

Inspiration
Sarah Mitchell is 67 years old. She has diabetes, hypertension, kidney disease, and atrial fibrillation — managed by four different doctors who don't talk to each other. Last week, her ER doctor prescribed ibuprofen for knee pain. He didn't know she's on warfarin. That combination can cause fatal bleeding.
Today's clinical AI agents hallucinate. They forget patient history between conversations. They can't detect when a new prescription conflicts with an existing allergy. And there's no cryptographic proof of what they recommended or why.
What it does
ClinicalMem is a deterministic safety layer that anchors GenAI reasoning to verified clinical evidence:
- Persistent Clinical Memory — Ingests FHIR R4 patient data and stores it as searchable memory blocks using mind-mem's hybrid BM25 + vector + RRF fusion retrieval
- Six-Model US-Based LLM Consensus — Drug interaction findings are verified by 6 US-based LLMs in parallel: OpenAI GPT-5.4, Google Gemini 3.1 Pro, Google Gemini 3.1 Flash Lite, xAI Grok 4.1, Anthropic Claude Opus 4.6, and Perplexity Sonar Reasoning Pro. Majority consensus required for high-confidence clinical verdicts
- Four-Tier Drug Interaction Detection — (1) Deterministic table catches known pairs in microseconds, (2) OpenEvidence API (Mayo Clinic / Elsevier ClinicalKey AI) for clinically authoritative evidence-grounded detection, (3) RxNorm REST API — resolves drug names to RxCUI identifiers, normalizes medication lists, and checks pairwise interactions via the NIH Drug Interaction API (the same federal database used by Epic, Cerner, and all certified EHRs), (4) Six-model LLM consensus for remaining pairs with majority voting
- SNOMED CT Allergy Cross-Reactivity — 8 drug class hierarchies (penicillin, cephalosporin, sulfonamide, fluoroquinolone, opioid, NSAID, ACE inhibitor, statin) with alias expansion. Catches prescriptions that cross-react with known allergies
- UMLS Metathesaurus Crosswalk — Maps between ICD-10, SNOMED CT, LOINC, and RxNorm vocabularies using CUI-based resolution
- What-If Medication Simulation — Clinicians can simulate adding, removing, or substituting medications to preview safety outcomes before making changes. Runs the full four-tier pipeline on hypothetical medication lists
- FDA Safety Alert Integration — Queries the openFDA Drug Enforcement and Drug Event APIs for active recalls, safety alerts, and adverse event signals for patient medications
- Clinical Trial Matching — Searches ClinicalTrials.gov for active trials matching patient conditions, with eligibility pre-screening based on age, gender, and active conditions
- PHI Detection Guard — Scans free-text clinical notes for Protected Health Information (SSN, MRN, phone, email, dates of birth, addresses) before storage, preventing accidental PHI leakage into the memory layer
- Hallucination Detection — Validates LLM-generated clinical text against retrieved evidence blocks. Flags unsupported claims, checks medication name accuracy, and detects fabricated citations
- Cross-Provider Contradiction Detection — Surfaces conflicting care plans, declining lab trends, and medication-lab contraindications across fragmented provider records
- LLM-Grounded Clinical Synthesis — Medical LLM cascade generates patient-specific clinical narratives with explicit evidence citations. When confidence is low, the system abstains rather than hallucinating
- SHA-256 Hash-Chain Audit Trail — Every clinical decision is logged in a tamper-proof Merkle chain, providing cryptographic proof that AI recommendations haven't been altered
Demo Scenario: Sarah Mitchell
Sarah is a 67-year-old with Type 2 Diabetes, Hypertension, CKD Stage 3b, and Atrial Fibrillation, managed by 4 different providers. ClinicalMem catches:
- NSAID + Warfarin — ER doctor prescribed Ibuprofen for knee pain, but Sarah is on Warfarin for AFib. ClinicalMem flags the serious bleeding risk.
- Amoxicillin + Penicillin Allergy — Urgent Care prescribed Amoxicillin without checking allergies. SNOMED CT drug class hierarchy detects the cross-reactivity with her documented Penicillin anaphylaxis.
- Declining GFR + Metformin — GFR dropping from 45 to 32 over 6 months, approaching the threshold where Metformin becomes contraindicated.
- Conflicting BP Targets — Cardiologist says <130/80, nephrologist says <140/90. ClinicalMem flags the belief drift.
How we built it
ClinicalMem is built on two open-source STARGA technologies:
mind-mem (v1.9.0) — Our persistent memory system for coding agents, adapted for clinical data. Provides hybrid BM25 + vector search, contradiction detection, causal dependency graphs, and hash-chain audit logging.
MIND Lang Scoring Kernels — Pure Python implementations of three MIND Lang kernels:
abstention.mind→ Confidence gating (decides when to abstain)importance.mind→ Clinical importance scoring (prioritizes acute over historical)adversarial.mind→ Negation detection (distinguishes "allergic" from "NOT allergic")
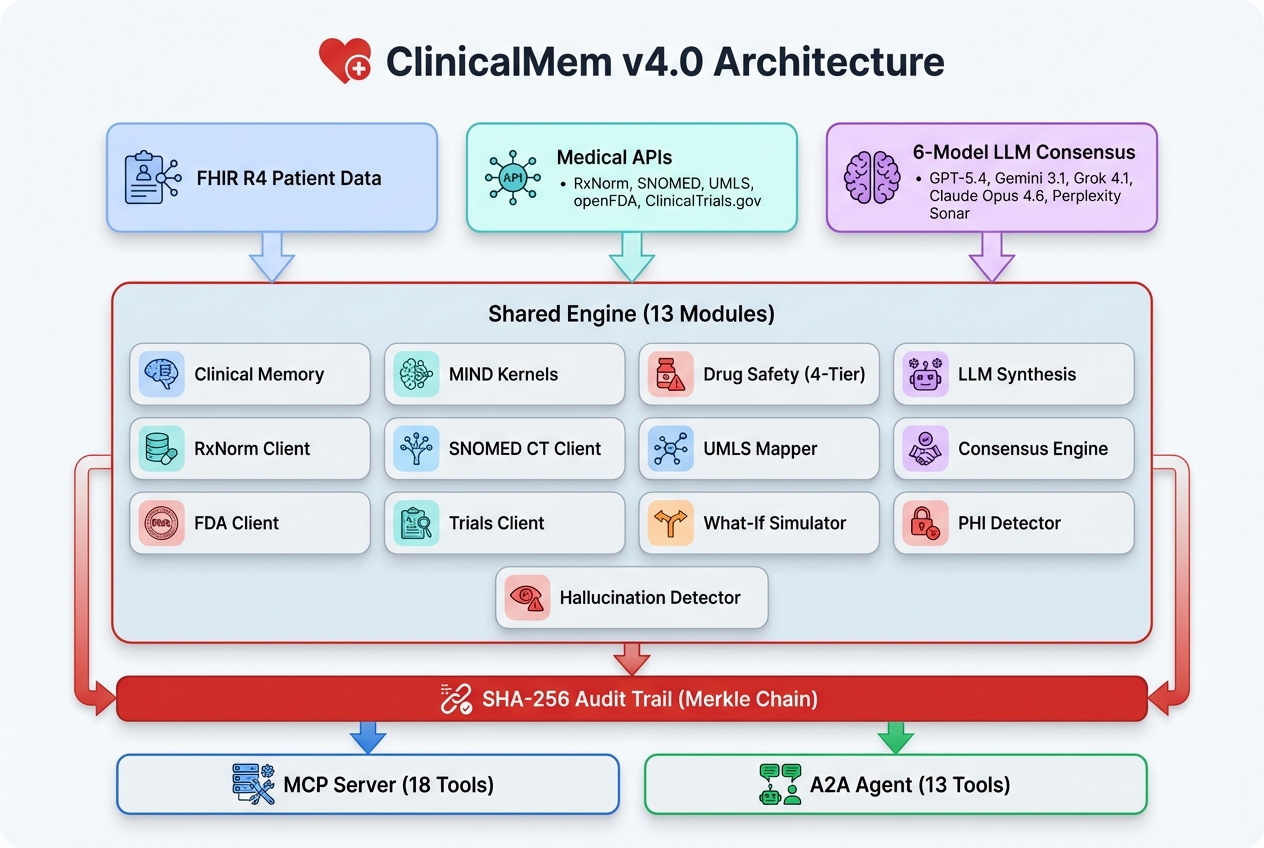
Architecture
- Shared Engine (
engine/) — 13 modules: FHIR R4 client, clinical memory, scoring kernels, LLM synthesizer, RxNorm client, SNOMED CT client, UMLS Metathesaurus mapper, consensus engine (6 US-based LLMs), FDA client, clinical trials client, what-if simulator, PHI detector, hallucination detector - MCP Server (
mcp_server/) — FastMCP 2.x with Streamable HTTP transport, 18 SHARP-on-MCP tools - A2A Agent (
a2a_agent/) — Google ADK agent with 13 clinical tools, AgentCard, API key middleware
The GenAI Pattern: Deterministic Detection + LLM Consensus + Safe Synthesis
ClinicalMem uses a six-layer architecture that makes AI safe for healthcare:
- Detection Layer 1 (Deterministic) — Rule-based safety rails catch known drug interactions, allergy conflicts, lab contraindications, and provider disagreements. Microsecond response, never hallucinate.
- Detection Layer 2 (OpenEvidence API) — For medication pairs not in the deterministic table, ClinicalMem queries OpenEvidence — the same medical AI engine powering Elsevier's ClinicalKey AI, developed with Mayo Clinic.
- Detection Layer 3 (RxNorm + NIH Drug Interaction API) — Resolves drug names to RxCUI identifiers via the RxNorm REST API, normalizes medication lists, then checks pairwise interactions through the NIH Drug Interaction API — the same federal database used by Epic, Cerner, and all certified EHR systems. Free, no API key required, authoritative.
- Detection Layer 4 (Six-Model LLM Consensus) — Verifies findings across 6 US-based LLMs in parallel: OpenAI GPT-5.4, Google Gemini 3.1 Pro, Google Gemini 3.1 Flash Lite, xAI Grok 4.1, Anthropic Claude Opus 4.6, and Perplexity Sonar Reasoning Pro. Requires majority consensus for clinical verdicts.
- Synthesis Layer (Medical LLM Cascade) — Generates patient-specific clinical explanations from detected findings, citing evidence blocks by ID. The LLM never invents facts — it explains what the detection layers found.
- Abstention Gate — When evidence is insufficient, the system refuses to generate a narrative. In healthcare, "I don't know" saves lives.
UMLS Terminology Services
ClinicalMem integrates three NIH terminology services for standardized clinical vocabulary:
- RxNorm Client — Resolves medication names to RxCUI identifiers, normalizes medication lists, and retrieves pairwise drug interactions from the NIH REST API
- SNOMED CT Client — Maps allergies to drug class hierarchies (8 classes: penicillin, cephalosporin, sulfonamide, fluoroquinolone, opioid, NSAID, ACE inhibitor, statin) with alias expansion
- UMLS Metathesaurus Mapper — Cross-vocabulary mapping between ICD-10, SNOMED CT, LOINC, and RxNorm using CUI-based concept resolution
Testing
356 tests covering clinical scoring kernels, FHIR client integration, engine ingestion/recall/safety checks, hash-chain audit trail integrity, LLM synthesis with abstention gating, RxNorm drug normalization, SNOMED CT cross-reactivity detection, UMLS crosswalk mapping, consensus engine verification, what-if simulation, FDA client, clinical trials matching, PHI detection, and hallucination detection.
Challenges we ran into
- Confidence calibration — The initial confidence formula was a self-referential ratio that always returned ~1.0. We redesigned it to use absolute evidence strength, so low BM25 scores actually trigger abstention.
- Cross-provider contradiction detection — Different specialists legitimately disagree (e.g., BP targets for cardiac vs renal patients). We had to distinguish harmful contradictions from acceptable clinical nuance.
- FHIR data normalization — Medications come in many formats (brand names, generics, coded concepts). Our fuzzy matching uses substring containment rather than exact match to catch variations.
- Negation boundary conditions — "ruled out" at end of string vs mid-sentence. Clinical NLP must handle terminal negation markers without trailing spaces.
- UMLS vocabulary alignment — Medications, allergies, and lab tests use different coding systems across providers (ICD-10, SNOMED CT, LOINC, RxNorm). We built a crosswalk module using UMLS Metathesaurus CUI-based resolution to unify them.
- Multi-LLM consensus orchestration — Each LLM provider has a different API format (OpenAI, Anthropic Messages API, Google generateContent, xAI, Perplexity). We built provider-specific adapters and parallel execution with timeout handling to get consensus in under 5 seconds.
- PHI detection in free text — Clinical notes contain unstructured text where PHI can appear in unexpected formats. We built regex-based pattern detection for SSN, MRN, phone numbers, emails, dates of birth, and physical addresses.
Accomplishments that we're proud of
- Six-model US-based LLM consensus — Drug interaction verdicts verified by GPT-5.4, Gemini 3.1 Pro, Gemini 3.1 Flash Lite, Grok 4.1, Claude Opus 4.6, and Perplexity Sonar Pro in parallel. No single model can hallucinate a finding into production.
- What-if medication simulation — Clinicians can preview safety outcomes of medication changes before making them — like a flight simulator for prescriptions.
- FDA safety alert integration — Real-time queries to openFDA for active recalls and adverse event signals on patient medications.
- Clinical trial matching — Automatically finds relevant active trials on ClinicalTrials.gov for patient conditions with eligibility pre-screening.
- PHI detection guard — Catches Protected Health Information before it enters the memory layer, preventing accidental data leakage.
- Hallucination detection — Validates LLM-generated clinical text against evidence, flagging unsupported claims.
- Deterministic safety + GenAI synthesis — Rules catch the conflicts reliably; LLMs explain them in clinical context. Best of both worlds.
- 4 conflicts caught in demo — Drug interactions, allergy cross-reactions, declining lab trends, and provider disagreements — all detected automatically with patient-specific clinical rationale.
- Full UMLS terminology integration — RxNorm, SNOMED CT, and UMLS Metathesaurus for standardized clinical vocabulary across 13 engine modules.
- Safe abstention — When evidence is insufficient, ClinicalMem says "I don't know" instead of hallucinating. In healthcare, this saves lives.
- Tamper-proof audit trail — SHA-256 Merkle chain provides cryptographic proof that clinical decision logs haven't been altered.
- 356 tests passing — Comprehensive coverage across clinical scoring, FHIR integration, drug normalization, allergy cross-reactivity, UMLS crosswalk, LLM synthesis with abstention gating, consensus engine, what-if simulation, FDA integration, clinical trials, PHI detection, and hallucination detection.
- Dual protocol support — Both MCP (18 tools) and A2A (13 tools) for maximum interoperability.
- Live on Azure — MCP server and A2A agent deployed on Azure Container Apps with zero cold-start.
What we learned
- MIND Lang's abstention kernel philosophy (refuse to answer when uncertain) is critical for clinical AI safety
- FHIR R4's bundled resource model maps naturally to mind-mem's block-based memory architecture
- Healthcare AI needs memory that is auditable, contradiction-aware, and confidence-gated — not just retrieval
- UMLS terminology services (RxNorm, SNOMED CT, Metathesaurus) are essential for interoperability across providers
- Multi-LLM consensus is more reliable than any single model — different models catch different edge cases
- What-if simulation transforms a safety tool into a clinical decision support system
- PHI detection must happen at the ingestion boundary, not as an afterthought
What's next for ClinicalMem
- BiomedBERT vector embeddings for medical-specific semantic search
- Multi-patient analytics (population-level safety signals)
- Production deployment with HIPAA-compliant encryption at rest via OpenAI Healthcare API with HIPAA BAA
- Real-time medication monitoring via DailyMed FDA label integration for black-box warnings
- Temporal trend analysis with predictive alerts (detect worsening trajectories before they hit thresholds)
- Integration with Epic FHIR APIs for real EHR data access


Log in or sign up for Devpost to join the conversation.