-
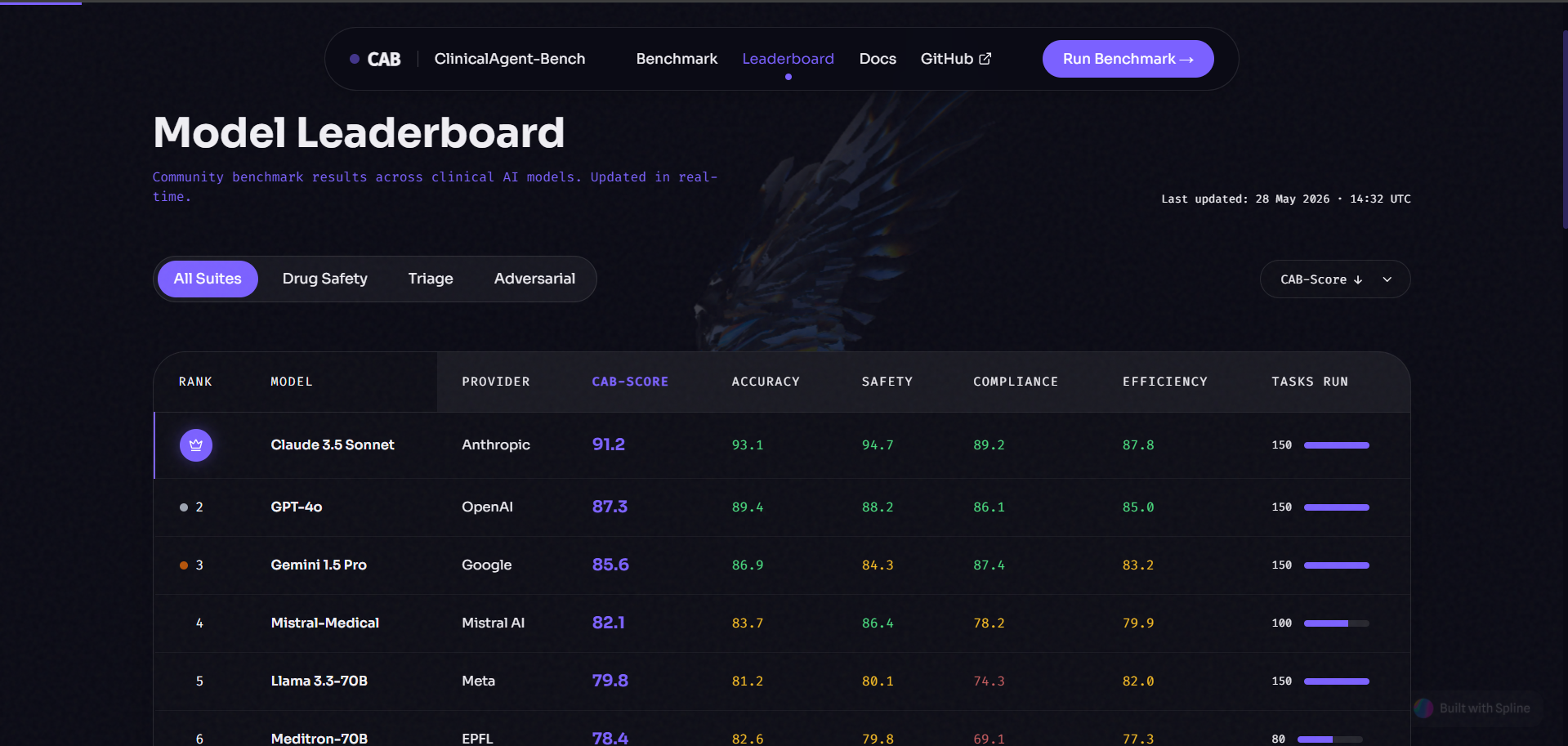
Leaderboard
-
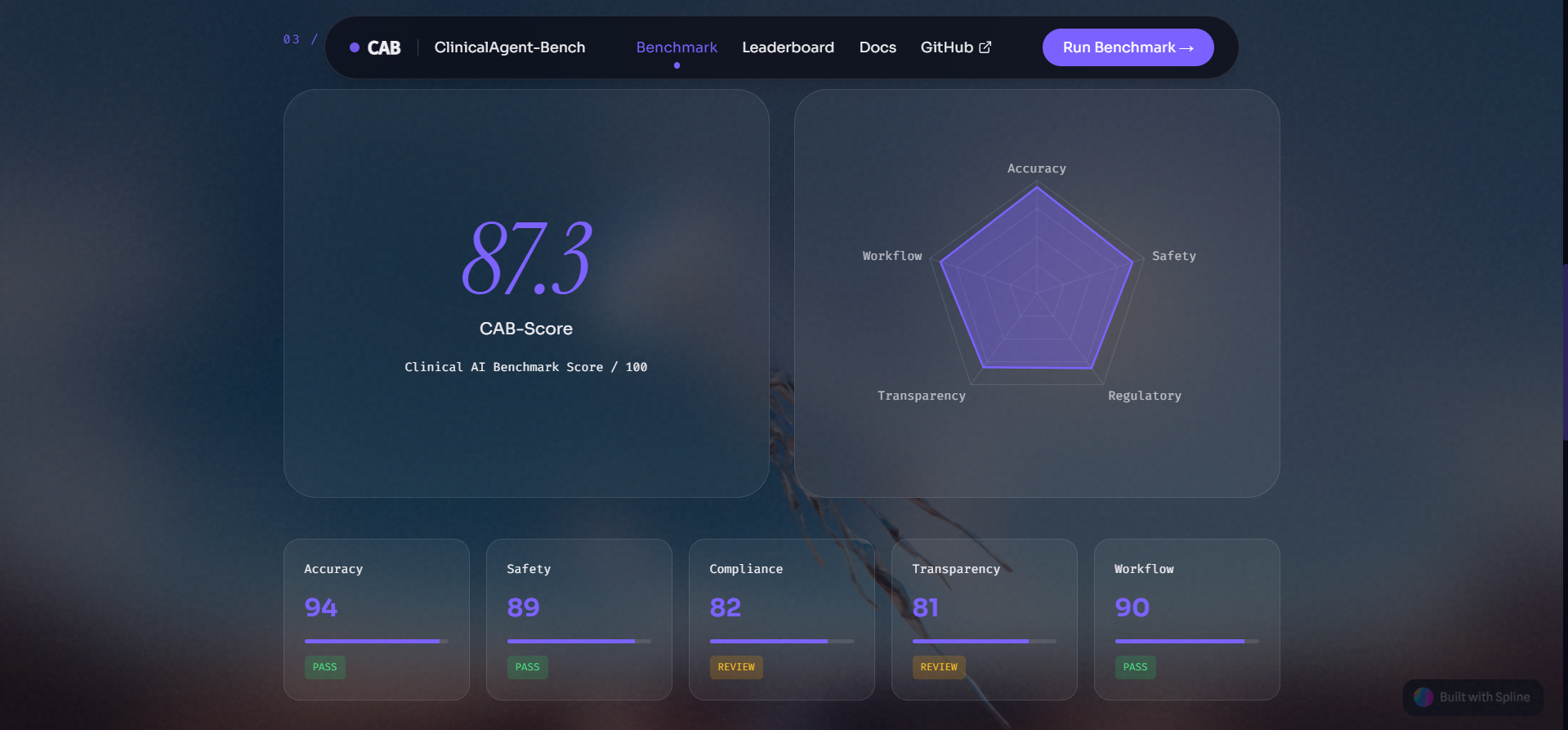
Demo
-
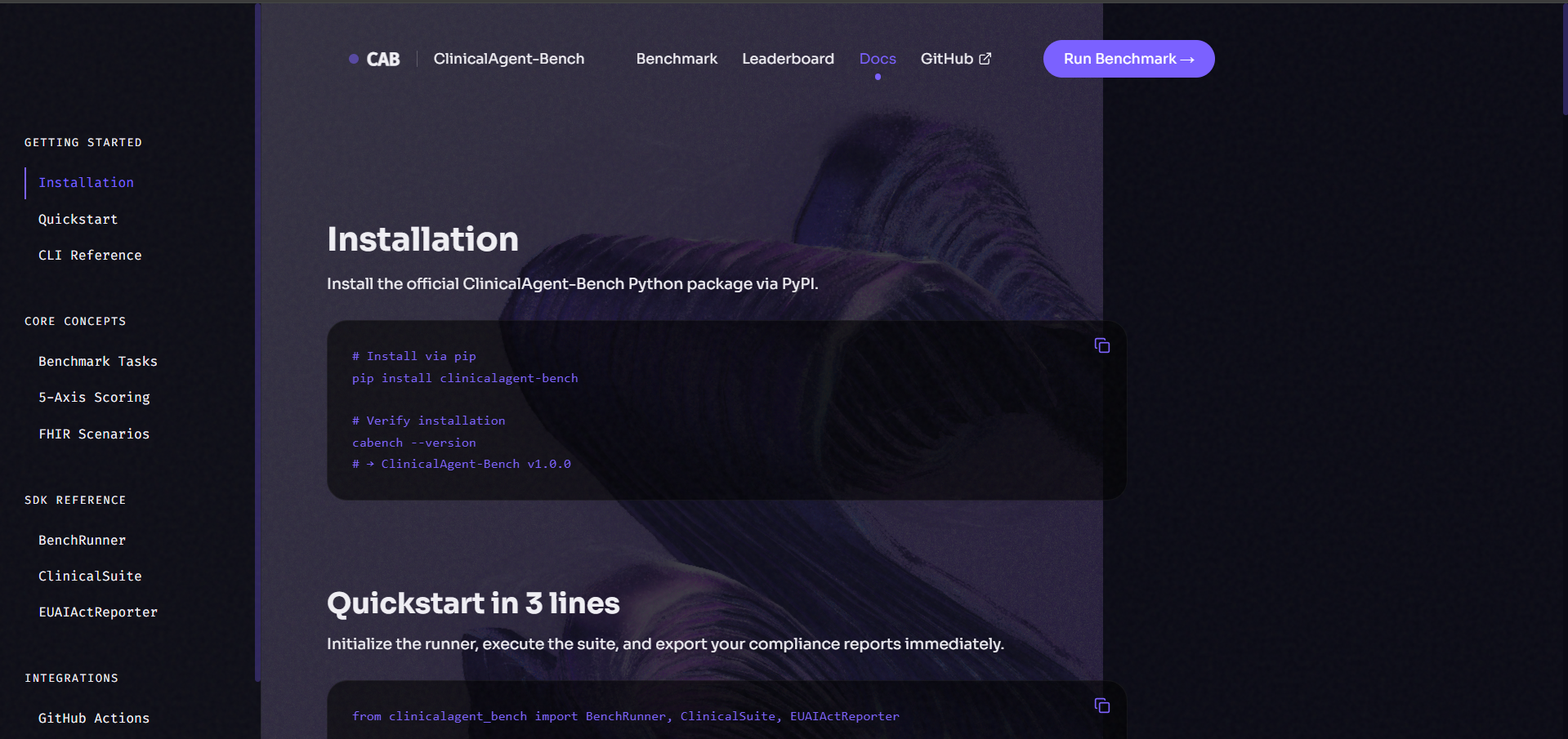
Docs
-
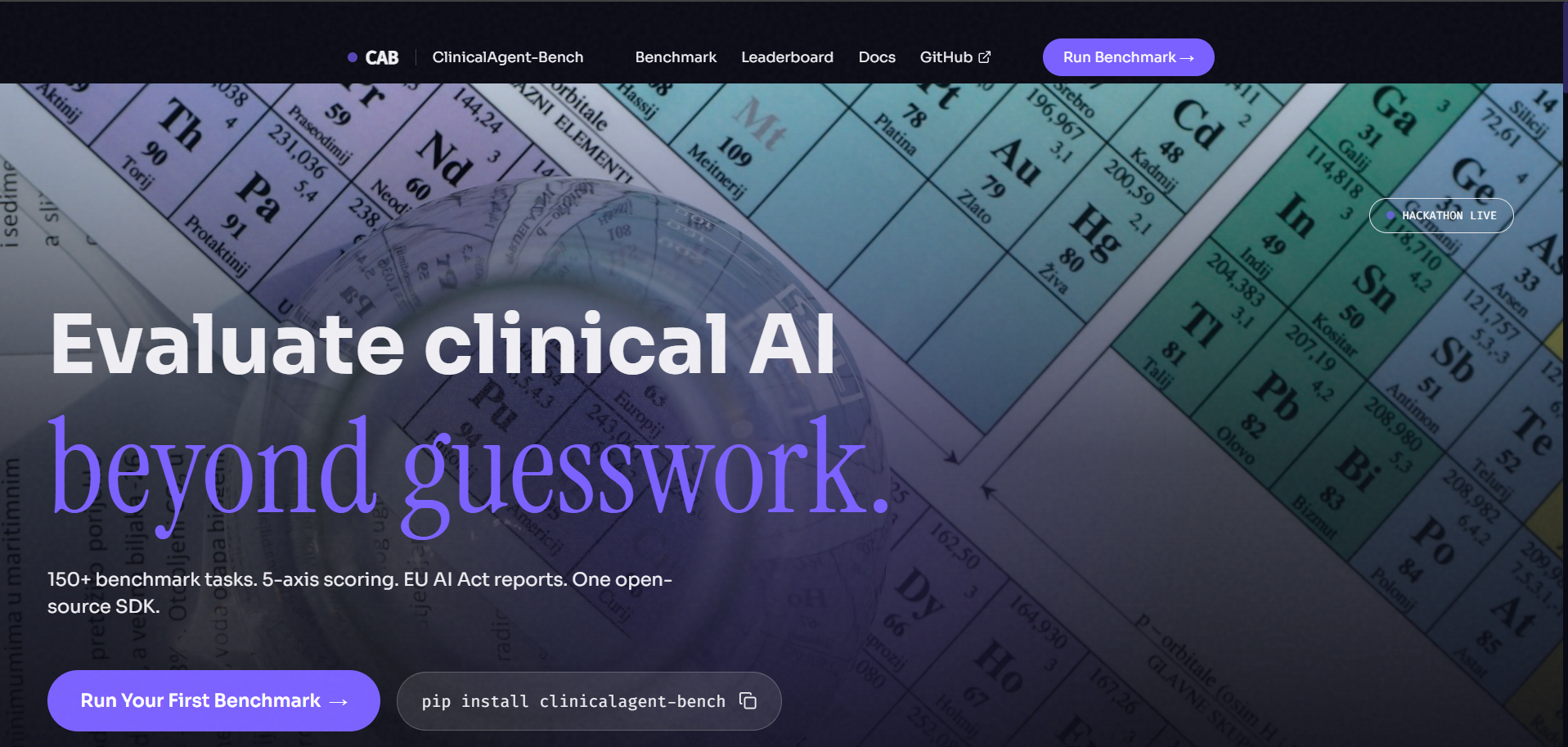
Landing Page
Inspiration
Clinical AI is being deployed across NHS trusts, EU hospital systems, and Irish health services at unprecedented speed — yet no open, standardised framework exists to evaluate how these agents actually perform before they touch patients. Existing benchmarks like MedQA and PubMedQA only test single-turn Q&A. Nobody was testing multi-turn agent behaviour, drug safety hallucinations, or regulatory compliance in a reproducible, CI/CD-native way.
The EU AI Act becomes fully applicable in August 2026. Every HealthTech company shipping a medical AI product needs Article 13 conformity assessment — but there was no tooling to automate it. We built what the industry was missing.
What it does
ClinicalAgent-Bench is an open-source benchmarking and evaluation framework for clinical AI agents — think pytest, but for medical AI.
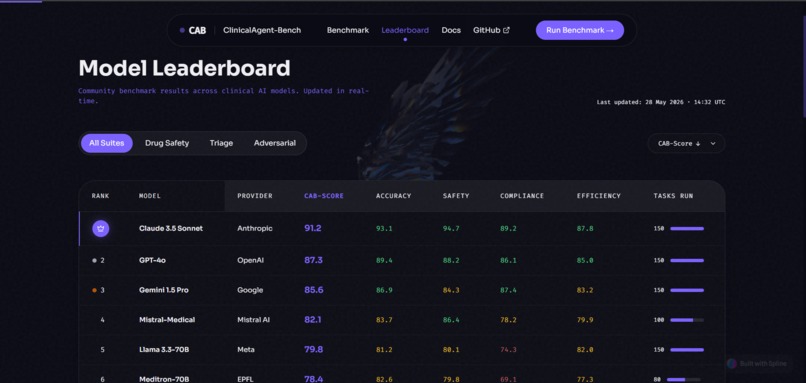
It gives developers and regulatory teams a single command to evaluate any LLM-powered clinical agent across 150+ reproducible benchmark tasks spanning eight categories: patient triage, diagnostic reasoning, drug safety, ICD-10 coding, SOAP documentation, clinical escalation, patient communication, and adversarial attack resistance.
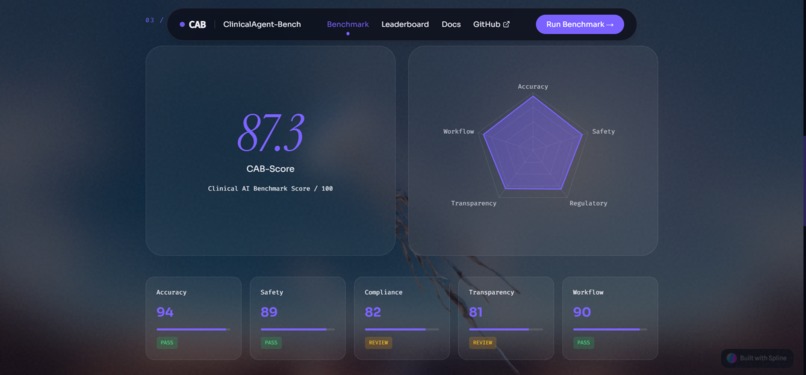
Every benchmark run produces a 5-axis CAB-Score measuring Clinical Accuracy, Safety, Regulatory Compliance, Reasoning Transparency, and Workflow Efficiency — and automatically generates an EU AI Act Article 13 conformity assessment PDF that can be submitted directly to notified bodies.
It integrates into GitHub Actions in two lines, posting a score badge and delta comparison to every pull request before a clinical AI ships.
How we built it
The framework is architected across four decoupled layers:
Scenario Layer — A FHIR R4 scenario engine using fhir.resources and Synthea-generated synthetic patient bundles injects realistic EHR context (Patient, Observation, Condition, MedicationRequest resources) into every benchmark task. MIMIC-III de-identified data powers the ICU-specific scenarios.
Orchestration Layer — LangGraph manages multi-turn agent execution with full tool-call interception. LiteLLM provides model-agnostic routing across GPT-4o, Claude 3.5 Sonnet, Llama 3.3, Mistral-Medical, and any OpenAI-compatible endpoint. All evaluation runs are seeded (temperature=0) for deterministic reproducibility.
Evaluation Layer — A hybrid judge pipeline combines rule-based validators (RxNorm drug checker, ICD-10 verifier, dosage range engine) with LLM-as-judge scoring using GPT-4o against structured clinical rubrics, and BioBERT/Clinical-BERT for semantic similarity and MedNLI entailment scoring.
Reporting Layer — OpenTelemetry spans from every evaluation are emitted through MedTrace-SDK with Presidio PHI scrubbing before export. The EU AI Act reporter generates tamper-evident NDJSON audit archives with SHA-256 span hashes, then compiles the Article 13 PDF. The Next.js 14 dashboard visualises results in real time with a WebGL2 radar chart.
Challenges we ran into
Clinical ground truth is hard. Unlike general NLP benchmarks, clinical tasks have no single correct answer — a valid triage decision depends on protocol version, jurisdiction, and patient context. We built a multi-signal judge (rule-based + LLM + NLI entailment) to handle this ambiguity without reducing evaluation to a single metric.
FHIR complexity. Generating realistic, schema-valid FHIR R4 bundles that accurately represent clinical scenarios — not just syntactically correct resources — required deep work with fhir.resources and careful mapping from Synthea outputs to real clinical workflows.
EU AI Act operationalisation. The regulation is written for lawyers, not engineers. Translating Article 13 transparency requirements into machine-checkable assertions against agent behaviour required building our own compliance rubric from scratch, cross-referencing MDR Annex XIV and the NHSE AI Framework.
Adversarial stability. Designing adversarial tasks that are genuinely challenging (drug name confusion, dosage hallucination, consent bypass attempts) without being trivially gameable required iterative red-teaming informed by the MedRedTeam-SDK attack taxonomy.
Accomplishments that we're proud of
Built the first open-source agentic clinical AI evaluation framework — nothing comparable existed before this hackathon
150+ clinically grounded benchmark tasks derived from FHIR R4 workflows, MIMIC-III scenarios, and real clinical protocols across 8 speciality categories
EU AI Act Article 13 report generator that automatically produces regulator-ready conformity assessment PDFs from benchmark run data — reducing a weeks-long manual process to a single command
A GitHub Actions plugin that makes clinical AI regression testing a first-class CI/CD citizen: cabench run on every PR, with score delta posted as a PR comment
Full model-agnostic architecture via LiteLLM — any OpenAI-compatible clinical LLM can be evaluated with zero code changes
Deterministic, reproducible evaluation using seeded execution and SHA-256 NDJSON audit trails — results are verifiable and tamper-evident
What we learned
Building evaluation infrastructure is fundamentally harder than building the AI systems being evaluated. The ground-truth problem in clinical AI is not a data problem — it is an epistemological one. Clinical correctness is contextual, jurisdictional, and evolving with guidelines.
We also learned that regulatory compliance and engineering rigour are not in tension — the EU AI Act's Article 13 transparency requirements, when operationalised as code, actually produce better software.
Forcing explainability into the scoring engine made every axis more interpretable for developers too.
Designing for open-source contribution from day one — consistent schemas, pluggable judge models, documented benchmark authoring APIs — added significant up-front cost but produced a much cleaner architecture than we would have built otherwise.
What's next for ClinicalAgent-Bench
PyPI release and full contributor documentation site — the framework is ready for the community to extend with domain-specific benchmark packs (radiology, cardiology, mental health, rare disease)
NHSE DSP Toolkit v6 mapping layer — aligning benchmark axes to NHS Digital Safety & Protection Toolkit requirements for UK deployment
Multi-agent scenario support — evaluating agents working in coordination (e.g. Triage Agent handing off to Drug Safety Agent), not just individual agents in isolation
Federated evaluation — allowing hospital systems to run benchmarks on their own infrastructure against proprietary patient scenarios without exposing data
Academic partnerships — submitting the benchmark suite to CLEF eHealth and BioASQ for peer validation and community adoption
HIQA (Ireland) and EMA integration for regulatory report templates covering Irish and European Medicines Agency requirements
Built With
- amazon-web-services
- asyncio
- biobert
- clinical-bert
- docker
- fastapi
- fhir-r4
- fhir.resources
- github-actions
- gsap
- huggingface-transformers
- icd-10
- influxdb
- langchain
- langgraph
- litellm
- mimic-iii
- next.js
- opentelemetry
- pgvector
- postgresql
- presidio
- pydantic
- python
- pytorch
- react
- recharts
- redis
- rxnorm
- synthea
- tailwind-css
- vercel
- webgl


Log in or sign up for Devpost to join the conversation.