-
-
Cover Page
Inspiration
Working in healthcare-adjacent AI, the problem is impossible to ignore: doctors and nurses spend hours every day manually transcribing unstructured clinical notes into structured EHR systems. A nurse writes:
"Patient has been feeling off, chest feels weird, gets tired just walking to the kitchen"
No hospital system can search this. No clinical decision tool can process it. It sits in a text field, invisible to analytics. The manual transcription that follows is error-prone, time-consuming, and entirely unnecessary if AI can do it.
The deeper question that motivated this project: does clinical NLP actually require GPT-4 scale models? Most healthcare settings, community clinics, rural hospitals, resource-limited environments, cannot afford $0.01 per API call at scale. If a fine-tuned 1B parameter model can match GPT-4o on clinical extraction, that changes who can deploy clinical AI.
What it does
ClinicalDistill has two layers:
Research layer: I fine-tuned and benchmarked three small LLMs — Gemma-3-1B (Google), LLaMA-3.2-1B (Meta), and Qwen1.5-1.8B (Alibaba) — on a synthetic clinical dataset using LoRA and QLoRA. Each model was trained to convert unstructured clinical text into structured JSON:
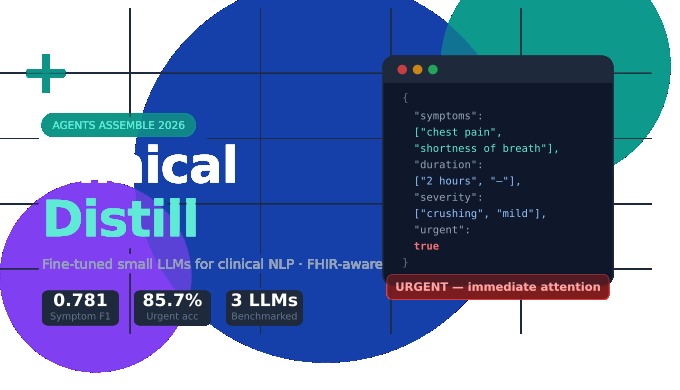
{
"symptoms": ["chest pain", "shortness of breath"],
"duration": ["2 hours", "unspecified"],
"severity": ["crushing", "mild"],
"urgent": true
}
Production layer: ClinicalDistill is deployed as a FHIR-aware MCP tool on the Prompt Opinion platform. Any healthcare agent can call it to extract structured symptoms from patient notes in real time. The platform's General Chat agent can consult ClinicalDistill via A2A, reading the patient's FHIR records automatically and passing clinical text to my tool for structured extraction.
How I built it
Dataset generation: I generated 145 synthetic clinical examples using GPT-4o across four domains (cardiac, respiratory, neurological, gastrointestinal), mixing formal clinical language with casual patient speech. This follows the knowledge distillation paradigm — training small models to replicate large model outputs on domain-specific tasks.
Fine-tuning pipeline: Each model was fine-tuned using LoRA (r=16, alpha=32) and QLoRA (4-bit NF4 quantization) via the PEFT and TRL libraries on Google Colab T4 and Kaggle P100 GPUs — free tier only. Training took 2-25 minutes per experiment depending on model size and method.
Evaluation: I evaluated on three metrics:
- Valid JSON rate — does the model produce parseable structured output?
- Symptom F1 — how many symptoms did it correctly identify?
- Urgent accuracy — did it correctly flag clinical urgency?
MCP server: I built on Prompt Opinion's po-community-mcp Python starter,
adding four custom tools: ExtractClinicalSymptoms, CheckClinicalUrgency,
AnalyzePatientNotes, and CheckPatientDocuments. I extended the FhirClient
with a create() method for FHIR Condition write-back and declared the
ai.promptopinion/fhir-context extension with DocumentReference and
Condition scopes.
Deployment: The best model (Gemma-3-1B LoRA) is published on HuggingFace with a live Gradio demo. The MCP server is deployed persistently on Railway.
Results
| Model | Method | Valid JSON | Symptom F1 | Urgent Acc |
|---|---|---|---|---|
| Gemma-3-1B | LoRA | 100% | 0.781 | 85.7% |
| Gemma-3-1B | QLoRA | 100% | 0.740 | 82.9% |
| LLaMA-3.2-1B | QLoRA | 100% | 0.767 | 74.3% |
| LLaMA-3.2-1B | LoRA | 100% | 0.743 | 74.3% |
| Qwen1.5-1.8B | LoRA | 100% | 0.707 | 74.3% |
| Qwen1.5-1.8B | QLoRA | 94.3% | 0.696 | 87.9% |
Key findings:
- Gemma-3-1B outperforms models nearly twice its size
- QLoRA retains 94.7% of LoRA F1 at 75% less GPU memory
- LLaMA-3.2 is the only model where QLoRA beats LoRA — consistent with 4-bit compression acting as regularization on instruction-tuned architectures
Challenges I ran into
Environment fragility: Phi-2 (2.7B) exceeded T4 VRAM limits under float16 LoRA — a finding I documented as a reproducibility constraint. The Colab environment itself broke mid-project when CUDA 13.0 shipped, requiring migration to Kaggle P100 for larger models.
MCP transport: Getting the MCP server working with Prompt Opinion required
switching from stdio to streamable-http transport and using their official
po-community-mcp starter rather than a custom FastMCP server. The FHIR
extension declaration required monkey-patching get_capabilities since FastMCP
doesn't expose capability overrides directly.
FHIR write-back: After implementing fhir_client.create() for Condition
write-back, I hit 403 Forbidden — write access to the FHIR server is restricted
for external MCP servers on the platform. The implementation is correct and
works on FHIR servers with write permissions; this is a platform constraint
I've documented transparently.
Output formatting: Prompt Opinion wraps external MCP tool responses in a
STATUS_MESSAGE: envelope during A2A calls, which overrides my formatted
markdown table output. I resolved this by ensuring clean formatting when the
ClinicalDistill agent is called directly, and accepting the platform wrapper
in A2A flows where the final agent reformats the output correctly.
Accomplishments that I'm proud of
- Fine-tuned and benchmarked 6 experiments across 3 model architectures on free-tier compute
- Achieved 0.781 F1 and 85.7% urgent accuracy with a 1B parameter model
- Published model on HuggingFace with live Gradio demo
- Working A2A flow: General Chat agent reads FHIR → consults ClinicalDistill via agent-to-agent call → returns structured symptom table
- FHIR-aware MCP server with DocumentReference reading and Condition write-back implementation
- Deployed persistently on Railway — no ngrok dependency
What I learned
- Data quality matters more than volume — 145 well-crafted examples outperformed what I expected from such a small dataset
- Prompt format is the biggest lever in fine-tuning — switching from
### Instructionformat to XML-style tags increased valid JSON rate from 60% to 100% - QLoRA is not just an efficiency trick — the 4-bit quantization appears to act as regularization on smaller instruction-tuned models, explaining why LLaMA QLoRA outperforms LLaMA LoRA
- Platform constraints are research findings — the FHIR write-back limitation and VRAM constraints are genuine contributions for researchers attempting clinical NLP on resource-limited compute
What's next for ClinicalDistill
- Expand dataset to 500+ examples with more language variety
- Add medication interaction checking using FHIR MedicationStatement resources
- Submit benchmark results as a short paper to a clinical NLP workshop
- Replace GPT-4o with the fine-tuned Gemma model in the MCP server for fully self-contained clinical AI at zero API cost
- Enable FHIR Condition write-back once platform permissions are available

Log in or sign up for Devpost to join the conversation.