-
-
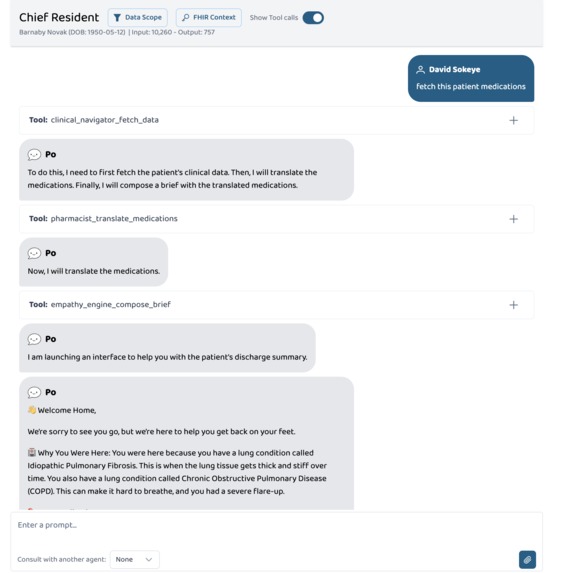
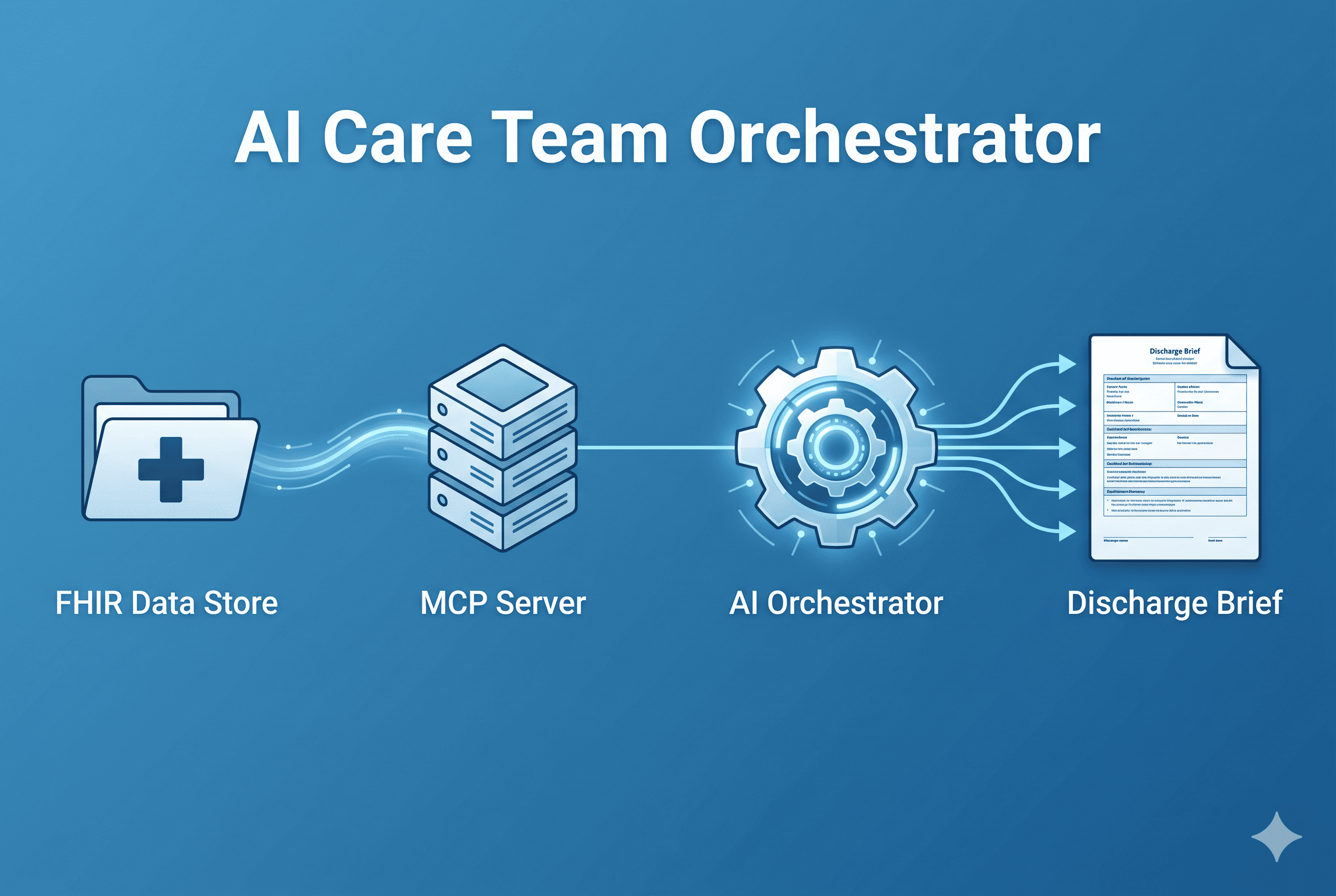
Tool calling sequence and result
-
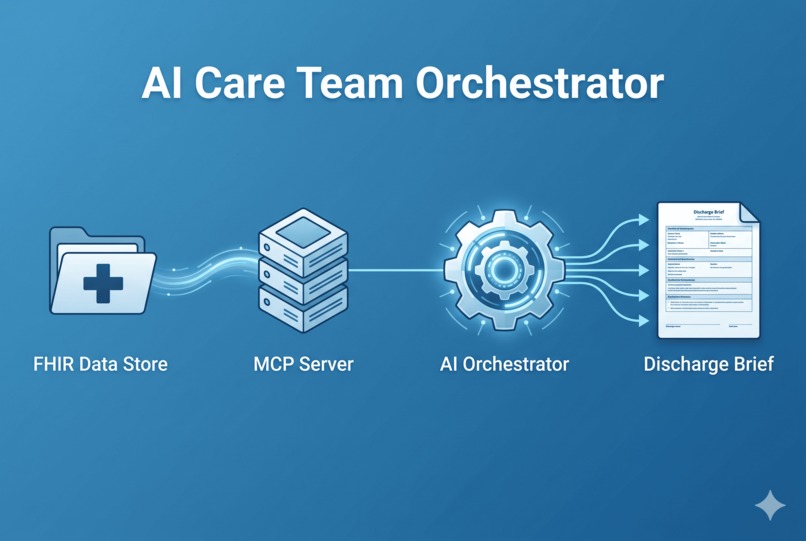
data flow
Inspiration
Medicine is a science of precision, but healing requires connection. When patients leave the hospital, they are often at their most vulnerable, yet we hand them discharge papers filled with cold, structured FHIR data and complex clinical jargon. The inspiration for this project came from a grounded realization: the "last mile" of healthcare isn't a medical problem, it is a communication problem. The most advanced treatment plan in the world is entirely useless if the patient cannot understand how to follow it. We built the Clinical-to-Patient Bridge because we recognized a gap between what machines process and what humans need. Advanced AI and multi-agent orchestration shouldn't just be used to compute more data; they should be used to translate that complexity into clarity and empathy. We believe that providing accessible, jargon-free instructions isn't just a convenience ; it is a fundamental standard of care.
What it does
Clinical-to-Patient Bridge is a multi-agent orchestration system built on the Prompt Opinion (PO) AI platform, using the Model Context Protocol (MCP) to connect a chain of specialized AI agents to live FHIR electronic health records.
A physician or care coordinator can simply tell the system: "Discharge this patient and prepare a brief."
What happens next unfolds in three automatic steps:
🧭 Step 1 — The Clinical Navigator The Clinical Navigator securely connects to the hospital's FHIR server using the patient's authenticated SMART-on-FHIR token. It fetches:
Active diagnoses and conditions All prescribed, historical, and administered medications Diagnostic and laboratory reports It does this in parallel — five FHIR API calls simultaneously — with built-in 8-second timeouts to ensure the system stays responsive even on slow networks. All data is cached server-side, keyed by patient ID, so it never needs to be re-fetched or echoed back through the AI model's output stream.
💊 Step 2 — The Pharmacist The Pharmacist reads the raw medication data from the server cache and applies a clinical abbreviation translation layer:
PO → by mouth BID → twice daily PRN → as needed IV → intravenously and dozens more standard dosing abbreviations This translation happens entirely server-side — no large language model tokens are consumed for this conversion. It's fast, deterministic, and reliable. The translated medications are stored back in the cache for the next agent.
💙 Step 3 — The Empathy Engine The Empathy Engine reads the full patient profile from cache — name, conditions, translated medications, and diagnostic reports — and generates a structured, warm, human-readable discharge brief with seven sections:
Welcome Home — a personal, encouraging greeting by name Why You Were Here — conditions explained in plain language Your Medications — the translated medication list, clearly formatted What Your Tests Showed — diagnostic results in accessible terms Taking Care of Yourself — 5 practical recovery tips When to Call Your Doctor — specific warning signs Note from Your Care Team — an encouraging, human close The entire brief is generated server-side by the MCP tool — meaning the LLM on the PO platform only needs to display it, not write it. This eliminates output token exhaustion entirely and ensures the brief is always complete, never truncated.
How we built it
Where It All Began: The Orchestrated Agent Approach The original architecture was straightforward, at least on paper.
We started by building a classic multi-agent system on the Prompt Opinion platform. The idea was to have a central orchestrator agent — the Chief Resident — that would receive a discharge request and delegate to three specialist sub-agents in sequence. Each agent had a clearly defined role and a carefully written system prompt.
The Chief Resident would call the Clinical Navigator agent, wait for its response, pass that data to the Pharmacist agent, and then hand everything off to the Empathy Engine to write the final brief. Clean, logical, and exactly how you would picture a modern agentic AI system working in a healthcare setting.
The problem surfaced immediately during testing.
When the Chief Resident delegated to a sub-agent, the Prompt Opinion platform assigned each agent an internal ID at registration time. But when the orchestrator tried to invoke a sub-agent at runtime, the ID it held in memory did not match the ID the platform used to look up that agent. Every delegation call failed silently. The platform would acknowledge the call, spin briefly, and return nothing.
This was a platform-level bug — not something we could patch from the application side. We raised it, confirmed it was reproducible, and then made a decision: we were not going to wait for a fix with a deadline in the room.
The Pivot: An Agent Is Just a Fancy Tool
That night, staring at the failed delegation logs, the thought crystallised into something simple and freeing:
An agent is just a fancy tool.
At its core, a Prompt Opinion agent is a named function with a system prompt, some input context, and an output. It reads data, reasons about it, and returns a response. That is precisely what an MCP tool does. The only meaningful difference is branding.
So we scrapped the sub-agent delegation model entirely.
Instead of three agents calling each other through the platform's agent layer, we re-implemented each specialist as a discrete MCP tool registered on the server. The Clinical Navigator became a tool called clinical_navigator_fetch_data. The Pharmacist became pharmacist_translate_medications. The Empathy Engine became empathy_engine_compose_brief.
The Chief Resident agent was kept as the single orchestrating presence, now configured as a BYO (Bring Your Own) agent with a carefully written system prompt that instructed it to call these tools in strict sequence — one at a time, with a spoken response to the user between each step.
This reframe solved the delegation bug completely. More than that, it produced an architecture that was tighter, faster, more transparent, and infinitely more debuggable. We could see exactly what each tool received, what it returned, and how the LLM responded at every step. The agentic illusion was preserved in the UI — three named specialists, doing distinct jobs, in order — but the underlying wiring was clean and deterministic.
Building the Server: MCP Over HTTP with FHIR Context
The MCP server was built in TypeScript using the official MCP SDK from Model Context Protocol, running over a stateless HTTP transport with Express.
Every incoming request from Prompt Opinion carries two critical HTTP headers: the FHIR server base URL and a SMART-on-FHIR Bearer token signed as a JWT. The token contains the patient's ID embedded in its claims, which means we never have to ask the LLM which patient to look up. We decode the JWT on the server, extract the patient ID, and pass it directly to the FHIR queries.
No user input. No prompt injection risk. No ambiguity.
The server registers the three tools on each request, connects them to a streaming HTTP transport, and closes cleanly when the connection ends. Stateless, ephemeral, and safe.
For local development and Prompt Opinion connectivity, we used ngrok to tunnel the local port to a public HTTPS endpoint, which PO requires for any BYO MCP server.
The FHIR Problem: Synthetic Patients Were Too Simple
This is where things got interesting.
Prompt Opinion's built-in FHIR demo environment populates patients with very basic, single-condition records. A patient might have hypertension and one prescription. That is fine for a connectivity test, but it does nothing to showcase the actual strength of the system — its ability to take genuinely complex, multi-layered clinical data and translate it into language a six-year-old could understand.
We needed patients who reflected the real world: elderly, multi-morbid, on five or six medications with overlapping dosing schedules, abbreviation-heavy instructions, and diagnostic reports with clinical conclusions that mean nothing to a layperson.
So we built them ourselves.
A Python script was written to generate a complete FHIR R4 bundle for fifteen synthetic patients, each with a distinct and medically realistic profile. The script used the fhir.resources library to construct valid FHIR-compliant resource objects — not hand-crafted JSON, but properly typed FHIR R4 instances that would pass validation on a live FHIR server.
Each patient was given:
Between two and five active diagnoses drawn from a curated list of complex, multi-syllable conditions: Idiopathic Pulmonary Fibrosis, Chronic Obstructive Pulmonary Disease, Atrial Fibrillation with Rapid Ventricular Response, Type 2 Diabetes Mellitus with peripheral neuropathy, Stage 3 Chronic Kidney Disease, Congestive Heart Failure with reduced ejection fraction, and more.
Between three and seven medications, each with full clinical dosing notation. Things like "Spironolactone 25mg PO QD", "Furosemide 40mg IV BID PRN", "Metformin 500mg PO TID AC", "Warfarin 2.5mg PO QHS with INR monitoring", and "Salbutamol 100mcg inhaled PRN via MDI". Every abbreviation intentional. Every dosage realistic. Every route clinically appropriate.
One or two diagnostic reports with typed conclusions: echocardiogram findings describing "EF of 35% with dilated left ventricle", spirometry results showing "FEV1/FVC ratio of 0.58 consistent with moderate obstruction", or HbA1c readings annotated with clinical interpretation.
The bundle was uploaded to a self-hosted HAPI FHIR server instance, which was then pointed to from the Prompt Opinion FHIR context. Suddenly, instead of testing against "John Smith, hypertension, one tablet daily", we were testing against patients like Barnaby Novak — a 75-year-old with four comorbidities, six medications, and a cardiology report no non-clinician could interpret.
When the Empathy Engine processed Barnaby's records and produced a discharge brief that opened with "Welcome home, Barnaby! We're so glad you're feeling better" and explained his Atrial Fibrillation as "an irregular heartbeat that causes your heart to beat too fast sometimes, like it's running when it should be walking" — that was the moment the project justified itself.
The Token Exhaustion Problem and the Caching Architecture Even with the tool-based architecture working, a new problem emerged.
Each tool call completes and returns its result to the LLM. The LLM uses that result as context to formulate its next action. In early versions, the Clinical Navigator returned the full extracted FHIR data — conditions, medications, reports — as text in its tool response. The Pharmacist would then receive that text and attempt to translate it. The Empathy Engine would receive the translated medications and attempt to write the brief.
The problem was output tokens. Prompt Opinion imposes a strict per-turn output limit on the LLM. When the Pharmacist's tool response included a full medication list, the LLM tried to pass that list as an argument to the Empathy Engine — a process that consumed its entire remaining output budget before it could finish the tool call. The conversation would stop at 28 output tokens. Every time.
The solution was a server-side in-memory cache, implemented in a dedicated module called pipeline-state.ts.
The cache is a simple Map keyed by patient ID. When the Clinical Navigator fetches FHIR data, it extracts only the fields it needs — condition display names, medication names and dosage text, report types and conclusions — and stores them in the cache. It then returns a one-line summary to the LLM: something like "Retrieved Amina Dubois' records. Three conditions, four medications, one report." Nothing more.
The Pharmacist reads from the cache directly. It never touches the LLM's context for the medication list. It performs its abbreviation translations server-side using a lookup table of over twenty clinical abbreviations, stores the translated results back in the cache, and returns a single sentence: "Four medications translated. Now composing the brief."
The Empathy Engine pulls everything from the cache — patient name, conditions, translated medications, reports — and generates the full discharge brief as a server-side string, structured with markdown sections and emoji headers. The LLM receives the complete brief as the tool's return value and simply displays it.
The LLM never writes clinical content. The LLM never echoes medication data. The LLM's entire output budget across the three tool calls amounts to roughly sixty tokens: three tiny tool call invocations and a few short relay sentences. Everything else — all the actual clinical processing — happens in our server code.
Cache entries auto-expire after five minutes to prevent stale data across sessions. A background interval runs every two minutes to prune expired entries.
Enforcing Sequential Execution
One final challenge was subtle but critical.
Prompt Opinion's model, when presented with multiple available tools and no explicit instruction to think between steps, defaults to parallel batching. It fires all tool calls it can predict in a single turn — Navigator, Pharmacist, and Empathy Engine simultaneously — before the cache has been populated by the Navigator. This causes the Pharmacist and Empathy Engine to read empty caches and fail.
Two mechanisms were used to enforce strict sequential execution.
First, the Pharmacist and Empathy Engine both check for cache presence on startup. If the cache is empty, they return an explicit error instructing the LLM to restart from Step 1. This is the hard gate.
Second, each tool's response is written as a natural conversational sentence that implies a next action. The Navigator's response ends by mentioning the Pharmacist. The Pharmacist's response ends by mentioning the Empathy Engine. This conversational cadence, combined with a system prompt that explicitly instructs the agent to relay each tool result to the user before calling the next tool, breaks the parallel batching pattern and restores the sequential flow.
The result is the tool-response-tool-response-tool-response rhythm that the UI displays — three visible tool calls, each followed by a short spoken relay from the agent, culminating in the full discharge brief as the final response.
The Stack, End to End
Platform: Prompt Opinion with FHIR Context and BYO MCP App MCP Server: TypeScript, MCP SDK, Express, StreamableHTTPServerTransport FHIR Client: Axios with SMART Bearer token auth, typed with @smile-cdr/fhirts Patient Data: FHIR R4 bundles generated via a custom Python script using the fhir.resources library, uploaded to a HAPI FHIR server Tunnel: ngrok (persistent URL for PO connectivity) Caching: In-memory Map with TTL expiry in pipeline-state.ts Medication Translation: Server-side abbreviation lookup, no LLM tokens consumed Brief Generation: Fully server-side template with markdown formatting Repository: github.com/dayveedd/clinical-to-patient-bridge-MCP
Final Results
Agent and MCP tool callimg in action

Empathy Engine Output

Challenges we ran into
Building this was not straightforward. Several platform-level constraints had to be innovated around:
Output Token Exhaustion Prompt Opinion limits the LLM's output tokens per conversational turn. Early versions of the system asked the LLM to translate medications and write the brief in its output — which hit the ceiling and caused the pipeline to stop mid-way. The solution was to move all heavy computation server-side, leaving the LLM responsible only for tool dispatch and relaying results.
Parallel Tool Batching PO's model, when given multiple tools with no text instruction in between, fires all tools simultaneously in a single "batch" and then stops — never completing the chain. This was solved by designing each tool's response as a conversational statement (e.g., "Now consulting the Pharmacist...") that prompts the LLM to respond with text before calling the next tool — enforcing strict sequential execution.
Agent ID Mismatch The PO platform had a bug with multi-agent delegation via its native agent system agent IDs assigned during registration didn't match during runtime fetching. Rather than waiting for a platform fix as I joined the hackathon a bit late, the entire multi-agent system was re-architected as MCP tools — with each "agent" implemented as a discrete, stateless server-side tool. This turned a platform limitation into an architectural advantage: no orchestration overhead, no delegation latency, deterministic tool ordering.
Send Agent Message Error

PO agent calling error

- FHIR Data Volume A full patient FHIR bundle can exceed 1,000 lines of JSON. Passing this through the LLM would be catastrophically token-expensive. The system never does this. It extracts only what is needed at query time — condition name, medication name and dosage, report conclusion — and discards the rest. The LLM sees only clean, structured summaries.
Accomplishments that we're proud of
I am incredibly proud of the architectural resilience and technical problem-solving this project required. During development, I encountered a critical beta routing bug on the platform where dynamic Agent IDs failed during Agent-to-Agent (A2A) orchestration. Instead of abandoning the multi-agent approach, I rapidly re-architected the payload flow. I flattened the hierarchy and integrated the sub-agents as direct Tool Calls governed by the Chief Resident. This pivot ensured zero downtime and preserved the strict separation of concerns required for clinical safety.
Furthermore, I am proud of the Server-Side State innovation. Passing thousands of raw FHIR tokens between agents usually exhausts LLM context windows and causes rate limits. By designing the Master Contextual Provider (MCP) to hold the FHIR data in a secure, server-side cache, the agents read from the cache internally. This resulted in zero token exhaustion, bulletproof orchestration , and a pipeline that successfully transforms complex codes like "PO BID PRN" into empathetic, 6th-grade-level care plans
What we learned
The most important lesson from this build was also the most counterintuitive one.
The more we tried to use the LLM to do the work — translate medications, write the brief, orchestrate the pipeline, the more the system broke. Output limits, hallucinations, parallel batching, interface launch messages, all of them symptoms of the same root cause: we were asking a language model to do things a program does better.
The breakthrough came when we shifted the question. Instead of "how do we prompt the LLM to do this correctly?", we asked "how do we make the LLM's job as small as possible?"
The LLM's job in this system is three things: dispatch the right tool at the right time, relay what it finds to the user in natural language, and display the final brief. Everything else: fetching, translating, composing, caching, is server code.
That division of responsibility is not a limitation. It is the architecture.
What's next for Clinical-To-Patient-Bridge
While the foundation of the Clinical-to-Patient Bridge is complete, the vision for the "last mile of healthcare" is just beginning. The immediate next steps include:
EHR Integration: Expanding the MCP server capabilities to handle live, secure OAuth2 connections with major Electronic Health Record systems like Epic and Cerner, rather than a local FHIR data store.
Multilingual Empathy: Upgrading the Empathy Engine to automatically translate the 6th-grade reading level discharge briefs into the patient's native language, breaking down both clinical and cultural language barriers.
Built With
- fhirclient
- geminiai
- mcpserver
- ngrok
- promptopinion
- typescript

Log in or sign up for Devpost to join the conversation.