-
-

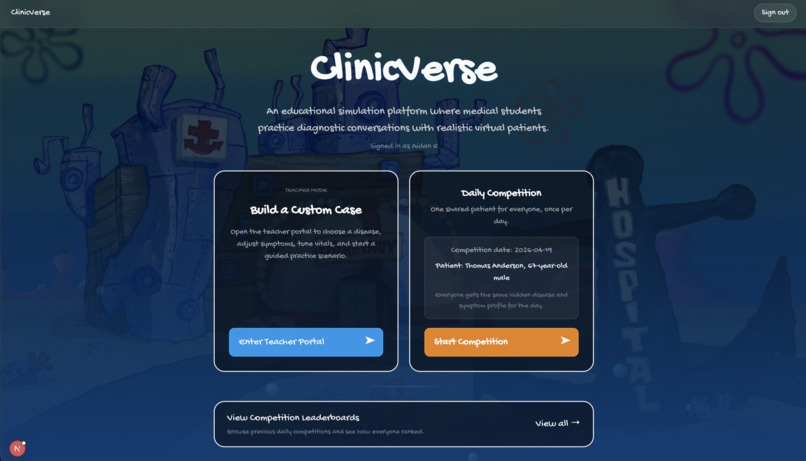
ClinicVerse
-
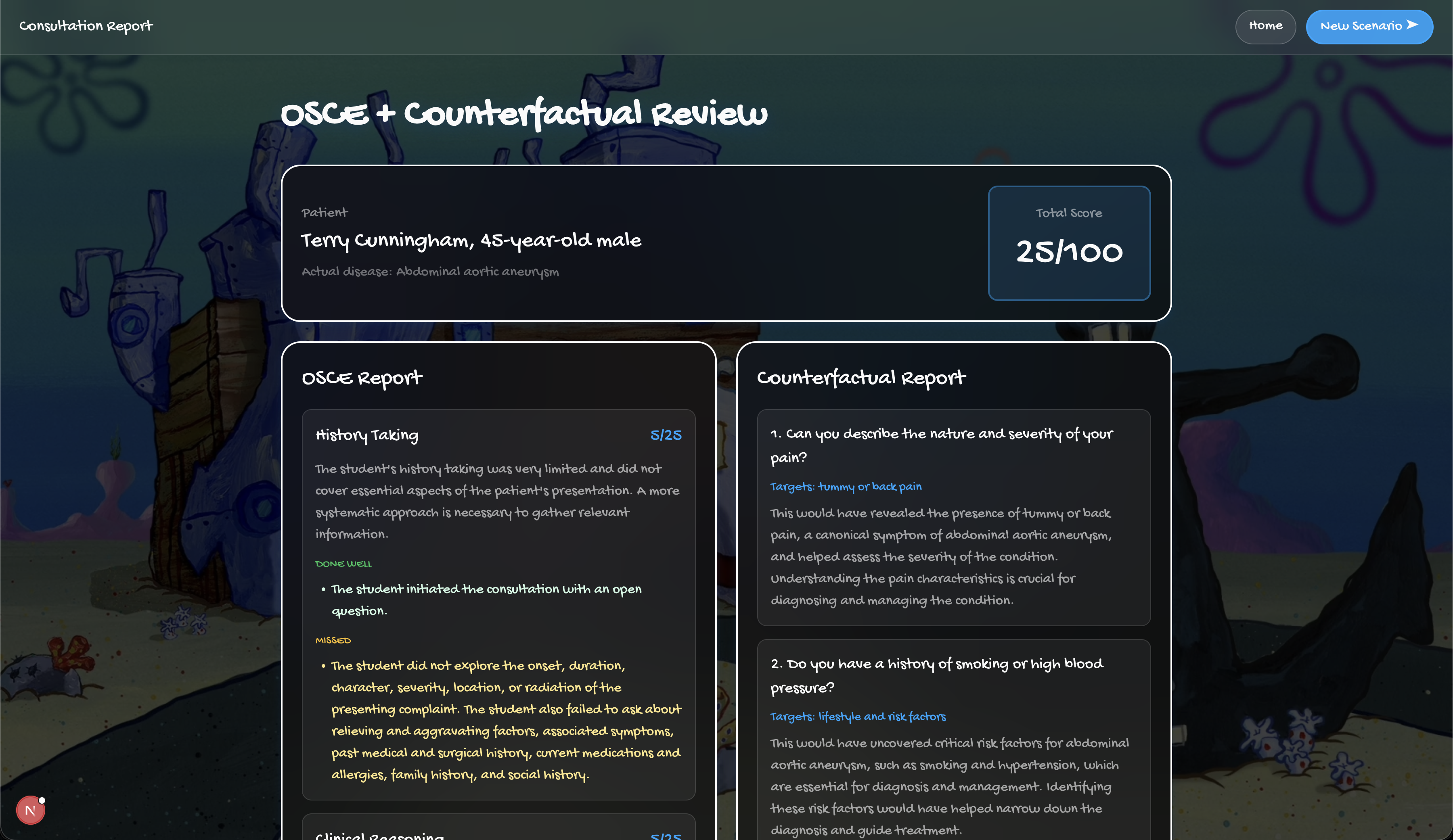
Report Page
-
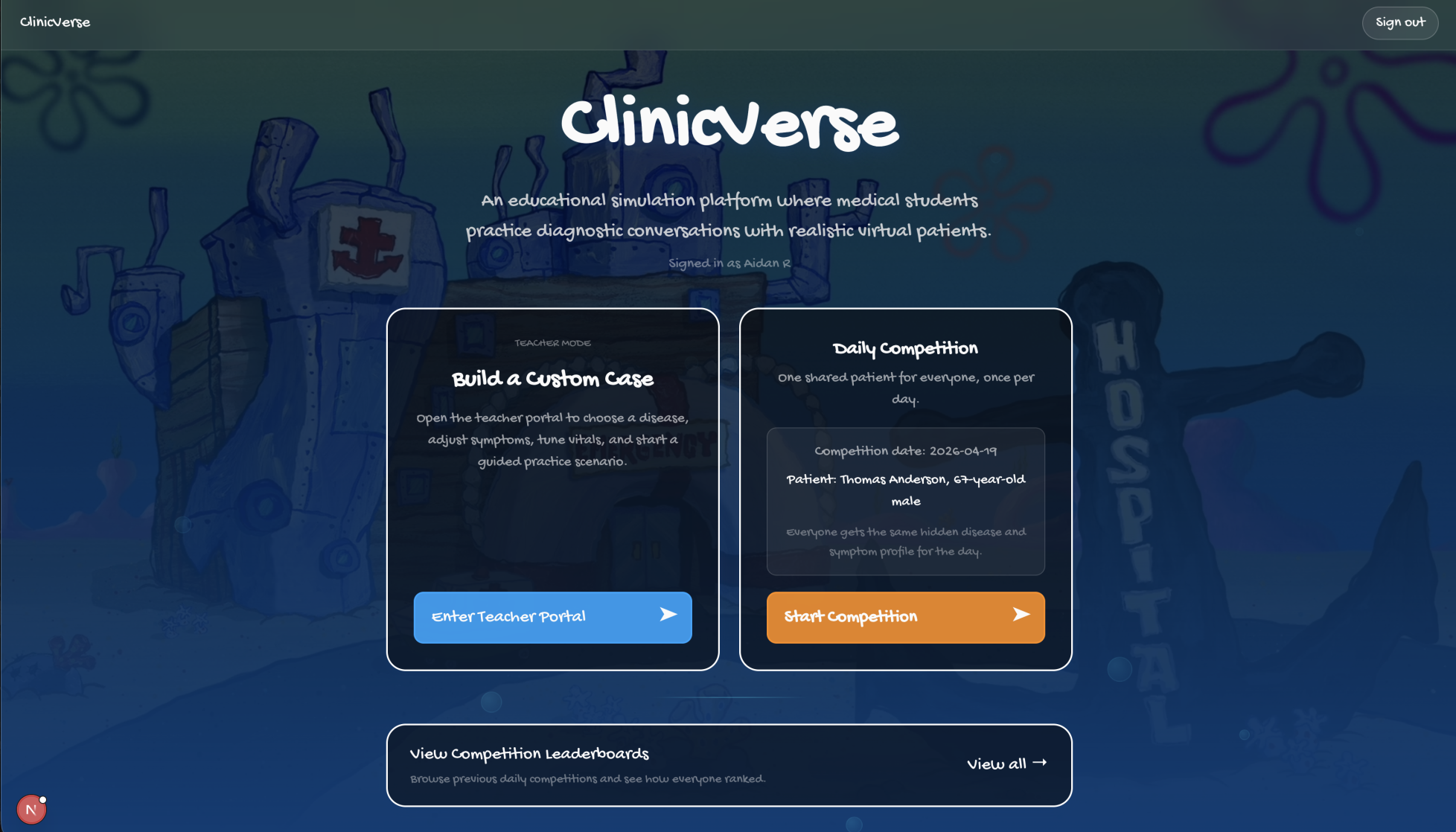
Home Page
-
Leaderboard
-
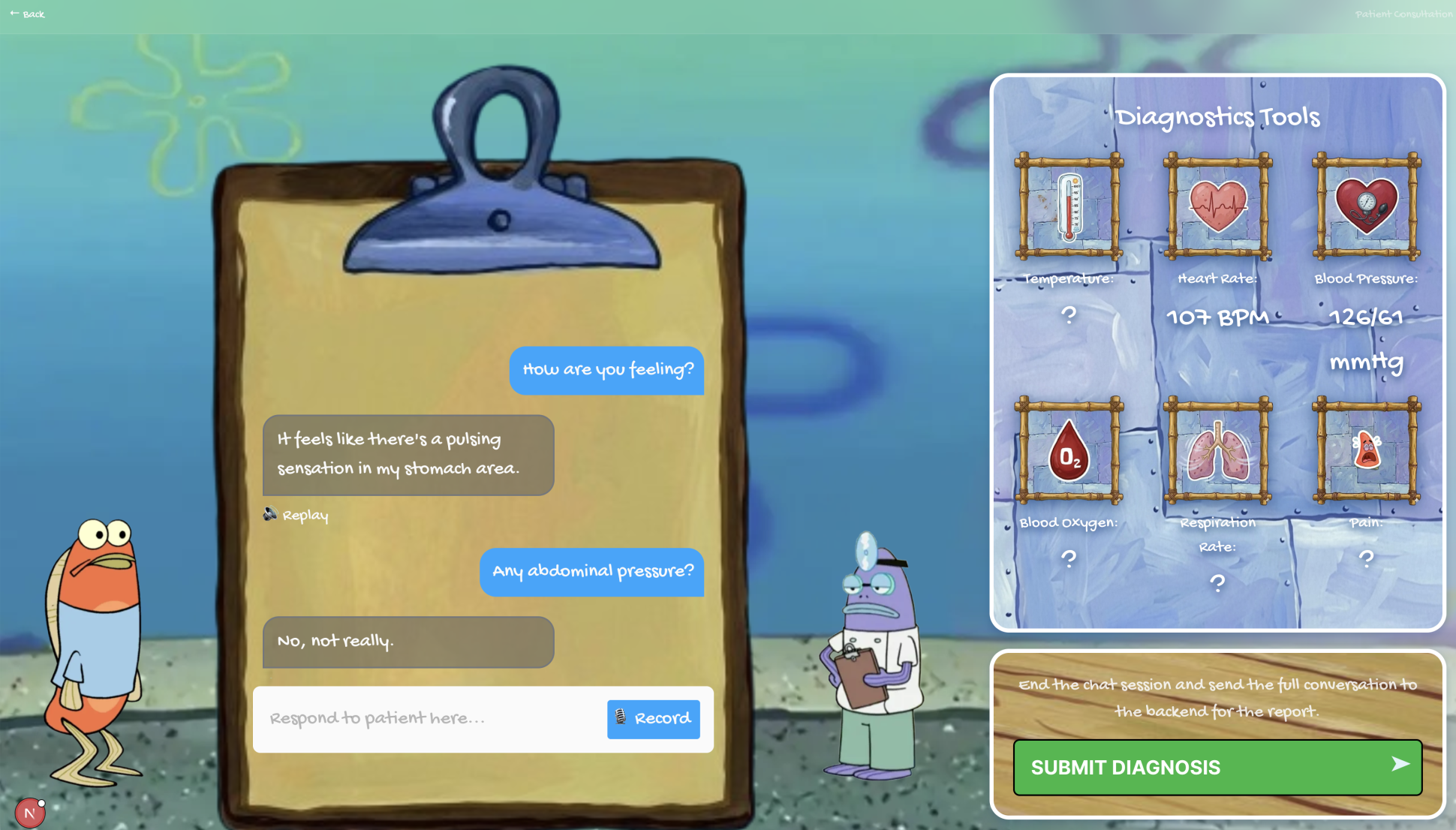
Medical Student Chatting With Patient
-
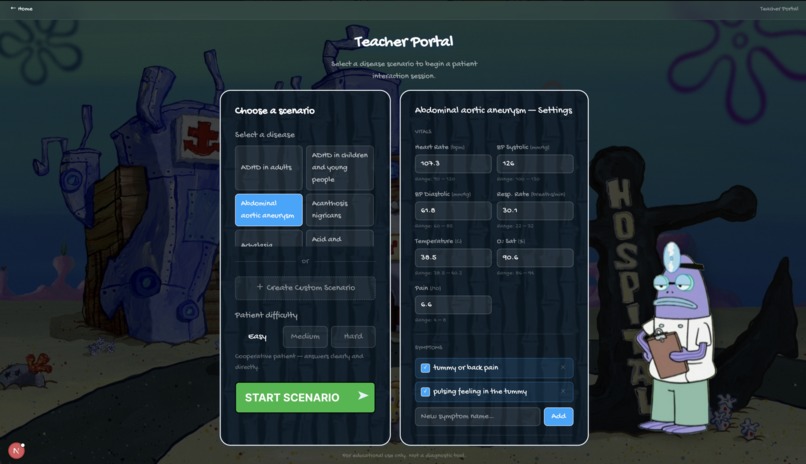
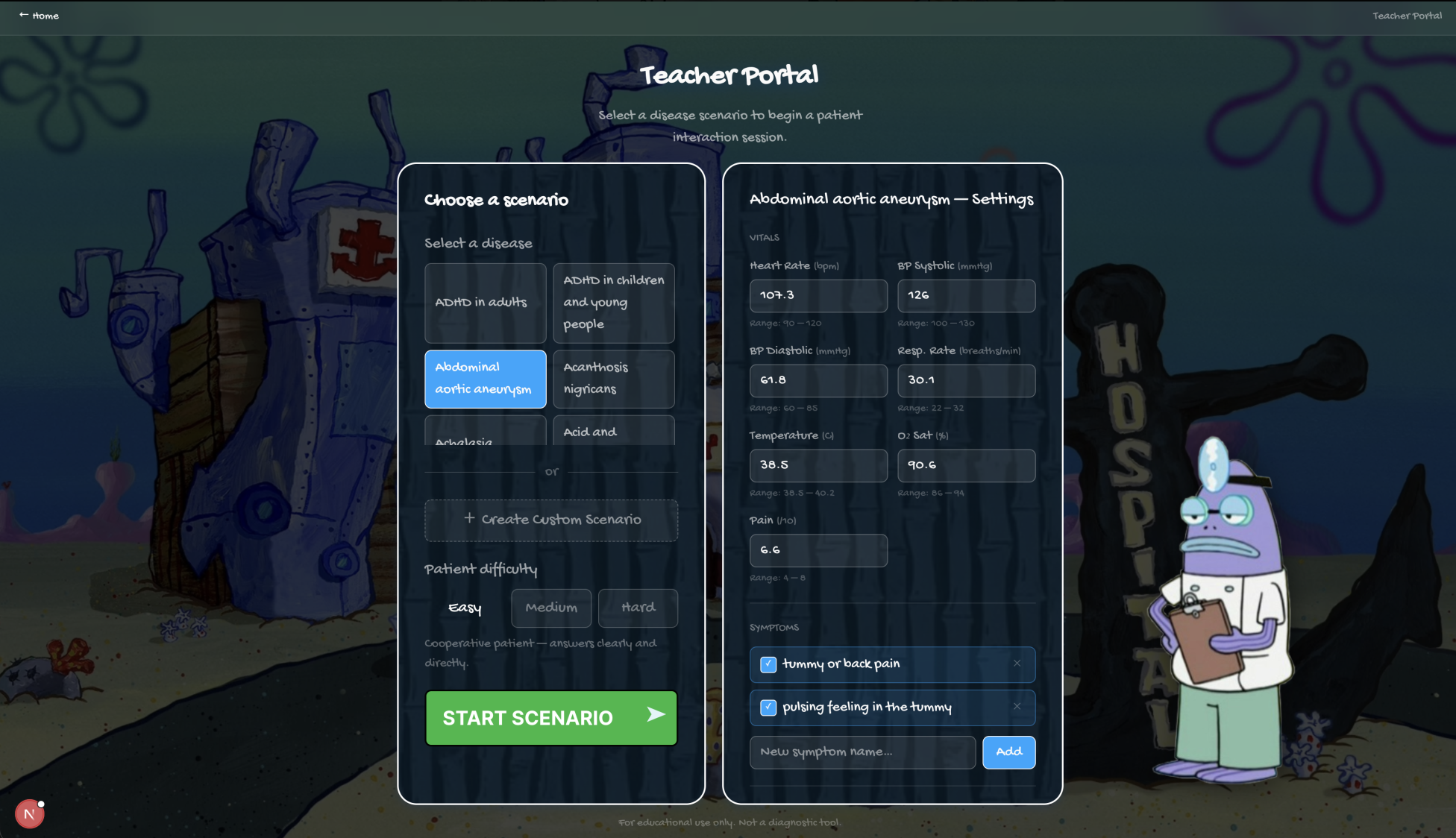
Teacher Set Up Page

ClinicVerse
AI-powered virtual patient simulator for clinical training
Not enough real patients to practice on? ClinicVerse gives med students unlimited realistic consultations, instant OSCE feedback, and daily diagnostic challenges. Free. Always available.
Inspiration
Medical students learn by doing, but real patients are not practice tools. A wrong question in a real consultation carries consequences. ClinicVerse removes that pressure entirely. Students can practice taking a history from a patient with appendicitis at 2 am, make every mistake possible, and learn from them without any real-world consequences.
Beyond common conditions, ClinicVerse can simulate diseases a doctor might encounter once in their entire career, such as a case of Addison's disease, a presentation of Guillain-Barré syndrome, or a rare paraneoplastic syndrome. In a traditional programme, students may never see these at all before qualifying. Here, they can practice them on demand, as many times as they need, until the presentation is familiar.
What We Built
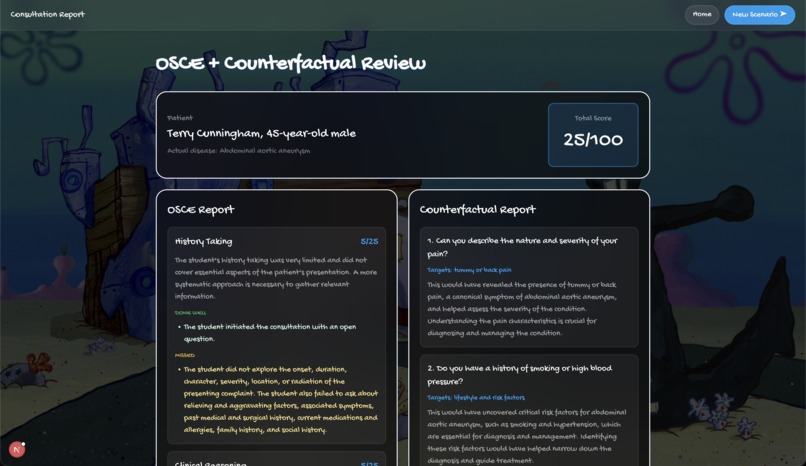
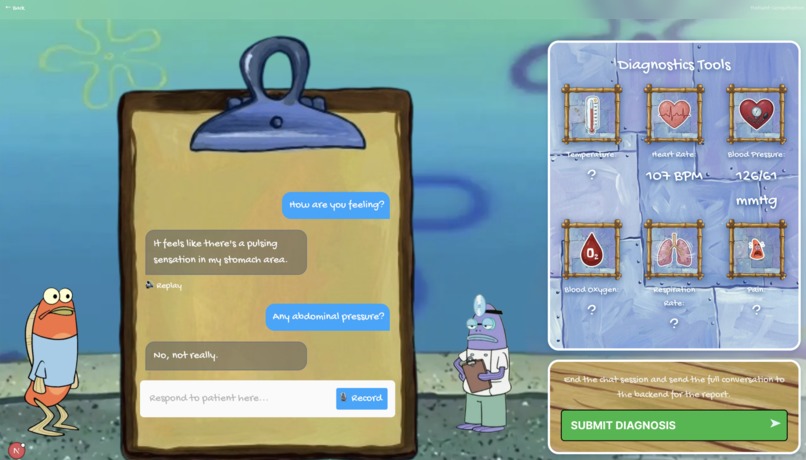
ClinicVerse is an AI-powered medical consultation simulator. A teacher configures a patient case. A student conducts a full clinical history in voice or text with an AI patient that responds like a real person. At the end, they receive a structured OSCE report graded across four domains, written examiner feedback, and a counterfactual breakdown of every high-value question they failed to ask.
How We Built It
1. The Patient LLM — Fine-Tuned Qwen 2.5-1.5B with LoRA
The core of ClinicVerse is a fine-tuned language model playing the patient. We used Qwen 2.5-1.5B-Instruct fine-tuned with QLoRA on doctor-patient dialogue from MTS-Dialog and NoteChat, training only 1.3% of parameters on a single GPU in under 90 minutes.
A base model prompted to play a patient behaves like a helpful assistant, volunteering diagnoses and breaking character. Our fine-tuned model learned four specific behaviours from real dialogue: role consistency, strategic symptom revelation, 2 to 4 sentence conciseness, and reliable identity grounding.
We measured the difference directly: 34% improvement in symptom F1 and 28% reduction in diagnosis leakage versus the base model.
Per turn, RAG context is injected from our disease KB, matching the doctor's question intent to the most relevant canonical symptoms, so answers stay grounded in what the disease actually presents with.
2. How ClinicVerse Uses Human Delta
1. Building the Brain — Precision Knowledge Extraction
When we build our medical knowledge base, we don't just dump raw NHS pages at an LLM and hope for the best. For each disease, Human Delta crawls the NHS page, chunks and embeds it semantically, then we run targeted vector searches — "symptoms of Pneumonia", "treatment for Pneumonia" — to surgically extract only the most clinically relevant sentences. Those clean, precise chunks go to Groq for structured extraction. The result is a richer, more accurate knowledge base compared to naive full-page scraping.
HD features used: indexes.create() · fs.read() · /v1/search
2. Persistent Agent Memory — The KB Remembers Itself
Every time the knowledge base is built or extended, ClinicVerse writes a
structured summary to Human Delta's agent memory at
/agent/notes/clinicverse_kb_summary.md — timestamp, how many diseases were
indexed, which ones succeeded, what context source was used. On the next run,
it reads that memory first. Human Delta becomes the long-term brain of the
builder, not just a one-time scraper.
HD features used: fs.write() · fs.read() on /agent/ path
3. Curriculum-Aware Case Generation — Your School, Your Cases
Teachers upload their medical school's curriculum PDF directly into
ClinicVerse. Human Delta stores and indexes it as a searchable document, then
extracts the full text via the /v1/documents/{id}/preview endpoint.
ClinicVerse matches that extracted text against our entire knowledge base —
instantly surfacing every disease covered in the curriculum and
highlighting them in the case selector. No manual searching needed.
A CSUF student and a Stanford student get cases tailored to what they're actually studying this semester, not a generic list of 50 diseases.
HD features used: documents.upload() · GET /v1/documents/{id}/preview
3. Voice — ElevenLabs
The consultation runs entirely by voice using ElevenLabs Scribe v2 for real-time STT and ElevenLabs TTS for the patient's responses. The voice layer adds the communication pressure that text removes; students must structure questions out loud, exactly as in a real OSCE station.
4. Evaluation — Groq + OSCE Framework
The full transcript goes to Groq llama-3.3-70b-versatile with a structured OSCE examiner prompt, scored across four domains (0 to 25 each, total 100):
| Domain | What It Measures |
|---|---|
| History Taking | Systematic coverage of complaint, history, medications, family and social history |
| Clinical Reasoning | Whether questions logically narrowed toward the diagnosis |
| Communication | Clarity, empathy, open to closed question structure |
| Final Diagnosis | Inferred from the conversation, scored against ground truth |
A second Groq call generates the counterfactual, specific questions missed, why each matters clinically, and the ideal consultation order. Students do not learn from scores. They learn from "you never asked about the radiation of the pain, and that was the single most important question."
5. Daily Competition — Neon Postgres
Every day, a new case rotates in. Students are ranked on a live leaderboard by OSCE score. Neon Postgres stores profiles, sessions, and competition attempts. Authentication runs via Google OAuth and NextAuth — students sign in with their university account in one click.
6. Difficulty Levels
| Level | Patient Behaviour |
|---|---|
| Easy | Calm, cooperative, answers directly |
| Medium | Vague on timelines, needs follow-ups |
| Hard | Minimises symptoms, contradicts onset dates, anchors on self-diagnosis, only reveals the key symptom after genuine empathy |
Challenges
Patient consistency across turns. Keeping a 1.5B model in character across 10 to 15 turns without contradicting earlier answers required injecting a running symptom log into every system message, a live record of what the patient had already disclosed.
OSCE scoring reliability. Getting Groq to return consistent, well-calibrated scores required explicit anchors for every score range ("exact match: 23 to 25, correct organ system but wrong diagnosis: 12 to 20") and temperature 0.1.
Human Delta query framing. "What are the symptoms of X" and "X symptoms" return meaningfully different results. Getting reliable symptom extraction required iterating on query structure, not just the index.
Integrating Human Delta into ClinicVerse came with a few unexpected challenges. The SDK's document upload method returns a doc_id field that was
consistently empty — the raw API actually returns id, so we had to bypass the SDK entirely and use direct requests calls to get the real document ID. The
virtual filesystem, while powerful, truncates uploaded document content with a placeholder message ("long extracted text is omitted here so Memory stays
fast"), which meant our initial approach of reading PDFs from /uploads/library/ returned stubs instead of actual text — we pivoted to the
/v1/documents/{id}/preview endpoint which correctly returns the full content_text. On the search side, the sources: ["documents"] and index_id scoping
parameters in the SDK silently dropped — falling back to searching all indexed content including our NHS web crawl — causing irrelevant diseases like
"flu" and "food allergy" to appear in curriculum matches. Once we understood these quirks and worked at the raw API level, Human Delta's document indexing
and preview extraction worked exactly as needed and became a genuine part of the product's value.
What We Learned
Fine-tuning a small model for a narrow behaviour beats prompting a large one for a broad behaviour. A 1.5B model trained on real patient dialogue is a more reliable patient simulator than GPT-4 asked to runs locally, stays in character.
The counterfactual report was the most valued feature in testing. Voice changes everything; latency, turn-taking, and error recovery need explicit design decisions that text hides.
What's Next
1000+ disease library. Scale from 450 to 1000 conditions using Human Delta to index NHS, Mayo Clinic, and MedlinePlus in parallel, keeping the precision extraction pipeline intact.
Smaller on-device model. Migrate from Qwen 2.5-1.5B to SmolLM2-360M (724 MB vs 3 GB). With the improved multi-turn fine-tuning pipeline now in place, the smaller model should match on this narrow task while running entirely on a student's laptop.
Educator dashboard. Cohort analytics on top of the existing Neon session store, which symptoms students consistently miss, which diseases produce low reasoning scores, and which students are falling behind.
Cross-institution leagues. Expand the daily challenge into week-long tables across universities. Medical education has no way to normalise performance across institutions, ClinicVerse's structured OSCE scoring makes this possible.
Examination findings layer. The patient describes what the doctor would find on examination ("when you press there it's very tender"), bridging history-taking practice into physical examination reasoning without a simulation lab.
Built With
- fastapi
- finetuning
- humandelta
- javascript
- knowledgebase
- llm
- neondb
- next.js
- python
- pytorch
- quantization
- rag
- sematicsearch





Log in or sign up for Devpost to join the conversation.