-
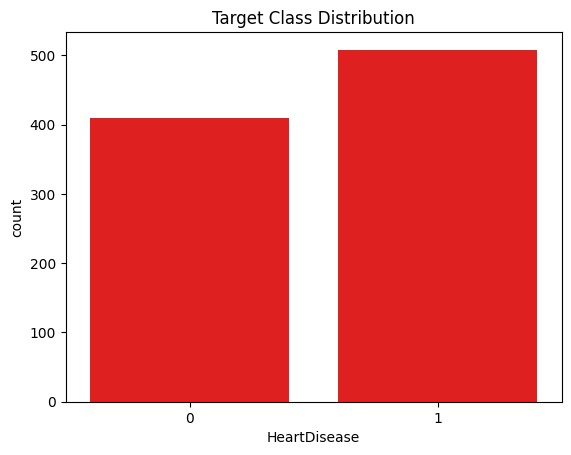
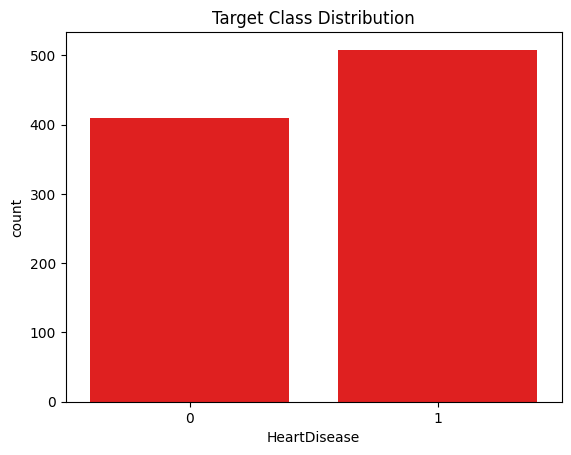
Target class distribution of heart disease outcomes.
-
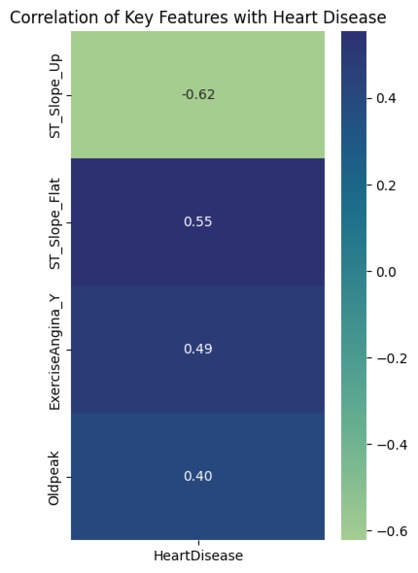
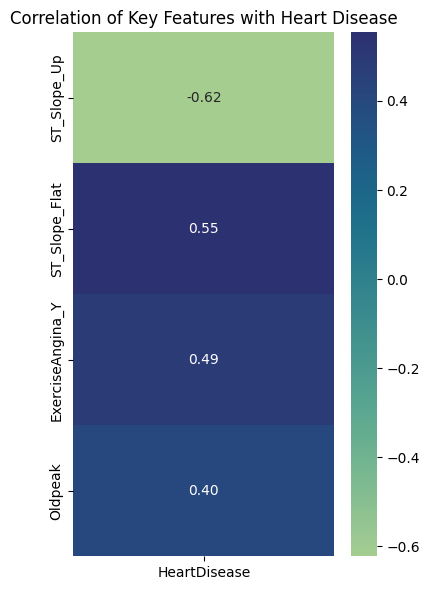
Correlation of selected clinical features with heart disease.
-
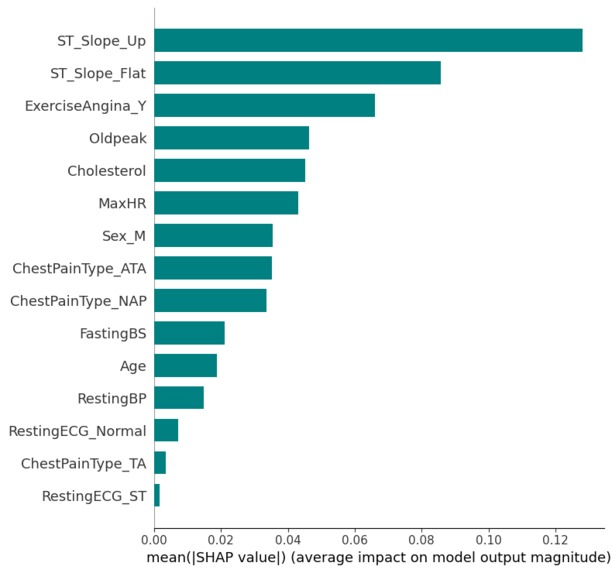
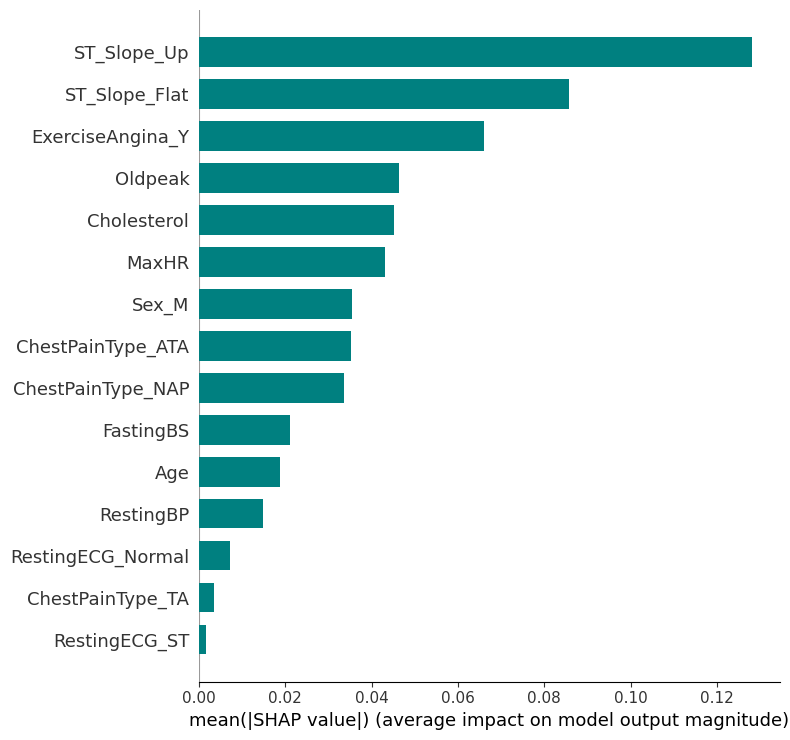
Global SHAP analysis of the Random Forest model.
-
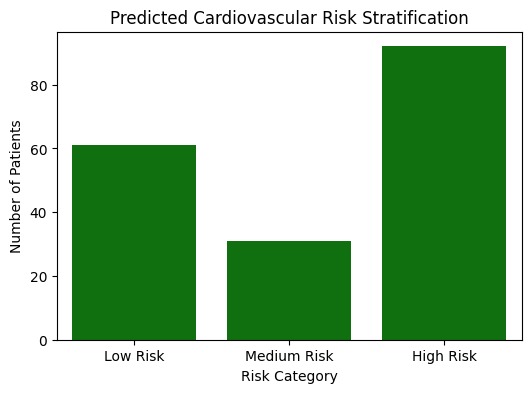
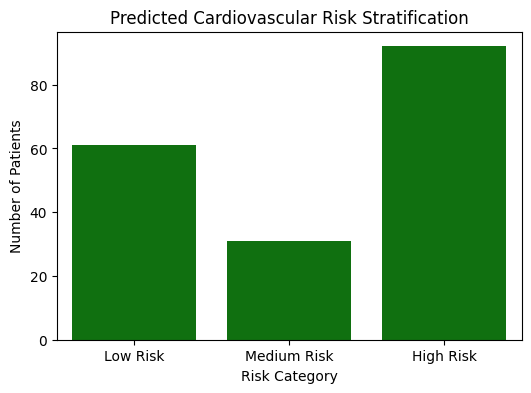
Model-based cardiovascular risk stratification using predicted probabilities.
-
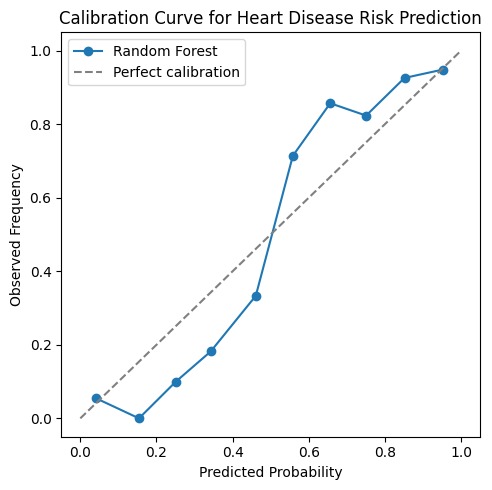
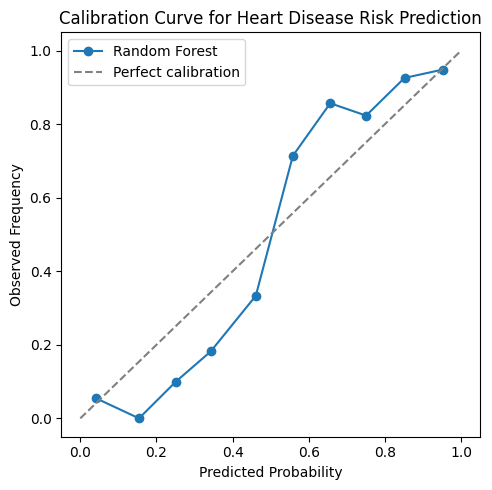
Calibration curve assessing probability reliability of the Random Forest model.
Inspiration
Cardiovascular disease is a leading cause of death, yet many machine learning approaches for prediction focus mainly on improving accuracy while ignoring whether the results are interpretable or usable in real clinical settings.
This project was inspired by the gap between predictive performance and clinical trust. In early screening scenarios, models need to be transparent, reliable, and aligned with medical reasoning. The goal was to explore whether simple, interpretable models could still provide strong performance while producing explanations that clinicians could reasonably trust.
What it does
The project predicts the risk of heart disease using structured clinical data and stratifies individuals into low, medium, and high cardiovascular risk groups.
Instead of producing only a binary prediction, the model outputs calibrated risk probabilities and explains which clinical features contribute most to each prediction. This allows the system to support early screening and triage decisions, rather than acting as a black-box classifier.
How I built it
The workflow began with exploratory data analysis to assess data quality, feature behavior, and class balance. A logistic regression model was first trained as an interpretable baseline to capture linear relationships.
To model non-linear interactions, a Random Forest classifier was then trained and evaluated using ROC-AUC, recall, and confusion matrices, with an emphasis on minimizing false negatives.
SHAP was applied to interpret model predictions and verify alignment with established clinical understanding. Finally, predicted probabilities were calibrated and used to stratify individuals into clinically meaningful risk groups.
Challenges I ran into
One challenge was balancing model performance with interpretability. Increasing complexity can improve accuracy, but it often reduces transparency, which is critical in healthcare settings.
Another challenge was ensuring that predicted probabilities were reliable enough to be used for risk stratification, which required calibration analysis rather than relying solely on ranking metrics like ROC-AUC.
Accomplishments that I am proud of
- Achieving strong predictive performance (ROC-AUC ≈ 0.93) using interpretable models
- Demonstrating consistent clinical patterns across correlation analysis, model coefficients, feature importance, and SHAP explanations
- Moving beyond binary classification by implementing risk stratification and probability calibration
- Framing the model explicitly as a decision-support tool rather than a black-box system
What I learned
This project reinforced the importance of interpretability and calibration in healthcare machine learning. High accuracy alone is not sufficient when model outputs influence screening and triage decisions.
We also learned that well-chosen, simple models combined with careful evaluation and explanation can be more valuable than overly complex approaches in clinical contexts.
What's next for Clinically Interpretable Heart Disease Risk Stratification
Future work could include validating the models across additional cardiovascular datasets to assess robustness and generalizability. Integrating temporal ECG features and exploring subgroup performance across age and sex groups could further improve clinical relevance.
Ultimately, the goal is to extend this work toward a more comprehensive and trustworthy decision-support system for cardiovascular risk screening.
Built With
- googlecolab
- matplotlib
- numpy
- pandas
- python
- scikit-learn
- seaborn
- shap

Log in or sign up for Devpost to join the conversation.