-
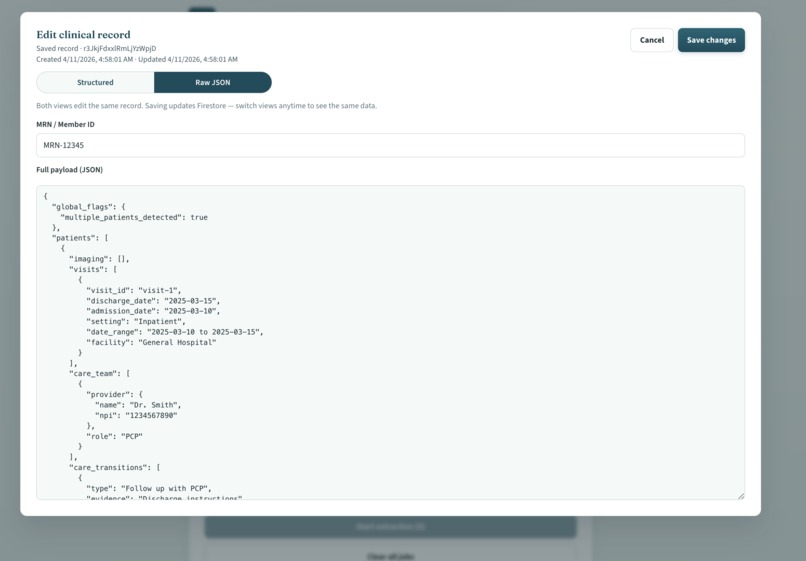
Example JSON Output
-
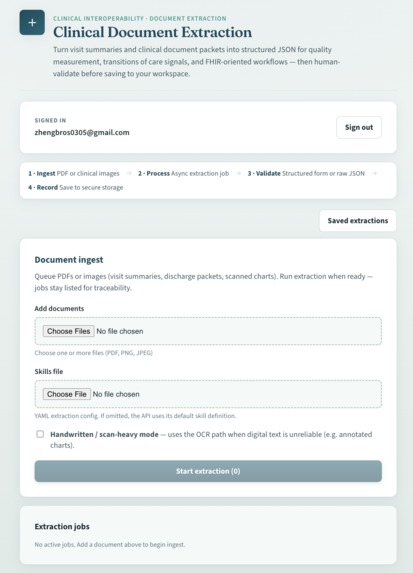
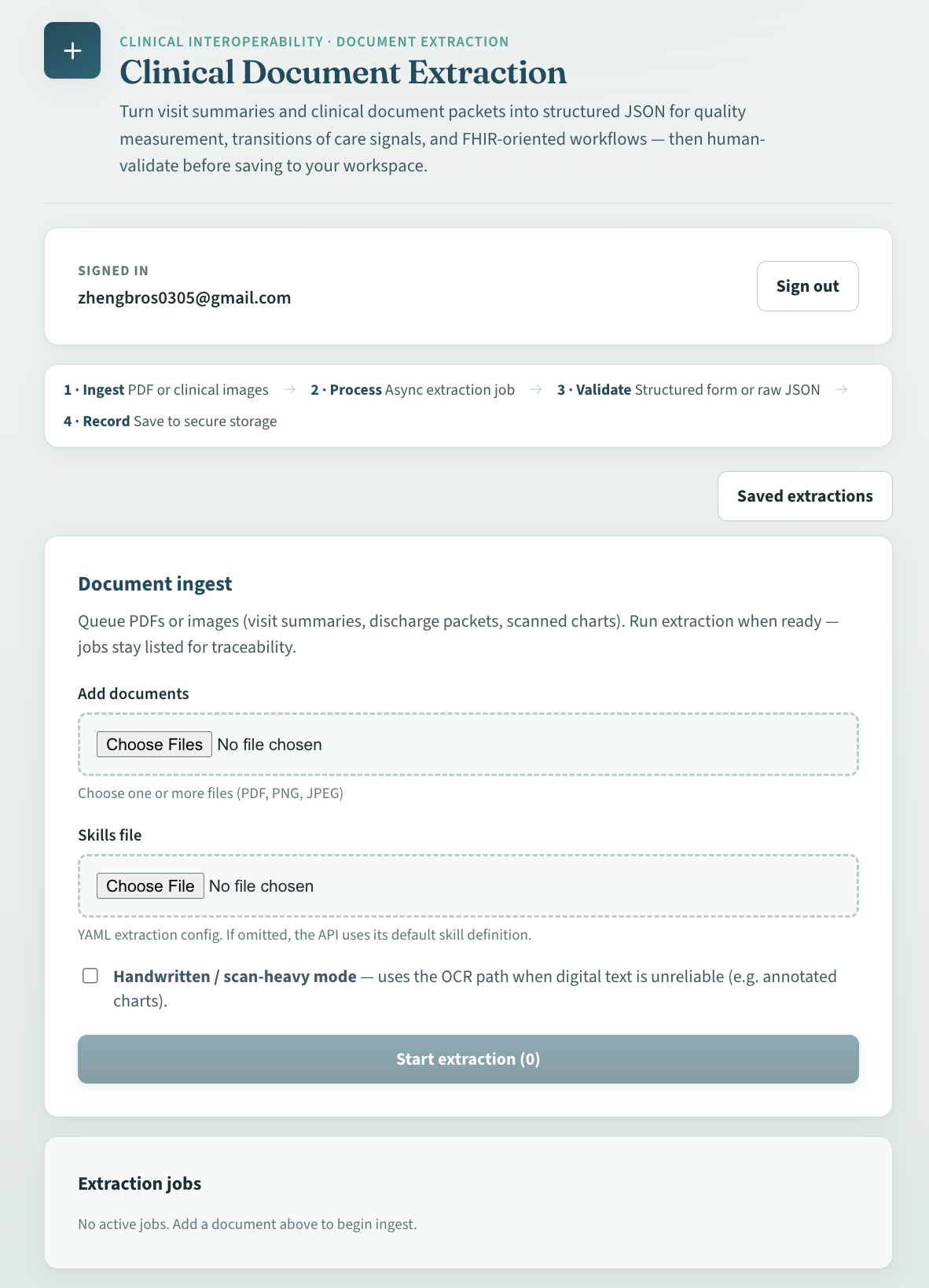
Homepage
-
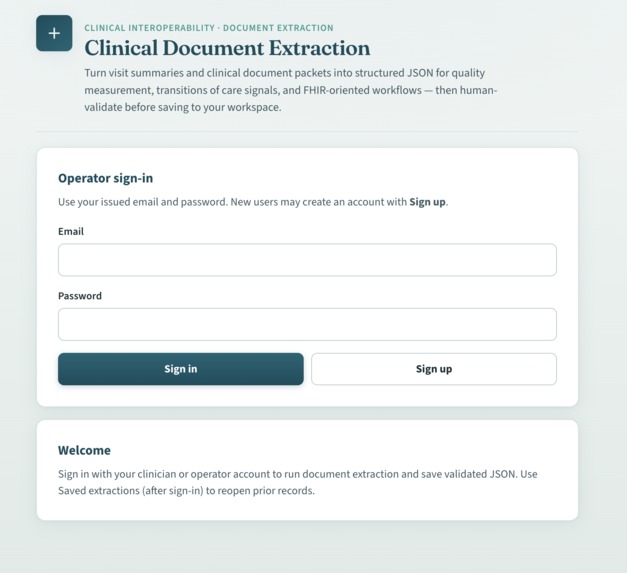
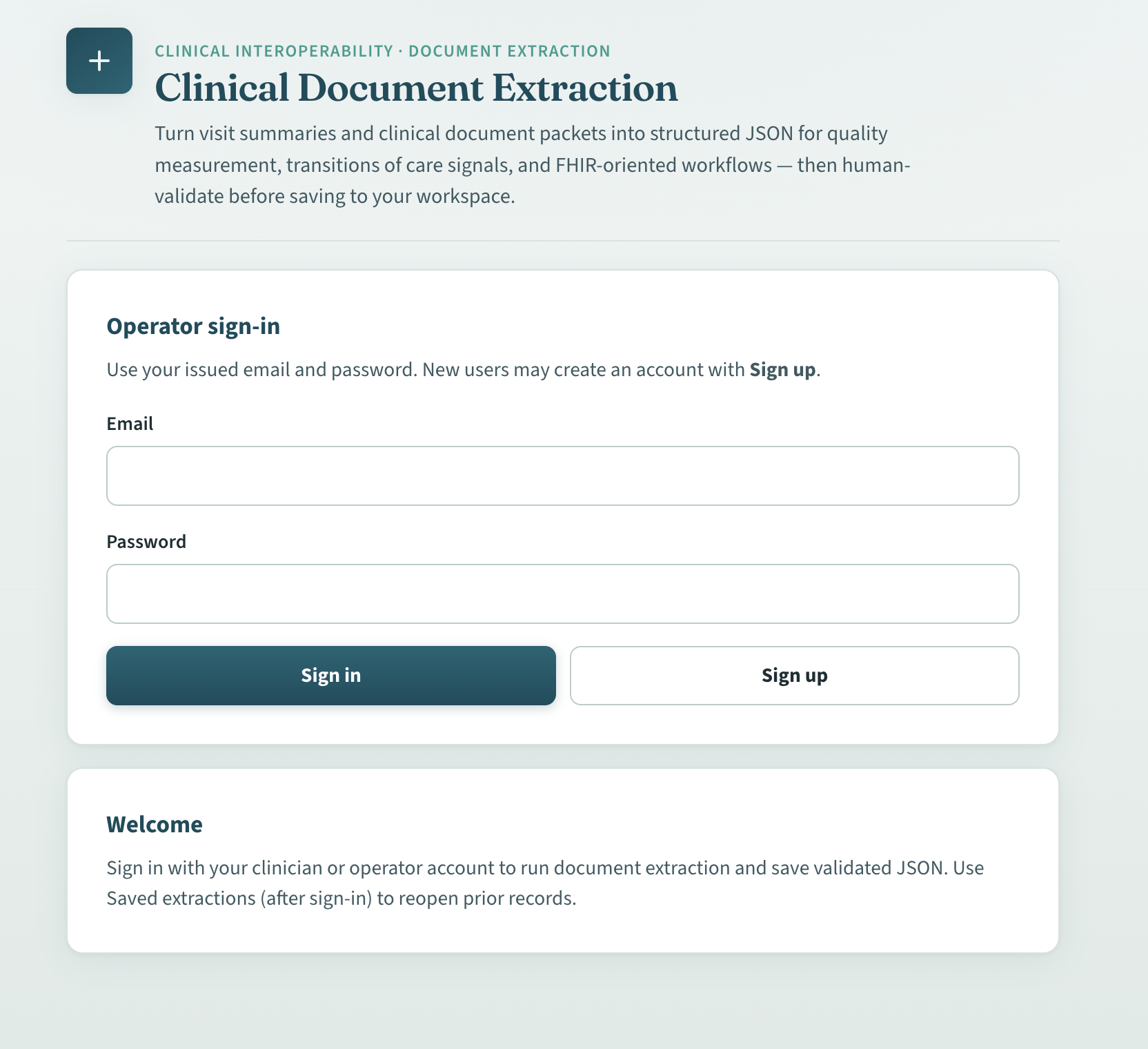
Login/Sign Up Screen
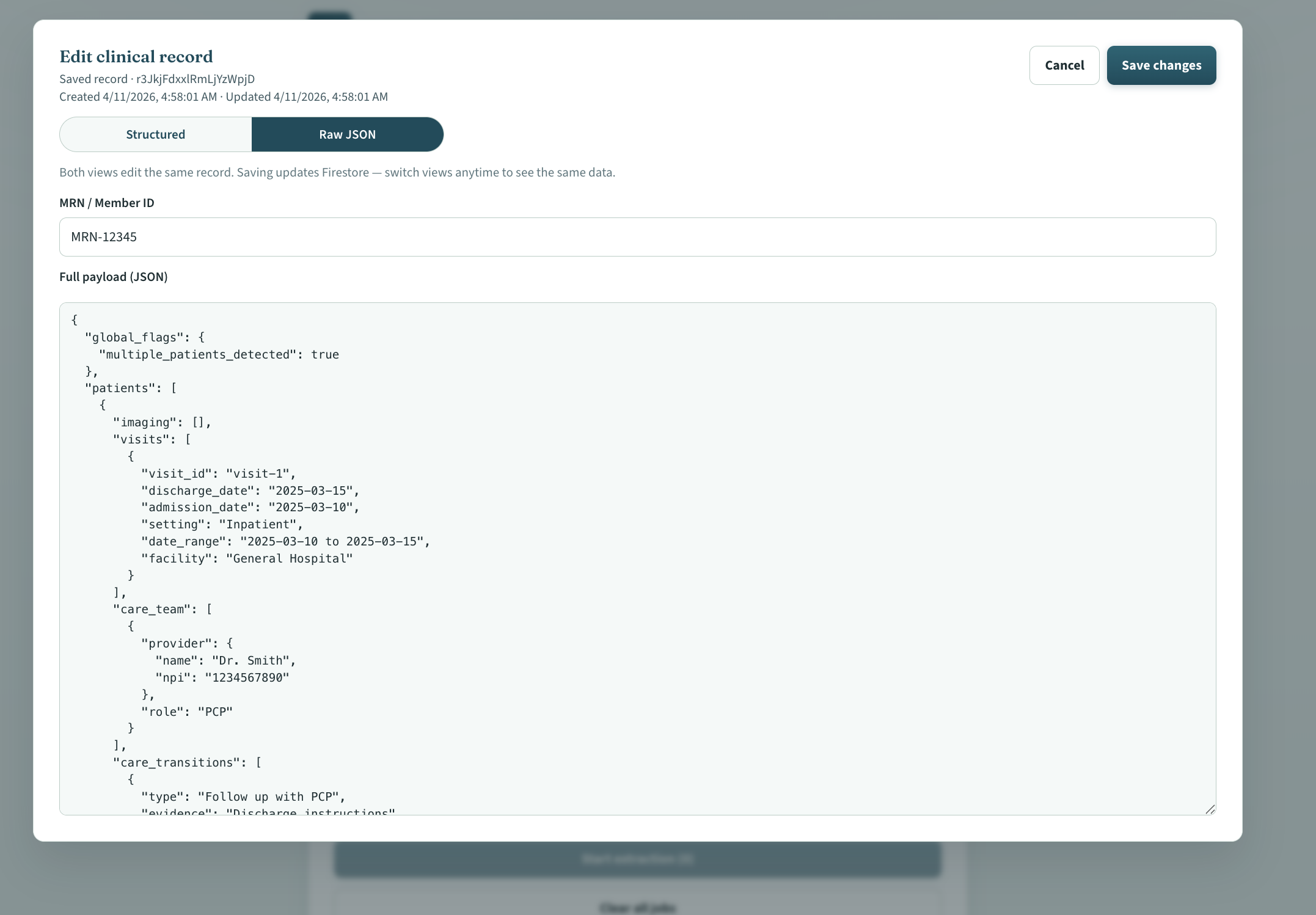
About the project
Inspiration
Healthcare still moves a lot of critical information as PDFs and scans (visit summaries, discharge packets, chart images), even as APIs and standards like FHIR get more attention. Turning those documents into consistent, machine-readable JSON—with visit-level structure, care-transition signals, and careful handling of PHI—is hard but necessary for analytics, gap closure, and interoperability-style workflows. This hackathon challenge pushed us to build something that behaves like a real pipeline: ingest long documents, run async jobs, and keep config-driven extraction (a YAML “skills” file) separate from the core serving code.
What we built
We built an end-to-end path from upload → async extraction → structured result:
- A FastAPI service prototyped in
Hackathon.ipynband run on Google Colab (with GPU). It accepts document uploads, runs extraction with an LLM plus PDF/image and OCR tooling, and exposes job status and results over HTTP (POSTingest,GETjob/result). - A React + Vite frontend in this repository so the system is demoable and testable: queue PDFs/images, optionally attach a YAML skills file, enable handwritten / scan-heavy mode when OCR matters, poll jobs, and review structured fields or raw JSON. Firebase (Auth + Firestore) is optional: when the app is configured, users can sign in and persist reviewed extractions; the extraction flow itself does not require Firebase.
The UI follows Ingest → Process → Validate → Record, with human review before saving anything to storage.
Team
| Name | Role |
|---|---|
| Arya Patel | Core backend / NLP logic: extraction design, LLM usage, and pipeline behavior, building on prior ML/NLP experience. Implementation details live in Hackathon.ipynb. |
| Andy Vo | Shaped that logic into a callable REST API, testing, and integration; helped with OCR paths so handwritten and scanned content remain usable. |
| Leo Zheng | Frontend: React UI wired to the backend—multipart ingest, job polling, error handling, ngrok compatibility (including ngrok-skip-browser-warning), long timeouts for slow jobs, and structured review plus optional Firebase. |
| Randy Truong | Data and requirements: inputs and expected outputs, and alignment with hackathon requirements on a tight timeline. |
How we built it
Backend (Colab / notebook only—there is no separate Python server repo in GitHub for this submission). We used PyTorch and Hugging Face Transformers with microsoft/Phi-3-mini-4k-instruct for instruction-style extraction, with PyMuPDF, pdf2image, and Pillow for documents, and EasyOCR and Tesseract for OCR. Extraction guidance is driven by YAML skill files rather than hard-coding everything in Python. We also use PHI-oriented redaction in logging where appropriate.
Frontend. React 18 and Vite, with a dev proxy to the API and extended timeouts for long-running jobs.
What we learned
- Notebooks are strong for GPU iteration; a thin API plus a real UI is what makes the system legible to judges and teammates.
- Async jobs fit NLP latency: the client stays usable while the server works.
- Digital text vs scans need different paths; a handwritten/scan toggle matched how we tested messy real-world files.
Challenges
Parallel work early on led to duplicated backend effort until we split roles: Arya and Andy on backend/API/OCR, Leo on frontend and integration, Randy on data and requirements.
Compute and deployment. Running a Transformers-based model locally was too slow for our hackathon window, so we used Colab GPUs. We could not fully productionize that stack on GitHub in time, so we tunnel the Colab API with ngrok and point the frontend (and Vite proxy) at that endpoint, with headers and timeouts tuned so browser-based demos stay reliable.
Long documents can be on the order of (10^2) pages; that reinforced why job-based processing and patient timeouts belong in the design—not as afterthoughts.

Log in or sign up for Devpost to join the conversation.