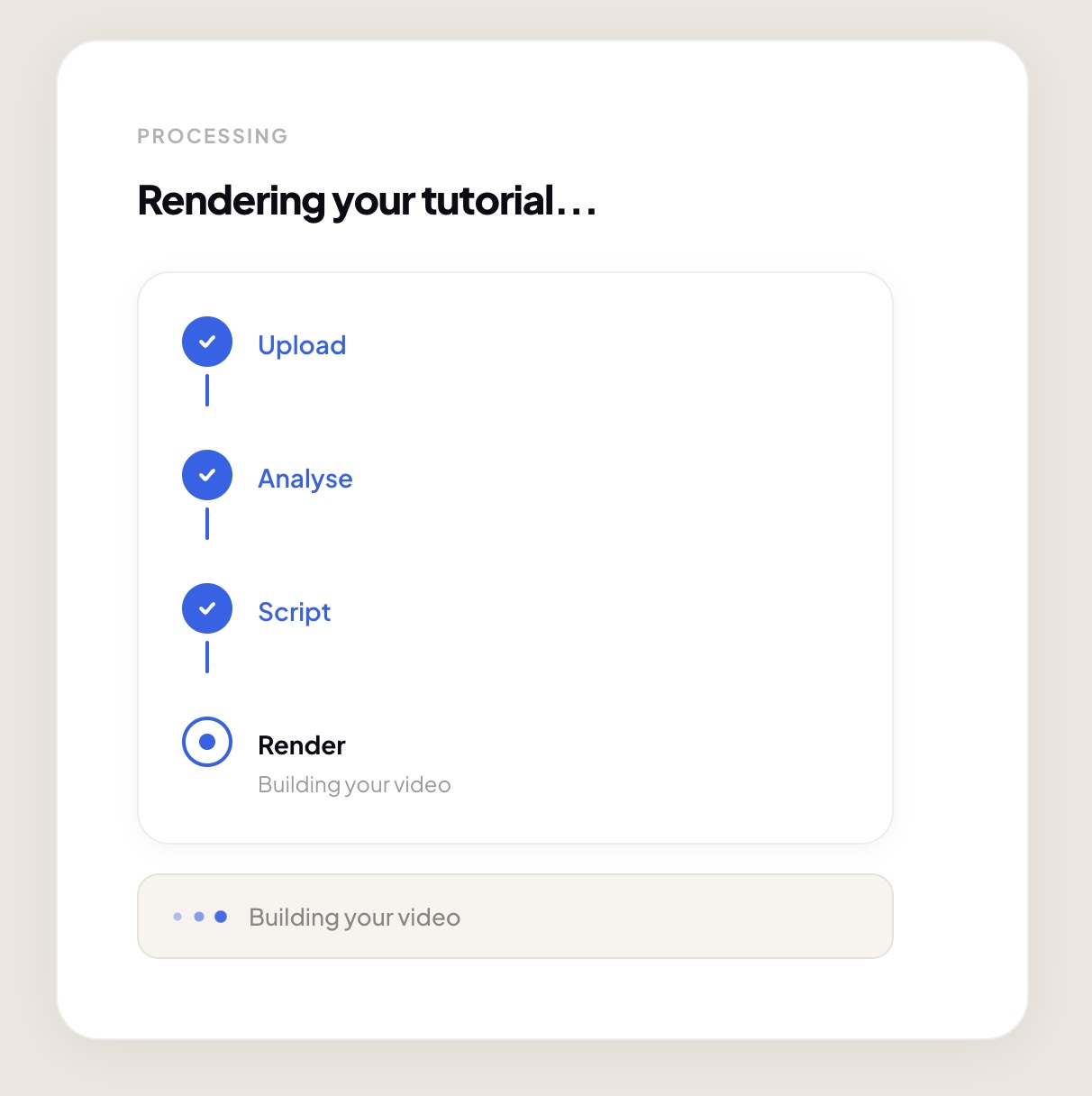
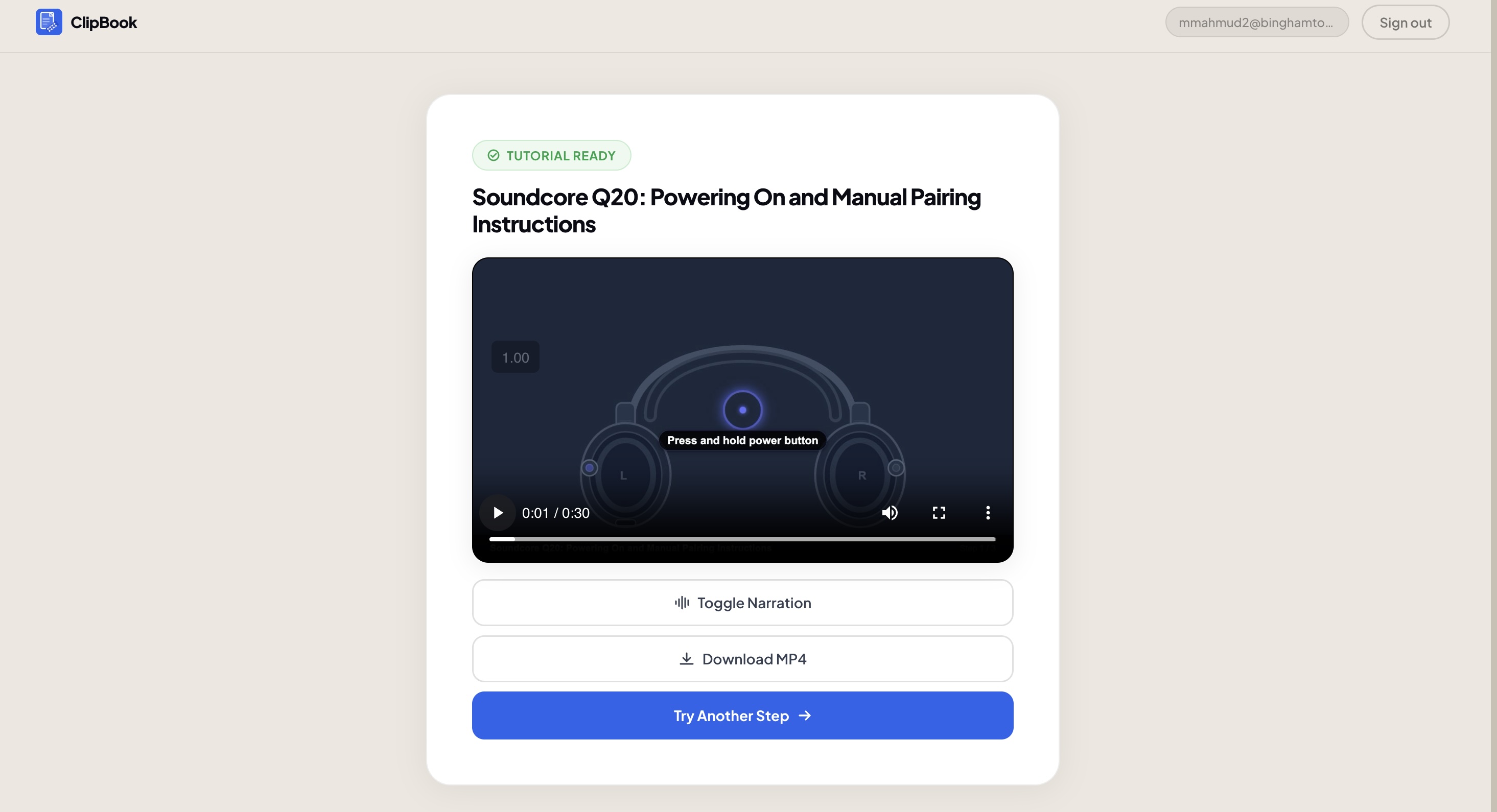
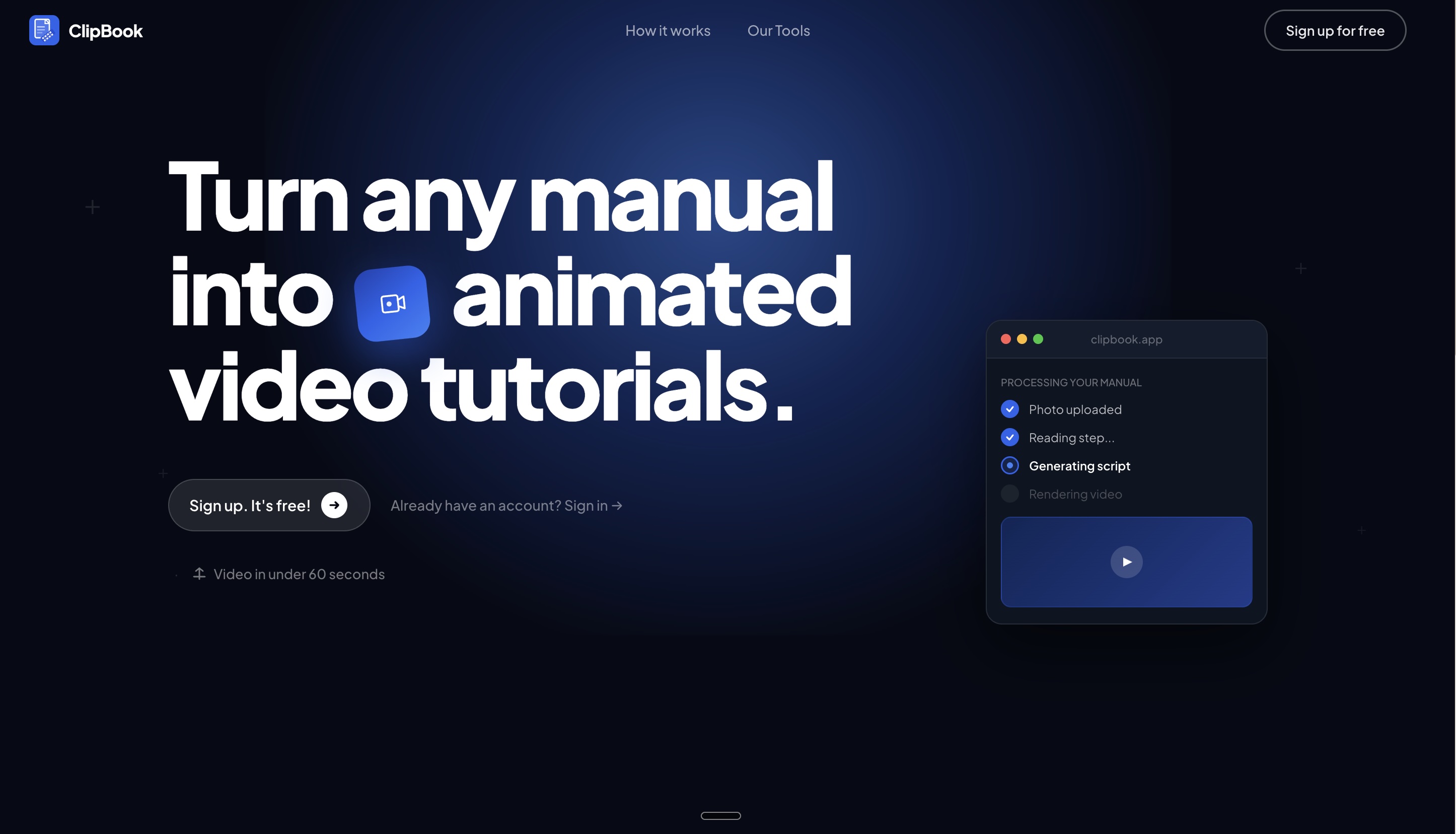
Clipbook lets you photograph any step from a physical instruction manual and returns a short animated video tutorial in under 60 seconds. The video includes animations, labels, and a spoken narration track — generated fresh from your photo, no pre-recorded library needed.
How we built it
- Frontend: React 18 + Vite, styled with Tailwind CSS, state managed with Zustand
- Backend: Node.js + Express, handling image uploads, OCR, and job orchestration
- Image processing: Sharp for compression before API calls
- OCR & detection: Google Cloud Vision (TEXT_DETECTION + LABEL_DETECTION)
- AI script generation: Google Gemini API — takes OCR output and returns a validated JSON animation script
- Animation rendering: Remotion — React-based programmatic video renderer, zero per-render API cost
- Storage: Cloudflare R2 for MP4 and image storage
- Database: Supabase (Postgres) for job tracking
- Language: TypeScript throughout — client, server, and renderer
Challenges we ran into
- A challenge we ran into was prompting Gemini to actually render a video which used certain components/elements in a correct manner, and also creating images necessary for the video
- Coordinating the async pipeline (upload → OCR → script → render → deliver) while keeping the UI responsive
- TypeScript strictness across three workspaces (client, server, renderer) caught many bugs earlier
Accomplishments that we're proud of
- An accomplishment we are proud of is actually being able to implement our elements and components into our AI animation videos.
What we learned
- Zod is invaluable as it validates structured data generated by AI
What's next for Clipbook
- Neural voice narration via ElevenLabs
- PDF manual ingestion (no photo needed)
- Multi-language support leveraging Gemini's multilingual capabilities
Built With
- cloudflare
- geminiapi
- node.js
- react
- supabase
- typescript
- visionai
- vite

Log in or sign up for Devpost to join the conversation.